java set源码_Java 源代码解析 | 集合类 | Set
> Set的实现基本上是依靠于相应的Map实现,从某种意义上来说,了解Set,只需要去分析相应的Map就可以了。
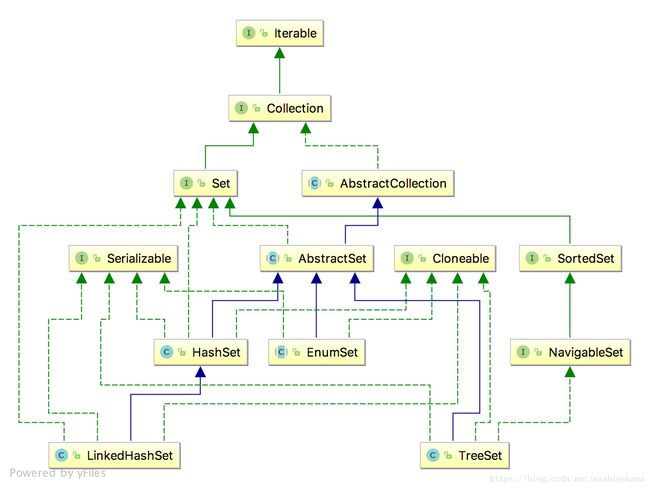
Set实现类的继承关系图
HashSet 源码简要分析
翻开源码我们我可以清楚地看到HashSet中有一个变量map,它的类型是HashMap。不难想到,HashMap的键值是一个不可重复的集合,它恰好可以作为一个Set,也不难理解为什么要叫HashSet。
private transient HashMap map;
public HashSet() {
//在构造方法中,new一个HaskMap对象
map = new HashMap<>();
}
在HashSet中,总共有5个构造方法(包括上面的构造方法)。在其他的构造方法中,也同样是new一个HashMap或LinkedHashMap。
使用HashMap的场景
public HashSet(Collection c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
使用LinkedHashMap的场景
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
增删改查
基本上是调用HashMap所对应的操作方法。增加元素的时候,值传PRESENT给HashMap。
// 用来充当Map键值对中的值
private static final Object PRESENT = new Object();
public boolean contains(Object o) {
return map.containsKey(o);
}
public boolean add(E e) {// 值传PRESENT
return map.put(e, PRESENT)==null;
}
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
public boolean isEmpty() {
return map.isEmpty();
}
public int size() {
return map.size();
}
public Iterator iterator() {
return map.keySet().iterator();
}
public void clear() {
map.clear();
}
从整体上面来看,HashSet是对HashMap的二次封装。关键还是在于HashMap的实现之上。
LinkedHashSet 源码简要分析
它的所有方法以及成员变量如下图所示:
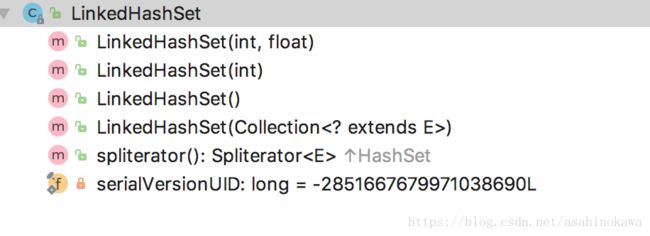 LinkedHashSet继承自HashSet。因此它是一个对HashSet的再次封装。它有5个函数,4个是构造函数。而且这些构造函数都将调用HashSet中的HashSet(int initialCapacity, float loadFactor, boolean dummy)方法。如下:
LinkedHashSet继承自HashSet。因此它是一个对HashSet的再次封装。它有5个函数,4个是构造函数。而且这些构造函数都将调用HashSet中的HashSet(int initialCapacity, float loadFactor, boolean dummy)方法。如下:
public LinkedHashSet(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor, true);
}
public LinkedHashSet(int initialCapacity) {
super(initialCapacity, .75f, true);
}
public LinkedHashSet() {
super(16, .75f, true);
}
public LinkedHashSet(Collection c) {
super(Math.max(2*c.size(), 11), .75f, true);
addAll(c);
}
TreeSet 源码简要分析
先再来单独看看其继承关系:
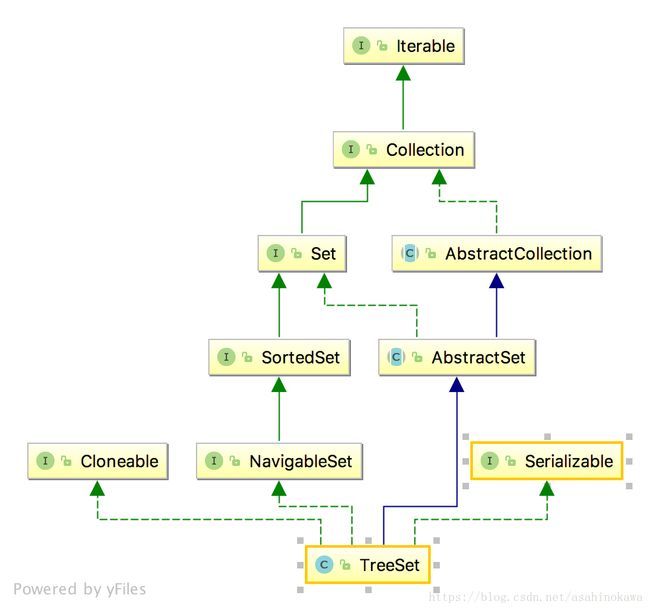 再来看其构造函数与重要的成员变量:
再来看其构造函数与重要的成员变量:
// 应该与上面的HashSet类似,用来存储
private transient NavigableMap m;
// 应该是用来填充键值对中的值
private static final Object PRESENT = new Object();
// 这个方法对我们来说不可见
TreeSet(NavigableMap m) {
this.m = m;
}
public TreeSet() {
this(new TreeMap());
}
public TreeSet(Comparator comparator) {
this(new TreeMap<>(comparator));
}
public TreeSet(Collection c) {
this();
addAll(c);
}
从4个构造方法中,我们可以大致看出,这个NavigableMap是一个接口,而TreeMap实现了此接口,并在此处为元素的实际存储载体。
增删改查方面,TreeSet与HashSet的实现类似:
public int size() {
return m.size();
}
public boolean isEmpty() {
return m.isEmpty();
}
public boolean contains(Object o) {
return m.containsKey(o);
}
public boolean add(E e) {
return m.put(e, PRESENT)==null;
}
//后续不再列举...
后记
Set 相关的源码基本对应这样的一个关系:XxxSet 需要去学习、研究 XxxMap。 相关 Map 的分析待后续文章分析、记录。