深度学习-错误集锦
1. target = target.cuda(async=True) AttributeError: 'list' object has no attribute 'cuda'
查看自己的target类型,原为['1','0','1','1']。这种列表试字符串型。而应该修改为torch.tensor类型。才能用于网络计算
简单改为:先改为numpy再转换为tensor,搞定!
label = torch.from_numpy(np.fromstring(label, dtype=int, sep=','))2. RuntimeError: multi-target not supported at /opt/conda/conda-bld/pytorch_1549628766161/work/aten/src/THCUNN/generic/ClassNLLCriterion.cu:15
使用的CrossEntropyLoss()作为损失函数,因此prediction and label的尺寸正确的应分别为【batch,calss】=我的【4,2】// 【batch】=我的【4】,然而实际我的分别是我的【4,2】// 【4,1】。所以要修改label的尺寸
loss = self.criterion(output, target_var.squeeze())一般出现这个错误都是尺寸不对。
3. tn, fp, fn, tp = confusion_matrix(target, pred).ravel() ValueError: not enough values to unpack (expected 4, got 1)
这个问题很难找,当tn, fp, fn, tp其中某项等于总数是,比如我的batch=4,当tn=4时,就会出现错误。
解决的方法只需加一个限定
tn, fp, fn, tp = confusion_matrix(target, pred, labels=[0, 1]).ravel()4. tensorboard打不开
查看是否已安装tensorflow/tensorboard/tensorboard_logger 若没有,pip 安装即可
打开时用命令
tensorboard --logdir=事件的上一极目录地址例如:tensorboard --logdir=/home/luo/code/pneu_classification/save/densenet103_190218
或者遇到错误:FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecat
这是因为numpy版本问题,解决方案:https://blog.csdn.net/kobe_academy/article/details/99706595
5.pytorch test报错:out of memory
训练和验证都没有超出显存*(一个batch以后才报),但测试的时候缺报:out of memory
因为在训练完一个batch后会释放内存:
optimizer.zero_grad()
loss.backward()
optimizer.step()但是测试的时候没有这几行代码,就可能一个batch后还占着内存,解决方法是把循环代码包在
with torch.no_grad():里面 with torch.no_grad():
for i, (input, target) in enumerate(test_loader):
input_var = torch.autograd.Variable(input)
target = target.cuda(async=True)
# compute output
output = model(input_var)
# torch to list
y_true.extend(target.cpu().data.tolist())
y_score.extend(output.cpu().data.tolist())
# measure error and record loss
err1, err2 = error(output.data, target, topk=(1, 2))
top1.update(err1, input.size(0))
top2.update(err2, input.size(0))
metric = allmetrics(output.cpu().data, target.cpu().squeeze())
for j in range(len(metric_arr)):
metric_arr[j] += metric[j]6.pytorch训练好的,网上预训练模型的加载
6.1 Missing key(s) in state_dict: "module.densenet121.features.denseblock1.denselayer1.norm1.weight"
Unexpected key(s) in state_dict: "module.densenet121.features.denseblock1.denselayer1.norm.1.weight"
原因:因为加载的两个模型写法不一样,一个用了nn.sequential,一个没用。所以module的名称不一样,加载不进去
解决方法:1,通过正则修改
model = DenseNet121(14, Fasle).cuda()
model = torch.nn.DataParallel(model).cuda()
pathModel = './models/m-25012018-123527.pth.tar'
Checkpoint = torch.load(pathModel, map_location=lambda storage, loc: storage)
pattern = re.compile(r'^(.*denselayer\d+\.(?:norm|relu|conv))\.((?:[12])\.'
r'(?:weight|bias|running_mean|running_var))$')
for key in list(Checkpoint['state_dict'].keys()):
res = pattern.match(key)
if res:
new_key = res.group(1) + res.group(2)
Checkpoint['state_dict'][new_key] = Checkpoint['state_dict'][key]
del Checkpoint['state_dict'][key]
model.load_state_dict(Checkpoint['state_dict'])2. 添加一个strict=False
model = DenseNet121(14, False).cuda()
model = torch.nn.DataParallel(model).cuda()
pathModel = './models/m-25012018-123527.pth.tar'
Checkpoint = torch.load(pathModel, map_location=lambda storage, loc: storage)
model.load_state_dict(Checkpoint['state_dict'], strict=False)两种方法都能正确加载自己训练好的模型,验证过,加载的值一样
6.2 Missing key(s) in state_dict: "densenet121.features.conv0.weight"
Unexpected key(s) in state_dict: "module.densenet121.features.conv0.weight",
原因:模型训练时用的DataParallel,保存时会在模块前面加一个‘module’
解决办法:1 使加载的模型也包含‘module’
model = DenseNet121(14, True).cuda()
model = torch.nn.DataParallel(model).cuda()
model.load_state_dict(Checkpoint['state_dict'], strict=False)2. 加载的模型不包含‘module’
model = DenseNet121(14, True).cuda()
new_state_dict = OrderedDict()
for k, v in pretrained_net_dict.items():
name = k[7:] # remove `module.`
new_state_dict[name] = v
model.load_state_dict(Checkpoint['state_dict'])
6.3 Missing key(s) in state_dict: "module.aspp1.convs.0.weight", "module.aspp1.convs.0.bias"
注意:只有Missing key(s) ,而没有Unexpected key(s) in state_dict
原因:在模型的初始化方法里,添加了state_dict中没有方法,以至于加载模型的参数的时候在state_dict里找不到对应的参数。

例如,我这里新增了一个aspp1的方法,但是保存模型的时候我没有这个方法,所以就报错了
解决办法:把新增的内容注释掉就行了。
7.ImportError: libSM.so.6: cannot open shared object file: No such file or directory import cv2报错
解决办法:访问该博客即可解决
8.Expected one of cpu, cuda, mkldnn, opengl, opencl, ideep, hip, msnpu device type at start of device string: cuda:0
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")从错误报告里知道,device是不能接“cuda:0”这个字符串的,只能接上面说的:cpu, cuda, mkldnn, opengl, opencl, ideep, hip
9.ModuleNotFoundError: No module named ‘spyder_kernels’
使用spyder编译器,切换Python环境时报错。解决办法:在该环境下直接安装 pip install spyder_kernels
10. RuntimeError: CUDA error: device-side assert triggered
Exception raised from operator() at /pytorch/aten/src/ATen/native/cuda/CUDAScalar.cu:32
报错如下:

大概意思就是loss计算的时候出现问题, 导致触发了cuda断言。
参考博客:https://blog.csdn.net/baoyongshuai1509/article/details/103314145/
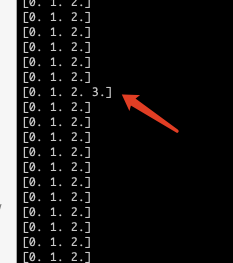
错误:本项目是3分割,label应该是0, 1,2。但是看下图,检查label的时候有个label范围超出了,所以在计算loss的时候就会有问题
11. RuntimeError: Failed to process string with tex because latex could not be found
RuntimeError: Failed to process string with tex because dvipng could not be found
调用matplotlib绘图时发生错误,没有latex或者dvipng, pip安装就好了
pip install latex
sudo apt-get install dvipng
sudo apt-get install -y texlive texlive-latex-extra texlive-latex-recommended
具体请参考:https://blog.csdn.net/weixin_42419002/article/details/103997521