学习笔记--处理图像分类问题的基于粒子群优化的灵活卷积自动编码(pso-FCAE)
博主日常整理的翻译,欢迎感兴趣的打工仔一块学习讨论。
英文原文:A Particle Swarm Optimization-Based Flexible Convolutional Autoencoder for Image Classification. Yanan Sun, Bing Xue, Mengjie Zhang, and Gary G. Yen. IEEE TRANSACTIONS ON NEURAL NETWORKS AND LEARNING SYSTEMS, VOL. 30, NO. 8, AUGUST 2019 2295
摘要:在过去几年中,卷积自编码器(CAEs)在叠加深度卷积神经网络(CNNs)对图像数据进行分类方面表现出显著的性能。然而,其固有的结构无法构建出最先进的CNNs。在这方面,本文提出了一种灵活的CAE(FCAE),它消除了传统CAE中卷积层和池化层的数量限制。此外,设计了一种利用粒子群优化的结构发现方法,该方法能够在不需要人工干预的情况下,以更少的计算资源自动搜索所提出的FCAE的最优结构。在四个广泛使用的图像数据机上测试了提出的方法,实验结果表明,本文提出的方法在性能上明显优于包括最新算法在内的同行竞争者。
关键词:卷积自动编码(CAE),深度学习,图像分类,神经网络,粒子群优化
1.引言
引言部分比较长,随便看看即可。
自编码器(AEs)是堆叠AE(SAE)的构建块,是三大主流的深度学习算法之一(即,其他是深度置信网络(DBNs)和卷积神经网络(CNNs)。AE是一个三层神经网络,由一个输入层、一个隐含层和一个输出层组成,其中输入层的单元数与输出层的单元数相同。通常,从输入层到隐藏层的转换称为编码器,从隐含层到输出层指的是译码器。编码器从输入数据中提取特征/表示,而解码器从特征/表示中重新构造输入数据。通过最小化输入数据和重构数据之间的差异,训练了一个AE。一个SAE由多个训练过的AEs堆叠,用于学习层次表示,这些层次表示在图像分类领域取得了比以往任何时候都更显著的性能。
当图像数据被输入SAE时,必须先转换成矢量形式,这将改变图像的固有结构,进而降低图像的连续性能。例如,一幅图像的形式是I属于Rnn,其中像素Ij,k (1 < j < n,0 < k < n)与像素Ij-1,k的距离很近。当I向量化到v属于Rn^2时,ij,k和ij-1,k之间的关系就会改变在V中可能不再是邻居了。*(好烦呀,word里面调好格式了,一粘进来就乱了,不调了)大量的文献表明,相邻信息是解决图像相关问题的关键因素。为了解决这个问题,Masci等人[16]提出了卷积AEs (CAEs),其中图像数据直接以二维形式输入。在CAEs中,编码器由一个卷积层和一个池化层组成,译码器仅由一个反卷积层组成。多个经过训练的CAEs被堆叠到一个CNN中,以学习提高最终分类性能的层次表示。受CAEs在用原始二维形式寻址数据方面优势的启发,随后提出了各种不同的CAEs。如Norouzi等人提出卷积限制玻尔兹曼机(RBMs)、 (CRBM)。Lee等人通过叠加一组训练好的CRBMs提出卷积DBN。此外,Zeiler等提出了基于稀疏编码模式的逆卷积编码,启发了Kavukcuoglu等设计卷积堆叠稀疏编码来解决目标识别任务。最近,Du等人利用DAE学习卷积滤波器,提出了卷积去噪AE (CDAE)。
尽管来自CAE及其变体的实验结果在不同的应用中显示出了优势,但存在一个主要的局限性,即其堆叠的cnn结构与最先进的cnn结构不一致,如ResNet和VGGNet。具体来说,因为一个CAE在编码器部分有一个卷积层和一个池化层,所以堆叠的CNN也有相同的卷积层和池化层数。然而,最先进的cnn具有不同数量的卷积层和池化层。由于CNN的架构是决定最终性能的关键因素之一,因此需要消除对CAEs的卷积层和池化层数量的限制。但在实际应用中,由于卷积层和池化层具有不可微和非凸的特性,选择合适数量的卷积层和池化层非常困难,这与神经网络的结构优化有关。
自动搜索神经网络最优结构的算法可以分为三类。第一类是基于随机系统的算法,包括随机搜索(RS)、基于贝叶斯的高斯过程(BGP)、树形结构Parzen estimators (TPEs)、基于序列模型的全局优化、进化的无监督深度神经网络(EUDNN)、结构学习、稀疏特征学习。第二部分涵盖了针对存在多个不同构建块的cnn特别设计的算法。元模型化算法(MetaQNN)和图像分类大进化(LEIC)算法都属于这一类。第三种是指扩张型算法及其各种变体,如神经进化。首先,有一种方法不属于这些类别,即网格搜索方法(GS),它对相关参数的每一个组合进行测试。
粒子群优化算法(Particle swarm optimization, PSO)是一种基于种群的随机进化计算算法,其动机是鱼群成群或鸟群聚集的社会行为,通常用于不需要领域知识的情况下求解优化问题。与其它启发式算法相比,粒子群优化算法具有概念简单、易于实现和计算效率高等特点。在粒子群算法中,个体称为粒子,每个粒子从自身记忆中保持最优解(第i个粒子用pBesti表示),种群记录所有粒子历史中最优解(用gBest表示)。在此过程中,粒子预期与pBesti和gBest协同互动,增强搜索能力,追求最优解。由于待优化问题没有要求(如凸或可微)的特性,粒子群优化算法被广泛应用于各种实际应用,自然也包括神经网络的结构设计。在神经网络结构的优化中,这些算法采用隐式方法对神经网络的各个连接进行编码,并利用粒子群算法(PSO)或其变体搜索最优解。但是,它们无法用于CAEs和CNNs,甚至SAEs和DBNs这类深度学习算法中,存在大量的连接权值,导致现有的基于PSO架构优化(PSOAO)的算法无法承受实现和有效优化的成本。如前所述,对于卷积层和池化层的数量没有限制的CAEs,在堆叠最先进的cnn时将会受到极大的青睐。然而,在确定架构之前,这些层的绝对数量是未知的。当使用粒子群算法进行结构优化时,粒子需要有不同的长度。原因是:
1)粒子的长度是指粒子群算法所要解决问题的决策变量的个数
2)在体系结构优化问题中,涉及一组不同的体系结构,不同的体系结构有不同数量的决策变量。然而,正则粒子群算法并没有提供任何更新非等长粒子速度的方法。此外,对每一个代表深度学习算法的粒子进行评估非常耗时,而且在基于种群的更新过程中会变得更加棘手。解决这个问题的一种常用方法是使用密集的计算资源和利用并行计算技术。
本文的目标是设计和开发一种高效的粒子群算法,用于自动发现柔性CAE (FCAE)的结构而不需要人工干预。为实现这一目标,提出了以下四个目标。
1)提出了一个可以存在多个卷积层和池层的FCAE。FCAE对卷积层和池化层的特定数目没有要求,并且有可能堆叠成不同类型的cnn。
2)为提出的FCAE设计一个PSOAO算法。在PSOAO中,我们将提出一种有效的编码方法来表示每个粒子中包含成百上千个参数的FCAE结构,并且我们还将为变长粒子开发一种有效的速度更新机制。
3)研究提出FCAE当其架构的性能优化设计PSOAO在图像分类基准数据集(即CIFAR-10数据集,MNIST数据集,STL-10数据集,和加州理工学院–101数据集),比较分类精度和同行竞争对手和检查进化PSOAO的有效性。
4)通过定量实验与对手进行比较,考察所设计的速度更新方法的有效性。
本文的其余部分组织如下。CAE和PSO的背景将在第二节中讨论。接下来在第三节详细介绍所提出的PSOAO算法。第四节和第五节分别对实验设计和结果分析进行了说明。最后,第六节总结了结论和未来的工作。
2. 文献综述
本文将分别基于CAE和PSO构建FCAE和PSOAO。因此,将在II-A - II-C部分分别给出CAE和PSO的骨架以及它们对于FCAE的局限性,以帮助读者更方便地理解所作工作。此外,还对相关工作进行了回顾和评论,这有助于读者容易地欣赏我们的工作在这篇论文的重要性。
A.卷积自编码器
为了便于开发,假设CAEs被用于图像分类任务。每幅图像X属于Rwhc,其中w、h、c分别表示图像宽度、高度和通道数。图1解释了一个CAE的结构。
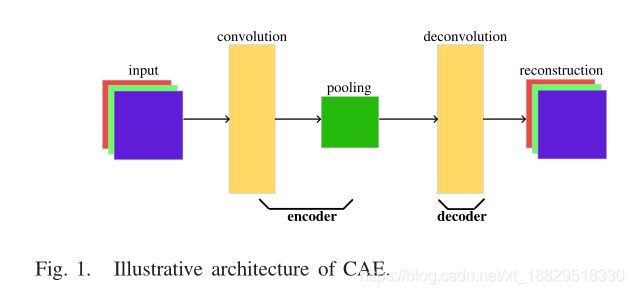
1)**卷积:**给定输入数据,卷积运算使用一个过滤器以一个定义的步幅滑动,并输出该过滤器与该过滤器重叠的输入数据的乘积之和的元素。一个过滤器生成的所有元素构成一个特征图,在卷积操作中允许使用多个特征图。卷积操作具有相同的类型和有效类型。与卷积操作相关的参数有滤波器大小(宽和高)filter size (width and height)、步长大小(宽和高)stride size (width and height)、卷积类型convolutional type和特征图feature map的数量。
2)池化: 池化操作类似于卷积操作,除了滤波器filter和生成相应特征图feature map元素的方式。具体来说,池化操作中的滤波器称为内核,内核中不存在任何值。池化操作中有两种统计指标:平均值和最大值。在CAEs中,最大池是首选。池化操作需要参数:内核大小(宽度和高度)、跨步大小(宽度和高度)和池化类型。
3)反卷积(Deconvolution): 反卷积操作可以等价于具有反参数设置的卷积操作。反卷积操作利用卷积操作中用到的内核filter和步长stride在卷积操作后得到的特征图feature map上进行卷积操作。为了保证反卷积操作的输出与对应卷积操作的输入大小相同,可以在反卷积操作的输入中填充额外的零。
4)学习的CAE: CAE的数学形式由(1)表示,其中conv(·), pool(·), and de_conv(·)分别表示卷积、池化和反卷积操作,F(·)和G(·)为元素非线性激活函数,b1和b2为对应的偏置项。r和X是X的学习特征和重构,l(·)测量X和X之间的差异,和omega是用于提高特征质量的正则化术语。通过最小化L来训练CAE,然后识别卷积运算、偏置项和反卷积运算的参数。编码器使用来自多个训练CAEs的这些参数组成一个CNN,用于学习有利于最终分类性能的层次特征
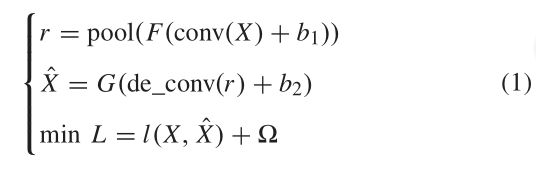
B. FCAE的动机
如图1所示,CAE由卷积层、池化层和反卷积层组成。通过卷积层和池化层的转换称为编码器。通过反卷积层进行的转换称为解码器。在使用CAEs构建CNN的过程中,来自多个CAEs的编码器根据训练顺序被堆叠在一起,当前编码器的输入数据是前一个编码器的输出数据。然而,这种结构既不能形成最先进的网络神经网络,也不能形成常见的深度网络神经网络。
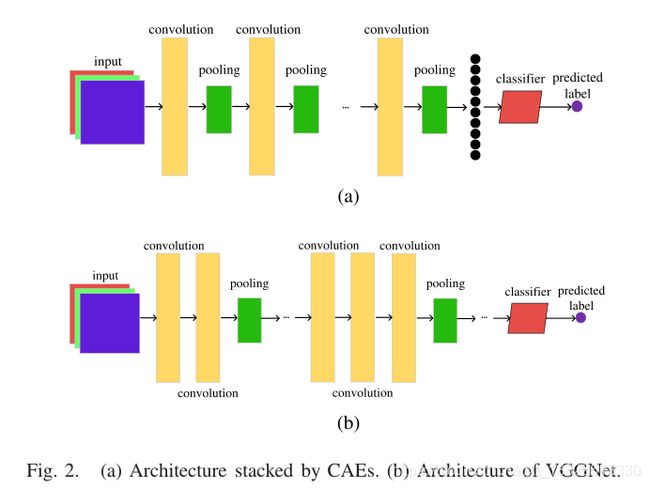
由CAEs叠加的CNN和最先进的CNN叫作VGGNet的架构分别如图2(a)和(b)所示。从这两个例子可以明显看出,CAEs无法堆叠到VGGNet中。原因是CAEs所堆叠的CNN具有相同的构建块,即包含卷积层和池化层的双层网络。因此,堆叠的CNN是由一系列这样的构建块组成的,卷积层的数量与池化层的数量相同。此外,在CAEs所堆叠的CNNs中,卷积层后面必须有一个池化层。从图2(b)可以看出,存在多个卷积层和池化层,二者具有相同的卷积层和池化层数,还有卷积层不一定跟在池化层后面。
池化层通常用于减少输入数据的维数,以降低计算复杂度。池化层最常用的配置是内核大小为22(2乘2,后面的内核和移动步长同理,这里显示不出来,看起来就像22),stride为22。根据第II-A节中介绍的工作机制,具有这种配置的池化层将减少一半的输入数据。例如,对于维数为3232的CIFAR-10数据集的一幅图像,输出的大小将变成5个11的池化层,即设计用CAEs处理CIFAR-10的CNN最多10层。然而,最先进的设计在这个基准上有超过100层。
综上所述,CAE局限性的根源在于其架构,CAE的编码器由一个卷积层和一个池化层组成。因此,人们自然会担心CAE的架构需要修改,这也促使了FCAE的设计,即在FCAE的编码器部分,允许不相同数量的卷积层和池化层,一个池化层可以遵循一系列的卷积层。
C. 粒子群优化
典型的粒子群优化算法的步骤如下:
第1步:初始化粒子,预先定义粒子的最大组数t,初始化一个计数器t = 0。
步骤2:评估粒子的适应度。
步骤3:对于每个粒子,从其内存中选择最佳的pBesti。
步骤4:从所有粒子的历史中选择最佳粒子gBest。
步骤5:根据公式(2)计算每个粒子的速度{v1,…, vi……}.
步骤6:根据公式(3)更新位置{p1,…, pi,…}
步骤7:将t增加1,如果t < maxt,则重复步骤2-6,否则执行步骤8。
第8步:报告gBest的位置

式(2)中,w为惯性权值,c1和c2为加速度常数,r1和r2为0到1之间的随机数,pg和pp分别为gBest和pBesti的位置。vi和pi分别表示第i个粒子xi的速度和位置。通过将惯性、全局搜索和局部搜索项整合到速度更新中,期望粒子能找到最佳位置。
注意(2)在全局搜索和局部搜索中存在两个减法操作。为了更好地理解这种减法操作是如何工作的,我们将以全局搜索中的术语pg-pi为例来详细描述。设待解的最小化问题表示为f (z1, z2,…)其中有n个决策变量{z1, z2,…}属于psi。使用粒子群优化算法求解该问题时,从psi中随机采样第i个粒子xi,其位置由特定值pi = {zi1, zi2,…}属于psi。通过(2)(3)的交互作用,将xi的位置更新到最优解的位置。经过多次迭代求解,最终得到全局最优粒子gBest的位置。在这个例子中,一个粒子的长度是n,即决策变量的数量和位置的维数。显然,pg -pi = {zg1- zi1, zg2- zi2,…, zgn -zin}。
FCAE中使用粒子群算法进行架构设计的局限性: 速度更新要求粒子xi, gBest和pBesti具有相同/固定的长度。当粒子群算法用于FCAE的结构优化时,粒子代表了FCAE潜在的最优结构。由于解决当前任务的FCAE的最优架构未知,将会出现不同长度的变粒。为此,需要设计一种新的速度更新方法。
D. 相关工作
正如在第一节中所讨论的,优化深层神经网络结构的算法分为四种不同的类别。
对于第一类算法,RS用预先定义的最大试验数来评估随机选择的架构,并使用性能最好的架构。已有文献报道,RS只在最优解在整个搜索空间的子空间的条件下有效。然而,这一事实是否同样适用于CNNs尚不清楚。与RS相比,BGP利用了更多的基于贝叶斯推理选择潜在最优架构的知识。然而,BGP有额外的参数,比如难以调优的内核。TPE的工作假设与架构相关的参数是独立的,而CNNs中的大多数参数确实是依赖的,比如卷积层的大小和步长。此外,EUDNN是为无监督深度神经网络设计的,与CNNs结构不同。此外,其他一些方法仅用于优化给定架构下的特定网络连接,如稀疏性。因此,这类算法不能用于CNNs的结构优化。因此,它们不适用于构建基于cnn的FCAEs。
对于第二类算法MetaQNN和LEIC,它们都是专门为CNNs的结构优化而设计的。具体来说,MetaQNN使用强化学习技术来启发式地挖掘CNNs潜在的最优结构,并对其进行全面评估,然后选择一个最适合的。LEIC对元神经网络采用了几乎相同的策略,只是LEIC使用了遗传算法作为启发式方法。由于两种算法都对每个候选对象进行了完整的训练,其不足之处也很明显,即训练依赖于大量的计算资源。例如,MetaQNN在10天内使用了8张图形处理单元(GPU)卡,而LEIC在CIFAR-10测试问题上使用了250台高性能计算机20天。不幸的是,并非所有感兴趣的研究人员都能获得足够的计算资源。
因为第三类算法都是基于NEAT,所以它们的工作流程几乎是一样的。具体地说,输入层和输出层首先被分配,然后这两层之间的神经元和任意两个神经元之间的连接被启发式地生成。通过对每一种情况的适应度评价,选择出较好的情况,并期望通过遗传算法找到最佳的情况**。除了限制发生于第二类算法,其他限制NEAT-based算法混合连接(例如,重量不相邻的层之间的连接)将产生,并输入层和输出层的配置必须提前指定,不允许或适用于CAEs。**
**理论上,GS可以找到最优的架构,因为它的穷尽性,尝试每个候选。然而,GS不可能在实践中尝试每一个候选者。**最近的实验研究表明,实际应用中GS只适用于不超过4个参数的问题。如Section II-A所示,即使CAE只包含一个卷积层和一个池化层,它也会有超过10个参数。另外,由于区间问题,GS不能很好地处理连续值的参数。
3. 基于PSOAO算法的FCAE算法
本节将详细介绍用于FCAE的PSOAO算法。将描述编码策略,包括FCAE表示,粒子初始化,适应度评估,速度和位置更新机制。
A. 算法概述

算法1概述了所设计的PSOAO算法的框架。首先,粒子随机初始化的基础上,提出了编码策略(第1行)。然后,粒子开始进化,直到生成数量超过了预定义的一个(3-9行)。最后,gbest粒子是捡起获得最终的性能通过深度训练解决手头的任务(第10行)。
进化过程中,每个粒子的适应度评估(第4行)首先,然后是pbesti和gbest更新基于适应度(第5行)。接下来,计算每个粒子的速度(第6行)和他们的位置更新(第7行)下一代的进化。在下面的章节中,将详细介绍PSOAO的关键方面。
B. 编码策略
为了便于发展,定义1通过对所有cnns的构建块进行概括,给出了FCAE的定义。显然,当卷积层和池化层的数量都设置为1时,CAE是FCAE的特殊形式。
定义1: 一个FCAE包含一个编码器和一个解码器。编码器由卷积层和池化层组成,其中这两种类型的层不是混合的,它们的数字是灵活的。译码器部分是编码器的逆形式。
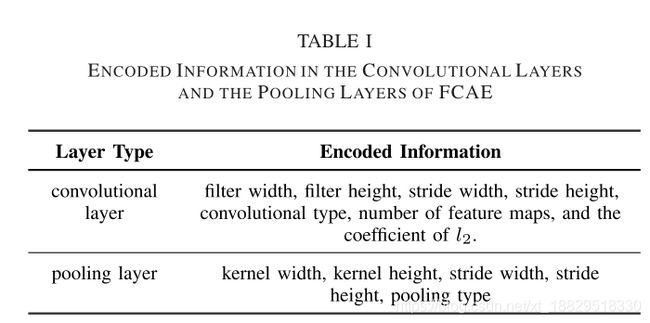
我们设计了一种编码策略,通过变长粒子将一个FCAE的势结构编码为一个粒子。由于FCAE中的解码器部分是编码器的逆形式,因此提出的变长编码策略中的粒子只对编码器部分进行编码,以降低计算复杂度。每个粒子包含不同数量的卷积层和池化层。基于II-A节引入对卷积操作和池化操作,所有用于FCAE的PSOAO编码信息见表I,其中l2为防止过拟合问题的权值衰减正则化项。因为只有卷积层才涉及权值参数,所以这个正则化项只应用于卷积层。此外,由于在相同卷积层的情况下输出大小不会与输入大小发生变化,这在自动架构发现中很容易控制,因此设计的编码策略不会对卷积层的类型进行编码,而是默认为相同的类型。正如在第II-A节中提到的,CAE更喜欢使用最大池化层,我们也不需要对这个参数进行编码。另外,PSOAO中常用编码粒子的三个例子如图3所示。在下面,我们将详细说明这种编码策略的基本原理。
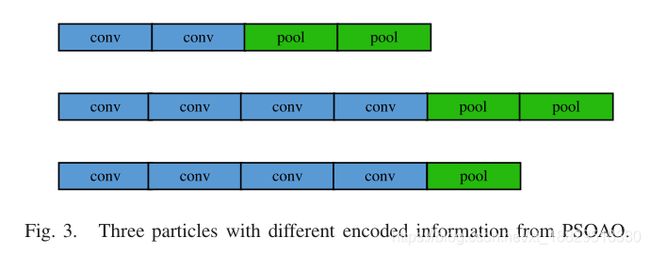
在提出的PSOAO算法中,针对不同结构的FCAEs粒子,设计了一种变长编码策略。主要原因是在优化之前不知道最佳架构,而在这种情况下,固定长度编码策略往往对体系结构施加限制。具体来说,如果采用传统的定长编码策略,则需要预先指定最大长度。但是,最大长度不容易设置,需要仔细调整以获得最佳性能。当表示最大长度的数值过小时,优化后的FCAE结构将无法解决复杂问题。如果进化生成数太多,会消耗更多不必要的计算量,而且在预定义的进化生成数相同的情况下,会导致性能下降。此外,每个粒子中存在两种层,这增加了采用定长编码策略的难度。通过设计的变长编码策略,可以在搜索过程中灵活地表示所有潜在最优架构的信息,用于开发和探索,无需人工干预。
C. 粒子初始化

算法2给出了给定总体大小、给定卷积层和池化层的最大数目时粒子初始化的过程。特别是,第3 - 8行演示了卷积层的初始化,第9 - 14行演示了池化层的初始化,其中的随机设置指的是这两种类型的层中编码的信息的设置。由于FCAE的解码器部分可以由编码器部分显式地推导出来,为了降低计算复杂度,PSOAO算法中的每个粒子都只包含编码器部分。
D.适应度评价

算法3展示了PSOAO中各部分的适应度评价。正如我们在第II-A节中所介绍的,正则化项丢失所增加的重构误差被确定为训练CAE的目标函数。
然而,FCAE中使用的正则化术语的丢失(即l2 loss)受权重数和权重值的影响很大,不同的架构有不同的权重数和权重值。为了研究粒子质量是否只反映结构,舍弃了l2损失,只采用重构误差作为适应度。假设批处理训练数据为{d1, d2,…}[djki属于Rwh为批处理训练数据中第i幅图像(j,k)处的像素值,每幅图像的维数为wh], FCAE中的权值为{w1,w2,…,wm},重构数据为{d^1, d^2,…, d^n}。l2由summi=1 w2i计算,重构误差由(1/n) sumnk=1 sumwl=1 sum hm=1(d^lmk - d^lmk) ^ 2计算。
通常,深度学习算法需要一个102 -103的训练代数来通过基于梯度的算法训练其权值参数。在基于种群的算法中,这个高计算代价的问题甚至更糟。
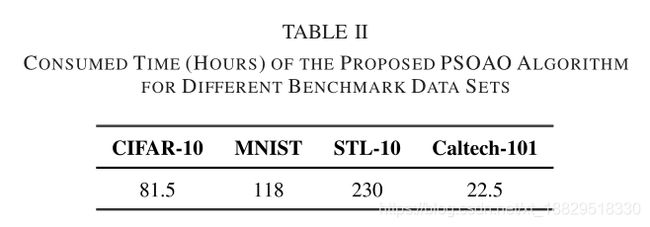
在提出的PSOAO算法中,为了加快训练速度,这个数字被指定为一个非常小的数字(如5或10)。例如,利用一张型号为GTX1080的GPU卡,在CIFAR-10数据集(有50000个训练样本)上训练一个epoch将花费2分钟。如果我们对每一个50倍口径的粒子训练10个2代,那么将需要大约1年的时间,这对于一般的学术研究来说是不能接受的。缓解这种困境的广泛使用的解决方案是使用密集的计算资源,例如谷歌最近在2017年提出的LEIC算法,其中250台计算机使用用于架构发现的遗传算法在CIFAR- 10数据集上工作了大约20天。实际上,在结构搜索过程中,并不需要通过大量的训练时间来评估每个粒子的最终性能。取而代之的是,在较少的训练epoch后,捡起一个有希望的粒子,然后用足够的训练epoch对它进行一次深度训练,这可能是一个有希望的替代方案。在提出的PSOAO算法中,使用了少量的训练epoch来进行粒子的适应度评估。通过评估适应度,选择gBest和pBest i来引导搜索向最优方向发展。当进化终止后,选择gBest,进行一次深度训练以达到最优性能。我们已经证明,这种设置可以在使用较少的计算资源的情况下极大地提高PSOAO的速度,同时仍然保持了PSOAO的良好性能。其中,所研究基准数据集的运行时间见表II,所研究基准数据集所采用的计算资源见第IV-C节,性能的实验结果见V-A节和V-C节。
E.速度计算和位置更新
在PSOAO中,粒子的长度不同,(2)不能直接使用。为了解决这一问题,我们设计了一种名为x-reference的方法来更新速度。在x-reference中,gBest和pBesti的长度指当前粒子x的长度,也就是说, gBest和pBesti保持相同的长度x。因为pBesti从每个粒子的记忆中被选中, gBest是从所有粒子中被选择,粒子当前的x总是与pBesti的长度相同,x-reference仅适用于全局搜索算法(2)的一部分。算法4显示x-reference方法的细节。

具体来说,在(2)的全局搜索部分的速度更新中,以同样的方式使用了两次x-reference方法,第一次是在gBest和x的卷积层部分(第2-14行),第二次是在pooling层部分(第15行)。对于卷积层部分,如果gBest的卷积层数cg小于x的卷积层数,则将初始值为零的新卷积层填充到cg尾部。否则,额外的卷积层将被从cg的尾部截断。算法4导出全局搜索部分后,将(2)中的惯性部分和局部搜索部分按正常方式进行计算,然后通过(3)计算完全速度并更新粒子位置。
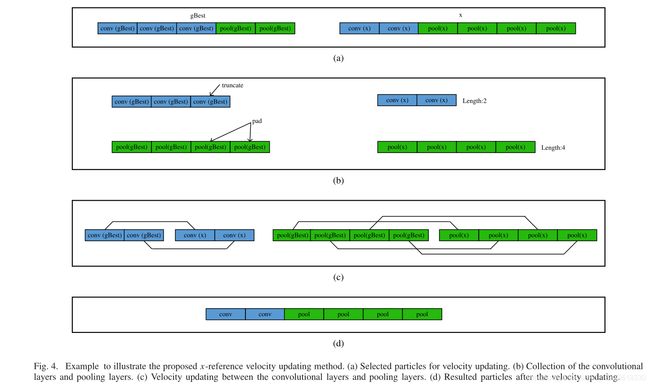
为了直观理解,所提出的x参考速度更新方法,图4给出了一个实例。具体来说,图4(a)显示了速度更新中用于全局搜索的gBest和x。图4 (b)从gBest和x收集的卷积层和池化层。因为x的卷积层和池化层的长度是2和4,gBest是3和2, gBest的最后一层卷积被截断一部分,和其他两个池化层被添加到gBest部分的池化层的尾部。特别地,填充的池化层是用编码信息的值等于0创建的。图4©为gBest和x对卷积层部分和池化层部分的更新,更新结果如图4(d)所示。
无论设计的x参考速度更新方法是填充还是截断,目的都是使gBest中的卷积层和池化层的长度分别与x中的相同。下面讨论这种设计背后的机制。在PSOAO中,种群中有一组长度不同的粒子,它们的目标是寻找的最优结构。用于解决图像分类任务的FCAEs。如果我们让每个粒子都遵循gBest的长度(即gBest参考速度更新方法),那么所有粒子的长度都与第二代gBest相同。因为pBesti是从每个粒子的历史记忆中选择的,所以gBest, pBesti和当前粒子x可能从第三代开始都有相同的长度。因此,所有的粒子都以一个特定的FCAE深度参与优化,只改变编码信息。事实上,关于gBest的长度变化可以被看作是一种探索搜索的能力行为,而编码信息的长度变化被看作是一种探索搜索行为。当所有粒子长度相同时,gBest的长度将保持不变,直到终止。在这方面,如果采用gBest-reference速度更新方法,则会丧失探索搜索的能力。另外,保持x的长度等于gBest也可以看作是多样性的损失,这很容易导致基于种群的算法过早收敛。勘探搜索的损失和和早熟收敛现象都会导致性能不佳。在V-D段进行了实验,进一步定量研究了这种速度更新设计。
F. gBest深度训练
当PSOAO进化完成后,选择最佳粒子gBest进行深度训练。如III-D节所述,每个粒子只训练了几个epoch,这不是解决实际应用的最佳性能。要解决这个问题,深入的培训是必要的。通常,深度训练的过程与第三节-D中的适应度评估是相同的,除了更大的时代数,比如100或200。
4. 实验设计
在本节中,我们将详细介绍基准数据集、竞争对手和参数设置,以研究采用PSOAO算法优化架构的FCAE的性能实验。
A. 基准数据集
实验在4个图像分类基准数据集上进行,这些数据集被广泛使用,专门用于研究AEs的性能。它们是CIFAR- 10数据集、MNIST数据集、STL-10数据集和Caltech-101数据集。图5显示了这些基准数据集的示例。下面对这些选择的数据集进行简要介绍。
-
CIFAR-10数据集:包含50000幅训练图像和10000幅测试图像,每幅图像都是一个大小为32*32的三通道RGB图像,属于10大类自然目标(即卡车、轮船、马、青蛙、狗、鹿、猫、鸟、汽车、飞机)中的一幅。每个类别的图片数量大致相同。此外,不同的物体占据图像的不同区域。
-
MNIST数据集:是一种手写数字识别数据集,用于分类0…9,包括60000张训练图像和10000张测试图像。每一个都是一个单通道灰度图像的大小为28*28,每个类别中的样本都有不同的变化,比如旋转。每个类别由相同数量的图像样本组成。
-
STL-10数据集:是一种广泛使用的用于无监督学习的数据集,包含100000张未标记图像,5000张训练图像,8000张测试图像,来自10类自然图像对象识别(即飞机、鸟、汽车、猫、鹿、狗、马、猴子、船、卡车)。每一个都是一个三通道的RGB图像,大小为96*96。此外,未标记的图像包含超过10个类别的图像。由于训练的样本较少,该数据集对CAEs/AEs和PSOAO的特征学习能力提出了挑战。
-
Caltech-101数据集:它是一个包含101类的图像分类数据集,图像的权重和高度在80 - 708像素之间。大多数图像是三通道RGB,偶尔灰度,不同的图像在每个类别从31到800。另外,大多数图像只显示图像的一小部分,其他区域被噪声占据,增加了分类的难度。由于图像的数量很少,而且每个类别的图像数量不相同,该数据集也对特征学习算法提出了挑战。
B .同行竞争对手
在第一节中介绍了拟采用的FCAE的同行竞争者,用于对所选择的图像分类基准数据集进行比较。它们是CAE,卷积RBM (CRBM),和最先进的CDAE。此外,两种广泛使用的AEs变体也被用作同行竞争对手进行全面比较。它们是稀疏AE (SAE)和DAE。因为本文的目的是提出一个FCAE可以堆叠最先进的cnn,同行竞争对手比较这里还包括这些压缩空气蓄能/ AEs的叠加形式,也就是说,堆叠CAE (SCAE),堆叠CRBM (SCRBM),堆叠CDAE (SCDAE)堆叠SAE (SSAE)和堆叠DAE (SDAE)。所提议的FCAE的堆叠形式为SFCAE。
C. 参数设置
竞争对手SCAE、SCRBM、SSAE和SDAE最近已经在选定的基准数据集上进行了调查,并且他们的架构已经通过领域专家进行了手动调优。它们的分类结果直接从原始出版物中引用,因此不需要指定它们的任何参数设置。此外,最新的SCDAE只在选择的基准数据集上使用一个和两个构建块来提供分类结果。为了进行公平的比较,我们还在最多使用两个构建块的SFCAE上进行了实验。注意,SFCAE是在选定的基准标记数据集上测试的,而没有为保持其同行竞争对手的一致性而进行数据增强的预处理。接下来详细介绍了PSOAO的参数设置。
在设计的PSOAO算法中,粒子群优化算法的相关参数按照其约定指定,**即惯性权值w设为0.72984,加速度常数c1和c2设为1.496172,初始速度设为0。**MNIST和CIFAR-10的训练集和STL-10的未标记数据自然被用于体能评估。由于Caltech-101数据集的图像不相同且每个类别的图像数量很少,**因此我们将从每个类别中随机抽取30幅图像进行适应度评估,并根据建议作为训练集。**因为不恰当的设置卷积操作和池化操作会导致一个难以承受的计算成本,使FCAE无竞争力,在探索每个粒子时,特征图谱的数量设置为[20, 100],宽度和高度的内核具有相同大小设置(2, 5),池化层的最大层数设置为1,和卷积层设置为5。请注意,实验中只研究了平方卷积滤波器和池化内核,这是基于先进的CNNs的约定。另外,l2项的系数设为[0.0001,0.01],这是实际训练神经网络常用的范围。
采**用PSOAO确定的架构和广泛使用的Xavier方法初始化的权值的FCAE用于深度训练,添加了一个完整的连接层,具有512单元和50%的Dropout,**与深度学习社区的惯例相一致。我们调查的分类结果通过摄食训练模型和相应的测试集,采用广泛使用的整流线性单元激活函数,Adam优化器的默认设置作为训练算法为权值优化,和BatchNorm技术加快训练。**以保持为了比较结果的一致性,训练模型在每个基准数据集上的实验也分别进行了5次。**由于Caltech-101数据集中训练数据存在极端不平衡,我们根据惯例对该数据集进行调查,即调查每一类图像的分类精度,然后报告整个数据集的平均值和标准偏差。
提出的PSOAO算法是由Tensorflow实现的,源代码的每一份拷贝都运行在一张型号相同的GTX1080 GPU卡上。为了重现本文报道的实验结果,代码发布在https://github.com/sunkevin1214/psoao。此外,在V-E节中给出了用于实验基准数据集的PSOAO化FCAEs的体系结构配置。PSOAO算法在基准数据集上的训练时间如表2所示。
5. 实验结果与分析
A. 总体性能
表3给出了本文提出的FCAE方法和竞争对手在基准数据集上分类精度的平均值和标准推导,该方法的架构是通过设计的PSOAO算法进行优化的。由于文献中没有给出SCAE在CIFAR-10和MNIST上的标准推导,SCRBM在CIFAR-10上的标准推导,SDAE在MNIST上的标准推导,因此只给出了它们的平均分类精度。表三中的参考文献表示了对应的平均分类准确率的来源,以粗体突出显示了最佳的平均分类结果。SFCAE-1和SFCAE-2分别是指具有一个和两个构件的SFCAE,其含义与SCDAE-1和SCDAE-2相同。
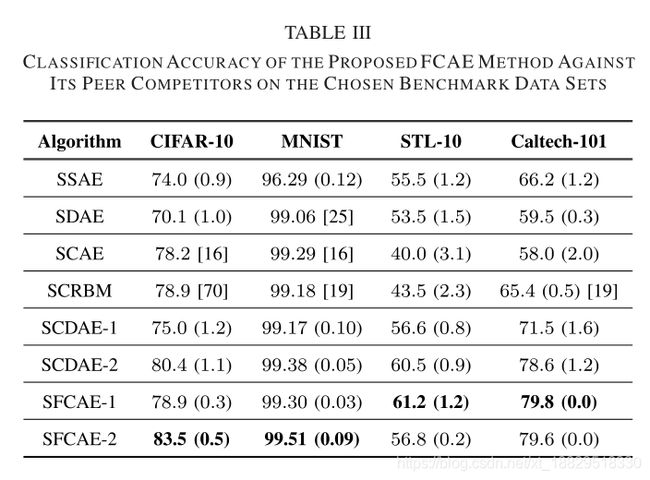
表III清楚地表明,在所有基准数据集上,FCAE的性能优于传统的AEs(即SSAE和SDAE)和传统的CAEs(即SCAE和SCRBM)。此外,在这些基准数据集上,FCAE的性能也优于最先进的CAEs(即SCDAE-1和SCDAE-2)。此外,在CIFAR-10和MNIST上,SFCAE-2达到了最好的结果。
STL-10和Caltech-101上的是SFCAE-1。注意,在STL-10和Caltech-101上,sfcae-2的性能要比sfcae-1差,这是因为这两个基准数据集中的训练实例数量要少得多,而且更深层次的架构存在过合问题。因为CIFAR-10和MNIST有更多的训练样本(在CIFAR-10中有50000个样本,在MNIST中有60000个样本),一个更深的架构自然会产生有希望的分类精度。综上所述,在采用设计的PSOAO算法对所提出的FCAE方法的架构进行优化时,FCAE在四种图像分类基准数据集上都表现出了优于竞争对手的性能。
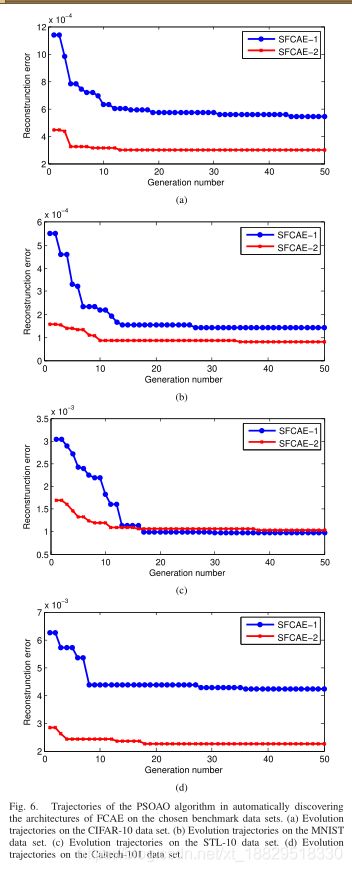
B. PSOAO的演化轨迹
为了直观地研究设计的功效PSOAO算法在优化架构所提出的FCAE方法,其发展轨迹的选择基准数据集在训练阶段是绘制在图6中,水平轴表示数量的一代又一代的进化,和纵轴表示gb的适应度值。从图6(a) (d)可以看出,PSOAO已经收敛到指定的最大生成数。具体地说,从第15代开始,sfcae-1和sfcae-2的基准数据集,以及从第5代开始,sfcae-2的CIFAR-10和Caltech-101数据集,已经趋同。值得注意的是,在STL-10数据集上,sfcae-2的重构误差小于sfcae-1的重构误差,这是由于它们的输入数据不同造成的。
C.不同训练示例数量的性能
在本节中,我们研究了所提出的FCAE方法的分类性能,该方法的架构是通过设计的PSOAO算法对不同数量的训练样本进行优化。MNIST数据集中的同行竞争者为SCRBM、ULIFH、SSAE和SCAE,CIFAR-10数据集中的同行竞争者为SCAE、Mean-cov.RBM和K-means (4k专长)。选择这些基准数据集和同行竞争者的原因是,文献提供了它们的对应信息,这些信息被广泛地用于各种不同CAEs变量之间的比较。
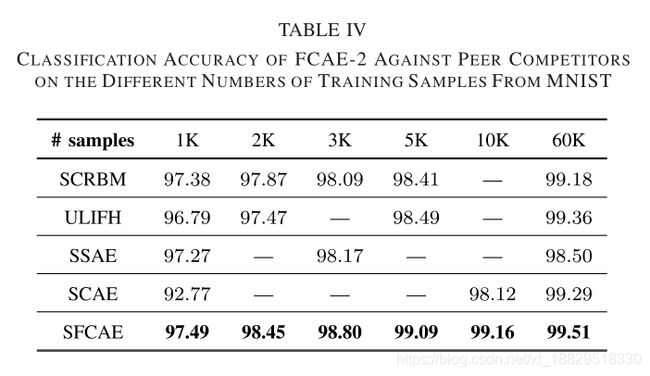
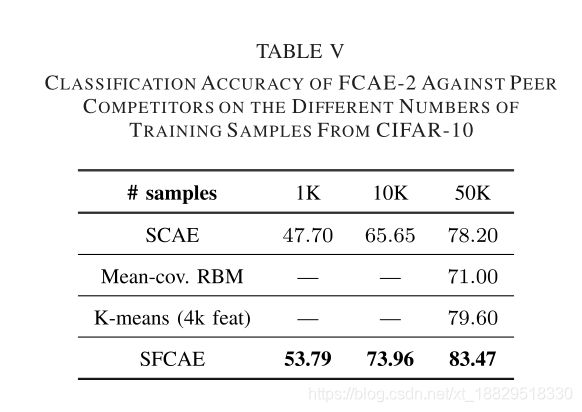
表IV和表V显示了第V-A小节确认的架构下的fcae-2在MNIST和CIFAR-10基准数据集不同数量的训练样本上的实验结果。符号“-”表示存在相关文献未见结果报道。最佳分类精度以粗体突出显示。
从表IV和表V可以看出,sfcae-2在这两个数据集上超过了所有的同行竞争对手。特别是在训练例数(1K)小得多的情况下,sfcae-2的分类准确率在MNIST上提高了4.72%,在cifair-10上提高了6.09%,优于CAE (SCAE)的精算。这些结果表明sfcae-2在处理不同数量的训练样本时具有良好的可扩展性。
D. x参考速度计算研究
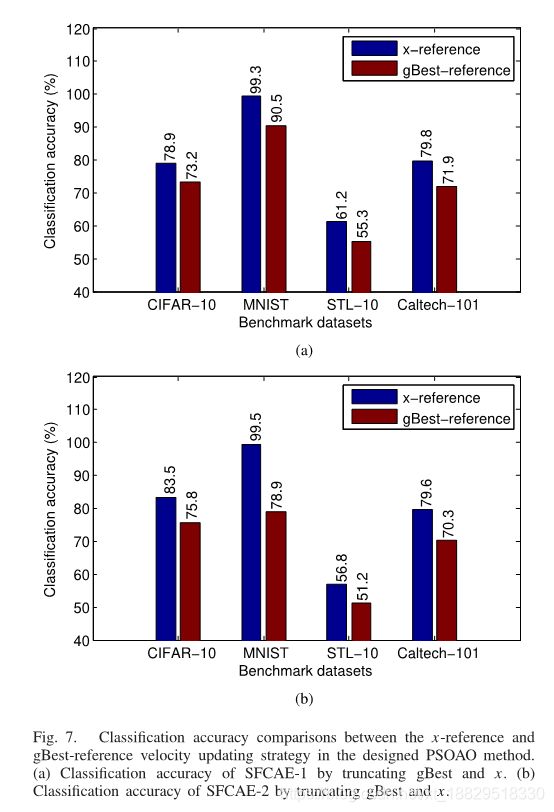
为了进一步研究x参考速度更新方法的优越性,我们将PSOAO算法中的x参考速度更新方法替换为gbest参考速度更新方法,并比较在第IV-a节中所选取的基准数据集上的性能。为了达到这个目的,我们首先让pBesti的长度等于gBest的长度。如果pBesti中卷积层的长度小于gBest,则填充0。否则,将pBesti的对应部分截断。我们在pBesti的池化层和x的这两类层中使用该方法,然后使用(2)和(3)更新每个粒子的位置。实验结果如图7所示,其中图7(a)为FSCAE-1的结果,图7(b)为FSCAE-2的结果。
从图7(a)可以看出,采用x-reference速度更新方法,sfcae-1在cifair-10、MNIST、STL-10和Caltech-101基准数据集上的分类准确率分别提高了5.7%、8.8%、5.9%和7.9%。如图7(b)所示,在这些选定的基准数据集上,sfcae-2的分类准确率也提高了7.7%、10.6%、5.6%和9.6%,表现出了同样有前景的性能。综上所述,分析和实验结果证明了所提出的x参考速度更新方法在PSOAO算法中的有效性。
E.对得到的结构进行研究
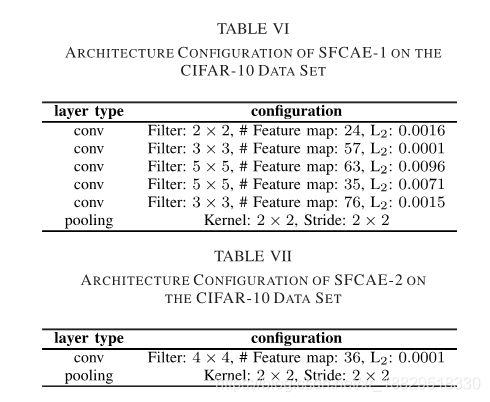
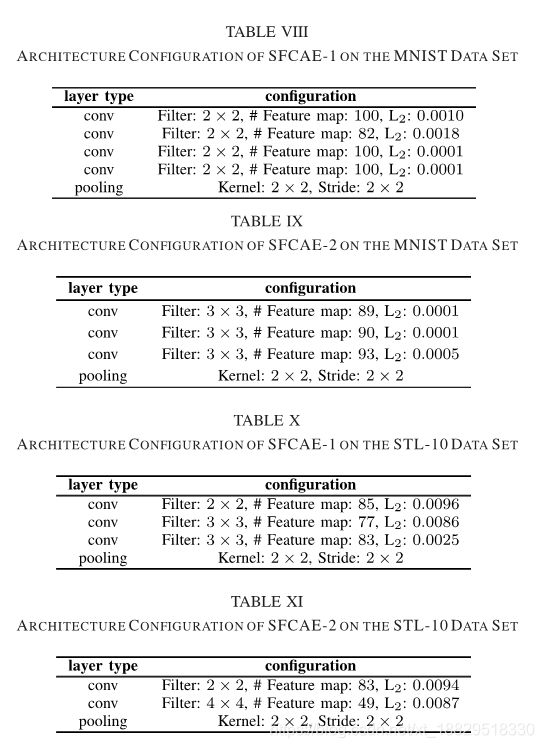
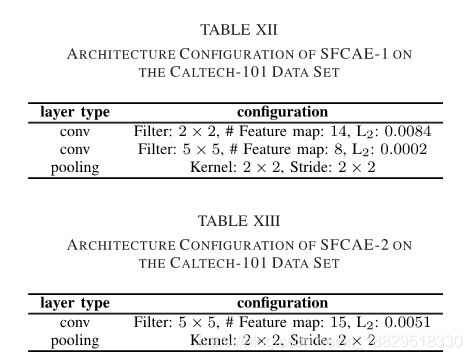
表VI、VIII、X和XII分别显示了CIFAR-10、MNIST、STL-10和Caltech-101数据集的SFCAE-1体系结构配置。此外,表VII、IX、XI和XIII显示了CIFAR-10 MNIST的sfcae-2的体系结构配置STL-10和Caltech-101数据集。注意,同样的卷积层、最大池化层和带有1*1的跨步都是基于实验设置使用的,因此,这些配置在这些表中没有显示。
所得到的架构是基于我们所设计的编码策略。编码策略本文设计架构的基础上的传统cnns构造由多个块组成,每个块由多个卷积层和池化层组成。不出所料,这些获得的架构遵循传统的CNNs和已知的和人工设计的网络架构,如VGGNet。
最近,有两种著名的cnns类型,ResNet和DensNet。由于这两种网络存在跳跃和密集连接,与传统的cnns网络结构有所不同,所获得的网络结构也与传统的cnns网络不同。由于ResNet和DenseNet在大尺度图像处理中的应用前景分类任务在他们的实验中显示,我们将在未来研究一种新的编码策略,能够编码ResNet的跳跃连接和DensNet的密集连接。
6. 结论
本文的目标是开发一种新的粒子群算法(PSOAO),**用于自动发现用于处理图像分类问题的fcae的最优结构,而不需要人工干预。**这个目标已经成功通过定义有潜力的FCAE构建先进的深卷积神经网络,设计一个高效的编码策略,能够代表PSOAO中粒子不恒等的长度,和发展一个有效的粒子速度更新机制。PSOAO实现了结构最优的FCAE,并将其与五个竞争对手(包括最先进的算法)在四个基准数据集上进行了比较,AEs专门用于图像分类。实验结果表明,在所有采用基准数据集的比较算法上,FCAE的分类准确率都明显优于所有的比较算法。此外,只有一个构建块的FCAE可以超越STL-10和Caltech-101基准数据集上的两个构建块。此外,FCAE达到最好的分类精度与四个同行竞争对手当只有1k, 2k, 3k, 5k, 10k训练MNIST基准数据集的图像,并显著优于三同行竞争对手只有1k, 10k 的CIFAR-10基准的训练图像数据集。此外,通过研究PSOAO算法的演化轨迹,该算法也表现出了良好的快速收敛特性,通过与对手的定量比较,该算法具有有效的速度更新机制。
虽然深度CNNs在图像分类方面已经取得了最新的成果,但其结构和超参数在很大程度上是由基于领域专业知识的手工调整决定的。本文提供了一个方向,表明这种手工学习可以被进化方法的自动学习所取代。在未来,我们将在更复杂的CNN模型上研究更简单的进化方法,使用更少的计算资源。