附代码:RepVGG: Making VGG-style ConvNets Great Again论文解读
RepVGG: Making VGG-style ConvNets Great Again论文解读
代码链接:https://github.com/DingXiaoH/RepVGG
重点:提出通过结构重新参数化来解耦训练时间的多分支和推理时间的纯体系结构
摘要:
我们提出了一个简单而强大的卷积神经网络结构,它具有一个类似VGG的推理时间体,只由3×3卷积和ReLU的堆栈组成,而训练时间模型具有多分支拓扑。这种训练时间和推理时间体系结构的解耦是通过结构重新参数化技术来实现的,从而使模型被命名为RepVGG。
训练过程采用多分支结构,推理过程采用单一3x3卷积结构。
虽然许多复杂的网络比简单的提供更高的精度,但缺点是显著的。
-
复杂的多分支设计(如ResNet中的残余加法和Inception中的分支连接)使
得模型难以实现和定制,降低了推理速度,降低了内存利用率。 -
一些组件(例如,在Xception和MobileNets中的深度转换和ShuffleNets中的通道混洗)增加了内存访问成本,并且缺乏对各种设备的支持。
-
除了实现的不便之外,复杂的模型可能会降低并行性[24]的程度,从而减缓推理。
优点
- 该模型的推理过程类似于VGG没有任何分支,这意味着每一层都将其唯一的前一层的输出作为输入,并将输出输入到其唯一的下一层。
- 该模型的推理过程只使用了3×3的conv和ReLU。
- 具体的架构(包括特定的深度和层宽)被实例化,没有自动搜索,手动细化,复合缩放,也没有其他重型设计。
Block:
由于多分支体系结构的优点都用于训练,而缺点不适用于推理,我们建议通过结构重新参数化来解耦训练时间(train)多分支和推理时间(eval)纯体系结构,这意味着通过转换参数将体系结构从一个转换到另一边。
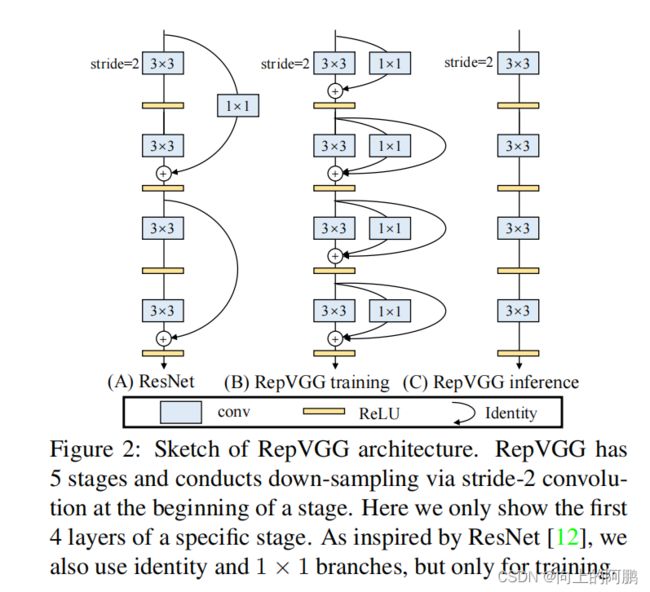
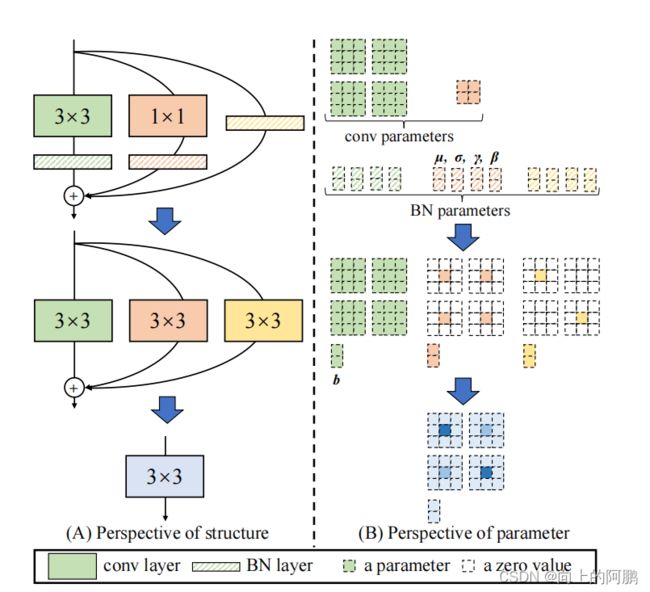
具体来说,我们使用identity和1×1分支构造训练时间RepVGG,训练后,我们用简单的代数执行转换,作为一个identity分支可以视为退化1×1conv,后者可以进一步视为退化3×3conv,这样我们可以构建一个3×3内核的训练参数原始3×3内核,identity和1×1分支和批规范化(BN)的卷积层。因此,转换后的模型是一个3×3conv层的堆栈,保存用于测试和部署,即推理。Block如下图,中间为训练时间block,右边为推理时间block。
训练过程公式:

M中上标为1的是输入,2是输出,其他上标为3对应3x3卷积的分支,上标为1为1x1卷积,0为identity。
推理过程的重参数化:

具体如下图所示:左边为训练过程,右边为推理过程
模型结构
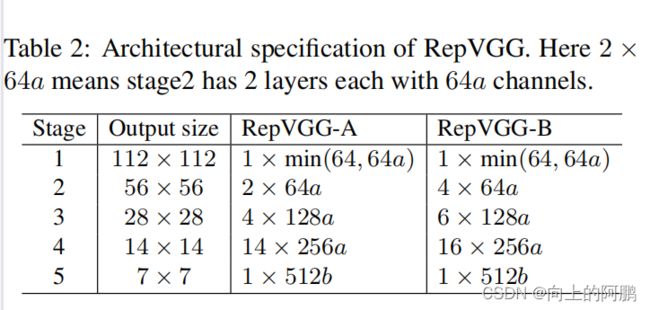
根据三个简单的指导方针来决定每个阶段的层数。1)第一阶段的分辨率很大,这很耗时,所以我们只使用一层作为较低的延迟。2)最后一个阶段应该有更多的通道,所以我们只使用一层来保存参数。3)将最多的层加入到第二个最后阶段。
深度:
我们让这五个阶段分别有1、2、4、14、1层来构建一个名为RepVGG-A的实例。我们还构建了一个更深的RepVGG-B,在第2、3和4阶段比A多两层。
宽度:
通过均匀缩放[64,128,256,512]的经典宽度设置来确定层宽。使用乘数a来缩放前四个阶段,b扩展到最后一个阶段。由于RepVGG在最后一阶段只有一层,因此较大的b并不会显著增加延迟和参数的数量,通常设置b>a,因为我们希望最后一层对分类或其他下游任务有更丰富的特征,即阶段2、3、4、5的宽度分别为[64a、128a、256a、512b]
代码:
import torch.nn as nn
import numpy as np
import torch
import copy
from se_block import SEBlock
def conv_bn(in_channels, out_channels, kernel_size, stride, padding, groups=1):
result = nn.Sequential()
result.add_module('conv', nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=kernel_size, stride=stride, padding=padding, groups=groups, bias=False))
result.add_module('bn', nn.BatchNorm2d(num_features=out_channels))
return result
class RepVGGBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size,
stride=1, padding=0, dilation=1, groups=1, padding_mode='zeros', deploy=False, use_se=False):
super(RepVGGBlock, self).__init__()
self.deploy = deploy
self.groups = groups
self.in_channels = in_channels
assert kernel_size == 3
assert padding == 1
padding_11 = padding - kernel_size // 2
self.nonlinearity = nn.ReLU()
if use_se:
self.se = SEBlock(out_channels, internal_neurons=out_channels // 16)
else:
self.se = nn.Identity()
if deploy:
self.rbr_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride,
padding=padding, dilation=dilation, groups=groups, bias=True, padding_mode=padding_mode)
else:
self.rbr_identity = nn.BatchNorm2d(num_features=in_channels) if out_channels == in_channels and stride == 1 else None
self.rbr_dense = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding, groups=groups)
self.rbr_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride, padding=padding_11, groups=groups)
print('RepVGG Block, identity = ', self.rbr_identity)
def forward(self, inputs):
if hasattr(self, 'rbr_reparam'):
return self.nonlinearity(self.se(self.rbr_reparam(inputs)))
if self.rbr_identity is None:
id_out = 0
else:
id_out = self.rbr_identity(inputs)
return self.nonlinearity(self.se(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out))
# Optional. This improves the accuracy and facilitates quantization.
# 1. Cancel the original weight decay on rbr_dense.conv.weight and rbr_1x1.conv.weight.
# 2. Use like this.
# loss = criterion(....)
# for every RepVGGBlock blk:
# loss += weight_decay_coefficient * 0.5 * blk.get_cust_L2()
# optimizer.zero_grad()
# loss.backward()
def get_custom_L2(self):
K3 = self.rbr_dense.conv.weight
K1 = self.rbr_1x1.conv.weight
t3 = (self.rbr_dense.bn.weight / ((self.rbr_dense.bn.running_var + self.rbr_dense.bn.eps).sqrt())).reshape(-1, 1, 1, 1).detach()
t1 = (self.rbr_1x1.bn.weight / ((self.rbr_1x1.bn.running_var + self.rbr_1x1.bn.eps).sqrt())).reshape(-1, 1, 1, 1).detach()
l2_loss_circle = (K3 ** 2).sum() - (K3[:, :, 1:2, 1:2] ** 2).sum() # The L2 loss of the "circle" of weights in 3x3 kernel. Use regular L2 on them.
eq_kernel = K3[:, :, 1:2, 1:2] * t3 + K1 * t1 # The equivalent resultant central point of 3x3 kernel.
l2_loss_eq_kernel = (eq_kernel ** 2 / (t3 ** 2 + t1 ** 2)).sum() # Normalize for an L2 coefficient comparable to regular L2.
return l2_loss_eq_kernel + l2_loss_circle
# This func derives the equivalent kernel and bias in a DIFFERENTIABLE way.
# You can get the equivalent kernel and bias at any time and do whatever you want,
# for example, apply some penalties or constraints during training, just like you do to the other models.
# May be useful for quantization or pruning.
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
#1x1 -> 3x3
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return torch.nn.functional.pad(kernel1x1, [1,1,1,1])
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
if isinstance(branch, nn.Sequential):
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
else:
assert isinstance(branch, nn.BatchNorm2d)
if not hasattr(self, 'id_tensor'):
input_dim = self.in_channels // self.groups
kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)
for i in range(self.in_channels):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def switch_to_deploy(self):
if hasattr(self, 'rbr_reparam'):
return
kernel, bias = self.get_equivalent_kernel_bias()
self.rbr_reparam = nn.Conv2d(in_channels=self.rbr_dense.conv.in_channels, out_channels=self.rbr_dense.conv.out_channels,
kernel_size=self.rbr_dense.conv.kernel_size, stride=self.rbr_dense.conv.stride,
padding=self.rbr_dense.conv.padding, dilation=self.rbr_dense.conv.dilation, groups=self.rbr_dense.conv.groups, bias=True)
self.rbr_reparam.weight.data = kernel
self.rbr_reparam.bias.data = bias
for para in self.parameters():
para.detach_()
self.__delattr__('rbr_dense')
self.__delattr__('rbr_1x1')
if hasattr(self, 'rbr_identity'):
self.__delattr__('rbr_identity')
if hasattr(self, 'id_tensor'):
self.__delattr__('id_tensor')
self.deploy = True
class RepVGG(nn.Module):
def __init__(self, num_blocks, num_classes=1000, width_multiplier=None, override_groups_map=None, deploy=False, use_se=False):
super(RepVGG, self).__init__()
assert len(width_multiplier) == 4
self.deploy = deploy
self.override_groups_map = override_groups_map or dict()
self.use_se = use_se
assert 0 not in self.override_groups_map
self.in_planes = min(64, int(64 * width_multiplier[0]))
self.stage0 = RepVGGBlock(in_channels=3, out_channels=self.in_planes, kernel_size=3, stride=2, padding=1, deploy=self.deploy, use_se=self.use_se)
self.cur_layer_idx = 1
self.stage1 = self._make_stage(int(64 * width_multiplier[0]), num_blocks[0], stride=2)
self.stage2 = self._make_stage(int(128 * width_multiplier[1]), num_blocks[1], stride=2)
self.stage3 = self._make_stage(int(256 * width_multiplier[2]), num_blocks[2], stride=2)
self.stage4 = self._make_stage(int(512 * width_multiplier[3]), num_blocks[3], stride=2)
self.gap = nn.AdaptiveAvgPool2d(output_size=1)
self.linear = nn.Linear(int(512 * width_multiplier[3]), num_classes)
def _make_stage(self, planes, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
blocks = []
for stride in strides:
cur_groups = self.override_groups_map.get(self.cur_layer_idx, 1)
blocks.append(RepVGGBlock(in_channels=self.in_planes, out_channels=planes, kernel_size=3,
stride=stride, padding=1, groups=cur_groups, deploy=self.deploy, use_se=self.use_se))
self.in_planes = planes
self.cur_layer_idx += 1
return nn.Sequential(*blocks)
def forward(self, x):
out = self.stage0(x)
out = self.stage1(out)
out = self.stage2(out)
out = self.stage3(out)
out = self.stage4(out)
out = self.gap(out)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
optional_groupwise_layers = [2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26]
g2_map = {l: 2 for l in optional_groupwise_layers}
g4_map = {l: 4 for l in optional_groupwise_layers}
def create_RepVGG_A0(deploy=False):
return RepVGG(num_blocks=[2, 4, 14, 1], num_classes=1000,
width_multiplier=[0.75, 0.75, 0.75, 2.5], override_groups_map=None, deploy=deploy)
def create_RepVGG_A1(deploy=False):
return RepVGG(num_blocks=[2, 4, 14, 1], num_classes=1000,
width_multiplier=[1, 1, 1, 2.5], override_groups_map=None, deploy=deploy)
def create_RepVGG_A2(deploy=False):
return RepVGG(num_blocks=[2, 4, 14, 1], num_classes=1000,
width_multiplier=[1.5, 1.5, 1.5, 2.75], override_groups_map=None, deploy=deploy)
def create_RepVGG_B0(deploy=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[1, 1, 1, 2.5], override_groups_map=None, deploy=deploy)
def create_RepVGG_B1(deploy=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[2, 2, 2, 4], override_groups_map=None, deploy=deploy)
def create_RepVGG_B1g2(deploy=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[2, 2, 2, 4], override_groups_map=g2_map, deploy=deploy)
def create_RepVGG_B1g4(deploy=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[2, 2, 2, 4], override_groups_map=g4_map, deploy=deploy)
def create_RepVGG_B2(deploy=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[2.5, 2.5, 2.5, 5], override_groups_map=None, deploy=deploy)
def create_RepVGG_B2g2(deploy=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[2.5, 2.5, 2.5, 5], override_groups_map=g2_map, deploy=deploy)
def create_RepVGG_B2g4(deploy=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[2.5, 2.5, 2.5, 5], override_groups_map=g4_map, deploy=deploy)
def create_RepVGG_B3(deploy=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[3, 3, 3, 5], override_groups_map=None, deploy=deploy)
def create_RepVGG_B3g2(deploy=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[3, 3, 3, 5], override_groups_map=g2_map, deploy=deploy)
def create_RepVGG_B3g4(deploy=False):
return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[3, 3, 3, 5], override_groups_map=g4_map, deploy=deploy)
def create_RepVGG_D2se(deploy=False):
return RepVGG(num_blocks=[8, 14, 24, 1], num_classes=1000,
width_multiplier=[2.5, 2.5, 2.5, 5], override_groups_map=None, deploy=deploy, use_se=True)
func_dict = {
'RepVGG-A0': create_RepVGG_A0,
'RepVGG-A1': create_RepVGG_A1,
'RepVGG-A2': create_RepVGG_A2,
'RepVGG-B0': create_RepVGG_B0,
'RepVGG-B1': create_RepVGG_B1,
'RepVGG-B1g2': create_RepVGG_B1g2,
'RepVGG-B1g4': create_RepVGG_B1g4,
'RepVGG-B2': create_RepVGG_B2,
'RepVGG-B2g2': create_RepVGG_B2g2,
'RepVGG-B2g4': create_RepVGG_B2g4,
'RepVGG-B3': create_RepVGG_B3,
'RepVGG-B3g2': create_RepVGG_B3g2,
'RepVGG-B3g4': create_RepVGG_B3g4,
'RepVGG-D2se': create_RepVGG_D2se, # Updated at April 25, 2021. This is not reported in the CVPR paper.
}
def get_RepVGG_func_by_name(name):
return func_dict[name]
# Use this for converting a RepVGG model or a bigger model with RepVGG as its component
# Use like this
# model = create_RepVGG_A0(deploy=False)
# train model or load weights
# repvgg_model_convert(model, save_path='repvgg_deploy.pth')
# If you want to preserve the original model, call with do_copy=True
# ====================== for using RepVGG as the backbone of a bigger model, e.g., PSPNet, the pseudo code will be like
# train_backbone = create_RepVGG_B2(deploy=False)
# train_backbone.load_state_dict(torch.load('RepVGG-B2-train.pth'))
# train_pspnet = build_pspnet(backbone=train_backbone)
# segmentation_train(train_pspnet)
# deploy_pspnet = repvgg_model_convert(train_pspnet)
# segmentation_test(deploy_pspnet)
# ===================== example_pspnet.py shows an example
def repvgg_model_convert(model:torch.nn.Module, save_path=None, do_copy=True):
if do_copy:
model = copy.deepcopy(model)
for module in model.modules():
if hasattr(module, 'switch_to_deploy'):
module.switch_to_deploy()
if save_path is not None:
torch.save(model.state_dict(), save_path)
return model
if __name__ == '__main__':
train_model = create_RepVGG_A0(deploy=False)
train_model.eval() # Don't forget to call this before inference.
deploy_model = repvgg_model_convert(train_model)
x = torch.randn(1, 3, 224, 224)
train_y = train_model(x)
deploy_y = deploy_model(x)
print(((train_y - deploy_y) ** 2).sum())