GAT源码维度变换详解
以下仅个人理解,请多多指正。
代码地址: https://github.com/Diego999/pyGAT
models.py(部分)
class GAT(nn.Module):
def __init__(self, nfeat, nhid, nclass, dropout, alpha, nheads):
super(GAT, self).__init__()
self.dropout = dropout
self.attentions = [GraphAttentionLayer(nfeat, nhid, dropout=dropout, alpha=alpha, concat=True) for _ in range(nheads)]
for i, attention in enumerate(self.attentions):
self.add_module('attention_{}'.format(i), attention)
self.out_att = GraphAttentionLayer(nhid * nheads, nclass, dropout=dropout, alpha=alpha, concat=False)
def forward(self, x, adj):
x = F.dropout(x, self.dropout, training=self.training)
x = torch.cat([att(x, adj) for att in self.attentions], dim=1)
x = F.dropout(x, self.dropout, training=self.training)
x = F.elu(self.out_att(x, adj))
return F.log_softmax(x, dim=1)
layers.py(部分)
class GraphAttentionLayer(nn.Module):
def __init__(self, in_features, out_features, dropout, alpha, concat=True):
super(GraphAttentionLayer, self).__init__()
self.dropout = dropout
self.in_features = in_features
self.out_features = out_features
self.alpha = alpha
self.concat = concat
self.W = nn.Parameter(torch.empty(size=(in_features, out_features)))
nn.init.xavier_uniform_(self.$W$.data, gain=1.414)
self.a = nn.Parameter(torch.empty(size=(2*out_features, 1)))
nn.init.xavier_uniform_(self.a.data, gain=1.414)
self.leakyrelu = nn.LeakyReLU(self.alpha)
def forward(self, h, adj):
Wh = torch.mm(h, self.W)
a_input = self._prepare_attentional_mechanism_input(Wh)
e = self.leakyrelu(torch.matmul(a_input, self.a).squeeze(2))
zero_vec = -9e15*torch.ones_like(e)
attention = torch.where(adj > 0, e, zero_vec)
attention = F.softmax(attention, dim=1)
attention = F.dropout(attention, self.dropout, training=self.training)
h_prime = torch.matmul(attention, Wh)
if self.concat:
return F.elu(h_prime)
else:
return h_prime
def _prepare_attentional_mechanism_input(self, Wh):
N = Wh.size()[0]
Wh_repeated_in_chunks = Wh.repeat_interleave(N, dim=0)
Wh_repeated_alternating = Wh.repeat(N, 1)
all_combinations_matrix = torch.cat([Wh_repeated_in_chunks, Wh_repeated_alternating], dim=1)
return all_combinations_matrix.view(N, N, 2 * self.out_features)
在训练开始之前,首先了解_prepare_attentional_mechanism_input()函数:
Wh_repeated_in_chunks = Wh.repeat_interleave(N, dim=0)表示对第0个维度复制N遍
Wh_repeated_alternating = Wh.repeat(N, 1)表示对第1个维度复制N遍
下面创建了两个矩阵,它们在行中的嵌入顺序不同:
这些是第一个矩阵的一行 (Wh_repeated_in_chunks):
e1, e1, ..., e1, e2, e2, ..., e2, ..., eN, eN, ..., eN
这些是第二个矩阵的一行 (Wh_repeated_alternating):
e1, e2, ..., eN, e1, e2, ..., eN, ..., e1, e2, ..., eN
则Wh_repeated_in_chunks.shape == Wh_repeated_alternating.shape == (N * N, out_features)
接着all_combinations_matrix = torch.cat([Wh_repeated_in_chunks, Wh_repeated_alternating], dim=1)
相当于在第1维上做全连接操作,得到了(N * N, 2 * out_features)的矩阵。
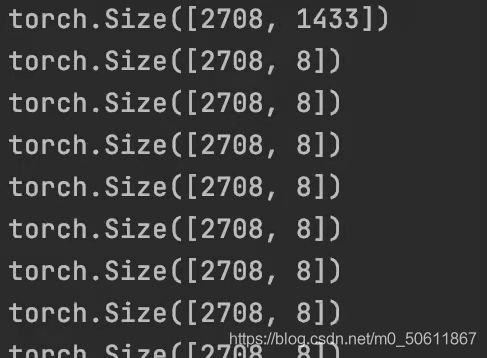
这个是我训练之前debug的结果,因此为了描述方便我们设输入特征矩阵 x x x维度为(2708,1433),nheads=8,nclass=7,nhid=8,nfeat=features.shape[1]=1433)
训练过程(只关注维度变化):
首先输入 x x x(2708,1433)和 a d j adj adj (2708,2708)
第一步:
x = F.dropout(x, self.dropout, training=self.training)
dropout不改变 x x x的维度, x x x仍为(2708,1433)
第二步(输入到隐藏层):
x = torch.cat([att(x, adj) for att in self.attentions], dim=1)
self.attentions = [GraphAttentionLayer(nfeat, nhid, dropout=dropout, alpha=alpha, concat=True) for _ in range(nheads)]
def __init__(self, in_features, out_features, dropout, alpha, concat=True):
a t t att att( x x x, a d j adj adj)在self.attentions中循环,次数为nheads,即为8次
由对应参数可知,in_features=nfeat ,out_features=nhid
权重矩阵 W W W(nfeat,nhid)= (1433,8)
注意机制 a(2 * hid,1)=(16,1)
W W Wh= torch.mm(h, self. W W W)= torch.mm(x, self. W W W) ,维度为(2708,1433)(1433,8)=(2708,8)
a_input= self._prepare_attentional_mechanism_input( W W Wh),维度为(27082708,16)
a t t e n t i o n attention attention的维度与 a d j adj adj一样,为(2708,2708)
h_prime = torch.matmul(attention, W W Wh),维度为(2708,8)
则 att( x x x, a d j adj adj)返回的 x x x维度为(2708,8),在第1维上做全连接之后 x x x维度为(2708,64)

第三步:
x = F.dropout(x, self.dropout, training=self.training)
第四步(隐藏层到输出):
x = F.elu(self.out_att(x, adj))
self.out_att = GraphAttentionLayer(nhid * nheads, nclass, dropout=dropout,alpha=alpha, concat=False)
def __init__(self, in_features, out_features, dropout, alpha, concat=True):
由对应参数可知,in_features=nhid * nheads ,out_features=nclass
权重矩阵 W W W(nhid * nheads,nclass)= (64,7)
注意机制 a a a(2nclass,1)=(14,1)
W W Wh= torch.mm(h, self. W W W) =h= torch.mm(x, self. W W W),维度为(2708,64)(64,7)=(2708,7)
a_input= self._prepare_attentional_mechanism_input( W W Wh),维度为(2708*2708,14)
attention的维度与 a d j adj adj一样,为(2708,2708)
h_prime = torch.matmul(attention, W W Wh),维度为(2708,7)
则 a t t att att( x x x, a d j adj adj)返回的 x x x维度为(2708,7)
