反向传播算法(过程及公式推导)_反向传播(BP)算法的数学原理
由于平台对公式支持较少,本文用了少量LaTeX语法来编辑公式,其中
a_j 表示以j为下标的代数式
a^j 表示以j为上标的代数式
a_j^l表示以j为下标、l为上标的代数式
\sum_j 表示对所有以j为下标的元素进行求和
b/a 表示以b为分子,a为分母的分数
============================================
欢迎关注本公众号。
============================================
在前面的文章(从神经网络识别手写体数字开始)中,我们已经了解了如何用梯度下降法来学习神经网络的权重和偏置参数,但在梯度下降算法中所依赖的损失函数梯度(偏微分)计算方法并没有介绍。本文详细介绍神经网络损失函数的梯度计算方法,即反向传播算法(简称BP算法)。
BP算法最早提出于上世纪七十年代,但直到1986年才因《自然》上的一篇论文被学术界广泛认可,这篇论文就是大名鼎鼎的《Learning representations by back-propagating errors》,作者是David Rumelhart, Geoffrey Hinton, and Ronald Williams,其中Geoffrey Hinton就是2018年图灵奖得主之一。这篇论文介绍了一系列神经网络模型,证实了反向传播算法在这些神经网络中高效的训练/学习性能,使得利用神经网络解决一系列过去无解的难题成为可能。直到现在,BP算法仍然是训练神经网络模型的基础算法。
BP算法涉及大量的数学推导,如果对数学不感兴趣但又想学习神经网络,完全可以把BP算法看做一个黑盒来用,而不必关心其推导细节。但是学习BP算法的数学原理,并非无用,相反对我们深入理解神经网络训练的底层原理有着非常重要的帮助。反向传播算法的核心是求解损失函数C关于任一网络权重w(或偏置b)的偏微分∂C/∂w (或∂C/∂b)。该偏微分表达式表示损失函数C的值随权重w或偏置b值变化而变化的变化率。很多时候虽然偏微分表达式看起来非常复杂,但反向传播算法为偏微分表达式中每项的物理含义提供了自然、直观和优美的解释。反向传播算法不仅提供了快速训练神经网络的算法基础,还为我们理解神经网络行为受权重和偏置参数影响的内在机制提供了深刻洞察。换句话说,我们可以通过观察BP算法的公式看到神经网络的行为是如何随着权重w和偏置b的值变化而变化的。
◇ 热身:快速计算神经网络输出值的矩阵表达式 ◇
在正式介绍反向传播算法之前,先回顾一下计算神经网络输出层的矩阵表达式,以方便后续的讨论。

首先介绍权重符号w_jk^l(下标jk,上标l)。该符号表示第l-1层的第k个神经元与第l层的第j个神经元之间连接对应的权重参数。以上图为例,w_24^3表示第2层的第4个神经元与第3层的第2个神经元之间连接的权重。人们可能觉得jk位置互换一下更直观,但为了便于矩阵运算,我们保持下标顺序为jk。
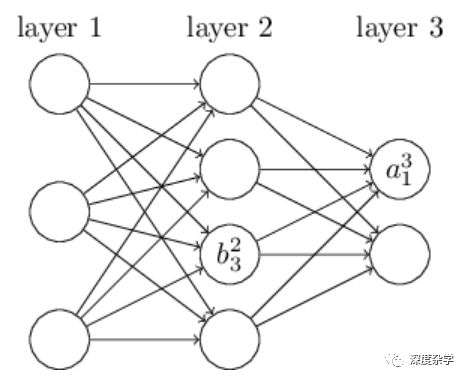
其次介绍神经网络偏置和激活的符号表示。利用b_j^l表示第l层的第j个神经元对应的偏置,a_j^l表示第l层的第j个神经元对应的激活(可以理解为神经元的输出)。上图中的b_3^2表示第2层的第3个神经元对应的偏置,a_1^3表示第三层神经元的第一个神经元对应的激活。
有了上述符号,我们就可以将第l层的第j个神经元的激活a_j^l与前一层(l-1)所有神经元的激活之间建立递推关系,这个递推关系就是所谓的“信息向后传播”机制,具体如公式(23)所示。

其中σ(·)表示某种激活函数,求和部分是针对前一层(l-1)所有神经元激活a_k^(l-1)的加权和。为了将上述公式表示为矩阵形式,我们需要先定义权重矩阵w^l,用来表示所有指向l层神经元的连接权重。矩阵w^l中第j行第k列的元素w_jk^l代表前一层(l-1)的第k个神经元与第l层的第j个神经元之间连接的权重。类似的,我们为每一个层定义一个偏置向量b^l,其中每一个元素b_j^l对应l层第j个神经元对应的偏置;每一层定义一个激活向量a^l,其中每一个元素a_j^l对应l层第j个神经元的激活。
为将公式(23)表示为矩阵形式,还需要对激活函数σ(·)进行向量化,即σ(·)的输入是向量v,激活函数运算法则运用到向量的每一个元素v_j后输出运算后的向量σ(v),其中σ(v)_j=σ(v_j)。例如一个简单的二次函数f(x)=x^2,对f进行向量化后f([2;3])=[f(2);f(3)]=[4;9],直观形式如下图所示:
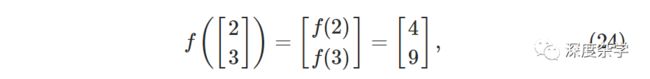
利用向量化的激活函数,我们可以将公式(23)重写为公式(25):
![]()
上式以全局的方式将l层激活(输出)与前一层(l-1)的激活联系在了一起,即只需要用权重矩阵乘以前一层激活向量,加上本层偏置向量,再作用于向量化的激活函数,就可以得到本层激活向量。这种矩阵形式的表达式,不仅使神经网络的表达式更加简洁,还有利于提升计算效率,因为市面上已存在了大量高效的矩阵运算工具库。
在前面定义的基础上,我们再定义另外一个符号z^l≡w^l×a^(l-1)+b^l,用于表示神经网络第l层神经元的权重输入,后面会经常用到这个符号。相应,l层激活向量也经常表示为a^l≡σ(z^l)。z^l的每一个元素可以表示为连加形式,即z_j^l≡\sum_k w_jk^l · a_k^(l-1) + b_j^l,意味着z_j^l就是简单的将第l层第j个神经元的权重输入。定义了以上符号后,就可以上路了。
◇ 关于损失函数的两个基本假设 ◇
反向传播算法的直接目标是计算损失函数C关于每一个权重参数w和偏置参数b的偏微分(偏导数),为此需要针对损失函数C的形式提出两个基本假设。以前文中用到的均方误差损失函数作为示例进行讨论。
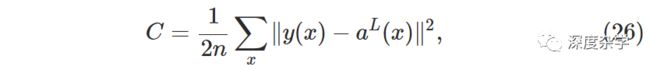
其中n是训练集中的样本数,y(x)是样本x对应的正确答案,L是神经网络的层数,a^L(x)是样本x作为输入对应的激活向量a^L(x)。基于此例,我们给出的关于损失函数C的第一个假设是:C可以写成C=1/n \sum_x C_x的形式,即所有单一训练样例x对应损失函数C_x的加和平均形式。对于公式(26)对应的单样本损失函数为C_x = 1/2 ||y(x)-a^L(x)||^2。这一假设适应于本系列文中的其它损失函数形式。提出这一假设的直接原因是,我们需要首先计算单个训练样本对应的偏导数(∂C_x/∂w和∂C_x/∂b),再通过计算全部样本对应偏导数的平均值(1/n \sum_x ∂C_x/∂w和1/n \sum_x ∂C_x/∂b),最终得到总体损失函数的偏导数(∂C/∂w和∂C/∂b)。下文所有讨论都符合此假设,这样在推导偏导数的时可将下标x省略,需要时再加回来即可。

提出的第二个假设是:损失函数C可以重写为神经网络输出向量的函数形式(如上图所示,个人认为可以将损失函数C看做神经网络训练时的特殊层,即损失函数层)。本文用到的均方误差损失函数即满足此假设,具体来看:
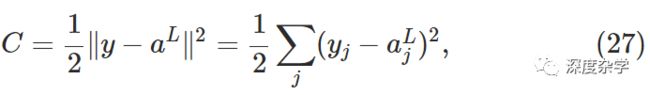
该损失函数可以视作神经网络输出(a_j^L)的函数。有一点需要注意,在神经网络训练过程中,训练样本的标准答案y_j是固定的常数,不可以将损失函数C视作y_j的函数。
哈达玛积(Hadamard Product)s⊙t
反向传播算法中包含了大量的线性代数运算,如矩阵与向量相乘、向量相加等。但哈达玛积并不太常见,其基本思想很简单,即两个向量的哈达玛积是两个向量对应元素之间相乘之后得到的新向量,因此哈达玛积也被称作按元素乘(elementwise product)。s和t是维数相同的向量,其哈达玛积s⊙t的元素就是(s⊙t)_j = s_j×t_j,例如:
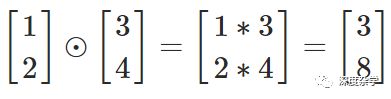
常用的矩阵代码库一般都提供哈达玛积的高效实现,这为实现反向传播算法提供了非常方便的工具。
◇ 反向传播算法中的四个基本公式 ◇
反向传播算法的核心目标是确定如何通过修改神经网络的权重和偏置参数来改变损失函数的值,为此需要计算损失函数对于权重和偏置参数的偏导数。在介绍偏导数的计算方法之前,我们首先介绍一个中间参数δ_j^l,它表示第l层第j个神经元对应的误差(error)。BP算法关键是通过计算各层神经元的误差δ_j^l,来推导出损失函数对于神经网络各层权重和偏置参数的偏导数(∂C/∂w_jk^l和∂C/∂b_j^l)。
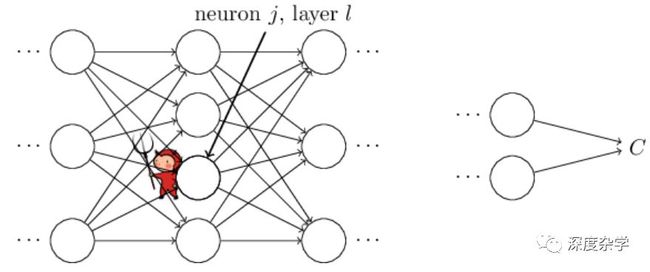
为了更好的理解误差的概念,假设在神经网络的第l层的第j个神经元中潜伏着一个“邪灵”。该“邪灵”通过修改神经元的加权输入值来搞破坏以影响该神经元的输出结果,并通过层层传导影响神经网络的最终输出结果。具体来说,假如某神经元的原加权输入为z_j^l,“邪灵”通过在原加权输入值上加一个误差∆z_j^l,使得神经元的原输出σ(z_j^l),修改为σ(z_j^l+∆z_j^l)。这个修改会层层传导,最后会导致总的损失函数产生变化,变化量为(∂C/∂z_j^l)·∆z_j^l。
现在我们假设这只“邪灵”改邪归正,化身为替天行道的“精灵”,她要通过自己的努力帮助我们改进神经网络,具体来说是找到合适的∆z_j^l以减小损失函数值。在调整时,假如∂C/∂z_j^l的绝对值较大(正数或负数),这个“精灵”可以找一个与∂C/∂z_j^l符号相反的数作为∆z_j^l;如果∂C/∂z_j^l的绝对值变的非常小,就意味着相应神经元的权重已经趋向于最优。因此,∂C/∂z_j^l可以看做是相应神经元误差的量化表示。受这个故事的启发,我们定义第l层第j个神经元对应的量化误差为:
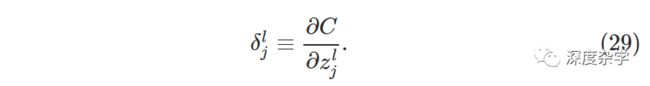
方便起见,我们利用δ^l来表示第l层神经元的误差向量。反向传播算法将给出每一层误差向量的递推公式,然后基于此给出我们真正关心的偏导数(∂C/∂w_j^l和∂C/∂z^l)。
接下来我们将一步一步介绍反向传播算法的数学原理。值得指出的是,要想深入彻底的理解下面的数学公式,需要花一些时间和精力。不过一旦通过努力理解了这些公式,将会得到“守得云开见月明”的丰硕成果。
基本公式一:神经网络输出层的误差向量δ^L,其中输出层误差向量的元素δ_j^L定义为公式BP1:

这是一个非常自然的公式,可以根据神经元误差的定义(公式29)和微分的链式法则直接导出。简单推导过程如下:
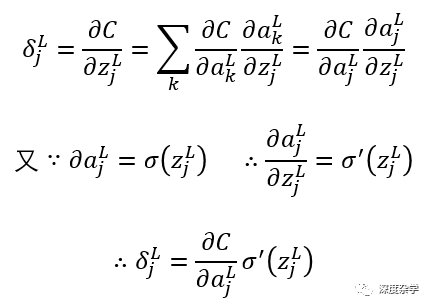
其中L是神经网络的层数,σ(·)是激活函数(具体可以根据特定任务指定任意激活函数)。
公式BP1也有较好的可解释性,∂C/∂a_j^L表示损失函数随着神经网络输出层的第j个神经元输出值变化而变化的快慢,理想的状况就是损失函数的大小与神经元的输出保持独立,也就是损失函数不依赖于输出层神经元的输出,这时候∂C/∂a_j^L会非常小;σ'(z_j^L)则表示神经元输出值随着z_j^L变化而变化的快慢。BP1中的两个数据项都非常容易计算,其中∂C/∂a_j^L的计算依赖于具体的损失函数的形式,只要给定了损失函数该项非常容易计算,例如本文中的利用均方误差(公式26和27)作为损失函数,即C=1/2 \sum_j (y_j - a_j^L)^2,则∂C/∂a_j^L = (y_j -a_j^L),很明显非常容易计算;σ'(z_j^L)的计算依赖于激活函数的选择,例如当激活函数选择Sigmoid函数时,σ'(z_j^L) = σ(z_j^L)(1-σ(z_j^L)),很显然也非常容易计算。BP1给出了输出层任一神经元对应的误差计算方法,为了方便矩阵运算,下面给出神经网络输出层的误差向量计算公式BP1a

其中∇a C是一个向量,第j个元素是∂C/∂a_j^L,可以理解为损失函数C随输出激活变化而变化的速率;σ'(z^L)是向量化的激活函数求导运算。很明显,BP1a与BP1等价,后面我将用BP1代指两个公式。如损失函数是均方误差公式,则∇a C = (a^L - y) ,对应的误差向量的矩阵形式为:
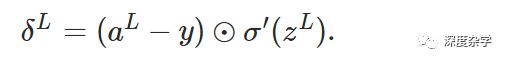
基本公式二:误差的反向传播递推公式,即神经网络第l层神经元误差向量δ^l与第第l+1层神经元误差向量δ^(l+1)之间的关系。直接上公式:
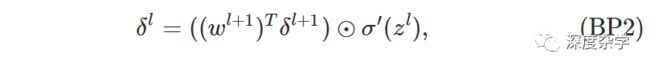
其中(w^(l+1))^T是l层神经元与(l+1)层神经元之间的权重矩阵的转置。这个公式稍微复杂一些,但是也具有良好的可解释性:δ^(l+1)是第l+1层神经元的误差向量,用l层和l+1层之间的转置权重矩阵乘以l+1层的误差向量,可以视作是将l+1层的误差反向传播到l层。再与σ'(z^l)进行哈达玛积,得到l层的输出误差向量。当然这只是一种直观的解释,具体的公式推导方法如下:

上述推导看起来复杂,其实只要掌握了多元函数微分链式法则、矩阵乘法等基础方法就可以很容易的看懂。不过还是建议,自己从头到尾推导一下,理解更为深刻。有了BP1和BP2,我们就可以利用递推法来求解神经网络任意层神经元的的误差向量了,具体来说,首先计算δ^L,再计算δ^(L-1),依次类推,最终可以计算得δ^1。
基本公式三:损失函数相对任一偏置参数b变化而变化的速率,即损失函数关于偏置参数b的偏微分:
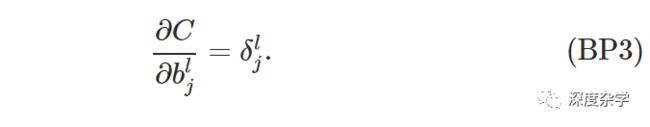
这个公式表明第l层的误差δ_j^l恰好等于∂C/∂b_j^l,而在BP1和BP2中,我们已经详细的说明了如何计算δ_j^l。BP3还可以写为矩阵形式:
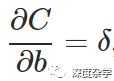
基本公式四:损失函数相对任一权重参数w变化而变化的速率,即损失函数关于权重参数w的偏微分:

上述公式告诉我们,可以通过计算上一层的激活a_k^(l-1)和本层的误差δ_j^l来计算损失函数关于权重的偏微分,而这两项我们已经知道如何计算。上述公式还可以较为形象的重写为下式:

针对单个权重参数的偏微分计算示意图如下图所示:

BP4的结论虽然比较简单,但也需要稍微推导一下,以加深理解:

最终损失函数关于l-1层到l层之间的权重矩阵的偏微分矩阵,如下所示:

到目前为止,已经介绍了反向传播算法的四个基本公式,有了这四个基本公式,我们就可以编写程序对任意损失函数关于权重参数和偏置参数求偏微分了。为了方便大家记忆,下面将四个公式放在一起写一下:

◇ 反向传播算法的形式化描述 ◇
前面介绍的四个公式给出了偏微分的计算方法,下面给出具体的算法描述:
输入x:计算输入层激活向量a^1=σ(z^1)信息传导:计算z^l = w^l · a^(l-1), (a^l = σ(z^l) ,l = 2, 3, ..., L)计算输出层误差向量δ^L:根据BP1计算误差反向传播:根据BP2计算L-1,L-2,...,2层的误差向量输出偏微分:根据BP3和BP4计算损失函数相对每一层权重和偏置参数的偏微分◇ 从全局视角理解反向传播算法 ◇
前面详细介绍了反向传播算法中四个基本公式的数学推导,但有一个问题并没有讲清楚,有心的读者可能会有一些困惑,这就是“反向传播算法到底做了些什么?”,我们虽然讲了很多数学公式,但对如此多矩阵、向量乘法背后的物理意义了解的并不深,需要再深入一些。
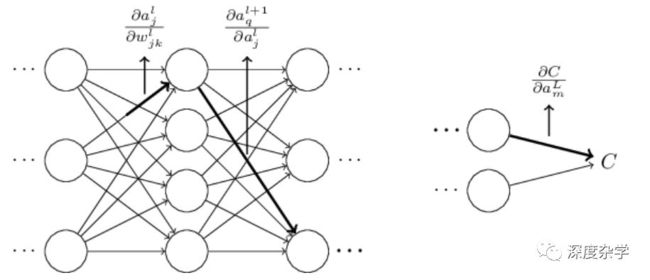
为了直观理解算法的行为,假设我们使神经网络的某一权重w_jk^l变化△w_jk^l,如下图所示:
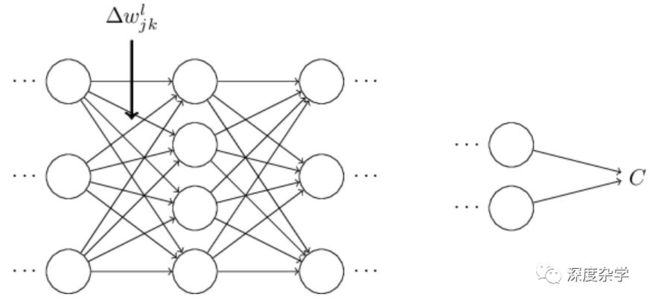
权重的细微变化会使对应神经元的激活输出产生相应的变化△a_j^l,如图:

进而使下一层神经元的输出产生相应变化,如图:

层层影响,最终导致损失函数的变化,如图:
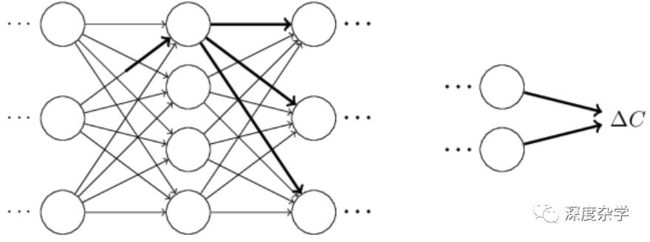
损失函数的变化△C与权重变化△w_jk^l之间的关系,由下式给定:
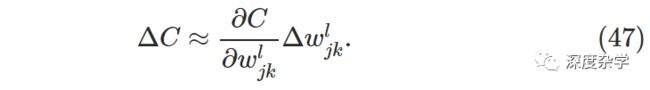
我们可以根据这个公式,通过追踪权重变化的层层传导,进而导致损失函数产生变化的过程,来计算损失函数相对于权重参数的偏导数。具体方法是将传导过程中容易计算的公式表示出来,然后得到∂C/∂w_jk^l的表达式。下面一层一层进行计算:
某一权重参数的微小变化△w_jk^l会直接导致第l层第j个神经元的激活输出产生变化△a_j^l,其表达式如下所示:
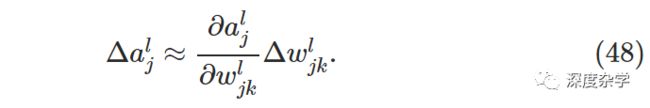
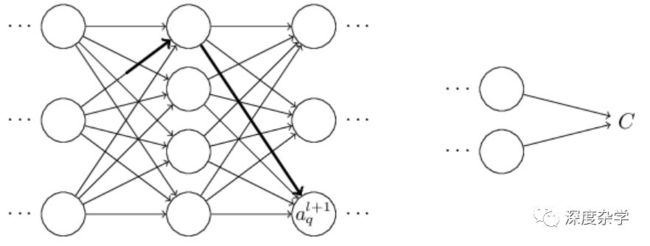
第l层第j个神经元激活输出的变化△a_j^l会引起(l+1)层所有神经元激活输出的变化,本文暂时只讨论其中一个神经元的变化,即a_q^(l+1),公式如下:
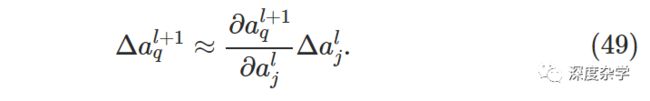
将公式(49)代入公式(48),得如下表达式:
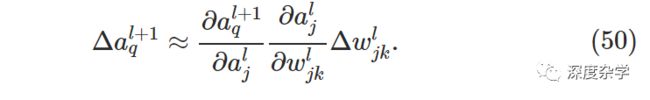
当然,l+1层神经元激活输出的变化还会引起下一层的变化。事实上,可以设想从l层到最后的损失函数,存在一条路径,使变化层层传导,最终使损失函数产生相应的变化。假设传导路径是a_j^l, a_q^(l+1), ...,a_p^(L-2), a_m^(L-1), a_n^L,那么由此路径传导产生的损失函数变化为:
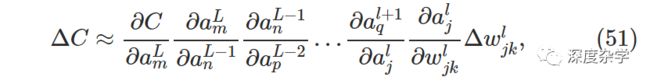
当然从a_j^l到C,还有很多其它路径使损失函数产生变化,为了计算由权重变化△w_jk^l引起的损失函数总的变化,我们需要将所有路径引起的损失函数变化加起来计算,其中路径总数为m×n×p×...×q个,最终变化公式为:

结合公式47和微分的定义,损失函数相对权重w_jk^l的偏微分计算公式可以重写为如下链式公式:
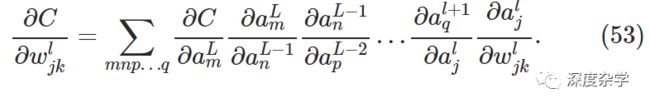
这个公式看起来复杂,但仔细观察公式的构成会发现,损失函数C关于某权重参数w的变化率(偏微分),是由所有从第l层第j个神经元到损失函数C之间路径的变化率因子相加得到的;而每一个路径变化率是由相邻两层神经元之间的边对应的变化率因子相乘得到的;两层神经元之间的边对应的变化因子可以通过直接计算下一层神经元激活关于上一层神经元激活的偏微分得到,即∂a^(l+1)/∂a^l;公式中的∂a^l/∂w_jk^l也可以根据具体激活函数的定义直接计算得到。总体偏导数的计算过程如下图所示:
截至目前,我们利用启发式的方式介绍了修改权重参数对损失函数的影响,在神经网络训练过程中每次对权重参数的修改都会导致损失函数的变化。因为损失函数值是神经网络性能的量化体现,所以目标函数的最优化(最小或最大)就意味着神经网络的性能最优化。对网络权重的不断调整,也就是对网络性能的不断优化,而损失函数关于权重参数的偏微分,就为我们不断调整网络权重参数提供了指导。对于偏置参数也有类似的结论。
通过本文介绍,我们基本了解了神经网络反向传播算法的数学原理,也对其内在物理意义有了一些直观的认识,这也为我们后续深入学习深度神经网络模型、原理以及改进方法奠定了坚实的基础。
再次感谢各位的耐心阅读,也欢迎关注这个更新不太频繁的个人公众号。
