干货!神经网络架构的快速性能估计方法的衡量
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

如何高效、准确地对神经架构进行性能估计是神经网络架构搜索(NAS)的一大关键问题。为了降低估计架构性能所需的训练成本,单次评估器(One-Shot Estimator, OSE)通过在所有架构之间共享一个“超网络”的参数来分摊架构训练成本。
最近也有研究者提出了完全不需要训练的零样本估计器(Zero-Shot Estimator, ZSE),以进一步降低架构评估成本。尽管这些评估器的效率很高,但它们的评估质量未得到充分的衡量和分析。本工作在五个不同大小、性质的搜索空间(NAS-Bench-101/201/301, NDS ResNet/ResNeXt-A)上衡量和分析了OSE 和ZSE的评估质量,并对评估器的应用和未来研究给出了建议。
本期AI TIME PhD直播间,我们邀请到华为-清华联合培养博士后——宁雪妃,为我们带来报告分享《神经网络架构的快速性能估计方法的衡量》。

宁雪妃:
2016年和2021年从清华大学电子工程系获得学士、博士学位。目前在华为-清华联合培养博士后工作站从事博士后研究。
1
Analysis Framework
What Does This Work Cares About?
神经网络架构搜索(Neural Architecture Search, NAS)算法通常由下图中三个部分组成:搜索空间,搜索策略和架构性能评估策略。
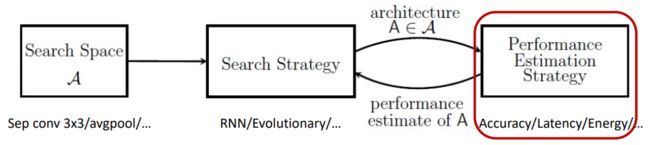
在对架构进行性能评估时,传统的做法需要将这个架构在训练集上训练并在验证集上测试得到精度作为架构的评估结果。由于单个架构训练开销较大,且搜索过程中待评估的架构数量较多,该估计策略的开销是比较大的。
所以,研究者们普遍关注如何使得架构评估变得更加高效,从而让整体的架构搜索过程变得更快。而我们关注的核心问题是:当前主流的高效性能评估策略的评估质量如何?
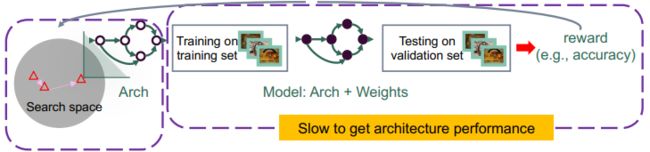
Analysis Target 1: One-Shot Estimators
我们的第一类分析对象是单次评估器(One-Shot Estimator, OSE)。该类评估器基于权重共享(parameter sharing)的策略,在不同架构之间共享权重参数,达到高效训练和评估的目的。
一般来说,单次评估策略会构建一种超网络(supernet),该超网络包含搜索空间里所有架构的权重,在评估一个架构性能时,我们只需要使用该架构在超网络中所对应的权重做推理即可,不需要再单独训练该架构。而在超网络的训练过程中,我们每次采样一个架构来更新超网络的权重。

Analysis Target 2: Zero-Shot Estimators
单次评估器是避免了单独训练每个架构,把训练成百上千个待评估架构的开销变成了训练单个超网络的开销,所以被称为单次评估器。
进一步地,研究者开始关心,能否进一步降低架构评估策略中的训练开销?甚至完全不需要训练就能够评估一个架构的潜力?近期的研究提出了一种训练开销为零的评估策略,即零次评估器(Zero-Shot Estimator, ZSE)。
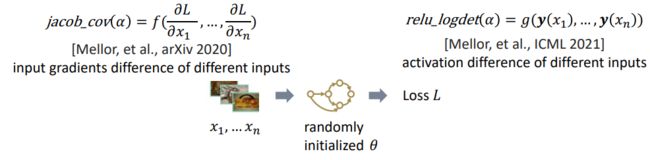
零次评估器的核心思想是在随机初始化的网络上使用高阶的统计信息来估计架构的潜力,这其中又可以按照统计信息的层级分为两类,分别是参数层级(parameter-level)的零次评估器和架构层级(architecture-level)的零次评估器。
下图展示的是参数层级的零次评估器,这类评估器会把逐个参数的敏感度进行计算后相加作为架构评估分数。

另一类零次评估器,基于架构层级分析的零次评估器会衡量在输入不同数据时反传到输入的梯度或网络中激活的差异性。
其认为如果不同输入数据得到的输入梯度或网络激活差异大,说明这个随机初始化网络对不同输入数据的区分能力较好。
而且认为随机初始化网络的区分能力也能够反映这个架构在经过训练后的区分能力,可以作为这个架构的评估分数。
Why This Work?
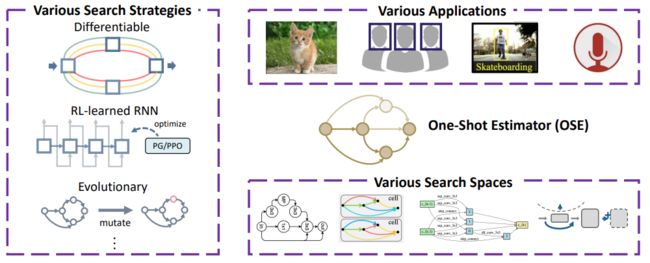
单次评估器是一种主流常用的高效评估策略,它可以适配不同的搜索空间,搭配不同的搜索策略,针对不同的应用场景使用。
然而,单次评估器并不完美,它不一定能很好的辨别的架构好坏,给出完全相关的架构排序。而了解其区分能力在不同空间上的表现,以及会出现怎么样的误差,可以帮助我们更好地提升单次评估器的准确性。
因此,我们这个工作对单次评估器做了全面衡量和分析。
另一方面,零次评估器是非常高效的,但是其合理性和是否足以在不同空间上均提供较好的评估性能仍然存疑。
比如,将所有参数的敏感性求和来作为架构的评估分数是否真的能够反映架构的好坏?不同零次评估器高低估哪些架构?我们该往哪些方向进一步提升零次评估器?

目前已有的针对高效评估器进行分析的工作还不够充分。比如,下图中两个工作仅在单个搜索空间上进行了衡量和分析,且没有清晰地展示单次评估器会产生的具体错误,也没有对产生错误的原因做进一步的探讨。
因此,我们进行了系列更为全面深入的实验研究,将单次评估器和零次评估器的工作放在一起对比,揭示了其目前仍存在的问题。

Analysis Benchmarks
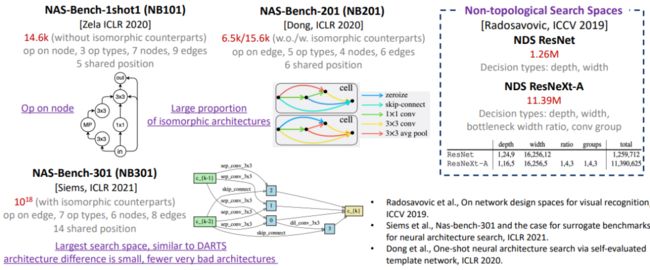
我们在5种NAS基准集对应的搜索空间上进行了实验,包括3个拓扑搜索空间和2个非拓扑搜索空间。
这5个空间具有不同的大小,和差异较大的性质,这使得我们的衡量分析更全面且具有代表性。
Analysis Aspect
我们利用多种指标,从多个角度对高效架构评估器进行了分析。首先是,对于一组架构,高效评估器给出的架构排序和它们真实排序的相关性。

我们还进一步研究了评估器对顶端架构和底端架构的区分能力,顶端架构指的是性能较好的架构,而底端架构指的是性能较差的架构。

此外,我们还分析了哪些架构是会被评估器低估或高估,并通过分析发现了单次评估器对架构的排序性能是会随着其他的一些因素而发生改变的。

Analysis Framework
下图总结了上述的分析要素,其中,分析目标包括单次评估器(OSE)和零次评估器(ZSE)。分析的搜索空间共5个,包括3个拓扑空间和2个非拓扑空间。分析层面包括排序相关性、对顶端/底端架构的区分能力、排序偏差、误差。

2
Evaluating One-shot Estimators (OSEs)
How training time influences the ranking quality?
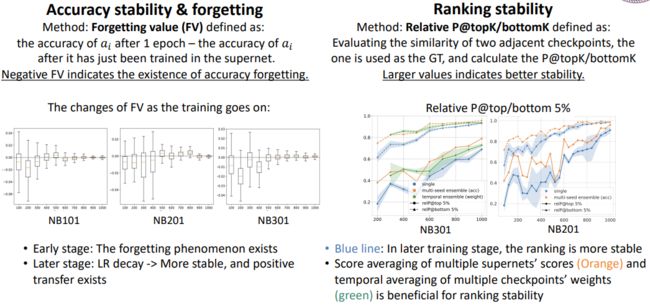
在下图中,我们可以看到,在除NB101外的4个搜索空间上,OSE排序性能随着训练epoch增加持续提升,并且相对区分顶端架构而言,更擅长区分较差的架构。这可以从紫色虚线和紫色实线的对比中看出,虚线代表P@bottom 5%即对底端较差架构的区分能力,而实线代表P@top5%即对顶端架构的区分能力。
在nb101上现象不一样,我们在文中也有分析这个区别的原因。另外一些观察包括,我们发现在NB301上,使用单次评估器推理得到的验证记 loss作为评估分数,会比使用验证集 accuracy作为评估分数有明显更好的排序质量,这可能是因为301上架构之间accuracy区别较小,而loss携带了更多的关于置信度的信息。

我们对OSE的估计偏差,即OSE对哪些架构会高估或低估,进行了分析。具体来说,我们从复杂度层面(complexity-level)和操作符层面(operation-level)进行分析。下图展示了一部分结果,比如下图左边展示,单次评估器会在超网络的训练前期严重高估复杂度较小的架构,并低估复杂度较大地架构。具体的衡量方法和分析可以参加我们的文章和代码仓库。

此外,我们也衡量了单次评估器精度的稳定性和排序结果的稳定性。下图展示出,随着超网络训练越充分,单次评估器给出的精度和排序都在变稳定。一些集成方法可以改善稳定性,比如独立训练三个超网络并对它们的分数进行平均,或者训练一个超网络平均几个不同时间点的权重(时序权重平均),都能提升OSE排序的稳定性。
3
Improving One-shot Estimators (OSEs)
Analyzing the problems of OSEs
我们首先总结了OSE三方面的问题如下:
1.训练超网络遵循了一个随机采样训练的过程,每一个训练迭代会随机采样一个架构,然后只更新这个架构在超网络里对应的权重。这样一个随机采样训练的过程是会带来一定的时序不稳定型。
2. 超网络训练时不够合理的架构采样策略导致了超网络排序的偏差。这又分为两类,一类是某些架构需要更高的采样概率才能使其在共享权重训练时的相对排序与其单独训练时相匹配,比如前面提到过的复杂度较高的架构可能需要更多的训练迭代才能训练充分。第二类是架构们确实从不公平的分布里采样出来,也就是由于采样方式的不合理,有些架构本不该、但却有着更高的等效采样概率。
3. 在前两个原因之下的本质原因还是在架构的参数共享,一些架构在某些操作位置期望的权重值可能差异很大,但是却被要求共享权重。也就是说虽然共享权重是单次评估加速的来源,其也不可避免地带来一定评估的偏差。如何更好地权衡单次评估的效率和相关性是值得研究的。
下面给出了两个例子,分别从第二个和第三个问题着手改进单次评估器。
Example of Direction 2: Improving the sampling fairness
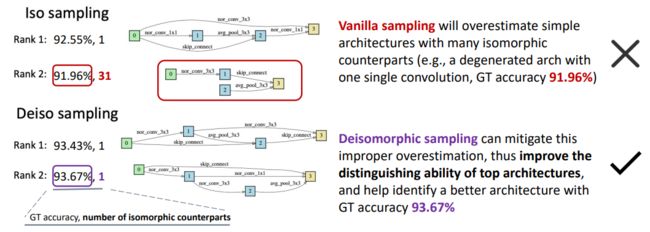
我们提出了一个去同构采样(Deiso sampling)的策略,实验发现该策略能在同构架构对较多的空间上(比如NB201),很大程度地提高对前端架构的排序性能。我们分析,这是因为同质架构在所有架构共用的参数上(比如Stem、FC、和预处理层参数)有着一样的梯度。所以,如果不进行去同构采样,由于一些非常简单的退化架构(如下图所示的,每个单元Cell只包含一个简单的Conv3x3)有着较多的同质架构,这些共用参数的优化方向会被这些简单架构的梯度方向所主导。在这种情况下,OSE会极度高估同构架构数多的同构架构组,比如下图中所示的Iso sampling所训练的OSE在全空间认为第二好的架构就是一个退化架构,其Cell只包含一个3x3卷积,且在空间中有着另外31-1=30个架构与其同构。而使用去同构采样来训练OSE很有效地缓解了这种架构级别的高估现象,并且能成功找到GT accuracy更高的架构 (93.43% 93.67% V.S. 92.55%, 91.96%)。
Example of Direction 3: Reducing the sharing extent
为了降低OSE的参数共享程度,我们进行了一些搜索空间剪枝尝试,包括剪掉操作选择,和按照One-shot分数剪掉一些One-shot分数较低的架构。我们发现One-shot搜索空间剪枝能带来较为一致的排序性能提升。具体来说,就是使用One-shot分数做搜索空间剪枝、再在剪完的搜索空间上采样架构并继续训练超网络。我们发现,在剪枝完的搜索空间上训练后的OSE,相比在整个空间上训练的OSE有着较大的排序性能提升,尤其是在前端架构上。这是因为,经过搜索空间剪枝让空间里的架构数变少后,超网络的共享程度变小,在这个子空间上的排序性能便会提升。
4
Evaluating Zero-shot Estimators (ZSEs)
Evaluation of Parameter-level ZSEs
对于零次评估器中的第一类——在参数级别进行分析的零次评估器(如下图所示),我们发现它们的性能存在不足。其排序性能在拓扑搜索空间上甚至不能超过直接使用架构的参数量或者计算量进行排序。

这些评估器还有着明显的评估偏差,例如,它们更偏向于不包含skip connection的线性架构。这是因为这样的架构存在梯度爆炸现象,而梯度越大,参数级别的敏感性也就越大,零次评估器就会误认为这些架构的性能较好。而实际上这些架构由于梯度爆炸等原因,实际效果并不好。

Evaluation of Architecture-level ZSEs
以下是我们发现的有关基于架构级别分析的零次评估器的部分知识,和这些知识所启发的应用研究建议:
在拓扑搜索空间上有着相对好的整体排序相关性。但是它们不恰当地偏好较小的卷积核。比如如下图所示,jacob_cov 和 relu_logdet选出的最优架构包含很少的3x3卷积和很多的1x1卷积。这样的架构感受野不够好,所以真实效果(GT accuracy)不会很高。这也解释了为什么jacob_cov, relu_logdet虽然有着较好的整体排序相关性,但是对前端架构的区分能力差 (P@topK很低)。可能在实际应用中,给它们集成一些做感受野分析的零次评估器能得到更好的评估效果。
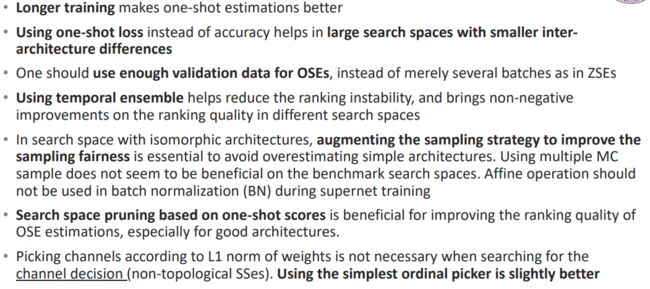
在不同的搜索空间中,最佳的ZSE是不同的。如何设计或集成出在不同空间上都有着较好表现的零次评估器是值得研究的问题。目前来说:
Relu_logdet在3个拓扑搜索空间上表现最好。
Synflow在2个非拓扑搜索空间上表现更好。
大多数ZSE对输入分布不敏感 (使用随机高斯/均匀噪声作为网络输入数据能得到非常相似的架构排名)。是否可以将零次评估器用在跨任务NAS中是值得探究的问题。

5
Summary
给出了针对高效性能评估器多方面特性的分析框架和工具
全面衡量对比了OSE和ZSE的排序质量,分析它们的评估偏差
给出了OSE的应用和研究建议
给出了ZSE的应用和研究建议

我们的poster较为扼要的给出了关键知识的highlight,欢迎大家查看。

提
醒
论文题目:
Evaluating Efficient Performance Estimators of Neural Architectures
论文链接:
https://proceedings.neurips.cc/paper/2021/file/65d90fc6d307590b14e9e1800d4e8eab-Paper.pdf
点击“阅读原文”,即可观看本场回放
整理:林 则
作者:宁雪妃
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了600多位海内外讲者,举办了逾300场活动,超170万人次观看。

我知道你
在看
哦
~
![]()
点击 阅读原文 查看回放!