【推荐系统】DeepFM模型分析
目录
一、原理
二、pytorch代码分析
1、数据准备
2、构建模型
2.1、FM模型
2.2、DNN模型
2.3、DeepFM模型
三、代码讲解 & 连接
emb层收敛速度慢的原因
1、输入极端稀疏化。这就意味着里面有很多0,导致w无法更新。
2、参数数量往往占整个神经网络参数数量的大半以上。
一、原理
解决的问题。(介绍的博客很多,建议看其他的人原理介绍。)
CTR预测任务中, 高阶特征和低阶特征的学习都非常的重要。 推荐模型我们也学习了很多,基本上是从最简单的线性模型(LR), 到考虑低阶特征交叉的FM, 到考虑高度交叉的神经网络,再到两者都考虑的W&D组合模型。 这样一串联就会发现前面这些模型存在的问题了, 简单盘点一下:
简单的线性模型虽然简单,同样这样是它的不足,就是限制了模型的表达能力,随着数据的大且复杂,这种模型并不能充分挖掘数据中的隐含信息,且忽略了特征间的交互,如果想交互,需要复杂的特征工程。
FM模型考虑了特征的二阶交叉,但是这种交叉仅停留在了二阶层次,虽然说能够进行高阶,但是计算量和复杂性一下子随着阶数的增加一下子就上来了。所以二阶是最常见的情况,会忽略高阶特征交叉的信息。
DNN,适合天然的高阶交叉信息的学习,但是低阶的交叉会忽略掉。
那么如果把上面这几种结构组合一下子,是不是效果会强大一些呢? 所以W&D模型在这个思路上进行了一个伟大的尝试,把简单的LR模型和DNN模型进行了组合, 使得模型既能够学习高阶组合特征,又能够学习低阶的特征模式,但是W&D的wide部分是用了LR模型, 这一块依然是需要一些经验性的特征工程的,且Wide部分和Deep部分需要两种不同的输入模式, 这个在具体实际应用中需要很强的业务经验。
所以总结起来就是:

- FM与DNN共享输入emb向量。
- 但是emb的参数更新是依赖于DNN部分,更新好的emb直接拿给FM去使用。
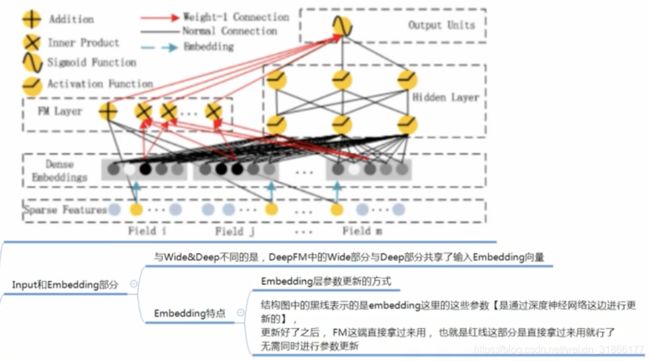
FM和DNN共享特征emb的好处

关于【特征交互】
在CTR预测中, 学习用户点击行为背后的特征隐式交互非常重要。
二阶特征交互原来是这个意思:
通过对主流应用市场的研究,我们发现人们经常在用餐时间下载送餐的应用程序,这就表明应用类别和时间戳之间的(阶数-2)交互作用是CTR预测的一个信号。三阶或者高阶特征交互是这个意思:
我们还发现男性青少年喜欢射击游戏和RPG游戏,这意味着应用类别、用户性别和年龄的(阶数-3)交互是CTR的另一个信号。根据谷歌的W&D模型的应用, 作者发现同时考虑低阶和高阶的交互特征,比单独考虑其中之一有更多的改进
这也就是作者要进行本篇文章研究的原因或者动机之一(改进了LR,FM,DNN)。
论文介绍的小经验,
下面依然是工业上的一些使用经验, 这个模型也是工业上常用的模型:
- MLP这端神经网络的层数, 工业上的经验值不超过3层,一般用两层即可。
- MLP这端隐藏神经元的个数,工业上的经验值,一般128就差不多,最多不超过500
embedding的维度一般不要超过50维, 经验值10-50
二、pytorch代码分析
https://github.com/zhongqiangwu960812/AI-RecommenderSystem/tree/master/DeepFM
使用是的部分Criteo数据集(原本包含45百万用户的点击记录,共有13个连续特征,26个分类特征。),介绍如下:
总共 13 列数值型特征 + 共有 26 列类别型特征(单值离散)
本次实验数据介绍:
- 1279个训练数据
- 320个验证数据
- 400个测试数据torch.__version__: 1.3.1
加载所需要的包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from tqdm import tqdm
import datetime
# pytorch
import torch
from torch.utils.data import DataLoader, Dataset, TensorDataset
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# from torchkeras import summary, Model
from sklearn.metrics import roc_auc_score
import warnings
warnings.filterwarnings('ignore')1、数据准备
# 指定训练数据路径
file_path = './preprocessed_data/'
def prepared_data(file_path):
# 读入训练集, 验证集和测试集
train = pd.read_csv(file_path + 'train_set.csv')
val = pd.read_csv(file_path + 'val_set.csv')
test = pd.read_csv(file_path + 'test_set.csv')
trn_x, trn_y = train.drop(columns='Label').values, train['Label'].values
val_x, val_y = val.drop(columns='Label').values, val['Label'].values
test_x = test.values
fea_col = np.load(file_path + 'fea_col.npy', allow_pickle=True)
return fea_col, (trn_x, trn_y), (val_x, val_y), test_x
"""导入数据"""
fea_cols, (trn_x, trn_y), (val_x, val_y), test_x = prepared_data(file_path)
# 把数据构建成数据管道
dl_train_dataset = TensorDataset(torch.tensor(trn_x).float(), torch.tensor(trn_y).float())
dl_val_dataset = TensorDataset(torch.tensor(val_x).float(), torch.tensor(val_y).float())
dl_train = DataLoader(dl_train_dataset, shuffle=True, batch_size=32)
dl_val = DataLoader(dl_val_dataset, shuffle=True, batch_size=32)我们可以打印一下数据,看一下内容:
for x, y in iter(dl_train):
print(x)
print(x.shape, y)
break
# 运行结果:
tensor([[8.4211e-02, 8.9118e-02, 0.0000e+00, ..., 5.3100e+02, 0.0000e+00,
0.0000e+00],
[2.1053e-02, 2.5426e-04, 3.5474e-04, ..., 5.4700e+02, 0.0000e+00,
0.0000e+00],
[0.0000e+00, 1.2713e-04, 0.0000e+00, ..., 5.3100e+02, 0.0000e+00,
0.0000e+00],
...,
[0.0000e+00, 2.5426e-04, 1.1825e-04, ..., 5.7000e+02, 2.7000e+01,
4.6400e+02],
[0.0000e+00, 8.3905e-03, 4.3751e-03, ..., 3.8000e+02, 2.0000e+00,
1.6000e+02],
[0.0000e+00, 1.2713e-04, 0.0000e+00, ..., 1.6300e+02, 0.0000e+00,
0.0000e+00]])
torch.Size([32, 39]) tensor([0., 0., 0., 1., 0., 1., 0., 0., 0., 0., 0., 0., 0., 1., 0., 1., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0.])[32, 39] 是因为总共有13+26个特征,32是dl_train = DataLoader(dl_train_dataset, shuffle=True, batch_size=32)定义的。遍历一次,拉取32个样本数据。
2、构建模型
这里依然是使用继承nn.Module基类构建模型, 并辅助应用模型容器进行封装。这个模型也是两部分组成, 左边是FM模型, 右边是DNN模型, DNN模型和之前的形式一样, 所以下面我们首先先实现这两个单模型,然后把它们拼起来
DeepFM的模型架构如下:
2.1、FM模型
class FM(nn.Module):
"""FM part"""
def __init__(self, latent_dim, fea_num):
"""
latent_dim: 各个离散特征隐向量的维度
input_shape: 这个最后离散特征embedding之后的拼接和dense拼接的总特征个数
"""
super(FM, self).__init__()
self.latent_dim = latent_dim
# 定义三个矩阵, 一个是全局偏置,
# 一个是一阶权重矩阵,
# 一个是二阶交叉矩阵,注意这里的参数由于是可学习参数,需要用nn.Parameter进行定义
self.w0 = nn.Parameter(torch.zeros([1,]))
self.w1 = nn.Parameter(torch.rand([fea_num, 1]))
self.w2 = nn.Parameter(torch.rand([fea_num, latent_dim]))
def forward(self, inputs):
# 一阶交叉
# print("self.w0:{}".format(self.w0))
# self.w0:Parameter containing:
# tensor([-0.0227], requires_grad=True)
# (samples_num, 1) # B,1
first_order = self.w0 + torch.mm(inputs, self.w1)
# 二阶交叉 这个用FM的最终化简公式
# (samples_num, 1) # B,1
second_order = 1/2 * torch.sum(
torch.pow(torch.mm(inputs, self.w2), 2) - torch.mm(torch.pow(inputs,2), torch.pow(self.w2, 2)),
dim = 1,
keepdim = True
)
return first_order + second_order 2.2、DNN模型
class Dnn(nn.Module):
"""Dnn part"""
def __init__(self, hidden_units, dropout=0.):
"""
hidden_units: 列表, 每个元素表示每一层的神经单元个数, 比如[256, 128, 64], 两层网络, 第一层神经单元128, 第二层64, 第一个维度是输入维度
dropout = 0.
"""
super(Dnn, self).__init__()
self.dnn_network = nn.ModuleList([nn.Linear(layer[0], layer[1]) for layer in list(zip(hidden_units[:-1], hidden_units[1:]))])
self.dropout = nn.Dropout(dropout)
def forward(self, x):
for linear in self.dnn_network:
x = linear(x)
x = F.relu(x)
x = self.dropout(x)
return x中间有个部分不明白
for layer in list(zip(hidden_units[:-1], hidden_units[1:])):
print(layer)
(256, 128)
(128, 64)
意思就是输入x,经过(256,128)的NN+relu。然后再经过(12,64)的NN+relu。最后接一个dropout。
2.3、DeepFM模型
class DeepFM(nn.Module):
def __init__(self, feature_columns, hidden_units, dnn_dropout=0.):
"""
DeepFM:
:param feature_columns: 特征信息, 这个传入的是fea_cols
:param hidden_units: 隐藏单元个数, 一个列表的形式, 列表的长度代表层数, 每个元素代表每一层神经元个数
"""
super(DeepFM, self).__init__()
self.dense_feature_cols, self.sparse_feature_cols = feature_columns
# embedding
self.embed_layers = nn.ModuleDict({
'embed_' + str(i): nn.Embedding(num_embeddings=feat['feat_num'], embedding_dim=feat['embed_dim'])
for i, feat in enumerate(self.sparse_feature_cols)
})
print("self.embed_layers\n", self.embed_layers)
# print("[0]:", self.sparse_feature_cols[0]['embed_dim']) # 8
# 这里要注意Pytorch的linear和tf的dense的不同之处,
# Pytorch的linear需要输入特征和输出特征维度, 而传入的hidden_units的第一个是第一层隐藏的神经单元个数,这里需要加个输入维度
self.fea_num = len(self.dense_feature_cols) + len(self.sparse_feature_cols)*self.sparse_feature_cols[0]['embed_dim']
hidden_units.insert(0, self.fea_num) # 在hidden前加入输入特征的维度
self.fm = FM(self.sparse_feature_cols[0]['embed_dim'], self.fea_num)
self.dnn_network = Dnn(hidden_units, dnn_dropout)
self.nn_final_linear = nn.Linear(hidden_units[-1], 1)
def forward(self, x):
dense_inputs, sparse_inputs = x[:, :len(self.dense_feature_cols)], x[:, len(self.dense_feature_cols):]
sparse_inputs = sparse_inputs.long() # 转成long类型才能作为nn.embedding的输入
sparse_embeds = [self.embed_layers['embed_'+str(i)](sparse_inputs[:, i]) for i in range(sparse_inputs.shape[1])]
# print("sparse_inputs.shape[1]", sparse_inputs.shape[1]) # 26个离散型特征
# for i in range(sparse_inputs.shape[1]): # 遍历第1个离散特征,i=1
# print("(sparse_inputs[:, i])\n ", (sparse_inputs[:, i])) # 32个batchsize的第1个特征
# tensor([201, 10, 12, 170, 154, 12, 52, 236, 161, 74, 76, 126, 51, 183,
# 42, 149, 51, 9, 91, 126, 10, 37, 51, 51, 125, 230, 131, 132,
# 12, 12, 130, 12])
# c = self.embed_layers['embed_'+str(i)](sparse_inputs[:, i]) # [1,32,8]
# 从emb table中lookup 第1特征的emb矩阵中,get 32个id对应的emb向量是多少,get到第1个特征中,id=201的vector是多少
# print("self.embed_layers['embed_'+str(i)](sparse_inputs[:, i])\n", self.embed_layers['embed_'+str(i)](sparse_inputs[:, i]))
sparse_embeds = torch.cat(sparse_embeds, dim=-1) # 横向拼接, dim=-1按照最后一维拼接。
# sparse_embeds_size torch.Size([32, 208])
# print("sparse_embeds_size ", sparse_embeds.shape)
# 把离散特征和连续特征进行拼接作为FM和DNN的输入
x = torch.cat([sparse_embeds, dense_inputs], dim=-1)
# Wide
wide_outputs = self.fm(x)
# deep
deep_outputs = self.nn_final_linear(self.dnn_network(x))
# 模型的最后输出
outputs = F.sigmoid(torch.add(wide_outputs, deep_outputs))
return outputs其中有些不理解的地方进行了打印,
self.embed_layers
self.embed_layers
ModuleDict(
(embed_0): Embedding(79, 8)
(embed_1): Embedding(252, 8)
(embed_10): Embedding(926, 8)
(embed_11): Embedding(1239, 8)
(embed_12): Embedding(824, 8)
(embed_13): Embedding(20, 8)
(embed_14): Embedding(819, 8)
(embed_15): Embedding(1159, 8)
(embed_16): Embedding(9, 8)
(embed_17): Embedding(534, 8)
(embed_18): Embedding(201, 8)
(embed_19): Embedding(4, 8)
(embed_2): Embedding(1293, 8)
(embed_20): Embedding(1204, 8)
(embed_21): Embedding(7, 8)
(embed_22): Embedding(12, 8)
(embed_23): Embedding(729, 8)
(embed_24): Embedding(33, 8)
(embed_25): Embedding(554, 8)
(embed_3): Embedding(1043, 8)
(embed_4): Embedding(30, 8)
(embed_5): Embedding(7, 8)
(embed_6): Embedding(1164, 8)
(embed_7): Embedding(39, 8)
(embed_8): Embedding(2, 8)
(embed_9): Embedding(908, 8)
)sparse_embeds = [self.embed_layers['embed_'+str(i)](sparse_inputs[:, i]) for i in range(sparse_inputs.shape[1])]
26个离散型特征:sparse_inputs.shape[1] 26。
(sparse_inputs[:, i]) ,假如i=1,(sparse_inputs[:, 1]),输入Batchsize的所有行第一列。
# 32个batchsize的第1个特征
(sparse_inputs[:, i])
tensor([13, 15, 26, 27, 0, 64, 56, 26, 40, 15, 0, 43, 0, 43, 33, 0, 0, 36,
0, 26, 0, 0, 0, 43, 26, 0, 33, 0, 33, 33, 75, 27])self.embed_layers['embed_'+str(1)](sparse_inputs[:, 1])
从embed_1的embedding矩阵中,找到13,15,26。。。27的id对应的emb vector。
tensor([[-1.4639, -0.7128, -1.0563, -1.4808, 0.4443, 0.0396, -0.4131, -0.4098],
[-0.3633, 0.3777, 0.6757, -0.3183, 0.7299, 1.1299, 0.7224, 0.2695],
[ 2.2873, 0.2555, 0.7544, -1.0387, 2.0232, 1.0837, 1.1289, -0.4323],
[-0.2851, -0.3741, 0.8221, 0.7784, -0.1501, -0.3380, 1.2154, 0.1392],
[-0.2266, -0.0376, -0.1725, 0.4715, 1.5847, 0.0148, -0.7969, -0.3344],
[ 1.3064, -0.2468, 0.9592, -0.6913, 0.1329, 0.2627, -0.0209, -0.9455],
[ 0.6701, 0.0199, 1.1647, -0.0132, 0.5499, -0.6432, 2.4543, 0.2394],
[ 2.2873, 0.2555, 0.7544, -1.0387, 2.0232, 1.0837, 1.1289, -0.4323],
[ 0.0656, 0.8834, -1.2746, -0.5263, -1.3244, -0.5119, 0.8927, -1.0337],
[-0.3633, 0.3777, 0.6757, -0.3183, 0.7299, 1.1299, 0.7224, 0.2695],
[-0.2266, -0.0376, -0.1725, 0.4715, 1.5847, 0.0148, -0.7969, -0.3344],
[-0.4535, -0.2620, 0.8880, 0.5566, 0.5189, 1.0608, -0.9572, -0.6825],
[-0.2266, -0.0376, -0.1725, 0.4715, 1.5847, 0.0148, -0.7969, -0.3344],
[-0.4535, -0.2620, 0.8880, 0.5566, 0.5189, 1.0608, -0.9572, -0.6825],
[ 0.8973, 1.0933, -0.3527, -0.3034, -0.7779, 0.1933, 1.0803, 2.2664],
[-0.2266, -0.0376, -0.1725, 0.4715, 1.5847, 0.0148, -0.7969, -0.3344],
[-0.2266, -0.0376, -0.1725, 0.4715, 1.5847, 0.0148, -0.7969, -0.3344],
[ 0.4971, 0.2588, 0.4070, 0.9371, 1.3312, 1.1213, -0.4729, -0.1009],
[-0.2266, -0.0376, -0.1725, 0.4715, 1.5847, 0.0148, -0.7969, -0.3344],
[ 2.2873, 0.2555, 0.7544, -1.0387, 2.0232, 1.0837, 1.1289, -0.4323],
[-0.2266, -0.0376, -0.1725, 0.4715, 1.5847, 0.0148, -0.7969, -0.3344],
[-0.2266, -0.0376, -0.1725, 0.4715, 1.5847, 0.0148, -0.7969, -0.3344],
[-0.2266, -0.0376, -0.1725, 0.4715, 1.5847, 0.0148, -0.7969, -0.3344],
[-0.4535, -0.2620, 0.8880, 0.5566, 0.5189, 1.0608, -0.9572, -0.6825],
[ 2.2873, 0.2555, 0.7544, -1.0387, 2.0232, 1.0837, 1.1289, -0.4323],
[-0.2266, -0.0376, -0.1725, 0.4715, 1.5847, 0.0148, -0.7969, -0.3344],
[ 0.8973, 1.0933, -0.3527, -0.3034, -0.7779, 0.1933, 1.0803, 2.2664],
[-0.2266, -0.0376, -0.1725, 0.4715, 1.5847, 0.0148, -0.7969, -0.3344],
[ 0.8973, 1.0933, -0.3527, -0.3034, -0.7779, 0.1933, 1.0803, 2.2664],
[ 0.8973, 1.0933, -0.3527, -0.3034, -0.7779, 0.1933, 1.0803, 2.2664],
[-1.9452, -1.4843, -0.4154, -0.0963, -0.3846, 0.4062, -0.5578, -0.4342],
[-0.2851, -0.3741, 0.8221, 0.7784, -0.1501, -0.3380, 1.2154, 0.1392]],
grad_fn=) 输入x,y数据
(features, labels)
(tensor([[0.0000e+00, 3.8139e-04, 4.7298e-04, ..., 7.1000e+02, 2.0000e+00,
3.6600e+02],
[0.0000e+00, 3.8139e-04, 1.7737e-03, ..., 5.7300e+02, 0.0000e+00,
0.0000e+00],
[6.3158e-02, 1.2713e-04, 3.5474e-04, ..., 6.7000e+01, 2.7000e+01,
4.0500e+02],
...,
[0.0000e+00, 4.8309e-03, 0.0000e+00, ..., 4.3100e+02, 2.7000e+01,
5.4500e+02],
[0.0000e+00, 8.8991e-03, 0.0000e+00, ..., 1.6300e+02, 1.0000e+00,
5.4400e+02],
[0.0000e+00, 3.8139e-04, 8.8684e-03, ..., 6.7000e+01, 2.7000e+01,
4.0500e+02]]), tensor([0., 0., 0., 0., 1., 1., 0., 1., 0., 0., 0., 1., 0., 0., 0., 0., 1., 0.,
0., 0., 0., 0., 0., 1., 0., 0., 1., 0., 1., 1., 0., 0.]))
features.shape torch.Size([32, 39])
labels.shape torch.Size([32])然后再将所有的emb特征,根据dim=-1,最后一维(横向拼接),sparse_embeds_size torch.Size([32, 208])。当做所有离散特征的处理结果。
上述代码只能处理单值离散型特征。
得到sparse_embeds:
- 单值离散特征:
feat_a = [12], lookup idx=12的emb vector即可。
- 如果想要处理变长离散特征, pad_size=5:
feat_b = [12,14,9,0,0], lookup idx=12,14,9的emb vector, 再除以3。
最后整个DeepFM模型结构如下,
DeepFM(
(embed_layers): ModuleDict(
(embed_0): Embedding(79, 8)
(embed_1): Embedding(252, 8)
(embed_10): Embedding(926, 8)
(embed_11): Embedding(1239, 8)
(embed_12): Embedding(824, 8)
(embed_13): Embedding(20, 8)
(embed_14): Embedding(819, 8)
(embed_15): Embedding(1159, 8)
(embed_16): Embedding(9, 8)
(embed_17): Embedding(534, 8)
(embed_18): Embedding(201, 8)
(embed_19): Embedding(4, 8)
(embed_2): Embedding(1293, 8)
(embed_20): Embedding(1204, 8)
(embed_21): Embedding(7, 8)
(embed_22): Embedding(12, 8)
(embed_23): Embedding(729, 8)
(embed_24): Embedding(33, 8)
(embed_25): Embedding(554, 8)
(embed_3): Embedding(1043, 8)
(embed_4): Embedding(30, 8)
(embed_5): Embedding(7, 8)
(embed_6): Embedding(1164, 8)
(embed_7): Embedding(39, 8)
(embed_8): Embedding(2, 8)
(embed_9): Embedding(908, 8)
)
(fm): FM()
(dnn_network): Dnn(
(dnn_network): ModuleList(
(0): Linear(in_features=221, out_features=128, bias=True)
(1): Linear(in_features=128, out_features=64, bias=True)
(2): Linear(in_features=64, out_features=32, bias=True)
)
(dropout): Dropout(p=0.0, inplace=False)
)
(nn_final_linear): Linear(in_features=32, out_features=1, bias=True)
)三、代码讲解 & 连接
推荐算法之: DeepFM及使用DeepCTR测试
深度学习deepctr 推荐算法召回youtube和排序deepfm,保存与加载、预测和部署(使用deepctr实现deepfm)
一些好的链接:
DeepFM推荐系统 论文+代码 (数据来源+代码)
https://github.com/whk6688/tensorflow-DeepFM(提供增量训练的代码)
AI上推荐 之 FNN、DeepFM与NFM(FM在深度学习中的身影重现) (大部分理论介绍来自于这里)
https://github.com/zhongqiangwu960812/AI-RecommenderSystem/tree/master/DeepFM deepfm pytorch版
推荐算法之: DeepFM及使用DeepCTR测试
推荐系统遇上深度学习(一)--FM模型理论和实践(可以回顾下FM原理)
数据下载地址:
https://s3-eu-west-1.amazonaws.com/kaggle-display-advertising-challenge-dataset/dac.tar.gz