tensorflow.js在nodejs训练猫狗分类模型在浏览器上使用
目录
- 本人系统环境
- 注意事项
- 前言
- 数据集准备
- 处理数据集
-
- 数据集初步处理
- 将每一张图片数据转换成张量数据(tensor)
-
- 将图片转换成张量数组的代码和运行效果
- 将图片的标注转换成张量数据(tensor)
- 最终训练集的数据处理为
- 建立训练模型
- 训练模型
- 使用模型
-
- 在nodejs上使用
- 在浏览器上使用
- 源码下载
本人系统环境
- nodejs版本为16.14.0
- @tensorflow/tfjs-node(windows)版本为:3.18.0
注意事项
如果你的电脑环境是在window系统下,装@tensorflow/tfjs-node,请使用3.18.0版本的@tensorflow/tfjs-node,不然你装不了的,因为官方没有针对window系统做3.18.0之后版本的tfjs-node。所以在window系统中,nodejs安装tensorflow.js的方式npm i @tensorflow/[email protected]。
不过我更建议深度学习的环境最好是Linux系统,毕竟你搞机器学习最终会发现还是Linux舒服。Linux环境中编写就比较好了,环境上问题一般不会太多。
还有,本文章使用的是cpu进行模型训练。
前言
本文章是基于tensorflow.js在nodejs中进行训练,并且基于浏览器去调用模型实现猫狗分类的一个文章,本文章整体基于本人的一个学习和实现过程的一个整理,便于后期忘记了回来翻阅,本人也是刚入门机器学习领域。
还有就是,能阅读到本文章的同学应该水平是比较不错的,所以一些东西就默认不说了,基础啥的建议自行补齐。在接触tensorflow.js之前如果有接触过python的tensorflow应该会比较熟悉。在被科普了张量(tensor)这东西有啥用的前提下,并且没接触过tensorflow的想直接入门tensorflow.js的同学,本篇文章应该是一个比较好的开头(因为我也是刚入门)。
还有一件事就是,本文基于我的个人理解,本人文笔不好,刚入门机器学习领域,如果有错误的地方,清指正,不要骂我。谢谢
数据集准备
数据集使用的是kaggle的猫狗数据集,下载地址:Cat and Dog
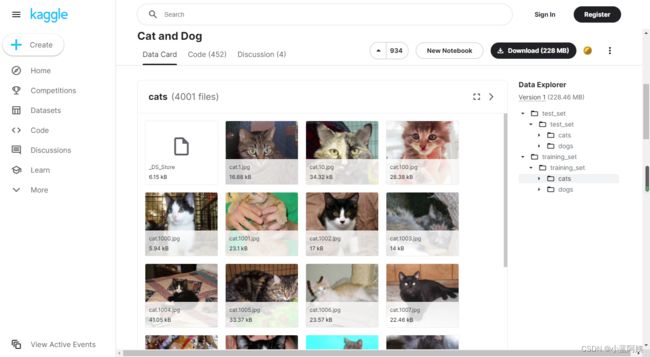
这里头一共有2000+的测试集,还有8000+的训练集
处理数据集
数据集初步处理
以下的处理方式我自己用的处理方式,有许许多多的处理方式,自己怎么方便怎么来哈。
处理数据集,我选择把测试集和训练集的图片放在一个文件夹上,然后生成对应的json文件(这一步自己动手去做哈)
我把猫和狗的图片全赛在一个文件夹,主要是懒,因为图片的名字就是标注了,那我只需要简单区分一下训练集和测试集的图片数据就行啦。
然后处理成一个json文件,方便去读图片数据

将每一张图片数据转换成张量数据(tensor)
这一步可是至关重要的,因为模型的训练需要输入的就是这图片的张量。
首先我们先来了解一下,在nodejs中要如何把一张图片转换成张量。
使用方法tf.node.decodeImage()将图片转换成一个张量。这个是不指定格式的,你可以使用指定格式的方法,官方文档自己看哈
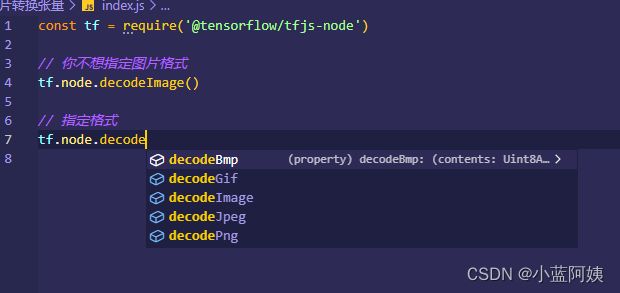
简单的将一张图片转换成张量然后输出来

代码
const tf = require('@tensorflow/tfjs-node')
const fs = require('fs')
const mTensor = tf.node.decodeImage(fs.readFileSync('cat.4001.jpg'))
// 输出图片张量
mTensor.print()
基于以上方法,我们直接将图片大批量读取然后直接转换即可(ps:这种方法后期需要调整为分批训练,因为我们的数据集不是很大,所以可以直接读到内存里面进行训练)
思路已经给出来了,所以我们直接实现就好啦。我就直接上代码啦,里头的东西我写了注释,自行去理解哈。
将图片转换成张量数组的代码和运行效果
/**
* 将图片转换成张量
* @param {string[]} paths 图片路径数组
* @returns {tf.Tensor}
*/
const imageToTensor = (paths) => {
// concat方法是将多个张量合并成一个张量
return tf.concat(paths.map(path => {
// 使用tidy方法,对张量进行内存控制,不然你直接读直接内存炸
return tf.tidy(() => {
return tf.node
.decodeImage(fs.readFileSync(path)) // 把图片转换成张量
.resizeNearestNeighbor([96, 96]) // 把图片的宽高转换成96x96
.toFloat() // 转换成浮点型的张量
.div(tf.scalar(255.0)) // 将图片张量进行归一化(这个自行去理解)
.expandDims()
})
}))
}
最终生成的图片张量是这样子的
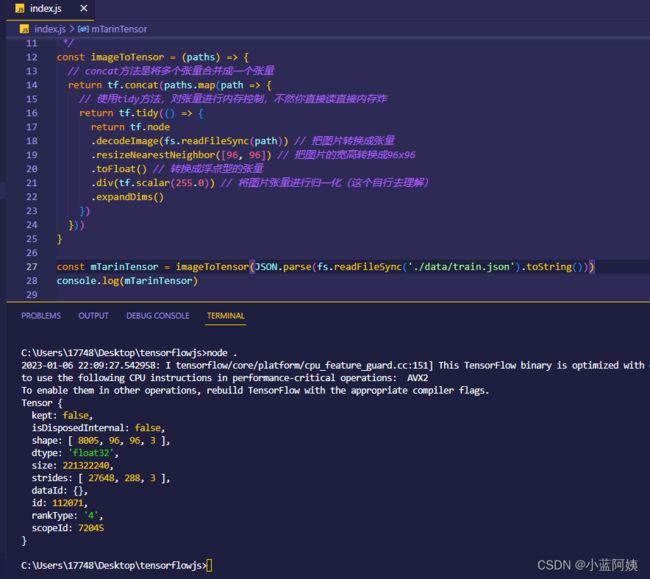
主要看那个shape,也就是那个[8005, 96, 96, 3],它表示张量的形状,也就是8005张图片,宽高为96,颜色通道为3(也就是rgb颜色值的三个数字)
我们训练时候只需要把这个传过去就行啦
将图片的标注转换成张量数据(tensor)
有了图片的数据后,我们需要的就是标注的数据啦。这个是很重要的,因为是分类数据,所以我们就把猫和狗给他编号一下,猫 = 0,狗 = 1。用数组表示就是['猫', '狗'],也就是[0, 1]
我们的标注数据,就是文件名,我们直接读一下文件名然后处理一下就行啦。
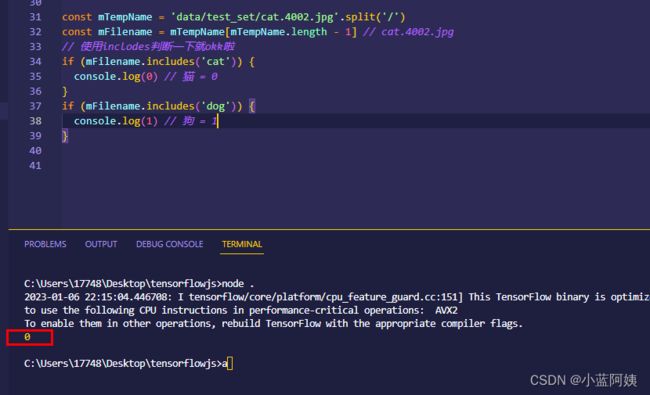
基于上面的这个思路,我们直接把全部标注拿出来,并生成张量,代码自行理解,注释已经打进去了。
/**
* 将图片路径里头的标注转换成张量
* @param {string[]} paths 图片路径数组
* @returns {tf.Tensor}
*/
const getLabels = (paths) => {
const mLabels = paths.map(path => {
const mTemp = path.split('/')
const mFilename = mTemp[mTemp.length - 1]
// 我就两个类,所以判断有cat就是0,没有cat就是1,也就是dog
return mFilename.includes('cat') ? 0 : 1
})
// mLabels输出的结果是只有0和1的数组,例如:[0,0,0,1,1,1,0,1,0...]
// 接下来我们将这个数组转换成张量,这一行自行翻源代码理解哈
return tf.oneHot(tf.tensor1d(mLabels, 'int32'), 2).toFloat()
}

运行结果也是注意这个shape,[8005, 2]代表里头有8005个标注,并分为2个种类,也就是猫和狗。
最终训练集的数据处理为
代码片段:
const mTarinPaths = JSON.parse(fs.readFileSync('./data/train.json').toString())
// 这个方法是tensorflow.js自带的工具方法,目的把数组的顺序打乱
tf.util.shuffle(mTarinPaths)
const mTarinTensor = imageToTensor(mTarinPaths)
const mTarinLabel = getLabels(mTarinPaths)
console.log(mTarinTensor, mTarinLabel)
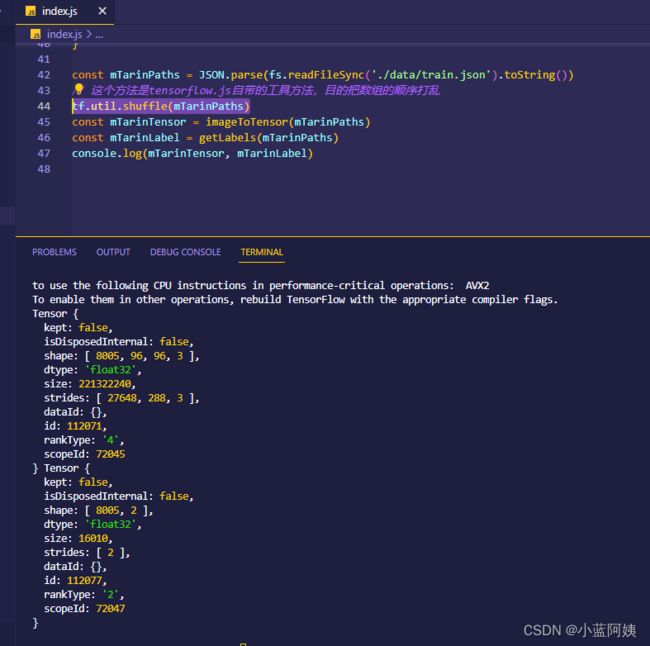
8005张图片就处理成这个张量。上述代码片段中出现了一个洗牌数据的方法tf.util.shuffle,目的只是为了打乱数组的顺序,使得训练集的对象在训练的时候更加的均匀一点。
建立训练模型
建立模型是本篇文章中最核心的地方,因为我们的训练这个分类就是基于这个模型去训练的,不过,我也是刚入门,这个模型是我直接从别人文章的python代码翻译过来的,我也不是很清楚到底是干啥的,只知道这玩意能训练出来模型达到效果,这是一个卷积神经网络模型。先暂时拿着用,一点点的消化。
/**
* 创建一个未训练的模型
* @returns {tf.Sequential}
*/
const createModel = () => {
// 网络每一层的一些参数
const kernel_size = [3, 3]
const pool_size= [2, 2]
const first_filters = 32
const dropout_conv = 0.3
const dropout_dense = 0.3
// 建立一个模型
const mModel = tf.sequential()
// 卷积层1
mModel.add(tf.layers.conv2d({
inputShape: [96, 96, 3],
filters: first_filters,
kernelSize: kernel_size,
activation: 'relu'
}))
// 卷积层2
mModel.add(tf.layers.conv2d({
filters: first_filters,
kernelSize: kernel_size,
activation: 'relu'
}))
// 池化层
mModel.add(tf.layers.maxPooling2d({ poolSize: pool_size }))
mModel.add(tf.layers.dropout({ rate: dropout_conv }))
mModel.add(tf.layers.flatten())
// 全连接层1
mModel.add(tf.layers.dense({
units: 256,
activation: 'relu'
}))
mModel.add(tf.layers.dropout({
rate: dropout_dense
}))
// 全连接层2
mModel.add(tf.layers.dense({
units: 2,
activation: 'softmax'
}))
// 编译模型
mModel.compile({
optimizer: tf.train.adam(0.0001),
loss: 'categoricalCrossentropy',
metrics: ['accuracy']
})
// 查看模型
mModel.summary()
return mModel
}
创建出来的这个模型就长这样子
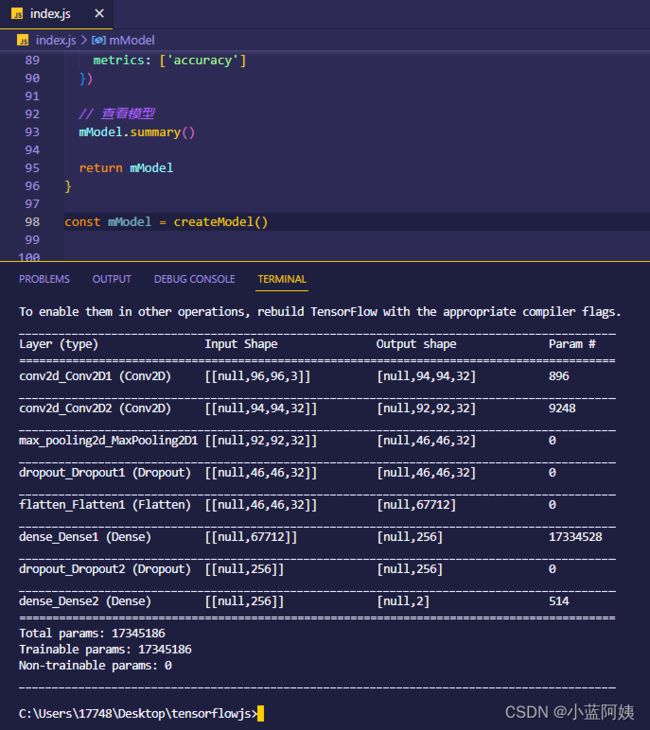
这个模型是未经过训练的,接下来我们就要训练模型啦。
训练模型
基于以上的代码片段,我们直接给出训练的代码片段
// 训练模型,只需要传入我们做好的两个张量,一个是样本一个是标注
mModel.fit(mTarinTensor, mTarinLabel, {
epochs: 15, // 训练15次,也就是这8005张图片要被训练15次
batchSize: 32, // 每批图片要训练多少张,这里电脑性能不好的同学最好填少一些
callbacks: {
onEpochEnd: () => {
// 每一次训练结束后执行的操作,保存模型
mModel.save('file://' + new Date().getTime())
}
}
})
训练过程

接下来就是漫长的训练时间,等待就好啦,那个进度条是自带的,acc代表临时精度,loss是一个损失值,越小越好。
然后每一次训练都会保存出一个模型
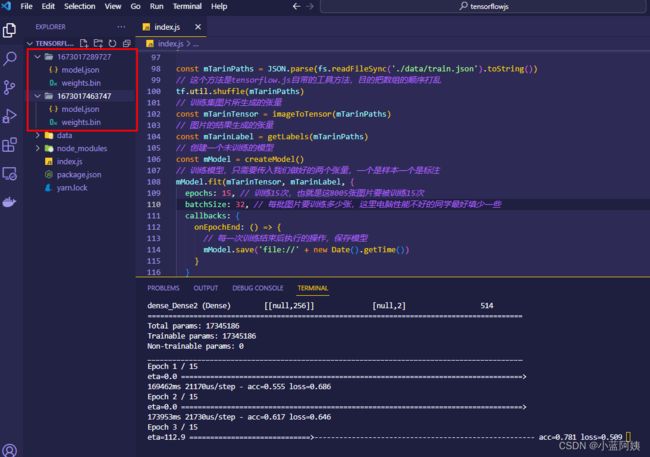
我们可以直接拿训练到最后一次的模型来使用。
我这边已经训练过了,我就直接拿我训练好15次的模型来使用就好哈
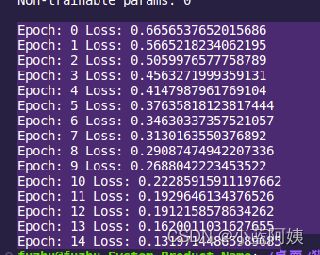
使用模型
因为tensorflow.js提供了多个环境下的依赖包,有浏览器的,有nodejs的,有wasm的。并且写法都是统一的,不过就是数据的获取方式有所不同,只需要做一小点改动就能在多环境下跑啦。我以浏览器和nodejs来运行我们的那个模型
在nodejs上使用
const tf = require('@tensorflow/tfjs-node')
const fs = require('fs')
const test = async () => {
// 读入模型
const mModel = await tf.loadLayersModel('file://1672996719000/model.json')
// 把要预测的图片转换成张量
const mTensor = tf.node.decodeImage(fs.readFileSync('bc363b9b0acf743cafa90fe77bde79a9.jpeg'))
.resizeNearestNeighbor([96, 96])
.toFloat()
.div(tf.scalar(255.0))
.expandDims()
// 获取预测结果,主要靠predict这个方法进行预测
const mResult = Array.from(mModel.predict(mTensor).dataSync()).map(num => num.toFixed(2))
console.log(mResult)
}
test()

预测出来的结果是概率,因为这个是提前做好的模型,忘记把第三类取消掉了,不过使用模型的方式的一样的,在控制台中输出的是概率,而最个概率对应的就是我们提前定好的类型,也就是['猫', '狗'],而我们这个['0.15', '0.85']也就是对应的概率,哪个大就是哪个,预测猫的概率为0.15,狗的概率是0.85,也就是说他预测出来了是狗。

我们预测一下猫,猫的概率是0.98,所以我们预测出来的是猫
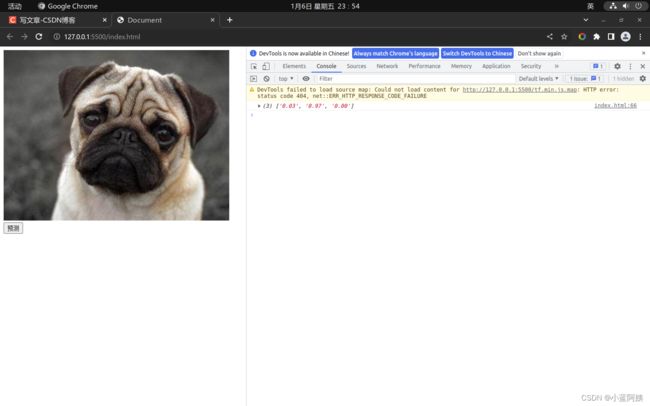
在浏览器上使用
浏览器上用法也是如此,不过要注意一点,也就是图片的转换问题。
转换图片我们只需要使用tf.browser.fromPixels这个方法即可把图片转换成张量
代码也是那个样,自行阅读哈
<body>
<div>
<img id="image" src="./3cfee36f7159e5559424fd635e857e50.jpeg" alt="">
<button id="submit">预测button>
div>
body>
<script>
window.onload = async() => {
const mModel = await tf.loadLayersModel('/1672996719000/model.json')
submit.onclick = async() => {
const mImageTensor = tf.browser
.fromPixels(document.getElementById('image'))
.resizeNearestNeighbor([96, 96])
.toFloat()
.div(tf.scalar(255.0))
.expandDims()
const mRes = Array.from(mModel.predict(mImageTensor).dataSync()).map(rate => rate.toFixed(2))
console.log(mRes)
}
}
script>
源码下载
自己把数据集下好然后放进去哈