python 爬取页面内的.ts文件并合并保存
一般网站的视频都是分段加载的,简单说就是把一个视频切成多个片段来加载,每个分段都会有不同的url地址。
这些url地址列表,会存放在一个.m3u8文件里。
首页打开待爬取的页面获取ts文件列表,按F12查看页面内容,ctlr+F 搜索 m3u8,找到这个地址。
(Ps:这个网站是个少儿不宜的网站,所以具体链接我就不贴出来了)

然后我们拿到这个地址,去读取里面内容。
import requests
url="https://xxx.sdhdbd1.com/52av/20210629/A%e5%9b%bd%e4%ba%a7%e8%87%aa%e6%8b%8d/%e8%ba%ab%e6%9d%90%e5%be%88%e6%98%af%e8%8b%97%e6%9d%a1%e9%98%b4%e6%af%9b%e5%a4%9a%e5%a4%9a%e6%8f%89%e5%a5%b6%e6%8e%b0%e7%a9%b4/SD/playlist.m3u8"
res=requests.get(url).text
print(res)打印结果:
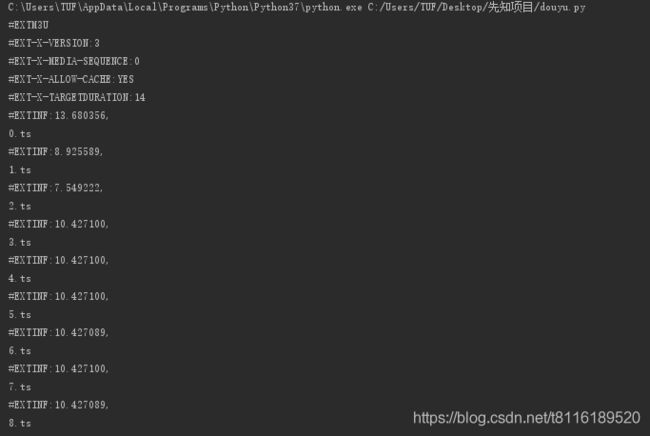
把ts列表中的内容用正则提取出来 ,放入列表,备用
ts=re.findall(r"(\d+).ts",res,flags=re.S)
print(ts)鼠标点击下播放页面的视频,我们来查看下视频播放时的请求:
没错,他就是在分段加载视频到浏览器!
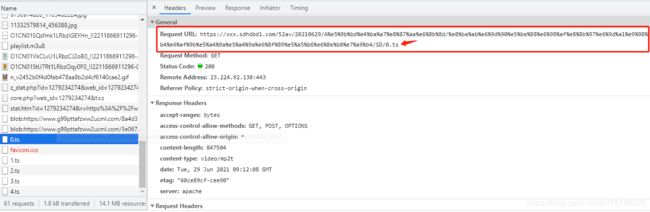
然后在当前目录建立个ts文件夹,挨个把这些ts文件下载下来,(多线程更好,但我懒得写)
url_prifix="https://xxx.sdhdbd1.com/52av/20210629/A%e5%9b%bd%e4%ba%a7%e8%87%aa%e6%8b%8d/%e8%ba%ab%e6%9d%90%e5%be%88%e6%98%af%e8%8b%97%e6%9d%a1%e9%98%b4%e6%af%9b%e5%a4%9a%e5%a4%9a%e6%8f%89%e5%a5%b6%e6%8e%b0%e7%a9%b4/SD/"
for i in ts:
u=url_prifix+i+".ts"
r=requests.get(url=u,headers=headers).content
print(i,u)
with open('./ts/'+i+'.ts',mode="wb") as file:
file.write(r)最后再合并这些ts文件,得出完整视频:
os.system("copy /b /ts/*.ts heel.ts")
搞定收工!(以上内容仅供学习交流,请勿做违法的事哦)
~
~
~
完整代码:
import requests
import re
import os
url_prifix="https://xxx.sdhdbd1.com/52av/20210629/A%e5%9b%bd%e4%ba%a7%e8%87%aa%e6%8b%8d/%e8%ba%ab%e6%9d%90%e5%be%88%e6%98%af%e8%8b%97%e6%9d%a1%e9%98%b4%e6%af%9b%e5%a4%9a%e5%a4%9a%e6%8f%89%e5%a5%b6%e6%8e%b0%e7%a9%b4/SD/"
url="https://xxx.sdhdbd1.com/52av/20210629/A%e5%9b%bd%e4%ba%a7%e8%87%aa%e6%8b%8d/%e8%ba%ab%e6%9d%90%e5%be%88%e6%98%af%e8%8b%97%e6%9d%a1%e9%98%b4%e6%af%9b%e5%a4%9a%e5%a4%9a%e6%8f%89%e5%a5%b6%e6%8e%b0%e7%a9%b4/SD/playlist.m3u8"
# 获取m3u8文件
res=requests.get(url).text
print(res)
# 正则提取内容
ts=re.findall(r"(\d+).ts",res,flags=re.S)
print(ts)
# 从网页上复制下来的请求头
headers = {
'authority': 'xxx.sdhdbd1.com',
'sec-ch-ua': '" Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"',
'sec-ch-ua-mobile': '?0',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'sec-fetch-site': 'none',
'sec-fetch-mode': 'navigate',
'sec-fetch-user': '?1',
'sec-fetch-dest': 'document',
'accept-language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7,zh-TW;q=0.6'
}
for i in ts:
# 拼接完整的ts文件下载链接
u=url_prifix+i+".ts"
r=requests.get(url=u,headers=headers).content
print(i,u)
# 二进制写入到本地
with open('./ts/'+i+'.ts',mode="wb") as file:
file.write(r)
#利用cmd命令将.ts文件合成为mp4格式
os.system("copy /b /ts/*.ts heel.mp4")
print("转换成功")