模糊二维码数据集_ECCV2020去模糊之真实世界数据集Realblur
Real-World Blur Dataset for Learning and Benchmarking Deblurring Algorithms
这是一篇ECCV2020的数据集论文,主要贡献是提出了一个真实世界糊涂图像的数据集,算是一个“挖坑”工作。
简单解释一下这里所说的“挖坑工作”:
科研工作可以大致分为两种:定义问题(挖坑)和解决问题(埋坑)。绝大多数人会选择“新”的方式来解决已有问题这个叫埋坑,埋掉前人挖出来的坑;另外一种就是定义一个新的问题,交给后人去解决,比较有代表性的就是ImageNet了,这篇论文大概也可以算得上挖坑。
感觉挖坑要比埋坑有性价比的多~

GitHub:RealBlur
先从标题看,标题其实只有一个关键词Real-World
因为去模糊领域里,从传统方法到深度学习方法,实际上并没有真的需要被去模糊的图片。因为如果用真实的图片作为模糊图片去训练的话,那去哪里找可供参考的GT呢?,没有GT也就无从计算loss了。当下去模糊领域两个常用的数据集GOPRO数据集和REDS数据集都是Nah提出的,都是用高速相机照出不模糊的图像,然后在这个基础上处理成模糊的图像,原图像拿来做GT,这就出现一个问题,你怎么保证你处理出来的模糊图像更符合现实世界的模糊图像。
大家的解决思路有两点,其一是学习生成更符合现实世界的模糊图像:
比如CVPR2020优图实验室的这篇,他们的思路是通过两个GAN,一个来生成更符合真实世界的模糊图像,一个用来学习去模糊。相比DeblurGan有了一定的进步(DeblurGan的思路是只考虑的用GAN来学习去模糊)。
其二就是能不能直接通过相机拍摄出现实世界的模糊图像呢:
最早的想法是能不能通过长、短焦距的镜头来拍摄图像对,或者普通相机和高速相机的图像对来做blur image和GT呢,那样的话就涉及图片对齐的问题了,这篇论文其实也就是这样的想法,

简单来说就是两台相机同时拍摄,其中一个相机通过低快门速度捕获模糊图像,另一个通过高快门速度捕获GT图像,然后再通过他们的后处理方法来生成高质量的真实GT图像。
之前大家很多人都有过类似的想法,最早我也是希望通过这样的方式来做一个新的数据集(说不好就顶会了哈哈哈),但是图像对齐的问题始终没有思路,直到看到这篇论文,不过现在可以放弃这个idea了~人家把这个坑已经挖好了,你要不就去填坑要不就只能挖别的坑了。
Abstract
Abstract里说了两点工作:
其一是提出了真实世界模糊图像和地面真实锐利图像的大规模数据集,
其二是为了处理图像对齐问题开发了一种后处理方法来生成高质量的地面真实图像。
1.Introduction
这里提了一下为什么很难去开发实世界的模糊数据集:
在存在模糊的情况下,应将模糊图像的内容及其GT清晰图像进行几何对齐。这意味着两个图像应该在同一相机位置拍摄,这很困难,因为必须摇晃相机才能拍摄模糊的图像。
此外,用于图像去模糊的真实世界模糊数据集应满足以下要求。首先,数据集应涵盖相机抖动的最常见情况,即运动模糊最频繁发生的弱光环境。其次,地面真相清晰图像应该具有尽可能小的噪声。最后,模糊和地面真实的清晰图像应进行光度对准。
数据集的名字是RealBlur,由两个共享相同图像内容的子集组成,其中一个是从相机原始图像生成的,另一个是由相机ISP处理的JPEG图像生成的。每个子集提供232对弱光静态场景的4,556对模糊和真实的清晰GT图像。数据集中的模糊图像会因照相机震动而模糊,并在昏暗的环境(例如夜晚的街道和室内房间)中捕获,以涵盖运动模糊的最常见情况。
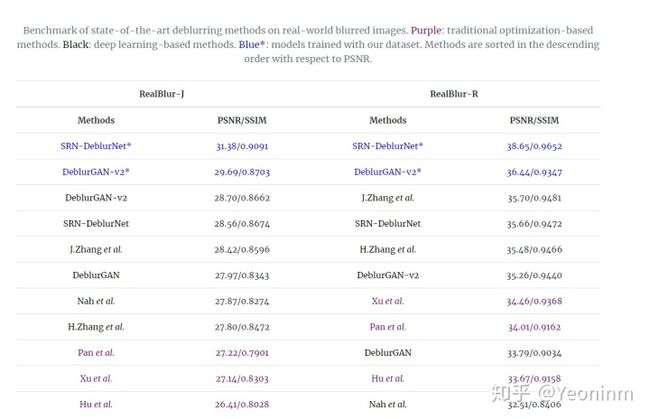
尽管这篇文章只提出了一个数据集,但是仍然投入了很大的工作量,基本上把现有的数据集(除了REDS)都做了一个对比,也在这个数据集上测试了绝大多数去模糊方法。
另外作者自己也提到了数据集没能收集动态场景模糊图像(由于上面那个两个相机组成的’big相机‘自身的限制),但是在论文中分析了使用这个数据集训练的网络依然可以很好地推广到具有移动对象的动态场景。
2.Related Work
这里有一点比较重要的就是作者介绍了一下通过GAN生成更真实的模糊图像这种方法,虽然通过GAN就不需要把模糊和清晰图像几何对齐了, 但是,由于它们依赖于生成网络,因此仅限于特定领域,例如,面孔和文字。
然后就介绍了一下他们的图像采集系统是受到几篇传统方法的启发:
Ben-Ezra, M., Nayar, S.: Motion deblurring using hybrid imaging. In: CVPR. pp. 657–664 (2003)
Tai, Y.W., Du, H., Brown, M.S., Lin, S.: Image/video deblurring using a hybrid camera. In: CVPR (2008)
Li, F., Yu, J., Chai, J.: A hybrid camera for motion deblurring and depth map super-resolution. In: CVPR (2008)
Yuan, L., Sun, J., Quan, L., Shum, H.: Image deblurring with blurred/noisy image pairs. In: SIGGRAPH (2007)
Ben-Ezra和Nayar 的那篇提出了一种混合摄像机系统,该系统配备了一个额外的高速低分辨率摄像机来捕获摄像机的运动。 Tai那篇扩展了空间变化模糊的方法。 Li提出了一种用于运动去模糊和深度图超分辨率的混合摄像机系统。 Yuan和Sorel等人使用包围曝光来捕获一对噪点和模糊图像,以进行准确的模糊核估计。
但是所有上述的这些方法都是为模糊核估计而设计的,既不提供高质量的真实GT图像,也不提供可以改善图像质量的后处理方法。
所以作者提出了Image Acquisition System和Postprocessing。
3.Image Acquisition System and Process
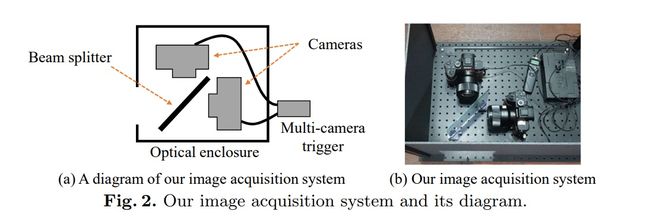
Image Acquisition System
为了同时捕获模糊和清晰的图像,构建了双摄像头系统。我们的系统包括一个分束器和两个摄像头,以便这些摄像头可以捕获相同的场景。摄像机和分束器安装在光学外壳中,以保护它们免受观看方向外部的光线的伤害。一台相机以低快门速度拍摄模糊的图像,而另一台相机以高快门速度拍摄清晰的图像。两款相机及其镜头均为相同型号(Sony A7RM3,Samyang 14mm F2.8 MF)。摄像机由多摄像机触发器同步以同时捕获图像。基于以下原因,我们的系统设计为具有全画幅传感器和广角镜的高端无反光镜相机 **。 首先,我们想将常规相机的相机内部处理反映到我们的数据集中,因为由相机ISP处理的模糊JPEG图像比原始图像更为常见。二,全画幅传感器和广角 镜头比小型传感器和窄角镜头可以聚集更多的光,因此它们可以更有效地抑制噪音。 广角镜头还有助于避免散焦模糊,这可能会对运动模糊的学习产生不利影响。
摄像机在物理上尽可能对齐。为了评估摄像机的对齐方式,我们进行了立体校准[50,15],并估计了摄像机之间的baseline。估计的baseline为8.22毫米,对应于在全分辨率下距离超过7.8米的对象的少于4个像素的视差,而在我们的最终数据集中包含了1/4下采样的图像的少于1个像素的视差。
Image Acquisition Process
使用我们的图像采集系统,我们捕获了各种室内和室外场景的模糊图像。对于每个场景,我们首先捕获一对(两个清晰的图像),称为参考对,它们将在后处理步骤中用于清晰和模糊图像的几何和光度对齐。然后,我们捕获了20张相同场景的模糊和清晰图像,以增加图像数量和相机抖动的多样性。对于参考对,我们将快门速度设置为1/80秒。并调整了ISO和光圈大小,以避免相机抖动造成的模糊。然后,我们对一台摄像机使用相同的摄像机设置来捕获清晰的图像,而将另一台摄像机的快门速度设置为1/2秒。 ISO值比参考ISO值低40倍,以拍摄相同亮度的模糊图像。为了捕获各种相机抖动,我们只需将系统保持静止以获取某些图像,然后随机移动系统以获取其他图像。在这两种情况下,由于曝光时间长,所以获得的图像模糊。我们捕获了232个不同场景的4,738对图像,包括参考对。我们捕获了相机原始格式和JPEG格式的所有图像,并生成了两个数据集:原始图像中的RealBlur-R和JPEG图像中的RealBlur-J。图3显示了RealBlur数据集中模糊图像的样本。

后处理方法包括三种:降采样和降噪、几何对齐、光度对齐,具体细节可以去论文里看,这里就不细说了(也没太懂)。
5.Experiments
看实验效果
Datasets and evaluation measure.
对于基准测试,从RealBlur-R和RealBlur-J中随机选择182个场景作为我们的训练集,其余50个场景作为我们的测试集。每个训练集由3,758个图像对组成,其中包括182个参考对,而每个测试集由980个图像对组成,没有参考对。我们在训练集中包括参考对,以便网络可以学习清晰图像的身份映射。除RealBlur外,我们还考虑了两个现有的去模糊数据集:GoPro 和K¨ohler的数据集。 GoPro数据集是最近基于深度学习的方法中使用最广泛的数据集,它是通过混合高速摄像机捕获的清晰视频帧而生成的合成数据集。 GoPro数据集为其训练和测试集提供了2,103和1,111对模糊和清晰的图像。 K¨ohler等人的数据集是一组带有真实相机抖动的小规模图像,这些图像是在受控实验室环境中捕获的。还考虑了另一个纯合成数据集,它是由BSD500细分数据集生成的。
Dataset comparison and training strategy
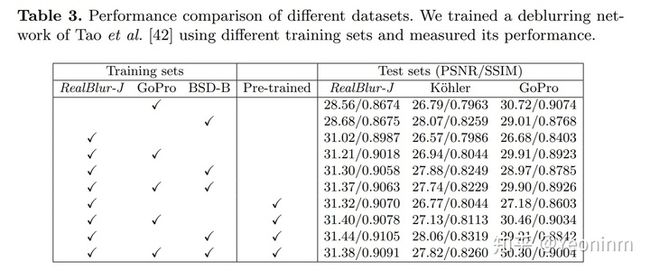
在对现有的去模糊方法进行基准测试之前,首先将数据集的性能与其他数据集对比,并寻求训练去模糊网络的最佳策略。具体来说,使用包括RealBlur在内的不同训练集的几种可能组合来准备去模糊网络的不同训练模型。然后,调查它们在不同测试集上的性能。为了进行评估,使用SRNDeblurNet。
表2和3显示了不同测试集上训练集的不同组合的性能。 “预训练”列指示是使用GoPro数据集根据预先训练的权重还是从头开始训练网络。从表中可以看出,与其他组合相比,GoPro数据集(表2和3中的第一行)在RealBlur测试集上的性能较低,这证明GoPro数据集不够真实,无法覆盖真实世界的模糊图像。 BSD-B数据集(表2和3中的第二行)在RealBlur测试集上的性能也很差,但在K¨ohler等人的测试集上却有很高的性能,这可能是因为K¨ohler等人。的数据集接近于合成,因为其图像是在受控实验室环境中捕获的。另一方面,RealBlur的训练集(表2和表3中的第三行)在RealBlur测试集上获得了更高的性能,这证明了现实世界中模糊训练数据的必要性。

6 Conclusion
提出第一个用于学习图像去模糊的大规模真实世界模糊数据集。为了收集数据集,我们构建了一个图像采集系统,该系统可以同时捕获一对模糊和清晰的图像。开发了一种后处理方法来生成高质量的地面真实图像,并分析了其几何对齐的效果和准确性。通过实验表明,RealBlur数据集可以极大地提高基于深度学习的去模糊方法在相机抖动和移动对象上对真实世界模糊图像的性能。
另外作者也给出了接下的工作方向
Limitations and future work.RealBlur数据集由静态场景组成,没有移动对象。虽然证明了用RealBlur训练的神经网络可以定性处理动态场景,但是动态场景数据集对于动态场景去模糊的定量评估至关重要。尽管使用无反光镜相机来收集现实世界中的模糊图像,但仍有大量用户使用智能手机相机。因此,收集此类低端相机的数据集将是一个有趣的未来工作。未来的工作可以为开发用于现实世界中模糊图像的去模糊方法提供基础。开发用于合成模糊图像的更现实的生成模型也将很有趣,该模型可用于学习图像去模糊,并且RealBlur数据集可用作其基础。