2021-03-27 深度信念网络(DBN)学习笔记
目录
前言
1.BM
2.RBM
二、DBN
总结
前言
仅此以记录学习过程。深度信念网络(DBN)通过采用逐层训练的方式,解决了深层次神经网络的优化问题,通过逐层训练为整个网络赋予了较好的初始权值,使得网络只要经过微调就可以达到最优解。而在逐层训练的时候起到最重要作用的是“受限玻尔兹曼机”(Restricted Boltzmann Machines,简称RBM),为什么叫“受限玻尔兹曼机”呢?因为还有一个是不受限的,那就是“玻尔兹曼机”(Boltzmann Machines,简称BM)。
先简要记录下BM和RBM,后展开DBN的学习。
一、BM/RBM
1.BM
受限玻尔兹曼机(RBM)的核心点在于:能量收敛到最小后,热平衡趋于稳定,也就是说,在能量最少的时候,网络最稳定,此时网络最优。
玻尔兹曼机(BM)是由随机神经元全连接组成的反馈神经网络,且对称连接,由可见层、隐层组成,BM可以看做是一个无向图,如下图所示:

其中,x1、x2、x3为可见层,x4、x5、x6为隐层。
整个能量函数定义为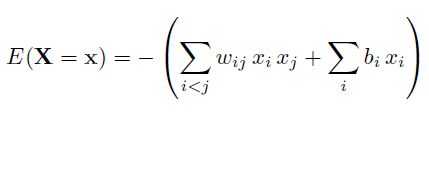
其中,w为权重,b为偏置变量,x只有{0,1}两种状态。
根据玻尔兹曼分布,给出的一个系统在特定状态能量和系统温度下的概率分布,如下:
前面讲过,“能量最少的时候,网络最稳定,此时网络最优”,因此要训练寻找参数使得整个网络的能量最小。计算很复杂,而且整个计算过程会十分地耗时(此处不做详细解剖,抛砖引玉)。玻尔兹曼机代价是训练时间很长很长很长。
2.RBM
所谓“受限玻尔兹曼机”(RBM)就是对“玻尔兹曼机”(BM)进行简化,使玻尔兹曼机更容易更加简单使用,原本玻尔兹曼机的可见元和隐元之间是全连接的,而且隐元和隐元之间也是全连接的,这样就增加了计算量和计算难度。
“受限玻尔兹曼机”(RBM)同样具有一个可见层,一个隐层,但层内无连接,层与层之间全连接,节点变量仍然取值为0或1,是一个二分图。也就是将“玻尔兹曼机”(BM)的层内连接去掉,对连接进行限制,就变成了“受限玻尔兹曼机”(RBM),这样就使得计算量大大减小,使用起来也就方便了很多。如下图。
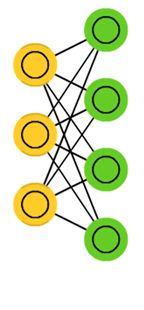
“受限玻尔兹曼机”(RBM)的特点是:在给定可见层单元状态(输入数据)时,各隐层单元的激活条件是独立的(层内无连接),同样,在给定隐层单元状态时,可见层单元的激活条件也是独立的。
跟“玻尔兹曼机”(BM)类似,根据玻尔兹曼分布,可见层(变量为v,偏置量为a)、隐层(变量为h,偏置量为b)的概率为:
训练样本的对数似然函数为: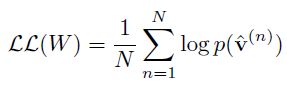
求导数: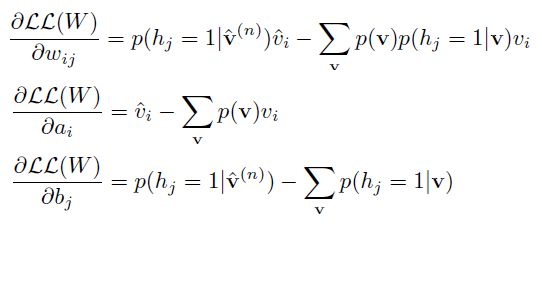
总之,还是挺复杂的,计算也还是挺花时间的。
同样,可以通过Gibbs 采样的方法来近似计算。虽然比一般的玻尔兹曼机速度有很大提高,但一般还是需要通过很多步采样才可以采集到符合真实分布的样本。这就使得受限玻尔兹曼机的训练效率仍然不高。
2002年,大神Hinton再出手,提出了“对比散度”(Contrastive Divergence,简称CD)算法,这是一种比Gibbs采样更加有效的学习算法,促使大家对RBM的关注和研究。
RBM的本质是非监督学习的利器,可以用于降维(隐层设置少一点)、学习提取特征(隐层输出就是特征)、自编码器(AutoEncoder)以及深度信念网络(多个RBM堆叠而成)等等。
二、DBN
2006年,Hinton大神出手了,提出了“深度信念网络”(DBN),并给出了该模型一个高效的学习算法,这也成了深度学习算法的主要框架,在该算法中,一个DBN模型由若干个RBM堆叠而成,训练过程由低到高逐层进行训练,如
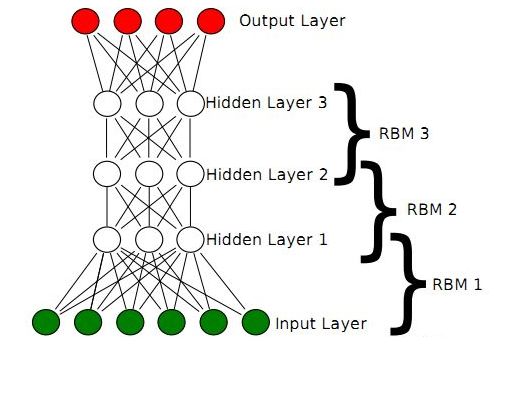
回想一下RBM,由可见层、隐层组成,显元用于接受输入,隐元用于提取特征,因此隐元也有个别名,叫特征检测器。也就是说,通过RBM训练之后,可以得到输入数据的特征。(感性对比:联想一下主成分分析,提取特征)
另外,RBM还通过学习将数据表示成概率模型,一旦模型通过无监督学习被训练或收敛到一个稳定的状态,它还可以被用于生成新数据。(感性对比:联想一下曲线拟合,得出函数,可用于生成数据)
正是由于RBM的以上特点,使得DBN逐层进行训练变得有效,通过隐层提取特征使后面层次的训练数据更加有代表性,通过可生成新数据能解决样本量不足的问题。逐层的训练过程如下:
(1)最底部RBM以原始输入数据进行训练
(2)将底部RBM抽取的特征作为顶部RBM的输入继续训练
(3)重复这个过程训练以尽可能多的RBM层
由于RBM可通过CD快速训练,于是这个框架绕过直接从整体上对DBN高度复杂的训练,而是将DBN的训练简化为对多个RBM的训练,从而简化问题。而且通过这种方式训练后,可以再通过传统的全局学习算法(如BP算法)对网络进行微调,从而使模型收敛到局部最优点,通过这种方式可高效训练出一个深层网络出来,如下图所示:
总结
Hinton提出,这种预训练过程是一种无监督的逐层预训练的通用技术,也就是说,不是只有RBM可以堆叠成一个深度网络,其它类型的网络也可以使用相同的方法来生成网络。
————————————————
版权声明:本文为CSDN博主「雪饼ai」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/rogerchen1983/article/details/79407386