MindSpore Serving模型部署,如何提升吞吐量,降低推理时延
1. 关于MindSpore Serving
MindSpore Serving是一个轻量级、高性能的服务模块,旨在帮助MindSpore开发者在生产环境中高效部署在线推理服务。当用户使用MindSpore完成模型训练后,导出MindSpore模型,即可使用MindSpore Serving创建该模型的推理服务。MindSpore Serving详情可参考 serving: A lightweight and high-performance service module that helps MindSpore developers efficiently deploy online inference services in the production environment.。
2. 最简单直接的将模型部署在Serving服务器
以ResNet-50模型部署为案例,运行本Serving样例所需文件和目录结构如下,其中serving_client.py和test_image为客户端运行所需。
├── resnet50
│ ├── 1
│ │ └── resnet50_1b_cifar10.mindir
│ └── servable_config.py
│── serving_server.py
├── serving_client.py
└── test_image
├── airplane.jpg 48KB
├── car.jpg 79KB
├── cat.jpg 330KB
└── horse.jpg 83KB其中
- resnet50_1b_cifar10.mindir为MindSpore训练后导出的模型,导出脚本可参考导出resnet50模型。
- 目录1下表示为版本1的模型。
- servable_config.py为模型配置脚本,声明模型文件,定义模型的输入输出处理流程。
- serving_server.py为服务启动脚本,指定模型部署的设备,启动gRPC或RESTful服务器。
- serving_client.py为客户单脚本,读取图片,向客户端发送请求,获取推理服务结果并打印。
- test_image中有大小不同的各类图片,图片较大时预处理时间较长。
先以最简单的方式配置和部署resnet50模型。
servable_config.py定义,通过declare_model声明了模型文件,定义了predict方法,输入为image,传给模型,输出为label,返回自模型结果。
from mindspore_serving.server import register
resnet_model = register.declare_model(model_file="resnet50_1b_cifar10.mindir", model_format="MindIR")
@register.register_method(output_names=["label"])
def predict(image):
x = register.add_stage(resnet_model, image, outputs_count=1)
return xserving_server.py定义,部署本地目录下的resent50到设备0,并启动地址为127.0.0.1:5500的gRPC服务器:
import os
import sys
from mindspore_serving import server
def start():
servable_dir = os.path.dirname(os.path.realpath(sys.argv[0]))
config = server.ServableStartConfig(servable_directory=servable_dir, servable_name="resnet50", device_ids=0)
server.start_servables(config)
server.start_grpc_server("127.0.0.1:5500")
if __name__ == "__main__":
start()serving_client.py定义,客户端读取两张图片,使用MindData进行预处理,将预处理结果发送给Serving服务器,对服务器返回的结果进行后处理,打印图片的便签:
import os
from mindspore_serving.client import Client
import numpy as np
import mindspore.dataset.vision.c_transforms as VC
# cifar 10
idx_2_label = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
def preprocess(image):
image_size = 224
mean = [0.4914 * 255, 0.4822 * 255, 0.4465 * 255]
std = [0.2023 * 255, 0.1994 * 255, 0.2010 * 255]
decode = VC.Decode()
resize = VC.Resize([image_size, image_size])
normalize = VC.Normalize(mean=mean, std=std)
hwc2chw = VC.HWC2CHW()
image = decode(image)
image = resize(image)
image = normalize(image)
image = hwc2chw(image)
return image
def postprocess(score):
max_idx = np.argmax(score)
return idx_2_label[max_idx]
def read_images():
"""Read images for directory test_image"""
image_files = []
images_buffer = []
for path, _, file_list in os.walk("./test_image/"):
for file_name in file_list:
image_file = os.path.join(path, file_name)
image_files.append(image_file)
for image_file in image_files:
with open(image_file, "rb") as fp:
images_buffer.append(fp.read())
return image_files, images_buffer
def predict(image_files, images_buffer):
client = Client("localhost:5500", "resnet50", "predict")
instances = []
for image in images_buffer:
image = preprocess(image)
instances.append({"image": image})
result = client.infer(instances)
for file, instance in zip(image_files, result):
score = instance["score"]
label = postprocess(score)
print(f"{file}, label: {label}")
if __name__ == '__main__':
image_files, images_buffer = read_images()
predict(image_files, images_buffer)执行serving_client.py
./test_image/car.jpg, label: automobile
./test_image/horse.jpg, label: horse
./test_image/cat.jpg, label: cat
./test_image/airplane.jpg, label: airplane我们重复进行上述过程的图片预处理、推理和后处理10次,每次100张图片(images_buffer *25共100张),平均每次耗时1788ms,平均每张图片17.88ms。
3. 预处理、后处理后置Serving服务器
我们可以将预处理、后处理后置到Serving服务器,以减少客户端和服务器通信数据量,其次使能Serving服务器推理与预处理、后处理并发处理能力。
我们将客户端serving_client.py中的预处理、后处理挪到服务器Servable_config.py中。
服务器Servable_config.py:
from mindspore_serving.server import register
import numpy as np
import mindspore.dataset.vision.c_transforms as VC
resnet_model = register.declare_model(model_file="resnet50_1b_cifar10.mindir", model_format="MindIR")
# cifar 10
idx_2_label = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
def preprocess(image):
image_size = 224
mean = [0.4914 * 255, 0.4822 * 255, 0.4465 * 255]
std = [0.2023 * 255, 0.1994 * 255, 0.2010 * 255]
decode = VC.Decode()
resize = VC.Resize([image_size, image_size])
normalize = VC.Normalize(mean=mean, std=std)
hwc2chw = VC.HWC2CHW()
image = decode(image)
image = resize(image)
image = normalize(image)
image = hwc2chw(image)
return image
def postprocess(score):
max_idx = np.argmax(score)
return idx_2_label[max_idx]
@register.register_method(output_names=["label"])
def predict(image):
image = register.add_stage(preprocess, image, outputs_count=1)
score = register.add_stage(resnet_model, image, outputs_count=1)
label = register.add_stage(postprocess, score, outputs_count=1)
return label客户端serving_client.py
import os
import time
from mindspore_serving.client import Client
def read_images():
"""Read images for directory test_image"""
image_files = []
images_buffer = []
for path, _, file_list in os.walk("./test_image/"):
for file_name in file_list:
image_file = os.path.join(path, file_name)
image_files.append(image_file)
for image_file in image_files:
with open(image_file, "rb") as fp:
images_buffer.append(fp.read())
return image_files, images_buffer
def predict(image_files, images_buffer):
client = Client("localhost:5500", "resnet50", "predict")
instances = []
for image in images_buffer:
instances.append({"image": image})
result = client.infer(instances)
for file, instance in zip(image_files, result):
label = instance["label"]
print(f"{file}, label: {label}")
if __name__ == '__main__':
image_files, images_buffer = read_images()
predict(image_files, images_buffer)我们重复进行上述过程的图片预处理、推理和后处理10次,每次100张图片(images_buffer *25共100张),平均每次耗时1343ms,平均每张图片13.43ms。
可以看到将预处理、后处理挪至服务器侧,降低客户端和服务器通信,利用Serving服务器预处理、后处理与模型推理的并发能力,可以显著提升推理吞吐量,降低每张图片的平均处理时延。
4. 多卡并发部署
如果设备存在多卡,我们可利用多卡并发能力,提升吞吐量。
我们更新serving_server.py中的部署脚本,修改代码部署到卡0和卡1(device_ids=(0,1))。
import os
import sys
from mindspore_serving import server
def start():
servable_dir = os.path.dirname(os.path.realpath(sys.argv[0]))
config = server.ServableStartConfig(servable_directory=servable_dir, servable_name="resnet50", device_ids=(0,1))
server.start_servables(config)
server.start_grpc_server("127.0.0.1:5500")
if __name__ == "__main__":
start()我们重复进行上述过程的图片预处理、推理和后处理10次,每次100张图片(images_buffer *25共100张),平均每次耗时692.7ms,平均每张图片6.93ms。
可以看到增加设备数量,可以显著提升推理吞吐量,降低每张图片的平均处理时延。
5. 额外进程提升Python预处理、后处理性能
由于Python GIL的存在,Python实现的预处理和后处理在一个进程内无法通过多线程实现并发,如果Python任务的处理时间大于模型推理时间,有必要增加Python进程并发处理Python任务。
1)获取Python任务和模型推理执行时间
启动serving_server.py前,打开GLOG_v设置INFO级别日志(export GLOG_v=1)。
启动服务器,运行客户端,接着查看worker日志serving_logs/我们可以观察到,
测试的四张图片每张图片差异不同,预处理大约耗时4~22ms,平均每张大约12ms。
method predict stage 1 function resnet50.preprocess get result 0 ~ 0 cost time 11.744976043701172 ms
method predict stage 1 function resnet50.preprocess get result 0 ~ 0 cost time 7.365942001342773 ms
method predict stage 1 function resnet50.preprocess get result 0 ~ 0 cost time 22.826194763183594 ms
method predict stage 1 function resnet50.preprocess get result 0 ~ 0 cost time 3.9374828338623047 ms推理大约耗时2.15ms每张图片。
Model resnet50_1b_cifar10.mindir InvokePredict Time Cost # 2.15127 ms后处理大约耗时0.32ms每张图片。
method predict stage 3 function resnet50.postprocess get result 0 ~ 0 cost time 0.32401084899902344 msPython任务预处理+后处理时间已经明显大约推理时间6倍。
2)增加额外的处理Python任务的进程
我们仅将模型部署到设备0,1: device_ids=(0,1),增加4个额外的worker进程处理Python任务,共6个并行的worker: num_parallel_workers=6。
在serving_server.py中:
import os
import sys
from mindspore_serving import server
def start():
servable_dir = os.path.dirname(os.path.realpath(sys.argv[0]))
config = server.ServableStartConfig(servable_directory=servable_dir, servable_name="resnet50", device_ids=(0,1), num_parallel_workers=6)
server.start_servables(config)
server.start_grpc_server("127.0.0.1:5500")
if __name__ == "__main__":
start()将日志级别恢复默认警告级别,unset GLOG_v,启动serving服务器。
我们重复进行上述过程的图片预处理、推理和后处理10次,每次100张图片(images_buffer *25共100张),平均每次耗时349ms,平均每张图片3.49ms。
当Python任务处理时间大于模型推理时间,可以看到增加额外的Python任务处理进程,可以显著提升推理吞吐量,降低每张图片的平均处理时延。
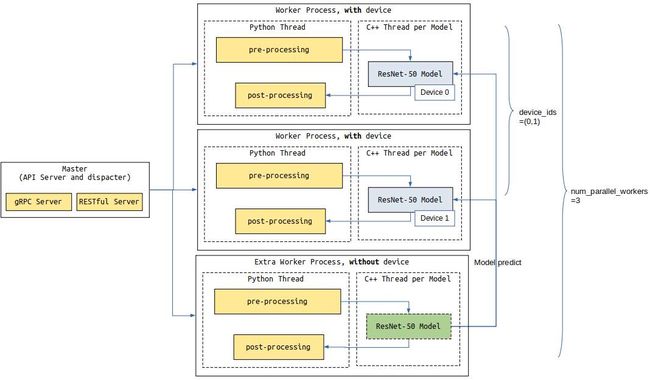
3) 相关运行结构图
存在额外Python任务进程,Serving运行结构图如下所示,图中,配置了2个Worker分别占用设备0和1(device_ids),可以处理模型推理和Python任务,配置了1个额外Worker,仅处理Python任务,共3(num_parallel_workers)个Worker:
6. 增加模型的batch_size
Serving当前不支持动态batch_size,动态batch_size开发中,模型的batch_size需用用户模型导出时指定。如果当增加模型batch size,平均每个batch的处理时间变小,则可权衡吞吐量和时延,适当增加模型的batch size。
由于本例子中,Python预处理时间为主要时间,模型推理时间较短,每张图片总体推理时间受batch_size影响不大。