【MediaPipe】(4) AI视觉,远程手势调节电脑音量,附python完整代码
各位同学好,今天和大家分享一下如何使用MediaPipe完成手势调节电脑音量,先放张图看效果。
注意!!
本节需要用到手部关键点的实时跟踪,我已经在之前的文章中详细写过了,本节会直接使用,有疑问的同学可以看我的这一篇文章:【MediaPipe】(1) AI视觉,手部关键点实时跟踪,附python完整代码
1. 导入工具包,编写主程序
# 安装opencv
pip install opencv-contrib-python
# 安装mediapipe
pip install mediapipe
# pip install mediapipe --user #有user报错的话试试这个
# 安装之后导入各个包
import cv2 #opencv
import mediapipe as mp
import time把工具包导入后,编写主程序,主程序只读取视频图像,将每一帧图像传给自定义函数。所有的手势处理均在自定义函数中完成。
handtracking是存放自定义函数的.py文件名。cap.read()读取视频帧图像,每执行一次,就读取一帧图像,返回值succes中存放视频是否成功被打开,img存放每一帧图像信息。
htm.handDetector() 中 handDetector() 是自定义的 handtracking.py 文件中定义的函数,将读取的图像数据img传给这个函数。
import cv2
import numpy as np
import time
import handtracking as htm
#(1)获取摄像头
cap = cv2.VideoCapture(0) # 0代表自己电脑的摄像头
cap.set(3, 1080) # 设置相机图像宽度1080
cap.set(4, 720) # 设置相机图像高度720
pTime = 0 # 处理第一帧图像的起始时间
#(3)处理每一帧图像
while True:
# 返回是否打开摄像头,以及每一帧的图像
success, img = cap.read()
# 调用手部关键点检测函数
# 返回拇指"4"和食指"8"的坐标信息,存放在lmList中
# 返回图像img,已经在食指和拇指关键点上画圈
# 返回音量vol
img, lmList = htm.handDetector(img)
# 记录处理每帧图像所花的时间
cTime = time.time()
fps = 1/(cTime-pTime) # 计算fps
pTime = cTime # 更新下一帧图像处理的起始时间
# 把fps值显示在图像上,img画板;fps变成字符串;显示的位置;设置字体;字体大小;字体颜色;线条粗细
cv2.putText(img, f'FPS: {str(int(fps))}', (10,50), cv2.FONT_HERSHEY_COMPLEX, 2, (0,255,0), 3)
# 显示图像,输入窗口名及图像数据
cv2.imshow('image', img)
if cv2.waitKey(1) & 0xFF==27: #每帧滞留1毫秒后消失,ESC键退出
break
# 释放视频资源
cap.release()
cv2.destroyAllWindows()
2. 拇指和食指间的连线
新定义一个文件 handtracking.py ,放在和主程序的相同文件夹下。
下面的程序中(1)和(2)部分有不明白的,可看一下我的手部关键点检测的文章:【MediaPipe】(1) AI视觉,手部关键点实时跟踪,附python完整代码
手部关键点标记如下图所示:

下面我解释一下如何绘制指尖连线,需要绘制拇指和食指间的连线,首先获取这两个关键点的坐标,每一个索引index对应一个关键点的xy坐标,每一帧图像有21个索引,也就有21个关键点坐标。由上图可知,拇指对应的索引为4,食指对应的索引为8,分别将其坐标表示为(x1, y1)和(x2, y2),接下去我们只需要处理这两个关键点即可。
使用 cv2.circle() 以这两个关键点为圆心画圆,在屏幕上突出显示出两个关键点。使用 cv2.line() 给出线段的起点和终点坐标,绘制两指间的连线。
import mediapipe as mp
import cv2
#(1)创建检测手部关键点的方法
mpHands = mp.solutions.hands #接收方法
hands = mpHands.Hands(static_image_mode=False, #静态追踪,低于0.5置信度会再一次跟踪
max_num_hands=2, # 最多有2只手
min_detection_confidence=0.6, # 最小检测置信度
min_tracking_confidence=0.5) # 最小跟踪置信度
# 创建检测手部关键点和关键点之间连线的方法
mpDraw = mp.solutions.drawing_utils
# 存放坐标信息
lmList = []
#(2)对传入的每一帧图像处理
def handDetector(img):
# 把图像传入检测模型,提取信息
results = hands.process(img)
# 检查每帧图像是否有多只手,一一提取它们
if results.multi_hand_landmarks: #如果没有手就是None
for handlms in results.multi_hand_landmarks:
# 绘制关键点及连线,mpHands.HAND_CONNECTIONS绘制手部关键点之间的连线
mpDraw.draw_landmarks(img, handlms, mpHands.HAND_CONNECTIONS)
# 获取每个关键点的索引和坐标
for index, lm in enumerate(handlms.landmark):
# 将xy的比例坐标转换成像素坐标
h, w, c = img.shape # 分别存放图像长\宽\通道数
# 中心坐标(小数),必须转换成整数(像素坐标)
cx ,cy = int(lm.x * w), int(lm.y * h) #比例坐标x乘以宽度得像素坐标
#(3)分别处理拇指"4"和食指"8"的像素坐标
if index == 4:
x1, y1 = cx, cy
if index == 8:
x2, y2 = cx, cy
# 打印坐标信息
print("4", x1, y1, ", 8", x2, y2)
# 保存坐标点
lmList.append([[x1,y1],[x2,y2]])
# 在食指和拇指关键点上画圈,img画板,坐标(cx,cy),半径5,红色填充
cv2.circle(img, (x1,y1), 12, (255,0,0), cv2.FILLED)
cv2.circle(img, (x2,y2), 12, (255,0,0), cv2.FILLED)
# 在拇指和食指中间画一条线段,img画板,起点和终点坐标,颜色,线条宽度
cv2.line(img, (x1,y1), (x2,y2), (255,0,255), 3)
# 拇指和食指的中点,像素坐标是整数要用//
cx, cy = (x1+x2)//2, (y1+y2)//2
# 在中点画一个圈
cv2.circle(img, (cx,cy), 12, (255,0,0), cv2.FILLED)
# 返回处理后的图像,及关键点坐标
return img, lmList效果如下:

3. 控制电脑音量
首先我们获取音量控制模块volume,音量的调节范围在[-65.25, 0]之间,音量最大为0
# 导入音量控制模块
from ctypes import cast, POINTER
from comtypes import CLSCTX_ALL
from pycaw.pycaw import AudioUtilities, IAudioEndpointVolume
# 获取音响设备
devices = AudioUtilities.GetSpeakers()
interface = devices.Activate(
IAudioEndpointVolume._iid_, CLSCTX_ALL, None)
volume = cast(interface, POINTER(IAudioEndpointVolume))
# volume.GetMute() # 静音
# volume.GetMasterVolumeLevel() # 获取主音量级
volRange = volume.GetVolumeRange() # 音量范围(-65.25, 0.0)
# 设置最值音量
minVol = volRange[0] # 元素:-65.25
maxVol = volRange[1] # 元素:0接着我们修改第2节的代码内容,添加音量控制模块。通过拇指和食指之间连线的长度来调节音量。可通过勾股定理计算(x1,y1), (x2,y2)之间的长度。通过打印线段长度,发现线段最长为300,最短为50。而音量的范围是[-65,0],因此,我们将线段长度映射到音量长度使用映射函数np.interp(),[50,300]==>[-65,0],该函数的用法:numpy.interp()用法_hfutdog的博客-CSDN博客_np.interp
设置音量控制器 volume.SetMasterVolumeLevel(vol, None) ,其中vol为映射后的线段长度。
#(1)创建检测手部关键点的方法
mpHands = mp.solutions.hands #接收方法
hands = mpHands.Hands(static_image_mode=False, #静态追踪,低于0.5置信度会再一次跟踪
max_num_hands=2, # 最多有2只手
min_detection_confidence=0.6, # 最小检测置信度
min_tracking_confidence=0.5) # 最小跟踪置信度
# 创建检测手部关键点和关键点之间连线的方法
mpDraw = mp.solutions.drawing_utils
# 存放坐标信息
lmList = []
#(2)对传入的每一帧图像处理,给出音量范围
def handDetector(img):
# 把图像传入检测模型,提取信息
results = hands.process(img)
# 检查每帧图像是否有多只手,一一提取它们
if results.multi_hand_landmarks: #如果没有手就是None
for handlms in results.multi_hand_landmarks:
# 绘制关键点及连线,mpHands.HAND_CONNECTIONS绘制手部关键点之间的连线
mpDraw.draw_landmarks(img, handlms, mpHands.HAND_CONNECTIONS)
# 获取每个关键点的索引和坐标
for index, lm in enumerate(handlms.landmark):
# 将xy的比例坐标转换成像素坐标
h, w, c = img.shape # 分别存放图像长\宽\通道数
# 中心坐标(小数),必须转换成整数(像素坐标)
cx ,cy = int(lm.x * w), int(lm.y * h) #比例坐标x乘以宽度得像素坐标
#(3)分别处理拇指"4"和食指"8"的像素坐标
if index == 4:
x1, y1 = cx, cy
if index == 8:
x2, y2 = cx, cy
# 打印坐标信息
# print("4", x1, y1, ", 8", x2, y2)
# 保存坐标点
lmList.append([[x1,y1],[x2,y2]])
# 在食指和拇指关键点上画圈,img画板,坐标(cx,cy),半径5,红色填充
cv2.circle(img, (x1,y1), 12, (255,0,0), cv2.FILLED)
cv2.circle(img, (x2,y2), 12, (255,0,0), cv2.FILLED)
# 在拇指和食指中间画一条线段,img画板,起点和终点坐标,颜色,线条宽度
cv2.line(img, (x1,y1), (x2,y2), (255,0,255), 3)
# 拇指和食指的中点,像素坐标是整数要用//
cx, cy = (x1+x2)//2, (y1+y2)//2
# 在中点画一个圈
cv2.circle(img, (cx,cy), 12, (255,0,0), cv2.FILLED)
#(4)基于长度控制音量
# 计算线段之间的长度,勾股定理计算平方和再开根
length = math.hypot(x2-x1, y2-y1)
# print(length)
# 线段长度最大300,最小50,转换到音量范围,最小-65,最大0
# 将线段长度变量length从[50,300]转变成[-65,0]
vol = np.interp(length, [50,300], [minVol, maxVol])
print('vol:',vol, 'length:', length)
# 设置电脑主音量
volume.SetMasterVolumeLevel(vol, None)
if length < 50: # 距离小于50改变中心圆颜色绿色
cv2.circle(img, (cx,cy), 12, (0,255,0), cv2.FILLED)
# 返回处理后的图像,及关键点坐标
return img, lmList
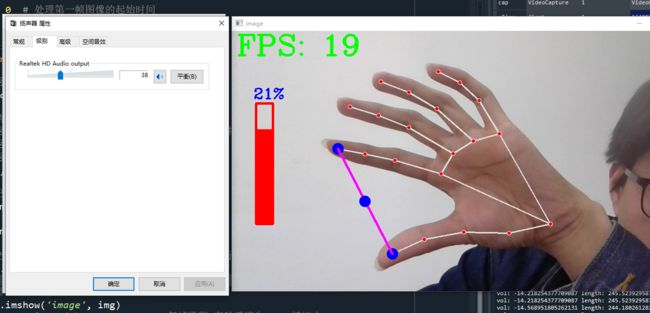
如下图所示,随着手部线段变化,音量也随着变化

4. 设置虚拟音量条
为了能更直观的展现出音量随着指尖距离的变化,设置虚拟的音量条,这样就不用总是打开音量控制面板看结果。因此我们在上面的代码中补充。
创建虚拟音量条的变量volBar,它的映射范围和vol不同,volBar的映射范围是虚拟音量框的高。从[50,300]映射到[400,150],确保填充可以在矩形框中变动。
# 导入音量控制模块
from ctypes import cast, POINTER
from comtypes import CLSCTX_ALL
from pycaw.pycaw import AudioUtilities, IAudioEndpointVolume
# 获取音量设备
devices = AudioUtilities.GetSpeakers()
interface = devices.Activate(
IAudioEndpointVolume._iid_, CLSCTX_ALL, None)
volume = cast(interface, POINTER(IAudioEndpointVolume))
# volume.GetMute() # 静音
# volume.GetMasterVolumeLevel() # 获取主音量级
volRange = volume.GetVolumeRange() # 音量范围(-65.25, 0.0)
# 设置最小音量
minVol = volRange[0] # 元素:-65.25
maxVol = volRange[1] # 元素:0
#(1)创建检测手部关键点的方法
mpHands = mp.solutions.hands #接收方法
hands = mpHands.Hands(static_image_mode=False, #静态追踪,低于0.5置信度会再一次跟踪
max_num_hands=2, # 最多有2只手
min_detection_confidence=0.6, # 最小检测置信度
min_tracking_confidence=0.5) # 最小跟踪置信度
# 创建检测手部关键点和关键点之间连线的方法
mpDraw = mp.solutions.drawing_utils
#(2)存放坐标信息
lmList = []
# 对传入的每一帧图像处理,给出音量范围
def handDetector(img):
# 把图像传入检测模型,提取信息
results = hands.process(img)
# 检查每帧图像是否有多只手,一一提取它们
if results.multi_hand_landmarks: #如果没有手就是None
for handlms in results.multi_hand_landmarks:
# 绘制关键点及连线,mpHands.HAND_CONNECTIONS绘制手部关键点之间的连线
mpDraw.draw_landmarks(img, handlms, mpHands.HAND_CONNECTIONS)
# 获取每个关键点的索引和坐标
for index, lm in enumerate(handlms.landmark):
# 将xy的比例坐标转换成像素坐标
h, w, c = img.shape # 分别存放图像长\宽\通道数
# 中心坐标(小数),必须转换成整数(像素坐标)
cx ,cy = int(lm.x * w), int(lm.y * h) #比例坐标x乘以宽度得像素坐标
#(3)分别处理拇指"4"和食指"8"的像素坐标
if index == 4:
x1, y1 = cx, cy
if index == 8:
x2, y2 = cx, cy
# 打印坐标信息
# print("4", x1, y1, ", 8", x2, y2)
# 保存坐标点
lmList.append([[x1,y1],[x2,y2]])
# 在食指和拇指关键点上画圈,img画板,坐标(cx,cy),半径5,红色填充
cv2.circle(img, (x1,y1), 12, (255,0,0), cv2.FILLED)
cv2.circle(img, (x2,y2), 12, (255,0,0), cv2.FILLED)
# 在拇指和食指中间画一条线段,img画板,起点和终点坐标,颜色,线条宽度
cv2.line(img, (x1,y1), (x2,y2), (255,0,255), 3)
# 拇指和食指的中点,像素坐标是整数要用//
cx, cy = (x1+x2)//2, (y1+y2)//2
# 在中点画一个圈
cv2.circle(img, (cx,cy), 12, (255,0,0), cv2.FILLED)
#(4)基于长度控制音量
# 计算线段之间的长度,勾股定理计算平方和再开根
length = math.hypot(x2-x1, y2-y1)
# print(length)
# 线段长度最大300,最小50,转换到音量范围,最小-65,最大0
# 将线段长度变量length从[50,300]转变成[-65,0]
vol = np.interp(length, [50,300], [minVol, maxVol])
print('vol:',vol, 'length:', length)
# 虚拟音量调的映射,如果和vol一样音量调填充不满
volBar = np.interp(length, [50,300], [400,150]) #映射到150-400
# print('volbar',volBar)
# 设置电脑主音量
volume.SetMasterVolumeLevel(vol, None)
if length < 50: # 距离小于50改变中心圆颜色绿色
cv2.circle(img, (cx,cy), 12, (0,255,0), cv2.FILLED)
#(5)画出矩形音量条,img画板,起点和终点坐标,颜色,线宽
cv2.rectangle(img, (50,150), (85,400), (0,0,255), 3)
# 用音量的幅度作为填充矩形条的高度,像素坐标是整数
cv2.rectangle(img, (50,int(volBar)), (85,400), (0,0,255), cv2.FILLED)
# 把音量值写上去,坐标(50-5,150-10)避免数字遮挡框
text_vol = 100 * (volBar-150)/(400-150) # 音量归一化再变成百分数
cv2.putText(img, f'{str(int(text_vol))}%', (50-5,150-10), cv2.FONT_HERSHEY_COMPLEX, 1, (255,0,0), 2)
# 返回处理后的图像,及关键点坐标
return img, lmList结果如下,24%代表的是矩形框中白色未填充部分。

拇指和食指的坐标点存放在 lmList 中,把它打印出来看一下
