R语言|dplyr()函数(一) ———R语言数据处理系列(一)
dplyr函数进行数据转换
- 筛选知识铺垫
-
- 比较运算符
- 逻辑运算符
- 数据准备
- filter()函数筛选行
- select()函数筛选列
- arrange()函数排列行
- 完整代码
dplyr()函数是R语言数据分析必学的实用包之一。
本文现阶段先讲解dplyr()函数的几个常用于数据转换的函数:filter()函数、select()函数、arrange()函数进行数据的行列筛选,以及行排序。【该部分完整代码附于文章末】
筛选知识铺垫
通常在筛选时我们常会设定一些筛选标准或要求,例如:成绩>60分、性别男且年龄>30岁等。因此需要先知道比较和逻辑运算符在R语言中的表达规则,以便于筛选能达到预期要求。
比较运算符
R 提供了一套标准的比较运算符:
| 符号 | 意义 |
|---|---|
| > | 大于 |
| >= | 大于且等于 |
| < | 小于 |
| <= | 小于且等于 |
| != | 不等于 |
| == | 等于 |
注: 在R语言中“=”也可做赋值语句,但在比较判断时表示为“==”
进行比较后,返回的值为逻辑值(TRUE、FALSE),然后用于后面的筛选中,TRUE表示保留,FALSE表示删除。以下面的代码为例,筛选出大于向量a中大于5的数字。当想要赋值与查看命令同时运行时,可将赋值语句加小括号。
> #### 比较运算符
> a <- c(9,5,8,4,6,7,3,2,4) #创建向量
> (b <- a>5) #a中的数字与5比较
[1] TRUE FALSE TRUE FALSE TRUE TRUE FALSE FALSE FALSE
> a[b] #筛选出大于5的数字
[1] 9 8 6 7
逻辑运算符
逻辑运算符又称布尔运算符: & 表示“与”、 | 表示“或”、 ! 表示“非”。如图1是R语言中基本的逻辑运算集合。
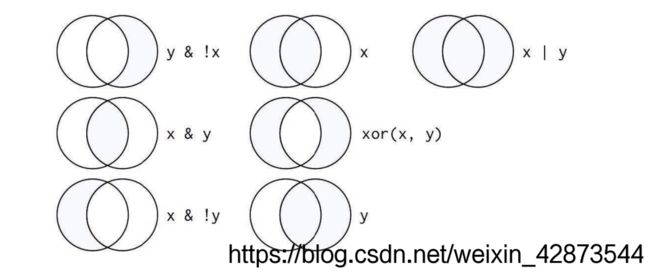 图1 逻辑运算集合 图1 逻辑运算集合
|
| 符号 | 意义 |
|---|---|
| y & !x | 包含 y 元素且不包含 x 元素的集合 |
| x | 只含 x 元素的集合 |
| x l y | 位于 x 或者位于 y 的所有元素集合 |
| x & y | 同时满足位于 x 且位于 y 中的元素集合 |
| xor( x , y ) | 只位于 x 但不属于 y ,或只位于 y 但不属于 x 的元素集合 |
| x & !y | 只位于 x 但不属于 y 的元素集合 |
| y | 只位于 y 的元素集合 |
> ### 逻辑运算符
> c <- c(1,2,3,4,5,6,7,8,9,0) # 创建向量
> (d <- c>7 | c<4) # 创建逻辑运算值
[1] TRUE TRUE TRUE FALSE FALSE FALSE FALSE TRUE TRUE TRUE
> c[d] # 筛选出满足条件的数值
[1] 1 2 3 8 9 0
数据准备
为了介绍 dplyr 中的基本数据操作,我们需要使用 nycflights13::flights 。这个数据框包含了 2013 年从纽约市出发的所有 336 776 次航班的信息。该数据来自于美国交通统计局,可以使用 ?flights 查看其说明文档:
### dplyr包解析
### 数据准备
library(tidyverse) #加载tidyverse包
library(dplyr)
flights <- nycflights13::flights #加载数据
str(flights) #查看数据变量
summary(flights) #查看数据基本信息
由于变量信息内容较多,此处不做解释,下面介绍数据框的变量信息,如图2,该数据框共有19个变量,数据的类型就是冒号后面的第一个。
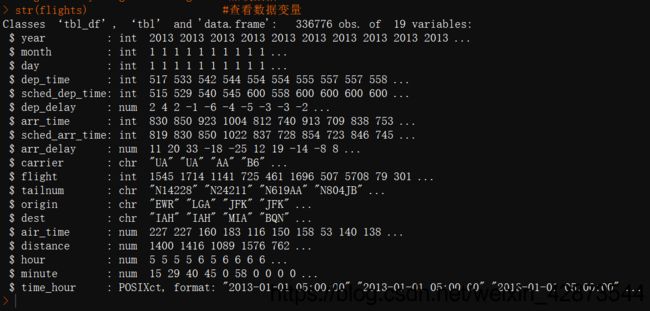 图2 数据的变量信息 图2 数据的变量信息
|
filter()函数筛选行
filter() 函数可以基于观测的值筛选出一个观测子集。第一个参数是数据框名称,第二个参数以及随后的参数是用来筛选数据框的表达式。
filter(数据框, 筛选要求)
#### filter() 筛选行
(Dec_25 <- filter(flights, month == 12, day == 25)) # 筛选出12月25日的所有信息
(Feb_Nov <- filter(flights, month == 2 | month == 11)) # 筛选出2月与12月的所有信息
(day_5_15_25 <- filter(flights, day %in% c(5,15,25))) # 筛选出5、15、25号的所有信息
由于输出数据太大,因此只像大家展示最后day_5_15_25的输出数据,如图3所示。
 图3 day_5_15_25部分数据展示 图3 day_5_15_25部分数据展示
|
select()函数筛选列
select()函数的使用方式和filter()函数一样,不过后面的是列名或表达式。select()适合使用于大型变量的数据框中,这里的数据框只有19个变量,因此使用效果并不佳。
select(数据框, 列名或表达式)
#### select() 筛选列
(y_m_d <- select(flights, year, month, day)) # 筛选出年月日三列数据
(dep <- select(flights, starts_with("dep"))) # 筛选出以dep开头的列名的数据
(delay_time <- select(flights, # 筛选出以time和delay结尾的数据
ends_with("delay"), ends_with("time") ))
此处也仅以delay_time的输出结果,如图4所示。
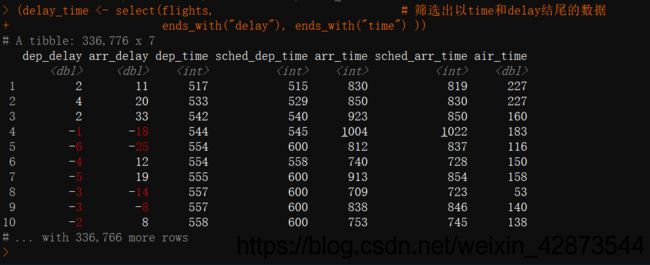 图4 delay_time的部分数据展示 图4 delay_time的部分数据展示
|
arrange()函数排列行
arrange() 函数的工作方式与 filter() 函数非常相似,但前者不是选择行,而是改变行的顺序。如果列名不只一个,那么就使用后面的列在前面排序的基础上继续排序。
arrange(数据框, 列名)
#### arrange() 排列行
(by_y_m <- arrange(flights, year, month)) # 按第一关键词为year,第二关键词为month排序
(by_arr_delay <- arrange(flights, desc(arr_delay))) # 按arr_delay倒序排列
此处展示按arr_delay倒序的部分数据,如图5。
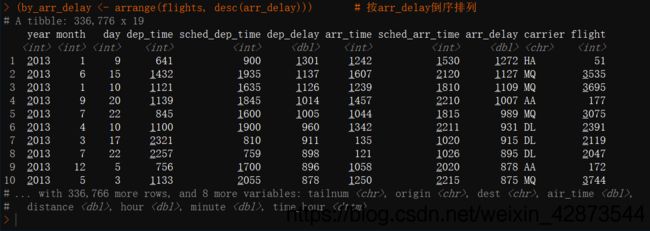 图5 arr_delay倒序的部分数据展示 图5 arr_delay倒序的部分数据展示
|
以上三种方法只是简单介绍筛选的基本知识,通常我们在实战时是三者融汇贯通一起使用的。大家可以先熟悉语法之后,再进行融会贯通。
完整代码
创作不易,你的赞就是对我最大的支持,感谢!
#### 比较运算符
a <- c(9,5,8,4,6,7,3,2,4) # 创建向量
(b <- a>5) # a中的数字与5比较
a[b] # 筛选出大于5的数字
### 逻辑运算符
c <- c(1,2,3,4,5,6,7,8,9,0) # 创建向量
(d <- c>7 | c<4) # 创建逻辑运算值
c[d] # 筛选出满足条件的数值
### dplyr包解析
### 数据准备
library(tidyverse) #加载tidyverse包
library(dplyr)
flights <- nycflights13::flights #加载数据
str(flights) #查看数据变量
summary(flights) #查看数据基本信息
#### filter() 筛选行
(Dec_25 <- filter(flights, month == 12, day == 25)) # 筛选出12月25日的所有信息
(Feb_Nov <- filter(flights, month == 2 | month == 11)) # 筛选出2月与12月的所有信息
(day_5_15_25 <- filter(flights, day %in% c(5,15,25))) # 筛选出5、15、25号的所有信息
#### select() 筛选列
(y_m_d <- select(flights, year, month, day)) # 筛选出年月日三列数据
(dep <- select(flights, starts_with("dep"))) # 筛选出以dep开头的列名的数据
(delay_time <- select(flights, # 筛选出以time和delay结尾的数据
ends_with("delay"), ends_with("time") ))
#### arrange() 排列行
(by_y_m <- arrange(flights, year, month)) # 按第一关键词为year,第二关键词为month排序
(by_arr_delay <- arrange(flights, desc(arr_delay))) # 按arr_delay倒序排列