DDPG 代码调试问题
最近在用DDPG做实验,因为不是专门研究学习算法,作为新手遇到了不少问题,之前查到的一些回答可能不是很详细,因此记录一下。更注重解决问题,没有原理解释,如有错误欢迎指正
1. DDPG的动作为n维向量时,应该如何设置?
解决办法:找到Actor网络的初始化代码,直接将输出层节点数(这段代码对应a_dim)改成想要的维度
class ANet(nn.Module): # ae(s)=a
def __init__(self, s_dim, a_dim, a_bound, ):
# nn.Module的子类函数必须在构造函数中执行父类的构造函数
super(ANet, self).__init__()
self.fc1 = nn.Linear(s_dim, 30) # 设置第一个全连接层(输入层到隐藏层): 状态维数个神经元到30个神经元
self.fc1.weight.data.normal_(0, 0.1) # 权重初始化 (均值为0,方差为0.1的正态分布)
self.out = nn.Linear(30, a_dim) # 设置第二个全连接层(隐藏层到输出层): 30个神经元到动作数个神经元
self.out.weight.data.normal_(0, 0.1) # 权重初始化 (均值为0,方差为0.1的正态分布)
许多已有的代码,例如莫烦教程里面的,都是直接采用gym里面的仿真环境,动作是一维的。但是实际运用算法解决问题的时候,可能需要结合自己的场景去搭环境,设计action和observation的维度。所以新手(也指我自己啦)可以去找一些场景比较简单的代码,了解环境怎么搭
2. 如何给Actor网络输出的动作添加约束,如何使得某些维的动作加起来为1?
a、有时候我们的动作可能会有一个上限约束,或者要求动作向量的某几维合为1。最简单的动作最大值约束可以看看这篇文章,直接在Actor网络的forward函数里面首先将输出动作经过一个tanh激活函数进行处理,将值压缩至区间[-1,1]内,然后乘上动作最大值
def forward(self,state):
state = torch.from_numpy(state).float()
x = F.relu(self.fc1(state))
x = F.relu(self.fc2(x))
x = F.relu(self.fc3(x))
action = torch.tanh(self.fc4(x))*self.action_limits # self.action_limits为限定的动作最大值
return action
b、另一个问题就是动作某些维有约束怎么办?例如某些维加起来为1。可以考虑直接采用softmax()激活函数,能够将所有输出值限定在(0,1),同时和为1。但是有可能会有上溢出或者下溢出的问题,解决方案参考softmax溢出问题
3. 输出的动作经过激活函数一直取边界值怎么办?
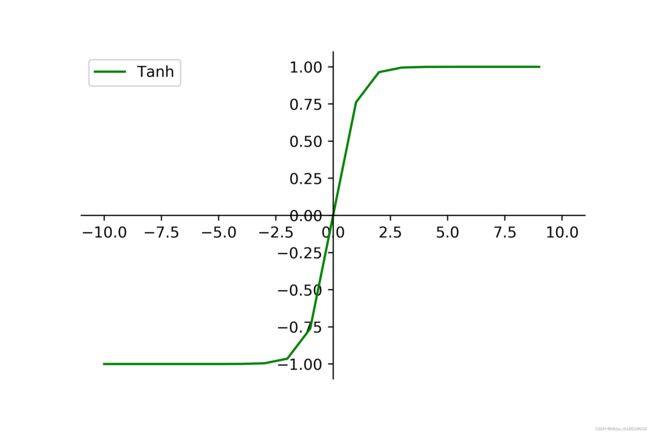
这个问题很大可能与输入状态的值有关,比如看一下tanh这个激活函数(图片来源),如果输入值特别大,就会始终输出1,反之特别小就只能输出-1。所以可以对输入状态进行归一化,具体的归一化方法有最大-最小值优化,具体可以去查一下,我自己的代码对输入归一化之后,效果好了不少。
4. 添加动作约束后,网络weight和bias不改变,网络参数的梯度为None,可能的原因
问题描述:
a、最开始我发现我每一个episode的结果都一样,网络相当于没有学习,所以去查看了actor网络和critic网络的weight和bias,发现actor网络的weight和bias一直是初始值,完全不发生改变:
print(self.actor.fc1.bias.data, self.actor.fc1.weight.data)
# self.actor是我定义的actor网络的名称;
# fc1是actor网络的某一层的名称
b、于是又去查看了actor网络参数的梯度,同时打印网络参数名称,是否为叶子节点,以及梯度是是否保留,最后一项是输出参数的梯度,可以看出,actor网络各层的参数的梯度都为None:
for name, param in self.actor.named_parameters():
print(name, param.is_leaf, param.requires_grad, param.grad)
# 结果如下:
episode= 0
fc1.weight True True None
fc1.bias True True None
fc2.weight True True None
fc2.bias True True None
fc4.weight True True None
fc4.bias True True None
解决办法:
我的网络参数更新部分主要参考了这位博主的文章,对应的actor网络的forward函数以及actor参数更新如下:
a、可以看到原始的动作是一个tensor,是有grad_fn的(grad_fn是一个tensor属性,作用在于计算梯度,见requires_grad,grad_fn,grad的作用) ,然后经过一个激活函数和最大值约束处理,输出的动作action也是张量,并且也是有grad_fn的,梯度被保留
#————————————————————————————————————actor forward函数————————————————————————
def forward(self,state):
# 这里输入的state为numpy类型,转化为tensor类型
state = torch.from_numpy(state).float()
x = F.relu(self.fc1(state))
x = F.relu(self.fc2(x))
x = F.relu(self.fc3(x))
action = torch.tanh(self.fc4(x))*self.action_limits
print('查看原始动作输出',self.fc4(x))
print('查看原始输出动作的梯度是否保留', self.fc4(x).requires_grad)
print('查看处理后的动作',action)
print('查看actions的梯度是否保留',action.requires_grad)
return action
# 输出:
查看原始动作输出 tensor([[ 0.1468, -0.0945],
[ 0.2414, -0.1756],
[ 0.2933, -0.3310],
...,
[ 0.1598, -0.1442],
[ 0.1160, -0.0202],
[ 0.1575, -0.0769]], grad_fn=<AddmmBackward0>)
查看原始输出动作的梯度是否保留 True
查看处理后的动作 tensor([[ 1889.1531, -1221.7098],
[ 3069.6135, -2252.6028],
[ 3695.8057, -4139.8857],
...,
[ 2053.7007, -1856.1440],
[ 1497.1184, -262.1638],
[ 2024.8003, -994.9755]], grad_fn=<MulBackward0>)
查看actions的梯度是否保留 True
b、但是我的actor网络对原始输出动作的处理更加复杂,在这里我【最开始将这里的tensor张量转化成了numpy类型,然后再进行处理】,这就是导致错误的一个原因。
—因为在神经网络的算法里面,通常都采用tensor类型,例如这篇文章的action还是state在网络中输入或者输出时都是用的tensor类型,但是在choose action,环境生成observation,以及存入memory的时候是采用的numpy类型。
—因此,由于actor网络不只是在choose action时需要用到,在更新网络参数时也需要调用actor的forward函数,要尽量保证其输出的动作是tensor类型的,如果需要对输出的动作转换为numpy,不要在forward函数内部处理。
—那怎么确保对原始输出的动作需要进行复杂的处理后,仍然能够在网络参数更新时,正常地反向传播呢?可以参考这篇文章,在20191126更新部分提到了对tensor元素进行赋值的注意事项,我采用的torch.cat(),最后actor网络forward函数输出的动作是有grad_fn的,requires_grad也为True,actor参数可以正常更新,梯度不为none
def learn_from_memory(self):
## 从memory中选择样本
s,a,r,s_,done = self.memory.sample(self.batch_size)
# 对样本进行进行数据类型的转换
s = np.array(s)
s_ = np.array(s_)
r = torch.tensor(r) # 可改为 r = torch.tensor(r,dtype=torch.float32)
print(r.dtype) # torch.int64
# 根据target_actor得到动作a_
a_ = self.target_actor.forward(s_).detach()
# 计算a_动作对应的target_critic(s_,a_)
next_val = torch.squeeze(self.target_critic.forward(s_,a_).detach())
y_expected = r + self.gamma*next_val
y_expected = torch.FloatTensor(y_expected)# 转换数据类型
# 下面计算预测值
a = torch.FloatTensor(a)
y_predicted = torch.squeeze(self.critic.forward(s,a))
# 计算损失项loss_critic
loss_critic = F.smooth_l1_loss(y_predicted,y_expected)
# 下面开始更新critic
self.critic_optimizer.zero_grad()
loss_critic.backward()
self.critic_optimizer.step()
# 下面开始更新actor——————网络参数更新失败主要的问题在于pred_a————————
pred_a = self.actor.forward(s)
loss_actor = -1*torch.sum(self.critic.forward(s,pred_a))
self.actor_optimizer.zero_grad()
loss_actor.backward()
self.actor_optimizer.step()
# 下面更新网络参数
soft_update(target=self.target_actor,source=self.actor,tau=self.tau)
soft_update(target=self.target_critic,source=self.critic,tau=self.tau)
return (loss_critic.item(),loss_actor.item()
c、还有一点,就是在actor网络中,choose_action时只需要输入当前环境的observation,但是在网络参数更新时(learn_from_memory),输入的就是全部样本对应的state,这一点需要注意。因为我在choose action时,不仅将observation输入到网络,在对actor网络原始输出动作进一步处理时,也用到了observation,这个observation只是当前的状态,与多个样本的state维度是不一样的,因此在网络参数更新时,输入全部样本的state到actor网络就有问题了,解决方案就是,将样本的state逐个输入actor网络,然后用torch.cat()将动作拼接起来(这个方法有点笨,但是能保证不出错)
d、最后是一些细节问题,这里learn_from_memory()函数,对样本中取出的奖励进行数据类型转换,源代码中的 r 类型为torch.int64,但是我查看自己的代码,r在类型转换后是 torch.float64(相当于double),于是下面就报错了,意思就是期望输入的是float类型,但是输入的是double类型,因此在数据类型转换时,指定 r 为torch.float32类型,代码就能正常跑了。
y_expected = torch.FloatTensor(y_expected) # 转换数据类型
TypeError: expected TensorOptions(dtype=float, device=cpu, layout=Strided, requires_grad=false (default), pinned_memory=false (default), memory_format=(nullopt)) (got TensorOptions(dtype=double, device=cpu, layout=Strided, requires_grad=false (default), pinned_memory=false (default), memory_format=(nullopt)))
总结:
这是我遇到的问题以及解决办法,还有一些小的出错点:
a、比如说在更新参数时,不要弄错target网络与原网络,以及网络输入的是当前state还是下一个state,都是比较细节的问题,我开始就输错了一次
b、最后actor网络的梯度有了,但是weight和bias的变化特别小,这也是需要进一步改进的;我之前了解到的是,可以调制learning rate,batch size,调整weight和bias初始化,目前还在探索中。
最后的最后,我是第一次做强化学习实验,不是专业的,记录这些遇到的问题,希望有所帮助!如果有更好的解决办法,也很乐意学习!