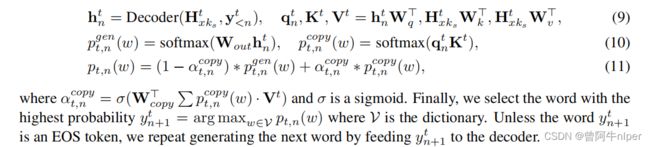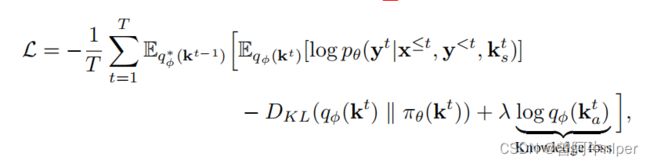- 【优秀文章】7月优秀文章推荐
优秀文章智能自主运动体与人工智能技术——环境感知、SLAM定位、路径规划、运动控制、多智能体协同作者:fpga和matlabC++之红黑树认识与实现作者:zzh_zao【手把手带你刷好题】–C语言基础编程题(十)作者:草莓熊Lotso飞算JavaAI:从“码农”到“代码指挥官”的终极进化论作者:可涵不会debug前端网页开发学习(HTML+CSS+JS)有这一篇就够!作者:一颗小谷粒
- 蛋白质结构预测/功能注释/交互识别/按需设计,中国海洋大学张树刚团队直击蛋白质智能计算核心任务
hyperai
蛋白质作为生命活动的主要承担者,在人体生理功能中扮演关键角色。然而传统研究面临结构解析成本高昂、功能注释严重滞后、新型蛋白质设计效率低下等挑战。近年来,生命科学对蛋白质复杂特性解析的需求日益迫切,大数据、深度学习、多模态计算等技术的突破性发展,为构建蛋白质智能计算体系提供了全新的发展契机。蛋白质智能计算体系的构建,使得蛋白质在大规模功能注释、交互预测及三维结构建模等领域取得显著成果,为药物发现与生
- C++17 并行算法:std::execution::par
在多核处理器普及的今天,如何高效利用硬件资源成为提升软件性能的关键。C++17引入的并行算法库(ParallelAlgorithms)为开发者提供了一套标准化的并行编程接口,通过简单的策略切换即可将顺序算法转换为并行执行。本文将深入探讨C++17并行算法中最核心的执行策略std::execution::par,从基础概念到高级应用,全面解析其原理、用法及最佳实践。一、C++17并行算法概述1.1并
- 【心灵鸡汤】深度学习技能形成树:从零基础到AI专家的成长路径全解析
智算菩萨
人工智能深度学习
引言:技能树的生长哲学在这个人工智能浪潮汹涌的时代,深度学习犹如一棵参天大树,其根系深深扎入数学与计算科学的沃土,主干挺拔地承载着机器学习的核心理念,而枝叶则繁茂地延伸至计算机视觉、自然语言处理、强化学习等各个应用领域。对于初入此领域的新手而言,理解这棵技能树的生长规律,掌握其形成过程中的关键节点和发展阶段,将直接决定其在人工智能道路上能够走多远、攀多高。技能树的概念源于游戏设计,但在学习深度学习
- 自然语言处理-基于预训练模型的方法-笔记
自然语言处理-基于预训练模型的方法-笔记【下载地址】自然语言处理-基于预训练模型的方法-笔记《自然语言处理-基于预训练模型的方法》由哈尔滨工业大学出版,深入探讨了NLP领域的前沿技术与预训练模型的应用。本书系统介绍了预训练模型的基本概念、发展历程及常见模型的原理,并通过丰富的实践案例与代码实现,帮助读者掌握这些技术在自然语言处理任务中的实际应用。无论是初学者、研发人员,还是希望提升NLP能力的研究
- 求平方根:牛顿迭代法
mjfztms
leetcode算法
应用牛顿迭代法求解方程近似解,收敛速度很快牛顿迭代法求解平方根给你一个非负整数x,计算并返回x的算术平方根n,结果只保留整数部分。算法流程图由题意得,n2=xn^2=xn2=x,即为对f(n)=n2−xf(n)=n^2-xf(n)=n2−x求解。第一步:易得:x2−x1=0−f(x1)f′(x1)x_2-x_1=\frac{0-f(x_1)}{f'(x_1)}x2−x1=f′(x1)0−f(x1)
- 【秋招算法】2025 届搜广推方向求职历程(SSP、头部计划)
秋冬无暖阳°
搜广推等—算法面经面试职场和发展算法
【秋招算法】2025届搜广推方向求职历程(SSP、头部计划)文章目录【秋招算法】2025届搜广推方向求职历程(SSP、头部计划)1.背景2.日常实习3.暑期实习3.1暑期BG3.2暑期记录4.秋招4.1秋招BG4.2转正4.3头部4.4提前批4.5正式批5.面试记录5.1Coding5.2其他高频编程题5.3常见八股、面经6.关于搜广推1.背景关于日常实习、暑期实习、提前批,秋招、春招、补招何为大
- 推荐算法(推广搜)——广告和推荐有什么不同?
导语近几年新兴起一个行业:推广搜。即推荐、广告、搜索算法的简称。各大厂都隐隐将其作为公司核心技术来发展。此文将带领大家探秘广告和推荐有什么区别以及其相似处。再此强调一下,广告算法里面的推荐广告和自然推荐结果里的推荐系统进行对比,但因为广告算法里面还有“搜索广告”,搜索广告和推荐系统差异性就太大了,这里不做讨论。一、不同点1.1本质不同推荐广告和自然推荐本质中要处理的群体和衡量的利益完全不一样。(图
- 算法分析与设计实验2:实现克鲁斯卡尔算法和prim算法
表白墙上别挂我
算法笔记经验分享
实验原理(一)克鲁斯卡尔算法:一种用于求解最小生成树问题的贪心算法,该算法的基本思想是按照边的权重从小到大排序,然后依次选择边,并加入生成树中,同时确保不会形成环路,直到生成树包含图中所有的顶点为止。具体步骤:边的排序:将所有边按照权重从小到大排序。初始化:创建一个空的生成树(可以是一个空的图结构),以及一个用于记录每个顶点所属集合(或称为连通分量)的数据结构(例如并查集)。边的选择:依次选择排序
- (面经总结)一篇文章带你整理面试过程中常考的九大排序算法
南淮北安
冲刺大厂之面经总结面经排序算法二分插入冒泡快速
文章目录一、二分插入排序1.原理2.代码二、冒泡排序1.原理2.代码三、插入排序算法1.原理2.代码四、快速排序算法1.原理2.代码五、希尔排序1.原理2.代码六、归并排序1.原理2.代码七、桶排序八、基数排序九、堆排序1.原理2.代码十、总结1.算法分类2.性能分析一、二分插入排序首先必须是排好序的数组,然后通过二分查找,找到合适的位置,插入1.原理二分查找算法又叫作折半查找,要求待查找的序列有
- Python常考面试题汇总(附答案)
TT图图
面试职场和发展
写在前面本文面向中高级Python开发,太基本的题目不收录。本文只涉及Python相关的面试题,关于网络、MySQL、算法等其他面试必考题会另外开专题整理。不是单纯的提供答案,抵制八股文!!更希望通过代码演示,原理探究等来深入讲解某一知识点,做到融会贯通。部分演示代码也放在了我的github的该目录下。语言基础篇Python的基本数据类型Python3中有六个标准的数据类型:Number(数字)(
- opencv-python与opencv-contrib-python的区别联系
剑心缘
零碎小知识pythonopencv
opencv-python包含基本的opencvopencv-contrib-python是高配版,带一些收费或者专利的算法,还有一些比较新的算法的高级版本,这些算法稳定之后会加入上面那个。官网对contrib模块的简介(点击链接跳转)参考链接
- 通信算法之278:数据链/自组网通信设备--MIMO(2T2R)-OFDM系统系列--实际工程应用算法代码--1.系统指标需求及帧结构设计
秋风战士
无线通信基带处理算法MATLAB仿真软件无线电算法无人机经验分享
MIMO(2T2R)-OFDM系统系列–实际工程应用算法代码第一章:系统指标需求拆解分析第二章:通信系统帧结构设计和OFDM参数设计第三章:通信业务速率设计及理论解调门限第四章:同步序列设计及同步性能仿真验证第五章:数据业务设计及性能仿真验证第六章:信道模型设计第七章:接收关键算法设计及仿真验证第八章:其它待补充本文目录MIMO(2T2R)-OFDM系统系列--实际工程应用算法代码一、实际项目:系
- 通信算法之287:通信技术点咨询
秋风战士
MATLAB仿真软件无线电无线通信基带处理算法网络算法无人机经验分享
专业技术咨询方向第一:SFBC编码与解码原理推导第二:SFBC系统中信道均衡推导第三:云哨物理层协议-速率匹配-解调门限-5dB第四:两天线SCFDE系统(SFBC码)帧结构设计第五:两天线OFDM系统(SFBC码)帧结构设计第一:SFBC编码与解码原理推导第二:SFBC系统中信道均衡推导第三:云哨物理层协议-速率匹配-解调门限-5dB第四:两天线SCFDE系统(SFBC码)帧结构设计第五:两天线
- 【计算机毕业设计】基于Springboot的办公用品管理系统+LW
枫叶学长(专业接毕设)
Java毕业设计实战案例课程设计springboot后端
博主介绍:✌全网粉丝3W+,csdn特邀作者、CSDN新星计划导师、Java领域优质创作者,掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流✌技术范围:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等设计与开发。主要内容:
- MongoDB + Voyage AI 详解:重塑数据库与AI的协同范式
csdn_tom_168
NoSQL数据库mongodb人工智能AI
MongoDB+VoyageAI详解:重塑数据库与AI的协同范式2025年2月,MongoDB官方宣布收购VoyageAI,这一举措标志着数据库与人工智能技术的深度融合迈入新阶段。通过整合VoyageAI的先进AI检索与嵌入模型能力,MongoDB旨在重新定义AI时代的数据库架构,为企业构建智能应用提供端到端的数据基础设施。一、收购背景与技术战略1.行业趋势驱动AI数据挑战:随着生成式AI与大语言
- HarmonyOS5.0仓颉引擎与盘古大模型:个性化作业批改系统架构设计与实现
H老师带你学鸿蒙
系统架构HarmonyOS5.0鸿蒙华为仓颉教育
人工智能与边缘计算的融合正在重塑教育评价体系。本文将展示如何基于HarmonyOS5.0仓颉并发引擎和盘古大模型,构建新一代智能作业批改系统。系统架构全景graphTDA[学生端设备]-->|提交作业|B[仓颉边缘处理]B-->C[盘古大模型分析]C-->D[个性化反馈生成]D-->E[学生终端]D-->F[教师仪表盘]subgraphHarmonyOS分布式系统B-->|设备协同|G[教室平板集
- 知识图谱的个性化智能教学推荐系统(论文+源码)
毕设工作室_wlzytw
python论文项目知识图谱人工智能
目录摘要Abstract目录第1章绪论1.1研究背景及意义1.2国内外研究现状1.2.1知识图谱1.2.2个性化推荐系统1.3本文研究内容及创新点1.4全文组织结构第2章相关理论与技术概述2.1知识图谱2.1.1知识图谱的介绍与发展2.1.2知识图谱的构建2.3协同过滤推荐算法2.2.1推荐算法概述2.2.2Pearson相关系数2.2.3Spearman相关系数2.4Bert模型和Albert模
- 反向传播神经网络极简入门
自信哥
单个神经元神经网络是多个“神经元”(感知机)的带权级联,神经网络算法可以提供非线性的复杂模型,它有两个参数:权值矩阵{Wl}和偏置向量{bl},不同于感知机的单一向量形式,{Wl}是复数个矩阵,{bl}是复数个向量,其中的元素分别属于单个层,而每个层的组成单元,就是神经元。神经元神经网络是由多个“神经元”(感知机)组成的,每个神经元图示如下:这其实就是一个单层感知机,其输入是由和+1组成的向量,其
- 阿里云瑶池数据库 Data Agent for Meta 正式发布,让 AI 更懂你的业务!
数据库观点资讯人工智能
背景随着生成式人工智能(GenerativeAI)从概念验证迈向规模化商业落地,AIAgent已成为企业核心业务流程的重要组成部分。然而,当模型调用日益便捷时,核心痛点已不再是模型本身,而是集中在一个关键要素上:数据。AIAgent的落地瓶颈已从技术能力转向高质量、高相关性、安全合规的数据供给。企业面临的核心挑战在于:数据孤岛导致知识库分散,通用大模型难以理解专业业务传统数据管理依赖人工开发维护,
- 【TVM 教程】如何处理 TVM 报错
ApacheTVM是一个深度的深度学习编译框架,适用于CPU、GPU和各种机器学习加速芯片。更多TVM中文文档可访问→https://tvm.hyper.ai/运行TVM时,可能会遇到如下报错:---------------------------------------------------------------AnerroroccurredduringtheexecutionofTVM.F
- 【限时干货】Calibre智能分类,轻松突破内网限制畅享电子书库
比头发还脆弱
服务器tcp/iplinux
文章目录前言1.网络书库软件下载安装2.网络书库服务器设置3.内网穿透工具设置4.公网使用kindle访问内网私人书库前言本研究旨在构建一套运行于微软操作系统环境下的独立电子图书管理体系,核心目标是建立可远程操作的资源访问机制。该架构采用高可用性设计,在第三方阅读平台服务中断时仍能保障数字内容传输的稳定性。系统创新性地融合了两大核心技术组件:通过Calibre开源软件实现文献分类算法与格式转换功能
- 【PaddleOCR】OCR文本检测与文本识别数据集整理,持续更新......
博主简介:曾任某智慧城市类企业算法总监,目前在美国市场的物流公司从事高级算法工程师一职,深耕人工智能领域,精通python数据挖掘、可视化、机器学习等,发表过AI相关的专利并多次在AI类比赛中获奖。CSDN人工智能领域的优质创作者,提供AI相关的技术咨询、项目开发和个性化解决方案等服务,如有需要请站内私信或者联系任意文章底部的的VX名片(ID:xf982831907)博主粉丝群介绍:①群内初中生、
- 多模态大模型的技术应用与未来展望:重构AI交互范式的新引擎
zhaoyi_he
重构人工智能
一、引言:为什么多模态是AI发展的下一场革命?过去十年,深度学习推动了计算机视觉和自然语言处理的飞跃,但两者的发展路径长期割裂。随着生成式AI和大模型时代的到来,**多模态大模型(MultimodalFoundationModels)**以统一的建模方式处理图像、文本、音频、视频等多源数据,重塑了“感知-认知-决策”链条,为AGI迈出关键一步。OpenAI的GPT-4o、Google的Gemini
- 说话人识别python_基于各种分类算法的说话人识别(年龄段识别)
weixin_39673184
说话人识别python
基于各种分类算法的语音分类(年龄段识别)概述实习期间作为帮手打杂进行了一段时间的语音识别研究,内容是基于各种分类算法的语音的年龄段识别,总结一下大致框架,基本思想是:获取语料库TIMIT提取数据特征,进行处理MFCC/i-vectorLDA/PLDA/PCA语料提取,基于分类算法进行分类SVM/SVR/GMM/GBDT...用到的工具有HTK(C,shell)/Kaldi(C++,shell)/L
- 使用 C++ 实现 MFCC 特征提取与说话人识别系统
whoarethenext
c++开发语言mfcc语音识别
使用C++实现MFCC特征提取与说话人识别系统在音频处理和人工智能领域,C++凭借其卓越的性能和对硬件的底层控制能力,在实时音频分析、嵌入式设备和高性能计算场景中占据着不可或缺的地位。本文将引导你了解如何使用C++库计算核心的音频特征——梅尔频率倒谱系数(MFCCs),并进一步利用这些特征构建一个说话人识别(声纹识别)系统。Part1:在C/C++中计算MFCCs直接从零开始实现MFCC的所有计算
- 深入解析C++中 std::sort背后的实现原理 —Introsort(Introspective Sort)
点云SLAM
C++c++算法数据结构快速排序排序算法堆排序深度优先
Introsort简介Introsort是一种混合排序算法,结合了三种经典算法的优点:算法用于特点快速排序通常情况平均时间复杂度O(nlogn)堆排序当快速排序退化(递归过深)时最坏时间复杂度O(nlogn)插入排序小规模数组时(如长度≤16)常数开销小,快Introsort运行机制排序逻辑如下:if(size2*log2(n))堆排序(HeapSort)else快速排序(QuickSort)快速
- 冒泡排序算法详解(含Python代码实现)
算法_小学生
算法
冒泡排序(BubbleSort)是最基础的排序算法之一,通常用于学习排序算法的入门理解。本文将通过Python代码实现冒泡排序,并详细讲解其原理、执行流程、复杂度分析及适用情况。✨一、算法简介冒泡排序的核心思想是:相邻两个元素比较,将较大的元素不断“冒泡”至右侧,最终实现排序。其基本过程是重复比较相邻的元素,如果顺序错误就交换,重复这一过程,直到没有任何需要交换的为止。二、Python代码实现下面
- 揭秘 Spring Cloud Zuul 在后端的负载均衡策略
大厂资深架构师
SpringBoot开发实战springcloud负载均衡springai
揭秘SpringCloudZuul在后端的负载均衡策略关键词:SpringCloudZuul、负载均衡、微服务网关、Ribbon、请求路由摘要:在微服务架构中,API网关是流量的“总调度员”,而负载均衡则是它的“智能大脑”。本文将以“小区门卫派件”为故事主线,用通俗易懂的语言揭秘SpringCloudZuul如何通过集成Ribbon实现后端负载均衡。我们将从核心概念到算法原理,从代码实战到应用场景
- ImportError: /nvidia/cusparse/lib/libcusparse.so.12: undefined symbol: __nvJitLinkComplete_12_4
爱编程的喵喵
Python基础课程pythonImportErrortorchnvJitLink解决方案
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的知识进行总结与归纳,不仅形成深入且独到的理解,而且能够帮助新手快速入门。 本文主要介绍了ImportError:/home/
- Spring的注解积累
yijiesuifeng
spring注解
用注解来向Spring容器注册Bean。
需要在applicationContext.xml中注册:
<context:component-scan base-package=”pagkage1[,pagkage2,…,pagkageN]”/>。
如:在base-package指明一个包
<context:component-sc
- 传感器
百合不是茶
android传感器
android传感器的作用主要就是来获取数据,根据得到的数据来触发某种事件
下面就以重力传感器为例;
1,在onCreate中获得传感器服务
private SensorManager sm;// 获得系统的服务
private Sensor sensor;// 创建传感器实例
@Override
protected void
- [光磁与探测]金吕玉衣的意义
comsci
这是一个古代人的秘密:现在告诉大家
信不信由你们:
穿上金律玉衣的人,如果处于灵魂出窍的状态,可以飞到宇宙中去看星星
这就是为什么古代
- 精简的反序打印某个数
沐刃青蛟
打印
以前看到一些让求反序打印某个数的程序。
比如:输入123,输出321。
记得以前是告诉你是几位数的,当时就抓耳挠腮,完全没有思路。
似乎最后是用到%和/方法解决的。
而今突然想到一个简短的方法,就可以实现任意位数的反序打印(但是如果是首位数或者尾位数为0时就没有打印出来了)
代码如下:
long num, num1=0;
- PHP:6种方法获取文件的扩展名
IT独行者
PHP扩展名
PHP:6种方法获取文件的扩展名
1、字符串查找和截取的方法
1
$extension
=
substr
(
strrchr
(
$file
,
'.'
), 1);
2、字符串查找和截取的方法二
1
$extension
=
substr
- 面试111
文强chu
面试
1事务隔离级别有那些 ,事务特性是什么(问到一次)
2 spring aop 如何管理事务的,如何实现的。动态代理如何实现,jdk怎么实现动态代理的,ioc是怎么实现的,spring是单例还是多例,有那些初始化bean的方式,各有什么区别(经常问)
3 struts默认提供了那些拦截器 (一次)
4 过滤器和拦截器的区别 (频率也挺高)
5 final,finally final
- XML的四种解析方式
小桔子
domjdomdom4jsax
在平时工作中,难免会遇到把 XML 作为数据存储格式。面对目前种类繁多的解决方案,哪个最适合我们呢?在这篇文章中,我对这四种主流方案做一个不完全评测,仅仅针对遍历 XML 这块来测试,因为遍历 XML 是工作中使用最多的(至少我认为)。 预 备 测试环境: AMD 毒龙1.4G OC 1.5G、256M DDR333、Windows2000 Server
- wordpress中常见的操作
aichenglong
中文注册wordpress移除菜单
1 wordpress中使用中文名注册解决办法
1)使用插件
2)修改wp源代码
进入到wp-include/formatting.php文件中找到
function sanitize_user( $username, $strict = false
- 小飞飞学管理-1
alafqq
管理
项目管理的下午题,其实就在提出问题(挑刺),分析问题,解决问题。
今天我随意看下10年上半年的第一题。主要就是项目经理的提拨和培养。
结合我自己经历写下心得
对于公司选拔和培养项目经理的制度有什么毛病呢?
1,公司考察,选拔项目经理,只关注技术能力,而很少或没有关注管理方面的经验,能力。
2,公司对项目经理缺乏必要的项目管理知识和技能方面的培训。
3,公司对项目经理的工作缺乏进行指
- IO输入输出部分探讨
百合不是茶
IO
//文件处理 在处理文件输入输出时要引入java.IO这个包;
/*
1,运用File类对文件目录和属性进行操作
2,理解流,理解输入输出流的概念
3,使用字节/符流对文件进行读/写操作
4,了解标准的I/O
5,了解对象序列化
*/
//1,运用File类对文件目录和属性进行操作
//在工程中线创建一个text.txt
- getElementById的用法
bijian1013
element
getElementById是通过Id来设置/返回HTML标签的属性及调用其事件与方法。用这个方法基本上可以控制页面所有标签,条件很简单,就是给每个标签分配一个ID号。
返回具有指定ID属性值的第一个对象的一个引用。
语法:
&n
- 励志经典语录
bijian1013
励志人生
经典语录1:
哈佛有一个著名的理论:人的差别在于业余时间,而一个人的命运决定于晚上8点到10点之间。每晚抽出2个小时的时间用来阅读、进修、思考或参加有意的演讲、讨论,你会发现,你的人生正在发生改变,坚持数年之后,成功会向你招手。不要每天抱着QQ/MSN/游戏/电影/肥皂剧……奋斗到12点都舍不得休息,看就看一些励志的影视或者文章,不要当作消遣;学会思考人生,学会感悟人生
- [MongoDB学习笔记三]MongoDB分片
bit1129
mongodb
MongoDB的副本集(Replica Set)一方面解决了数据的备份和数据的可靠性问题,另一方面也提升了数据的读写性能。MongoDB分片(Sharding)则解决了数据的扩容问题,MongoDB作为云计算时代的分布式数据库,大容量数据存储,高效并发的数据存取,自动容错等是MongoDB的关键指标。
本篇介绍MongoDB的切片(Sharding)
1.何时需要分片
&nbs
- 【Spark八十三】BlockManager在Spark中的使用场景
bit1129
manager
1. Broadcast变量的存储,在HttpBroadcast类中可以知道
2. RDD通过CacheManager存储RDD中的数据,CacheManager也是通过BlockManager进行存储的
3. ShuffleMapTask得到的结果数据,是通过FileShuffleBlockManager进行管理的,而FileShuffleBlockManager最终也是使用BlockMan
- yum方式部署zabbix
ronin47
yum方式部署zabbix
安装网络yum库#rpm -ivh http://repo.zabbix.com/zabbix/2.4/rhel/6/x86_64/zabbix-release-2.4-1.el6.noarch.rpm 通过yum装mysql和zabbix调用的插件还有agent代理#yum install zabbix-server-mysql zabbix-web-mysql mysql-
- Hibernate4和MySQL5.5自动创建表失败问题解决方法
byalias
J2EEHibernate4
今天初学Hibernate4,了解了使用Hibernate的过程。大体分为4个步骤:
①创建hibernate.cfg.xml文件
②创建持久化对象
③创建*.hbm.xml映射文件
④编写hibernate相应代码
在第四步中,进行了单元测试,测试预期结果是hibernate自动帮助在数据库中创建数据表,结果JUnit单元测试没有问题,在控制台打印了创建数据表的SQL语句,但在数据库中
- Netty源码学习-FrameDecoder
bylijinnan
javanetty
Netty 3.x的user guide里FrameDecoder的例子,有几个疑问:
1.文档说:FrameDecoder calls decode method with an internally maintained cumulative buffer whenever new data is received.
为什么每次有新数据到达时,都会调用decode方法?
2.Dec
- SQL行列转换方法
chicony
行列转换
create table tb(终端名称 varchar(10) , CEI分值 varchar(10) , 终端数量 int)
insert into tb values('三星' , '0-5' , 74)
insert into tb values('三星' , '10-15' , 83)
insert into tb values('苹果' , '0-5' , 93)
- 中文编码测试
ctrain
编码
循环打印转换编码
String[] codes = {
"iso-8859-1",
"utf-8",
"gbk",
"unicode"
};
for (int i = 0; i < codes.length; i++) {
for (int j
- hive 客户端查询报堆内存溢出解决方法
daizj
hive堆内存溢出
hive> select * from t_test where ds=20150323 limit 2;
OK
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
问题原因: hive堆内存默认为256M
这个问题的解决方法为:
修改/us
- 人有多大懒,才有多大闲 (评论『卓有成效的程序员』)
dcj3sjt126com
程序员
卓有成效的程序员给我的震撼很大,程序员作为特殊的群体,有的人可以这么懒, 懒到事情都交给机器去做 ,而有的人又可以那么勤奋,每天都孜孜不倦得做着重复单调的工作。
在看这本书之前,我属于勤奋的人,而看完这本书以后,我要努力变成懒惰的人。
不要在去庞大的开始菜单里面一项一项搜索自己的应用程序,也不要在自己的桌面上放置眼花缭乱的快捷图标
- Eclipse简单有用的配置
dcj3sjt126com
eclipse
1、显示行号 Window -- Prefences -- General -- Editors -- Text Editors -- show line numbers
2、代码提示字符 Window ->Perferences,并依次展开 Java -> Editor -> Content Assist,最下面一栏 auto-Activation
- 在tomcat上面安装solr4.8.0全过程
eksliang
Solrsolr4.0后的版本安装solr4.8.0安装
转载请出自出处:
http://eksliang.iteye.com/blog/2096478
首先solr是一个基于java的web的应用,所以安装solr之前必须先安装JDK和tomcat,我这里就先省略安装tomcat和jdk了
第一步:当然是下载去官网上下载最新的solr版本,下载地址
- Android APP通用型拒绝服务、漏洞分析报告
gg163
漏洞androidAPP分析
点评:记得曾经有段时间很多SRC平台被刷了大量APP本地拒绝服务漏洞,移动安全团队爱内测(ineice.com)发现了一个安卓客户端的通用型拒绝服务漏洞,来看看他们的详细分析吧。
0xr0ot和Xbalien交流所有可能导致应用拒绝服务的异常类型时,发现了一处通用的本地拒绝服务漏洞。该通用型本地拒绝服务可以造成大面积的app拒绝服务。
针对序列化对象而出现的拒绝服务主要
- HoverTree项目已经实现分层
hvt
编程.netWebC#ASP.ENT
HoverTree项目已经初步实现分层,源代码已经上传到 http://hovertree.codeplex.com请到SOURCE CODE查看。在本地用SQL Server 2008 数据库测试成功。数据库和表请参考:http://keleyi.com/a/bjae/ue6stb42.htmHoverTree是一个ASP.NET 开源项目,希望对你学习ASP.NET或者C#语言有帮助,如果你对
- Google Maps API v3: Remove Markers 移除标记
天梯梦
google maps api
Simply do the following:
I. Declare a global variable:
var markersArray = [];
II. Define a function:
function clearOverlays() {
for (var i = 0; i < markersArray.length; i++ )
- jQuery选择器总结
lq38366
jquery选择器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40
- 基础数据结构和算法六:Quick sort
sunwinner
AlgorithmQuicksort
Quick sort is probably used more widely than any other. It is popular because it is not difficult to implement, works well for a variety of different kinds of input data, and is substantially faster t
- 如何让Flash不遮挡HTML div元素的技巧_HTML/Xhtml_网页制作
刘星宇
htmlWeb
今天在写一个flash广告代码的时候,因为flash自带的链接,容易被当成弹出广告,所以做了一个div层放到flash上面,这样链接都是a触发的不会被拦截,但发现flash一直处于div层上面,原来flash需要加个参数才可以。
让flash置于DIV层之下的方法,让flash不挡住飘浮层或下拉菜单,让Flash不档住浮动对象或层的关键参数:wmode=opaque。
方法如下:
- Mybatis实用Mapper SQL汇总示例
wdmcygah
sqlmysqlmybatis实用
Mybatis作为一个非常好用的持久层框架,相关资料真的是少得可怜,所幸的是官方文档还算详细。本博文主要列举一些个人感觉比较常用的场景及相应的Mapper SQL写法,希望能够对大家有所帮助。
不少持久层框架对动态SQL的支持不足,在SQL需要动态拼接时非常苦恼,而Mybatis很好地解决了这个问题,算是框架的一大亮点。对于常见的场景,例如:批量插入/更新/删除,模糊查询,多条件查询,联表查询,