PR曲线与ROC曲线
PR曲线概念
PR曲线中的P代表的是precision(精准率),R代表的是recall(召回率),其代表的是精准率与召回率的关系,一般情况下,将recall设置为横坐标,precision设置为纵坐标。
![]()
P-R曲线怎么画?
在机器学习中,分类器往往输出的不是类别标号,而是属于某个类别的概率值,根据分类器的预测结果从大到小对样例进行排序,排在前面的是学习器认为最可能是正例的样本,排在后面的是学习器认为最不可能是正例的样本,可以选取不同的阈值或者按此顺序逐个把样本作为正例进行预测,则每次可计算当前的P、R值,以P为y轴,以R为x轴,可以画出P-R曲线。
- 绘制:选取不同的confidence置信度阈值,可以在PR坐标系上得到不同的点,连接这些点即可获得PR曲线
- 用途:用来评估模型性能。Precision值和Recall值越大越好,所以PR曲线越往右上角凸越好。
举例:
Inst#是样本序号,图中有20个样本。Class是ground truth 标签,p是positive样本(正例),n当然就是negative(负例) score是我的分类器对于该样本属于正例的可能性的打分。因为一般模型输出的不是0,1的标注,而是小数,相当于置信度。
然后设置一个从高到低的阈值T,大于等于阈值T的被我正式标注为正例,小于阈值T的被我正式标注为负例。
显然,我设置n个阈值,我就能得到n种标注结果,评判我的模型好不好使。
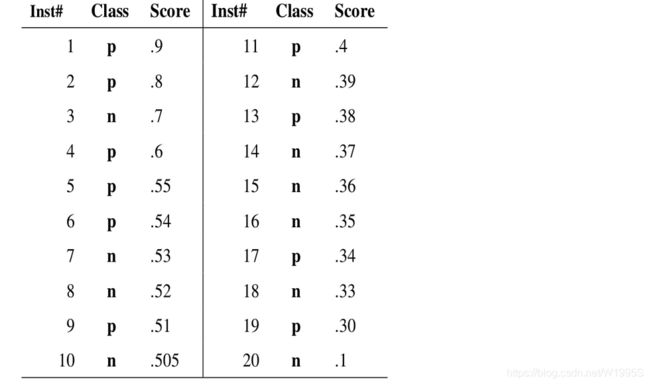
如上图:真实情况 正例p 反例n 各有10个。
0.9作为阈值(大于等于0.9为正例,小于0.9为反例),此时TP=1,FP=0,FN=9,故P=1,R=0.1。
用0.8作为阈值,此时TP=2,FP=0,FN=8,P=1, R=0.2。
用0.7作为阈值,此时TP=2,FP=1,FN=7,P=0.67,R=0.2。
用0.6作为阈值,此时TP=3,FP=1,FN=6,P=0.75,R=0.3。
以此类推。。。
最后得到一系列P、R值序列,就画出P-R曲线(示意图,不对应上面数据):
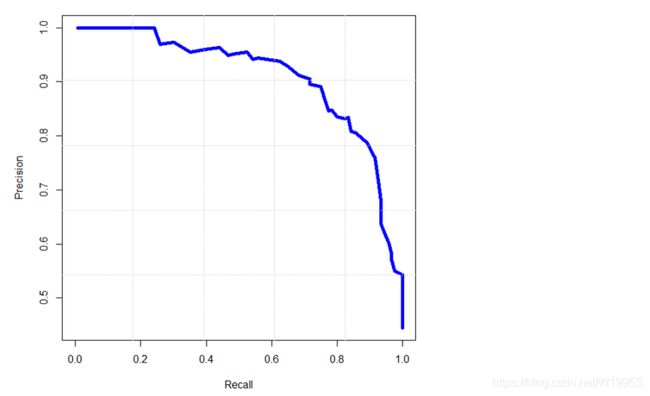
P-R曲线解析
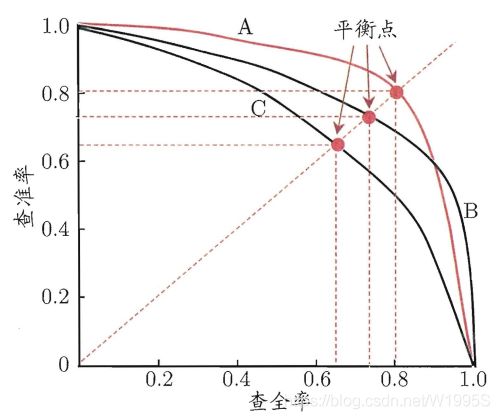
显然,P-R 曲线越靠近右上角性能越好。
如果一个学习器的P-R曲线被另一个学习器的P-R曲线完全包住,则可断言后者的性能优于前者,例如上面的A和B优于学习器C。但是A和B的性能无法直接判断,我们可以根据曲线下方的面积大小来进行比较,但更常用的是平衡点或者是F1-score。
平衡点(BEP)是P=R时的取值,如果这个值较大,则说明学习器的性能较好。
F1 = 2 * P * R /( P + R ),F1-score综合考虑了P值和R值,是精准率和召回率的调和平均值, 同样,F1值越大,我们可以认为该学习器的性能较好。
ROC曲线
在ROC曲线中,横轴是假正例率(FPR),纵轴是真正例率(TPR)。
![]()
(1)真正类率(True Postive Rate),代表分类器预测的正类中实际正实例占所有正实例的比例。
(2)负正类率(False Postive Rate),代表分类器预测的正类中实际负实例占所有负实例的比例。
我们可以发现:TPR=Recall。
ROC曲线也需要相应的阈值才可以进行绘制,原理同上的PR曲线。
用0.9作为阈值,此时TP=1,FP=0,FN=9,TN=10,故TPR=0.1,FPR=0。
用0.8作为阈值,此时TP=2,FP=0,FN=8,TN=10,故TPR=0.2,FPR=0。
用0.7作为阈值,此时TP=2,FP=1,FN=8,TN=9,故TPR=0.2,FPR=0.1。
用0.6作为阈值,此时TP=3,FP=1,FN=7,TN=9,故TPR=0.3,FPR=0.1。
以此类推。。。
最后的ROC曲线如下图:
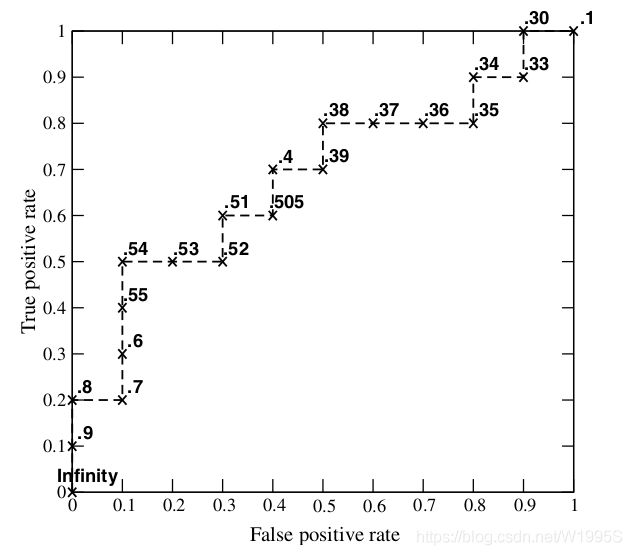
ROC曲线图中的四个点
第一个点:(0,1),即FPR=0, TPR=1,这意味着FN=0,并且FP=0。这是完美的分类器,它将所有的样本都正确分类。
第二个点:(1,0),即FPR=1,TPR=0,类似地分析可以发现这是一个最糟糕的分类器,因为它成功避开了所有的正确答案。
第三个点:(0,0),即FPR=TPR=0,即FP=TP=0,可以发现该分类器预测所有的样本都为负样本(negative)。
第四个点:(1,1),分类器实际上预测所有的样本都为正样本。经过以上的分析,ROC曲线越接近左上角,该分类器的性能越好。
一个对比:
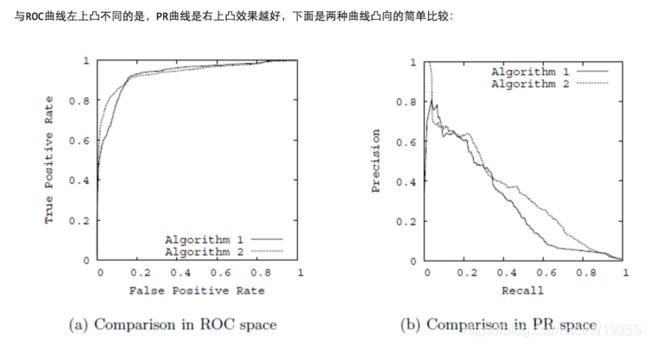
AUC
这里补充一下AUC的简单介绍。
AUC (Area under Curve):ROC曲线下的面积,介于0.1和1之间,作为数值可以直观的评价分类器的好坏,值越大越好。
AUC = 1,是完美分类器,采用这个预测模型时,存在至少一个阈值能得出完美预测。绝大多数预测的场合,不存在完美分类器。
0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值
PR曲线和ROC曲线的关系
PR曲线和ROC曲线都能评价分类器的性能。如果分类器a的PR曲线或ROC曲线包围了分类器b对应的曲线,那么分类器a的性能好于分类器b的性能。
PR曲线和ROC曲线有什么联系和不同:
相同点:
首先从定义上PR曲线的R值是等于ROC曲线中的TPR值。
都是用来评价分类器的性能的。
不同点:
ROC曲线是单调的而PR曲线不是(根据它能更方便调参),可以用AUC的值得大小来评价分类器的好坏(是否可以用PR曲线围成面积大小来评价呢?)。
正负样本的分布失衡的时候,ROC曲线保持不变,而PR曲线会产生很大的变化。
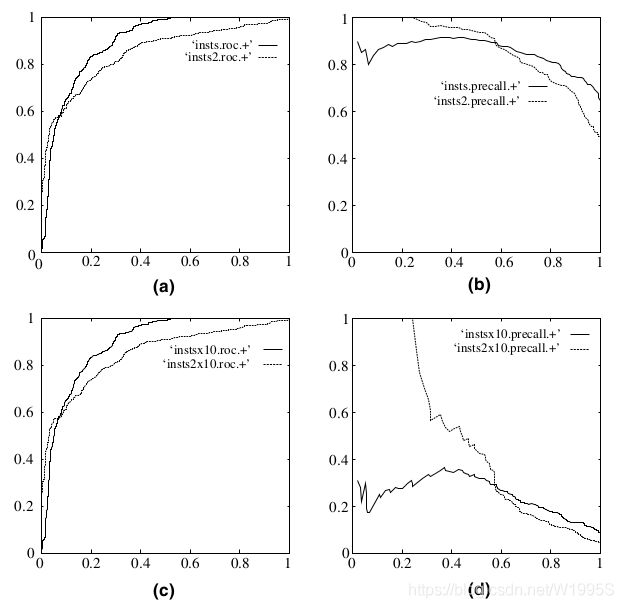
(a)(b)分别是正反例相等的时候的ROC曲线和PR曲线
(c)(d)分别是十倍反例一倍正例的ROC曲线和PR曲线
可以看出,在正负失衡的情况下,从ROC曲线看分类器的表现仍然较好(图c),然而从PR曲线来看,分类器就表现的很差。
事实情况是分类器确实表现的不好(分析过程见知乎 qian lv 的回答),是ROC曲线欺骗了我们。
参考(感谢)
https://blog.csdn.net/teminusign/article/details/51982877
https://www.jianshu.com/p/ac46cb7e6f87
https://www.zhihu.com/question/30643044/answer/64151574?from=profile_answer_card
http://www.fullstackdevel.com/computer-tec/data-mining-machine-learning/501.html