70 岁 Hinton 还在努力推翻自己积累了 30 年的学术成果,他让我知道了什么叫做生命力...

来源:算法与数学之美(ID:MathAndAlgorithm)
本月,Hinton的那篇Capsule论文终于揭下了神秘的面纱,也因为该篇论文,他被刊进了各大媒体的头版头条。
在论文中,Capsule被Hinton大神定义为这样一组神经元:其活动向量所表示的是特定实体类型的实例化参数。
他的实验表明,鉴别式训练的多层Capsule系统,在MNIST手写数据集上表现出目前最先进的性能,并且在识别高度重叠数字的效果要远好于CNN。
该论文无疑将是今年12月初NIPS大会的重头戏。
不过,对于这篇论文的预热,Hinton大神可是早有准备。

一个月前,在多伦多接受媒体采访时,Hinton大神断然宣称要放弃反向传播,让整个人工智能从头再造。不明就里的媒体们顿时蒙圈不少。
8月份的时候,Hinton大神还用一场“卷积神经网络都有哪些问题?”的演讲来介绍他手中的Capsule研究,他认为“CNN的特征提取层与次抽样层交叉存取,将相同类型的相邻特征检测器的输出汇集到一起”是大有问题的。
当时的演讲中,Hinton大神可没少提CNN之父Yann LeCun的不同观点。毕竟,当前的CNN一味追求识别率,对于图像内容的“理解”帮助有限。

而要进一步推进人工智能,让它能像人脑一样理解图像内容、构建抽象逻辑,仅仅是认出像素的排序肯定是不够的,必须要找到方法来对其中的内容进行良好的表示……这就意味着新的方法和技术。
而当前的深度学习理论,自从Hinton大神在2007年(先以受限玻尔兹曼机进行训练、再用有监督的反向传播算法进行调优)确立起来后,除了神经网络结构上的小修小改,很多进展都集中在梯度流上。
正如知乎大V“SIY.Z”在《浅析Hinton最近提出的Capsule计划》时所举的例子。 (https://zhuanlan.zhihu.com/p/29435406)
sigmoid会饱和,造成梯度消失。于是有了ReLU。
ReLU负半轴是死区,造成梯度变0。于是有了LeakyReLU,PReLU。
强调梯度和权值分布的稳定性,由此有了ELU,以及较新的SELU。
太深了,梯度传不下去,于是有了highway。
干脆连highway的参数都不要,直接变残差,于是有了ResNet。
强行稳定参数的均值和方差,于是有了BatchNorm。
在梯度流中增加噪声,于是有了 Dropout。
RNN梯度不稳定,于是加几个通路和门控,于是有了LSTM。
LSTM简化一下,有了GRU。
GAN的JS散度有问题,会导致梯度消失或无效,于是有了WGAN。
WGAN对梯度的clip有问题,于是有了WGAN-GP。
而本质上的变革,特别是针对当前CNN所无力解决的动态视觉内容、三维视觉等难题……进行更为基础的研究,或许真有可能另辟蹊径。
这当然是苦力活,Hinton大神亲自操刀的话,成功了会毁掉自己赖以成名的反向传播算法和深度学习理论,失败了则将重蹈爱因斯坦晚年“宇宙常数”的覆辙。
所以,李飞飞对他在这里的勇气大为赞赏:
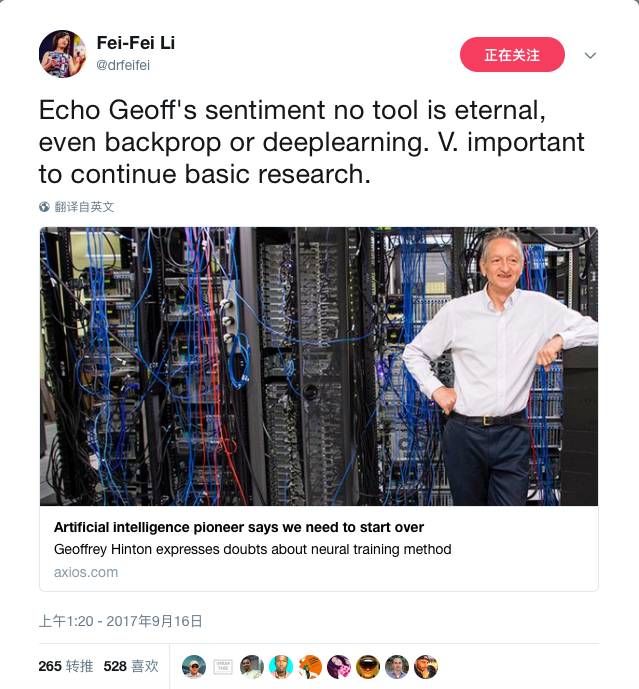
如今Capsule的论文刚刚出来,深度学习的各路大神并没有贸然对其下评论,深夜中的外媒亦尚未就此发稿,甚至就连技术圈内一向口水不断的Hacker News,今天也是静悄悄地一片。
不过,可以肯定的一点是,一个月后的NIPS大会,Capsule更进一步的效果必定会有所显现。
至于Hinton此举对于深度学习和整个人工智能界的后续影响,包括Yann LeCun在内的各路大神恐怕都不敢冒下结论,咱们还是静等时间来验证Hinton大神的苦心孤诣到底值不值得吧。
这正如Hinton大神在接受吴恩达采访时所说的:
如果你的直觉很准,那你就应该坚持,最终必能有所成就;反过来你直觉不好,那坚不坚持也就无所谓了。反正你从直觉里也找不到坚持它们的理由。
当然,营长肯定是相信Hinton大神的直觉的,更是期待人工智能能在当前的水平上更进一步。
尽管意义不同,Hinton大神此举却让营长想到了同在古稀之年的开尔文勋爵,他1900年那场关于物理学“两朵乌云”的演讲可是“预言”得贼准:
“紫外灾难”让年近不惑的普朗克为量子力学开创了先河,“以太漂移”让刚刚毕业的爱因斯坦开始思考狭义相对论,经典物理学的大厦就此崩塌。
那么,人工智能上空所飘荡的到底是一朵“乌云”呢?还是一个新的时代?让我们拭目以待。
参考链接:
https://zhuanlan.zhihu.com/p/29435406



感谢你的分享,点赞,在看三连↓