LeNet小结
提示:本文是参考李沐老师和另一个B站up主代码以及讲解对自己所学东西的整理,具体资料连接会在文章中给出。且全部实验代码是在kaggle平台上验证过滴。
文章目录
- 前言
- 一、LeNet网络架构
- 二、搭建LeNet网络
-
- 2.1 版本一
-
- 2.1.1 模型构建
- 2.1.2 数据加载
- 2.1.3 模型训练
- 2.2 版本二
-
- 2.2.1 模型定义
- 2.2.2 数据加载
- 2.2.3 模型训练
- 总结
前言
李沐老师参考资料地址:link.
B站up主霹雳吧啦Wz:link.
注意:本文主要是对LeNet网络的梳理,且主要是对代码的梳理,是Pytorch版本。视以后情况,可能会增加tensorflow版本代码。看懂改代码需要一定MLP、CNN和Pytorch基础知识,B站有相关up主讲解比较详细,在此我推荐几个up主吧,大家自行决定决定要不要看吧。
李沐老师主页:link.
B站up主刘二大人:link.
B站up主二次元的Datawhale:link.
其中二次元的Datawhale是一个开源组织,这个开源组织还有其他资料也比较好,pandas教程,西瓜书教程(偏理论教学),其中南瓜书就是由这个开源组织编写的。我觉得可能对刚入门的小伙伴比较友好一些。
还有请大家知晓一下啦,本博客基本是对自己所学知识整理,方便以后自己复习(主要是代码整理)。而且自己也还是学生,初学深度学习(但是不是人工智能方向相关专业学生哦,只是需要用到深度学习作为一个工具使用),有很多表述可能有不当和错误,希望大家可以指出来哦!谢谢大家。
一、LeNet网络架构
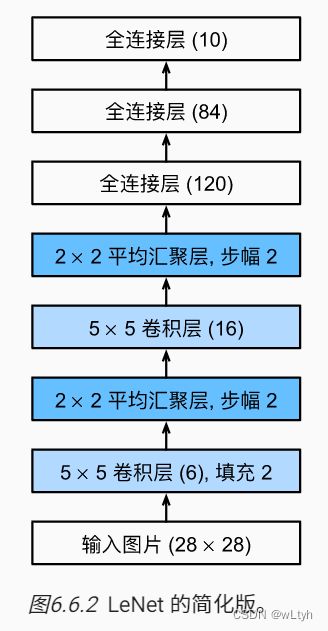
这是李沐老师动手深度学习书上的图,自己比较懒,就不动手画了。这个就是LeNet基本网络架构。
注意

这里做了一点小小的改变,之所以删除最后一层的高斯激活,是因为后面实践证明该层实际对网络作用不大,可以省去。我们可以看到每一个框中都有一些参数,大家可以去看我推荐的资料看下具体含义。
二、搭建LeNet网络
2.1 版本一
2.1.1 模型构建
参考地址:link.
代码如下(示例):
'''导入我们需要的包'''
import torch
from torch import nn
'''构建Sequential模型'''
net = nn.Sequential(
'''
卷积层:输入通道数为1,输出通道数为6,核大小为5×5,填充为2,步幅采用默认为1
激活函数:Sigmoid激活
'''
nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),
'''平均池化:核大小为2×2,步幅为2,一般用于激活函数后'''
nn.AvgPool2d(kernel_size=2, stride=2),
'''
输入通道数为6,输出通道数为16,核大小为5×5,不填充,步幅默认为1
激活函数:Sigmoid激活
'''
nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),
'''平均池化:核大小为2×2,步幅为2,一般用于激活函数后'''
nn.AvgPool2d(kernel_size=2, stride=2),
'''
Flatten层,将数据压平
若如输入维度为(16, 3, 4),经过该层后,输出维度为(16, 12)
若输入维度为(10, 3, 4, 10),经过该层后,输出维度为(10, 120)
我们总保持第0个维度不变,来压缩后面所有的维度,这是在默认参数情况下。
'''
nn.Flatten(),
'''全连接层,输入特征为16×5×5,输出特征为120,后再加一个激活函数'''
nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),
'''全连接层,输入特征为120,输出特征为84,后再加一个激活函数'''
nn.Linear(120, 84), nn.Sigmoid(),
'''全连接层,输入特征为120, 输出特征为10,这是最后一层,因为我们有10类,所以
该层输出特征为10'''
nn.Linear(84, 10))
接下来,我们看一看每层输出维度。
'''
这里我们假设输入数据维度为(1, 1, 28, 28),其中第个‘1’代
表batch大小,即我们这里设为1个样本,第二个‘1’代表图片通道
数正常来说我们生活中彩色图片都是RGB图片即3通道,这里我们为
黑白图片,只有1个通道。后面两个个数据分别为图片的H和W。
torch.rand函数这里是产生[0,1)的均匀分布
'''
X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape: \t',X.shape)
输出如下:

2.1.2 数据加载
代码如下(示例):
'''导入我们需要的包'''
import torchvision
from torchvision import transforms
from torch.utils import data
''' 数据加载方式 '''
def load_data_fashion_mnist(batch_size, resize=None):
"""下载Fashion-MNIST数据集,然后将其加载到内存中"""
'''将像素数值类型转换为张量'''
trans = [transforms.ToTensor()]
'''对图片是否进行缩放操作'''
if resize:
trans.insert(0, transforms.Resize(resize))
'''将对图形要处理的所有操作放在里面'''
trans = transforms.Compose(trans)
'''
这里我把路径放在./data下了,大家使用的是kaggle的话会在Output下看到
/kaggle/working一栏下看data文件夹,大家就会在里面看到数据集。
'''
# 训练集
mnist_train = torchvision.datasets.FashionMNIST(
root="./data", train=True, transform=trans, download=True)
# 验证集
mnist_test = torchvision.datasets.FashionMNIST(
root="./data", train=False, transform=trans, download=True)
'''
这里就是设置数据集的batch_size大小,并将训练集进行shuffle(打乱)操作,而
验证集不用shuffle操作。并且使用4个进程加快读取速度
'''
return (data.DataLoader(mnist_train, batch_size, shuffle=True,
num_workers=4),
data.DataLoader(mnist_test, batch_size, shuffle=False,
num_workers=4))
# batch_size大小
batch_size = 256
# 加载数据
train_iter, test_iter = load_data_fashion_mnist(batch_size=batch_size)
运行上面的程序之后我们就会得到分好batch的训练集train_iter和验证集test_iter。接下来我们查看一些数据集信息。
from collections.abc import Iterable, Iterator
# 每一个batch有batch_size个样本,最后一个batch可能不足batch_szie个样本
print(f"训练集数据有 {len(train_iter)} batch")
print(f"验证集数据集有 {len(test_iter)} batch")
if isinstance(train_iter, Iterable):
# 如果train_iter是可迭代对象,我们用iter()方法将其转换为迭代器,并用next取出第一个batch
batch_one = next(iter(train_iter))
print("输入数据维度:", batch_one[0].shape)
print("输入数据标签维度:", batch_one[1].shape)
输出结果:

可以看到第一个batch样本数量是256,通道数是1,H和W分别为28。
查看一些图片,
import matplotlib.pyplot as plt
# 得到对应文本标签
def get_fashion_mnist_labels(labels):
"""返回Fashion-MNIST数据集的文本标签"""
text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat',
'sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']
return [text_labels[int(i)] for i in labels]
def show_images(imgs, num_rows, num_cols, titles=None, scale=1.5):
# num_rows:行,num_cols:列,scale:设置图片大小
figsize = (num_cols * scale, num_rows * scale) # 相当于画布大小
_, axes = plt.subplots(num_rows, num_cols, figsize=figsize)
axes = axes.flatten()
for i, (ax, img) in enumerate(zip(axes, imgs)):
if torch.is_tensor(img):
# 图片张量
ax.imshow(img.numpy())
else:
# PIL图片
ax.imshow(img)
# 不显示X轴
ax.axes.get_xaxis().set_visible(False)
# 不显示Y轴
ax.axes.get_yaxis().set_visible(False)
if titles:
# 给每一个图片设置标题
ax.set_title(titles[i])
return axes
X, y = next(iter(train_iter))
# 显示前18张图片
show_images(X[:18].reshape(18, 28, 28), 2, 9, titles=get_fashion_mnist_labels(y[:18]))
输出结果:

在画图中我们有一个关于axes.flatten(),具体解释见该链接link
2.1.3 模型训练
计算准确度有关部分程序
'''这个是我们为了在训练过程中存储某些数据而定义的一个类'''
class Accumulator:
def __init__(self, n):
self.data = [0.0] * n
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
def __getitem__(self, idx):
assert idx<len(self.data)
return self.data[idx]
'''求正确预测数量'''
def accuracy(y_hat, y):
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
y_pre = y_hat.argmax(axis=1)
cmp = (y_pre.type(y.dtype)==y)
return float(cmp.type(y.dtype).sum()) # 返回正确预测数量
def evaluate_accuracy_gpu(net, data_iter, device=None):
"""使用GPU计算模型在数据集上的精度"""
if isinstance(net, nn.Module):
'''设置为评估模式'''
net.eval()
'''如果没给出使用CPU还是GPU,我们可以查看模型参数在哪个设备上'''
if not device:
device = next(iter(net.parameters())).device
'''存储两个数,分别为正确预测的数量,总预测的数量'''
metric = Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
if isinstance(X, list):
# BERT微调所需的(之后将介绍)
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
metric.add(accuracy(net(X), y), y.numel())
return metric[0] / metric[1] # 返回预测精度
画动态图有关部分程序
import matplotlib.pyplot as plt
from IPython import display
def set_axes(axes, xlabel, ylabel, xlim, ylim, xscale, yscale, legend):
"""设置matplotlib的轴"""
axes.set_xlabel(xlabel) # 设置标签
axes.set_ylabel(ylabel) # 设置标签
axes.set_xscale(xscale) # 控制坐标轴的缩放类型
axes.set_yscale(yscale)
axes.set_xlim(xlim) # 设置x轴范围
axes.set_ylim(ylim) # 设置y轴范围
if legend:
axes.legend(legend)
axes.grid()
class Animator:
"""在动画中绘制数据,这里最多显示四条线,因为fmts中只有四个元素,若要显示更多值,在fmts添加元素即可"""
def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,
ylim=None, xscale='linear', yscale='linear',
fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,
figsize=(4, 3.5)):
# 增量地绘制多条线
if legend is None:
legend = []
"""使用svg格式在Jupyter中显示绘图"""
display.set_matplotlib_formats('svg')
self.fig, self.axes = plt.subplots(nrows, ncols, figsize=figsize)
if nrows * ncols == 1:
self.axes = [self.axes, ]
# 使用lambda函数捕获参数
self.config_axes = lambda: set_axes(
self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)
self.X, self.Y, self.fmts = None, None, fmts
def add(self, x, y):
# 向图表中添加多个数据点
if not hasattr(y, "__len__"):
y = [y] # 没有__len__属性表示我们只要画一条线
n = len(y) # 需要画n条线
if not hasattr(x, "__len__"):
x = [x] * n # x轴,因为我们要画n调线,所以对应n个x轴
if not self.X:
self.X = [[] for _ in range(n)]
if not self.Y:
self.Y = [[] for _ in range(n)]
for i, (a, b) in enumerate(zip(x, y)):
if a is not None and b is not None: # 我们画n条线的数据保存在X和Y中
self.X[i].append(a)
self.Y[i].append(b)
self.axes[0].cla() # 清理当前轴
for x, y, fmt in zip(self.X, self.Y, self.fmts): # 画n条线
self.axes[0].plot(x, y, fmt)
self.config_axes() # 设置轴的参数
display.display(self.fig) # 显示当前fig
# 清除当前图像,设置wait=True表示直到有一个图像可以替代当前图像
display.clear_output(wait=True)
有关画动态图的参考博客可见该链接link
计时部分程序
# 计时
import time
class Timer:
"""记录多次运行时间"""
def __init__(self):
self.times = []
self.start()
def start(self):
"""启动计时器"""
self.tik = time.time()
def stop(self):
"""停止计时器并将时间记录在列表中"""
self.times.append(time.time() - self.tik)
return self.times[-1]
def avg(self):
"""返回平均时间"""
return sum(self.times) / len(self.times)
def sum(self):
"""返回时间总和"""
return sum(self.times)
def cumsum(self):
"""返回累计时间"""
return np.array(self.times).cumsum().tolist()
训练部分程序
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):
"""用GPU训练模型(在第六章定义)"""
# 自定义初始化
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on', device)
net.to(device)
# 使用SGD优化算法
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
# 计算损失,使用交叉熵
loss = nn.CrossEntropyLoss()
# 初始化画图对象
animator = Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['train loss', 'train acc', 'test acc'])
# 训练时间、数据被分为了多少个batch
timer, num_batches = Timer(), len(train_iter)
for epoch in range(num_epochs):
# 训练损失之和,训练准确率之和,样本数
metric = Accumulator(3)
net.train()
for i, (X, y) in enumerate(train_iter):
# 计算时间,时间开始
timer.start()
# 清空梯度,pytorch不会自动清除上次求导梯度,需要自己动手清除
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
# 计算损失
l = loss(y_hat, y)
# 反向传播
l.backward()
# 参数更新
optimizer.step()
# 在with里面的计算不加入计算图中
with torch.no_grad():
metric.add(l * X.shape[0], accuracy(y_hat, y), X.shape[0])
timer.stop() # 时间结束
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
# 每个epoch中每经过num_batches//5 个batch就记录一次数据或者每个epoch的最后一个batch必须记录数据
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
#epoch + (i + 1) / num_batches,这种写法每次都可以将X轴固定在0到num_epochs之间
animator.add(epoch + (i + 1) / num_batches,
(train_l, train_acc, None))
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, '
f'test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec '
f'on {str(device)}')
开始训练
lr, num_epochs = 0.05, 10
device = "cuda:0" if torch.cuda.is_available() else "cpu"
train_ch6(net, train_iter, test_iter, num_epochs, lr, device)
结果如下:

2.2 版本二
参考地址:link
需要大家合理,这是一个github地址。
2.2.1 模型定义
模型定义如下,与李沐老师有稍许不同,不同已写在注释中。
import torch.nn as nn
import torch.nn.functional as F
'''
该版本与李沐老师版本主要不同如下
1、数据集是CIFAR10数据集,其为RGB彩色图片,通道为3;Fashion-MNIST为黑白图片,通道数为1;
2、这里卷积层通道数不同;
3、我们将平均池化换成了最大池化;
4、我们将Sigmoid激活换成了ReLU激活;
5、我们将Flatten层换成了view来改变X形状来达到同样的效果。
'''
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(3, 16, 5)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 32, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(32*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.relu(self.conv1(x)) # input(3, 32, 32) output(16, 28, 28)
x = self.pool1(x) # output(16, 14, 14)
x = F.relu(self.conv2(x)) # output(32, 10, 10)
x = self.pool2(x) # output(32, 5, 5)
# 两个维度,-1代表由程序自己推测该维度,我们只需要第二个维度为32*5*5
x = x.view(-1, 32*5*5) # output(32*5*5)
x = F.relu(self.fc1(x)) # output(120)
x = F.relu(self.fc2(x)) # output(84)
x = self.fc3(x) # output(10)
return x
2.2.2 数据加载
首先下载数据,并查看数据形状。
import torchvision.transforms as transforms
'''
(0.5, 0.5, 0.5), (0.5, 0.5, 0.5)表示CIFAR10数据集每个通道的均值和标准差都为0.5
根据channel数做归一化,使每个通道服从均值为0,标准准差为1的正态分布,这是在视觉中处理图片常用手段,有利于模型训练。
在使用该方法之前必须将像素值转换为tensor类型,否则Normalize会报错
'''
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 50000张训练图片
# 第一次使用时要将download设置为True才会自动去下载数据集
train_set = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=36,
shuffle=True, num_workers=0)
print("第一个batch输入数据维度:", next(iter(train_loader))[0].shape)
print("第一个batch输出标签维度:", next(iter(train_loader))[1].shape)
输出:

有关该部分transform的两个函数相关功能可参考该博客link,hh,这里建议大家手动实现一下,我自己试了一下,是正确的,就不贴出代码了。
关于归一化这块做一个简单数学证明:
现有一随机变量 X X X,设 X X X均值为 μ μ μ,标准差为 δ δ δ,求随机变量 X − μ δ \frac{X-μ}{δ} δX−μ的均值和方差。
求均值: E ( X − μ δ ) = E ( X − μ ) δ = E ( X ) − E ( μ ) δ = μ − μ δ = 0 E(\frac{X-μ}{δ})=\frac{E(X-μ)}{δ}=\frac{E(X)-E(μ)}{δ}=\frac{μ-μ}{δ}=0 E(δX−μ)=δE(X−μ)=δE(X)−E(μ)=δμ−μ=0
因此我们的归一化后的均值为0。
求方差: E ( ( X − μ δ − 0 ) 2 ) = E ( ( X − μ δ ) 2 ) = E ( ( X − μ ) 2 ) δ 2 = E ( X 2 − 2 μ X + μ 2 ) δ 2 E((\frac{X-μ}{δ}-0)^2)=E((\frac{X-μ}{δ})^2)=\frac{E((X-μ)^2)}{δ^2}=\frac{E(X^2-2μX+μ^2)}{δ^2} E((δX−μ−0)2)=E((δX−μ)2)=δ2E((X−μ)2)=δ2E(X2−2μX+μ2)
由期望的性质可得如下式子: E ( X 2 − 2 μ X − μ 2 ) = E ( X 2 ) − 2 μ E ( X ) + μ 2 = E ( X 2 ) − μ 2 = δ 2 E(X^2-2μX-μ^2)=E(X^2)-2μE(X)+μ^2=E(X^2)-μ^2=δ^2 E(X2−2μX−μ2)=E(X2)−2μE(X)+μ2=E(X2)−μ2=δ2
因此可得: E ( ( X − μ δ ) 2 ) = δ 2 δ 2 = 1 E((\frac{X-μ}{δ})^2)=\frac{δ^2}{δ^2}=1 E((δX−μ)2)=δ2δ2=1
如果随机变量X的样本数量趋于 ∞ \infty ∞,则根据大数定律得(应该是这个,具体哪个定理有点忘了),该分布就是标准正态分布。
latex语法格式参考博客连接:link1,link2
接下来我们显示几张图看看:
import matplotlib.pyplot as plt
import numpy as np
# 得到对应文本标签
def get_fashion_mnist_labels(labels):
"""返回Fashion-MNIST数据集的文本标签"""
text_labels = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
return [text_labels[int(i)] for i in labels]
def show_images(imgs, num_rows, num_cols, titles=None, scale=2.9):
# num_rows:行,num_cols:列,scale:设置图片大小
figsize = (num_cols * scale, num_rows * scale) # 相当于画布大小
_, axes = plt.subplots(num_rows, num_cols, figsize=figsize)
axes = axes.flatten()
for i, (ax, img) in enumerate(zip(axes, imgs)):
if torch.is_tensor(img):
# 图片张量,将维度从(C,H,W)转换为(H,W,C),不能使用reshape,只能用tranpose
ax.imshow(np.transpose(img.numpy(), (1,2,0)))
else:
# PIL图片
ax.imshow(img)
# 不显示X轴
ax.axes.get_xaxis().set_visible(False)
# 不显示Y轴
ax.axes.get_yaxis().set_visible(False)
if titles:
# 给每一个图片设置标题
ax.set_title(titles[i])
return axes
X, y = next(iter(train_loader))
# 显示前8张图片
show_images(X[:8], 2, 4, titles=get_fashion_mnist_labels(y[:8]))
输出结果如下:

注意
从前面我们可以看到我们每张图片的维度为(3,32,32),即(C,H,W)形式,但是我们在显示图片的时候,imshow只接受(H,W,C)这种维度格式输入。因此要对每一张图片在显示的时候调用np.transpose()将数据进行转置操作,这其实是多维数组转置操作。对于该函数理解可看该博客link
不过我们要注意reshape和transpose的一个区别吧,反正我容易弄混。
首先我们生成一个测试数据:
# 假设a为像素值,且维度格式为(H, W, C)
a = torch.tensor(range(48)).reshape(4,4,3)
print(a.shape)
print(a)
输出如下:

现在我们需要将a转换为(C, H, W)格式数据。似乎我们好像使用reshape操作就可以得到,现在使用reshape来达到效果
print(a.reshape(3,4,4))
输出结果:

reshape就是将源张量进行了一个类似于flatten的操作,即从0到47个元素按顺序排,然后按照[3,4,4]进行一个分组罢了。
我们使用transpose操作:
print(np.transpose(a.numpy(), (2,0,1)))
输出结果如下:

我们可以看到两种截然不同的效果,很明显使用transpose是对的,因为我们是要将数据格式从(H, W, C)转换为(C, H, W)。本质就是将数据索引交换位置,从而使数据索引变动,从而形成一个新的张量。
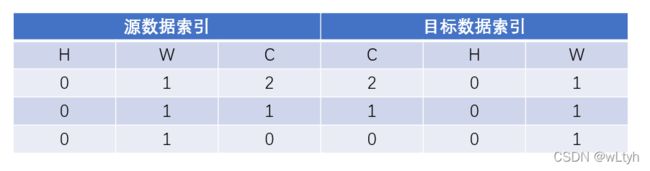
由上表可以看出,假如一个数据在原张量中索引为[0,1,2],现在进行transpose后,其索引变成[2,1,0],若源数据索引为[0,1,1],变换之后其索引为[1,0,1]。其实就是与二维矩阵的转置操作相似,也就是把行列索引值交换,从而元素到了一个新的位置。
2.2.3 模型训练
数据处理程序
import matplotlib.pyplot as plt
from IPython import display
def set_axes(axes, xlabel, ylabel, xlim, ylim, xscale, yscale, legend):
"""设置matplotlib的轴"""
axes.set_xlabel(xlabel) # 设置标签
axes.set_ylabel(ylabel) # 设置标签
axes.set_xscale(xscale) # 控制坐标轴的缩放类型
axes.set_yscale(yscale)
axes.set_xlim(xlim) # 设置x轴范围
axes.set_ylim(ylim) # 设置y轴范围
if legend:
axes.legend(legend)
axes.grid()
class Animator:
"""在动画中绘制数据,这里最多显示四条线,因为fmts中只有四个元素,若要显示更多值,在fmts添加元素即可"""
def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,
ylim=None, xscale='linear', yscale='linear',
fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,
figsize=(4, 3.5)):
# 增量地绘制多条线
if legend is None:
legend = []
"""使用svg格式在Jupyter中显示绘图"""
display.set_matplotlib_formats('svg')
self.fig, self.axes = plt.subplots(nrows, ncols, figsize=figsize)
if nrows * ncols == 1:
self.axes = [self.axes, ]
# 使用lambda函数捕获参数
self.config_axes = lambda: set_axes(
self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)
self.X, self.Y, self.fmts = None, None, fmts
def add(self, x, y):
# 向图表中添加多个数据点
if not hasattr(y, "__len__"):
y = [y] # 没有__len__属性表示我们只要画一条线
n = len(y) # 需要画n条线
if not hasattr(x, "__len__"):
x = [x] * n # x轴,因为我们要画n调线,所以对应n个x轴
if not self.X:
self.X = [[] for _ in range(n)]
if not self.Y:
self.Y = [[] for _ in range(n)]
for i, (a, b) in enumerate(zip(x, y)):
if a is not None and b is not None: # 我们画n条线的数据保存在X和Y中
self.X[i].append(a)
self.Y[i].append(b)
self.axes[0].cla() # 清理当前轴
for x, y, fmt in zip(self.X, self.Y, self.fmts): # 画n条线
self.axes[0].plot(x, y, fmt)
self.config_axes() # 设置轴的参数
display.display(self.fig) # 显示当前fig
# 清除当前图像,设置wait=True表示直到有一个图像可以替代当前图像
display.clear_output(wait=True)
'''这个是我们为了在训练过程中存储某些数据而定义的一个类'''
class Accumulator:
def __init__(self, n):
self.data = [0.0] * n
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
def __getitem__(self, idx):
assert idx<len(self.data)
return self.data[idx]
'''求正确预测数量'''
def accuracy(y_hat, y):
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
y_pre = y_hat.argmax(axis=1)
cmp = (y_pre.type(y.dtype)==y)
return float(cmp.type(y.dtype).sum()) # 返回正确预测数量
训练部分代码
import torch
import torchvision
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
def main():
'''
(0.5, 0.5, 0.5), (0.5, 0.5, 0.5)表示CIFAR10数据集每个通道的均值和标准差都为0.5
根据channel数做归一化,使每个通道服从均值为0,标准准差为1的正态分布,这是在视觉中处理图片常用手段。
在使用该方法之前必须将像素值转换为tensor类型
'''
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 50000张训练图片
# 第一次使用时要将download设置为True才会自动去下载数据集
train_set = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=256,
shuffle=True, num_workers=0)
# 10000张验证图片
# 第一次使用时要将download设置为True才会自动去下载数据集
val_set = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
val_loader = torch.utils.data.DataLoader(val_set, batch_size=5000,
shuffle=False, num_workers=0)
val_data_iter = iter(val_loader)
val_image, val_label = val_data_iter.next()
# classes = ('plane', 'car', 'bird', 'cat',
# 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
net = LeNet()
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.005)
# ----------------------
num_epochs = 10
animator = Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['train loss', 'train acc', 'vail acc'])
num_batchs = len(train_loader)
device = "cuda:0" if torch.cuda.is_available() else "cpu"
print("device INFO:", device)
net.to(device)
val_image, val_label = val_image.to(device), val_label.to(device)
net.train()
for epoch in range(num_epochs): # loop over the dataset multiple times
metric = Accumulator(3)
#running_loss = 0.0
for step, data in enumerate(train_loader, start=0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = loss_function(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
#running_loss += loss.item() * inputs.shape[0]
with torch.no_grad():
metric.add(loss.item()*inputs.shape[0], accuracy(outputs, labels), inputs.shape[0])
if (step+1) % (num_batchs // 5) == 0 or step == num_batchs - 1:
train_l = metric[0]/metric[2]
train_acc = metric[1]/metric[2]
animator.add(epoch + (step + 1) / num_batchs,(train_l, train_acc, None))
outputs = net(val_image)
predict_y = torch.max(outputs, dim=1)[1]
vail_acc = torch.eq(predict_y, val_label).sum().item() / val_label.size(0)
animator.add(epoch + 1, (None, None, vail_acc))
print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, '
f'vail acc {vail_acc:.3f}')
print('Finished Training')
# 保存权重参数
save_path = './Lenet.pth'
torch.save(net.state_dict(), save_path)
开始训练
main()
输出结果:

这是在CIFAR10数据上训练的结果,只训练了10个epoch,总体来说效果有点差,没有在Fashion-MNIST训练效果好,这是因为CIFAR10数据集更加复杂,而且LeNet模型整体拟合能力也不强的原因吧,具体参数我也没怎么调。在模型训练过程我们设置了在训练完成后保存了模型的参数,如下图所示:

其中.pth文件就是我们报错的权重参数。
import torch
import torchvision.transforms as transforms
from PIL import Image
def main_predict():
transform = transforms.Compose(
[transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
net = LeNet()
net.load_state_dict(torch.load('Lenet.pth'))
im = Image.open('1.jpg')
im = transform(im) # [C, H, W]
im = torch.unsqueeze(im, dim=0) # [N, C, H, W]
with torch.no_grad():
outputs = net(im)
predict = torch.max(outputs, dim=1)[1].numpy()
print(classes[int(predict)])
上面这部分就是预测代码部分。
运行代码:
main_predict()
这里就没有运行结果了哈,大家如果想自己做预测的话,注意下图片路径就行了哈。
总结
以上就是本次博客的内容,主要并不是想要介绍LeNet网络,更多只是读代码,找一些Trick并做一些笔记供自己以后参考。