《Deep Learning for Image Super-resolution: A Survey》之 Loss Functions
本文节选自论文:Deep Learning for Image Super-resolution: A Survey
在图像超分中,用损失函数来衡量重建图像与真实图像之间的差异,并以此来引导模型的优化。
关于超分中常用的损失函数(Loss Functions)的总结:
1、Pixel Loss(基于像素级的损失)
包含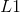 loss(平均绝对值误差)、
loss(平均绝对值误差)、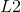 loss(均方误差)
loss(均方误差)
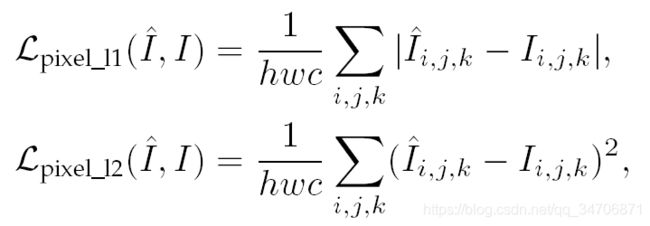
其中,![]() 为重建图像,
为重建图像, 为真实图像,
为真实图像,  、
、 、
、 分别为图像的高、宽和通道数。
分别为图像的高、宽和通道数。
loss还有一个变种,称为 Charbonnier loss,其表达式如下:
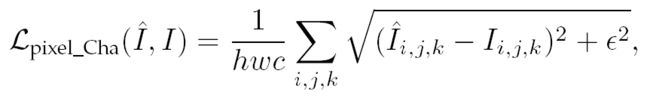
其中, 是为了数值稳定而设的一个很小的常量。
是为了数值稳定而设的一个很小的常量。
在实际应用中, loss 比 loss 有着更好的效果和收敛性。因为图像重建的评价指标之一——峰值信噪比(PSNR)与像素级的差异有关,所以最小化 Pixel loss 能够直接最大化 PSNR ,因此 Pixel loss也就成为了一个广泛使用的损失函数。
缺点:Pixel loss 没有考虑到图像的感知质量(perceptual quality)和 结构信息(textures),缺少高频信息,容易造成重建图像过度光滑。
2、Content Loss(基于内容的损失)
为了提高图像的感知质量(perceptual quality),Content loss 采用一个已经训练好的图像分类网络去衡量重建图像与真实图像之间的语义差异(semantic differences)。假设采用的、已经训练好的分类网络为 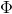 ,
,![]() 表示图像 在 的第
表示图像 在 的第  层上的高阶表示(high-level representations)(其实,就是把 输入到 中,然后在第 层上的输出特征图(这个称为语义信息)),则 content loss 可以表示如下:
层上的高阶表示(high-level representations)(其实,就是把 输入到 中,然后在第 层上的输出特征图(这个称为语义信息)),则 content loss 可以表示如下:
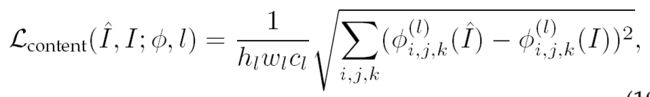
也就是衡量 ![]() 与 在 网络 中第 层上的特征图的差异(语义差异)。
与 在 网络 中第 层上的特征图的差异(语义差异)。
content loss 产生的图像有更好的感知效果(人眼看的效果),常用的网络 有 VGG 和 ResNet。
3、Texture Loss(基于结构/纹理 的损失)
重建图像应该与真实图像具有相同的样式(如 颜色、纹理 、 对比度等)
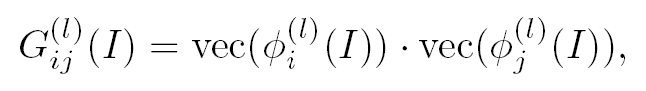

与上面 Content Loss 有点类似,Texture loss也是针对特征图的计算。图像纹理被认为是不同特征通道之间的相关性,用Gram matrix ![]() 来表示在 网络上第 层的特征图的第
来表示在 网络上第 层的特征图的第  个通道与第
个通道与第  个通道之间的这种相关性。
个通道之间的这种相关性。
优点:能产生更加真实的纹理结构和符合视觉的效果。
缺点:确定去匹配纹理结构的图像块的大小仍以经验为主。
4、Adversarial Loss(对抗损失)
我们将 SR 模型看成是一个生成器,再加一个判别器去分辨重建图像和真实图像。
SRGAN采用的损失函数如下:
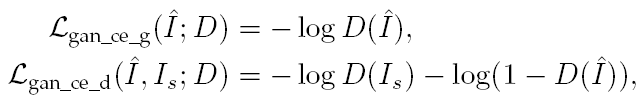
第一个为生成器(SR model)的对抗损失,第二个为判别器的损失。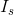 是从真实图像中随机采样的点。
是从真实图像中随机采样的点。
后面又有如下的损失函数:
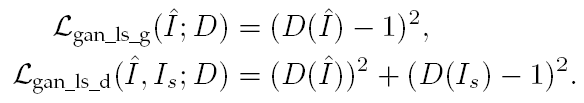
相比于SRGAN,它能使训练更稳定并且产生更好的效果。
与上面的工作不同的是,Park et al. 认为基于像素层面的判别器只会让生成器生成一些无意义的高频噪声,使用特征层面的判别器将会使重建图像更加真实(之前传给判别器的是图像,这里是让图像先通过一个预训练的网络,再将网络的某层的特征图(high-level representations)传给判别器)。
5、Cycle Consistency Loss(循环一致性损失)
这是受到CycleGAN的启发,对于一幅 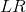 图像 ,先重建出它的
图像 ,先重建出它的 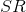 图像
图像 ![]() ,再将
,再将 ![]() 通过一个CNN网络下采样成 图像
通过一个CNN网络下采样成 图像 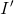 ,比较 与 之间的差异,计算公式如下:
,比较 与 之间的差异,计算公式如下:
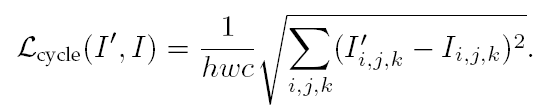
6、Total Variation Loss(基于全变分的损失)
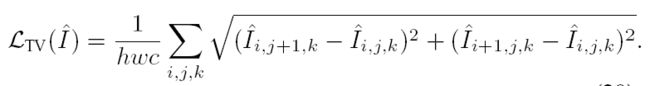
它定义为重建图像相邻像素之间的差异,以此来衡量图像中含有多少噪声 。
7、Prior-Based Loss(基于先验的损失)
总结:实际应用上,研究者们会使用多种 Loss 的加权平均,但不同 Loss 之间的权重系数仍以经验为主