时间序列问题案例分析Kaggle M5 Forecasting(代码+数据)
目录
- 0.案例介绍
-
- 0.1 数据
- 0.2 评价指标
- 0.3 方法论
- 1. 数据EDA
-
-
- 1.探索性数据分析
-
- 数据 First Look(类型,每列的意义,目标值)
- 数据检查和清洗(主键判重、空值,异常值检测)
- 异常值检测
- 趋势作图
- Downcast
- 提取时间相关特征
- 小结
- 作业
- 1.x 构建树模型解决方案
-
- 2. 特征工程
-
- 2.1 特征构建(重要)
- 2.2 特征选择
- 2.3 特征编码
- 3.建模预测
- 4.误差分析
-
- 4.预测结果产出
- 5.误差分析及模型解释
- 我的note
- 参考资料
Markidakis竞赛(又称M竞赛或M-Competitions),是由预测研究员Spyros Makridakis领导的团队组织的一系列公开对于时间序列预测的竞赛,旨在评估和比较不同预测方法的准确性。
每一届均是真实数据,其实验方案可用于测试真实的业务。
M5是最近的一次比赛,目标:预测零售巨头沃尔玛在未来28天的销量,kaggle官网下载数据地址。

0.案例介绍
0.1 数据
我们正在处理42,840个分层时间序列。数据是从美国3个加利福尼亚州(CA),德克萨斯州(TX)和威斯康星州(WI),7个部门的3049种单独产品中获得的。
这里的“分层”表示可以在不同级别上汇总数据:商店级别,部门级别,产品类别级别和州级别。销售信息可以追溯到2011年1月至2016年6月。除了销售数量,我们还提供了有关价格,促销和节假日的相应数据。
注意:大多数时间序列数据都包含零值。

层级关系为 State->Store->Category->Department->item,如上图所示。
The historical data range from 2011-01-29 to 2016-06-19.数据时间范围: 2011-01-29 to 2016-06-19。

0.2 评价指标
RMSSE
探索性数据分析(Exploratory Data Analysis,简称EDA)
0.3 方法论
- 数据EDA -> 特征工程 -> 建模训练 -> 预测结果产出 -> 误差分析及模型解释
- 特征工程
- 建模训练 -> 预测结果产出 -> 误差分析及模型解释
- 预测结果产出 -> 误差分析及模型解释
- 误差分析及模型解释
如果单纯参加比赛的话,只需要进行前4步就可以了。
- 数据EDA->特征工程->建模训练->预测结果产出->误差分析及模型解释
- 特征工程:选定预测输出策略;常见特征的生成;特征选择;类别型变量编码
- 建模训练:模型选择(如何兼顾效果和速度),AutoML
- 误差分析:Feature importance,shaply value
1. 数据EDA
1.探索性数据分析
数据 First Look(类型,每列的意义,目标值)
大致看一下数据的大小,列名、内容、数据类型
# 读入数据
import pandas as pd
train = pd.read_csv('filename.csv')
# 检查数据基本信息
train.shape
train.sample()
train.dtypes
数据检查和清洗(主键判重、空值,异常值检测)
# 确定主键后按照主键去重,判断数据的 Uniqueness
train[train.duplicated(subset=['Store', 'Date'])]
# 检查数据空值,并按照要求填充空值
train.isna().sum()
train.fillna(0, inplace=True)
# 查看数据的数值分布
train.describe()
异常值检测
是一个大的课题,后续为专门梳理一篇博客来介绍
Python有专门的异常值检测库:Python Outlieer Detection(PyOD)
通过调用API的方式,来进行异常值检测。
例:

- 销量中有很多0,面对这种销量在现实项目中,先去判断是不是能用业务理解去解释这些0。比如,在过去某便利店的销量预测项目中,发现扑克牌在按照天维度去预测的时候会有大量的0,一周可能只会在某几天卖出2-3副扑克牌,但是如果巧妙的将客户的需求从按照日维度预测未来1-28天,变成扑克牌品类按照周维度去预测,可能在周维度上每周扑克牌销量是稳定恒定值。
- 在kaggle比赛或者没有业务的深度参与的项目中,我们还能用一些所谓的"denosing"方法,去还原,平滑这些销量,并利用平滑完后的销量去做后续的特征工程的处理。
- 但作为一个实战项目,不会轻易去denoise
趋势作图
# 1号店的销量随时间的图像
seclect_store = train[train['Store']==1]
select_store[['Date', 'Sales']].plot(x='Date', y='Sales', title='Store1', figsize=(16, 4))

- 目标值的趋势
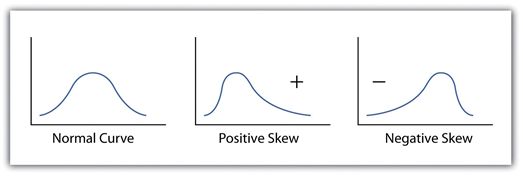
- 目标值的分布情况,观察目标值的分布和统计情况,可以确定适用于哪种模型或者loss function进行训练,当服从高斯分布的时候,一般用RMSE的loss function。统计学有个概念叫偏度,用来描述分布情况。
- Log1p, box-cox
# 目标值 Sales 分布曲线
for i in ['Sales']:
sns.histplot(data=train[i], kde=True)

Downcast
5000万行以下的数据,用pandas是完全没有问题的。再大的话,比如8000万*40的数据,则需要spark分布式操作,或者用Downcast方法。
当数据量太大,又只能用pandas处理的时候,需要用一些Downcast手段,去把项目的内存拉小,
对于比较小的数字,比如32,达不到2^8,故没有必要用64位来存储,这就是可以降低内存的手段。根据数字的大小,适度转为int8或者int16,避免浪费。
def downcast(df):
cols = df.dtypes.index.tolist()
types = df.dtypes.values.tolist()
for i,t in enumerate(types):
if 'int' in str(t):
if df[cols[i]].min() > np.iinfo(np.int8).min and df[cols[i]].max() < np.iinfo(np.int8).max:
df[cols[i]] = df[cols[i]].astype(np.int8)
elif df[cols[i]].min() > np.iinfo(np.int16).min and df[cols[i]].max() < np.iinfo(np.int16).max:
df[cols[i]] = df[cols[i]].astype(np.int16)
elif df[cols[i]].min() > np.iinfo(np.int32).min and df[cols[i]].max() < np.iinfo(np.int32).max:
df[cols[i]] = df[cols[i]].astype(np.int32)
else:
df[cols[i]] = df[cols[i]].astype(np.int64)
elif 'float' in str(t):
# float 16不能被pyarrow to parquet 所以全部转成float32
if df[cols[i]].min() > np.finfo(np.float16).min and df[cols[i]].max() < np.finfo(np.float32).max:
df[cols[i]] = df[cols[i]].astype(np.float32)
else:
df[cols[i]] = df[cols[i]].astype(np.float64)
elif t == np.object:
if cols[i] == 'date':
df[cols[i]] = pd.to_datetime(df[cols[i]], format='%Y-%m-%d')
else:
df[cols[i]] = df[cols[i]].astype('category')
return df
提取时间相关特征
df['Year'] = df['Date'].dt.year
df['Month'] = df['Date'].dt.month
df['DayOfWeek'] = df['Date'].dt.dayofweek
df['WeekOfYear'] = df['Date'].dt.weekofyear
小结
- 了解常见真实数据
- 了解数据进行探索性分析的方法论
- 能独立运用一些python可视化工具进行各类分析作图
作业
- 运行目前的EDA代码,增加更多方向和维度的一些数据探索性分析,例如周一-周日每天的销量分布情况,节假日和非节假日(event)在不同维度上的销量分布情况,可以尝试用不同的画图方式和图形表示。
- 作为一个完整的预测,如何建立未来的数据(1942-1969)?
- 拿出若干条时间序列,用过去学过的传统时序算法进行建模和回测,例如Prophet, DeepAR,看一下最后的RMSSE score和训练时长情况。
1.x 构建树模型解决方案

- 直接多步骤预测
prediction(t+1) = model1(obs(t-1), obs(t-2), ..., obs(t-n))
prediction(t+2) = model2(obs(t-2), obs(t-3), ..., obs(t-n))
- 对于每个forecast horizon都有一个模型,那么每个模型的特征必然不会是相同的了。
- 缺点在于可能会出现较高的方差,特别是如果我们要预测的时间步长比较长的情况下,比如我们要预测未来100个时间步骤,则第100个时间步骤使用的最近的一样观测样本是100个时间步之前的,我们知道,周期越接近当前时间点的滞后特征预测效果越好,间隔时间越长效果越差。
- 递归多步预测
prediction(t+1) = model(obs(t-1), obs(t-2), ..., obs(t-n))
prediction(t+2) = model(prediction(t+1), obs(t-1), ..., obs(t-n))
如果 model 是一个线性 model,看起来不太会有 bias;但是如果不是,bias 会变的越来越大
- ⭐优点:只需训练一个模型,很省时间和资源 对于 M5 这种有几千万条时间序列的大项目很友好
- ⭐缺点:由于使用预测代替真实值,因此递归策略会累积预测误差,即递归策略的偏差比较大,从而随着预测时间范围的增加,模型的性能可能会迅速下降。
- 直接递归混合策略
prediction(t+1) = model1(obs(t-1), obs(t-2), ..., obs(t-n))
prediction(t+2) = model2(prediction(t+1), obs(t-1), ..., obs(t-n))
为什么会有上述三种策略呢?
- 本质原因是传统的机器学习算法无法正常处理多输出问题,多步预测的本质是多输出,我们需要多输出模型才能在一个模型里预测多个标签,比如 预测未来的 3 步是一个 3 输出模型,这个概念就类似于我们的多标签分类、多标签回归的概念。
- 实际上针对于直接预测法,就是一种常见的使用传统的机器学习算法解决多标签问题的转化方法,而递归预测法本质上还是普通的简单的单标签问题。
- 多输出策略
prediction(t+1), prediction(t+2) = model(obs(t-1), obs(t-2), ..., obs(t-n))
- 神经网络可以打破这样的限制,nn 可以非常灵活的支持多输入或者多输出的形式
- seq2seq 结构考虑输出的标签之间的序列依赖性.

2. 特征工程
一个完整的特征工程可以包括但不限于:
- 特征构建
- 销量预测:历史销量lag,历史销量的统计值(MA),窗口统计值(Window max,min)
- 各类维度表信息的合并(商品,门店,价格,促销,节假日)
- 特征选择
- 去除leakage特征(比如做一个 t+28 的问题,其实不能够看到 t+1 的销量,这就是leak泄露,也就是28天前去预测28天后的,那其实我们训练的时候不能让模型知道前一天的销量,过去一天的信息,要知道过去28的情况,所以要去除可能leak的特征;另外,比如做一个价格的特征,在训练集中可能合并到那一天的总销售额,总销售额=单价*数量,其实这个特征不能用,因为它泄露了那一天实际上卖的数量,所以它是leak的特征。)
- 去除常量(constant)特征(当某个特征所有数据都一样,没有信息增益,该特征对于模型毫无意义,对于树模型做分割的时候,没啥意义。)
- 去除 high correlation 特征(去除相关性高的特征,比如两个特征相关度为1,这会导致对这两个特征分别处理的时候,会得到同样的结果,需要删除其中的一个。)
- 类别型特征的编码
2.1 特征构建(重要)
- Lag特征(历史销量特征,如’lag1’表示过去一天的销量。)
- MA特征
- 一阶差分特征
- Window 统计值特征
- 预防 leakage
# 历史销量lag特征,在已经按照日期排序填充的数据集上利用pandas shift函数完成
df[‘lag1’] = df.groupby([‘store‘, ‘sku’])['Sales'].shift(1)
# 对lag可以取moving average,
# w_avg = w1*(t-1) + w2*(t-2) + w3*(t-3)+ w4*(t-4)
df[‘ma_1_4’] = df[[‘lag1’,’lag2’,’lag3’,’lag4’]].mul([0.4,0.3,0.2,0.1]).sum(1)
# 一阶差分,可以提取增长率的特征
df[‘diff_1_2’] = df[‘lag1’] - df[‘lag2’]
# 窗口统计值
df['rolling_max'] = df[‘Sales'].rolling(window=4).max()
下图中,对于2月19来说,其lag1就是2月18的销量1.0 。

下图中,Lag1是Sales经过一次shift的结果,Lag2是Sales经过两次shift后的结果,MA2是取Lag1以2为窗口数量的滑动平均(MA2是Lag1和Lag2的平均)

Time-Related Features: 时间相关特征
业务相关特征:比如价格、促销,还会衍生出其它相关特征,比如有个特征代表是否是促销,还可以做对于每一天(假如是促销),其上一个促销日的销量,这也是一种Lag特征,只不过执行的Lag是纯统计的无脑的,而现在的聚合逐渐增加了是否是促销,或者是节假日等。
pandas 对时间有非常多的预制写好的功能非常强大的操作,如果有一列是pandas.Datetime的格式,如下面的Date列,就可以提取到时间相关的年月日,甚至它在哪一周,在哪一年。
下面有pandas的官方文档,在下面你可以看到,甚至可以看到它是不是一个月的开始,是不是一个月的结束,是不是一个季度的开始,是不是一个季度的结束,
# 提取时间相关特征
df['Year'] = df['Date'].dt.year
df['Month'] = df['Date'].dt.month
df['Day'] = df['Date'].dt.day
df['DayOfWeek'] = df['Date'].dt.dayofweek
df['WeekOfYear'] = df['Date'].dt.weekofyear
这些时间特征,在我们实际模型训练的时候,该如何使用?
其实它能够反映出销量的季节性,或者时间相关的一些规律性,比如说某一个商品——冰淇淋,可能夏天它的销量比较高,这就是时间相关特征的重要性。

业务相关特征,比如价格、促销等各种各样的业务相关特征,
之后,比如说有一个特征,我能做比如某一天它是促销的情况下,其上一个促销日的销量情况,也可以构架一个lag特征,这个聚合增加了一个是否是促销这个特征,同理,是节假日的某天,也可以与上一个是节假日的某天做lag,而不是节假日的某天,也可以找上一个不是节假日的某天计算lag特征,
也就是有了业务特征之后,你还可以衍生出来更多的东西。
2.2 特征选择
特征选择的好处:
- 简化模型,使模型更易于理解:去除不相关的特征会降低学习任务的难度。并且可解释性能对模型效果的稳定性有更多的把握
- 改善性能:节省存储和计算开销
- 改善通用性、降低过拟合风险:减轻维数灾难,特征的增多会大大增加模型的搜索空间,大多数模型所需要的训练样本随着特征数量的增加而显著增加。特征的增加虽然能更好地拟合训练数据,但也可能增加方差。(特征增多的时候,模型变得越复杂,需要增加更多的样本,如果不增加样本,就容易过拟合。)
# 去除leak的特征,包括Sales总销售额,Sales自己肯定要去除,因为它也是dataframe的一个列;
# 有些人做了log_Sales也要去除,
# Customers:那天来了多少顾客。它也会反应那天卖了多少东西,当前节点去预测未来的时候,不知道未来会有多少顾客,要去除
# Date:需要处理后,才能放入模型,处理方法:把时间格式按照顺序排列,比如2017.2.18为1,依次增加一天加1,也可以去除
# 目标值,datetime值等不需要的特征
excluded_cols = ['Date', 'Sales','log_Sales', 'Customers','PromoInterval','monthStr']
init_cols = whole_df.columns
features = columns_minus(init_cols, excluded_cols) # list1 - list2
# 去除常数项特征,如open全都是1(代表店是开着的状态)
constant_cols = [col for col in features if whole_df[col].nunique() == 1]
features = columns_minus(features, constant_cols)
# 剩下特征区分numeric & categorical
num_features = whole_df[features].select_dtypes(include=[np.number]).columns.tolist()
cate_features = columns_minus(features, num_features)
# num_features可以去计算correlation,默认是pearson correlation
# 而pandas.DataFrame.corr()只能处理数值类的特征,
corr_matrix = whole_df[num_features].corr().abs()
# 选择左上矩阵,目的为了观察哪些是high correlation的
upper = corr_matrix.where(np.triu(np.ones(corr_matrix.shape), k=1).astype(np.bool)) # np.triu选择矩阵的左上
# 去除相关性高于某个threshold的特征,而不能处理类别或者中文类特征,比如中文的省份和另外一列一一对应了,这时候只有把中文省份转为数值,再进行处理,
high_corr_cols = [col for col in num_features if any(upper[col] >= 0.9)]
说明:
- 如果用pandas自带的求特征相关度的corr(),其只能计算数值类的特征,不能计算类别类的特征,需要先将其转为数值;
2.3 特征编码
- 我们拿到的数据通常比较脏乱,可能会带有各种非数字特殊符号,比如中文。而实际上机器学习模型需要的数据是数字型的,因为只有数字类型才能进行计算。
- 根据 categorical column 的意义选择合适的编码器
- 独热编码的缺点:会把特征搞得特别大,有时候与我们特征筛选的意图相违背,而下面的直接转成数字的方式,会更好
# Label-Encoder
from sklearn import preprocessing
label_encoder = preprocessing.LabelEncoder()
# Encode labels in column
for col in cate_features:
train_df[f'{col}_le']= label_encoder.fit_transform(train_df[col])

3.建模预测
经过上述的处理,N 条时间序列数据已经转化为标准的表格类结构化数据(Tabular Data),将其分为合适的训练预测数据进行建模。
- Resampling strategy – Cross-validation or Hold-out validation (如何划分train_data和test_data)
- Model Selection – LGB,XGB,RF(shai你要考虑尝试哪些模型,以及每个模型最后的一个筛选,或做集成)
- Parameter Tuning (参数自动搜索,有现成的工具,比如obtiuna(音),)
- Model Explanation(Feature importance, SHAP Value)
- Ensemble & Stacking
- 定义合适的objective function & metrics (模型的考察指标,如何判断模型好或差,需要一个metrics,比如下面定义的rmspe)
- 选择合适的树的数量 & 大小
- earlystopping (防止过拟合,和神经网络里面的dellport类似)
LightGBM官方文档
# 模型考察指标
def rmspe(y_true, y_pred):
return np.sqrt(np.mean((y_pred/y_true-1) ** 2))
def log_rmspe_lgb(y_true, y_pred):
y_true = np.expm1(y_true)
y_pred = np.expm1(y_pred)
return "rmspe", rmspe(y_true, y_pred), False
# 参数
model_params = {
'boosting_type':'gbdt',
'objective': 'rmse',
'num_leaves': 127,
'learning_rate': 0.15,
'n_estimators': 200,
'feature_fraction': 0.8,
'bagging_fraction': 0.8,
'max_bin': 100,
'max_depth':9,
}
# 模型训练
target = 'log_Sales'
m = lgb.LGBMRegressor(**model_params) # 定义你的 LGB
features = num_features + cate_features
m.fit(X=train_df[features], y=train_df[target],
eval_set = [(val_df[features], val_df[target])],
eval_metric=log_rmspe_lgb,
categorical_feature=cate_features,
early_stopping_rounds=15,
verbose=10,
)
# 在测试集上进行预测输出
test_df['log_pred'] = m.predict(test_df[features])
test_df['pred'] = np.expm1(test_df['log_pred'])
4.误差分析
4.预测结果产出
5.误差分析及模型解释
我的note
cmd中输入 jupyter notebook ,把弹出到word中的链接复制到地址栏,打开即可,代码放在机器学习算法课件
参考资料
[1] Kaggle知识点:数据分析EDA;