东北大学2023分布式操作系统实验
1.实验目的
建立伪分布式(有条件的可以建立分布式环境)的Hadoop环境,并成功运行示例程序。
2.Hadoop简介
2.1 Hadoop项目基础结构

在其核心,Hadoop主要有两个层次,即:
- 加工/计算层(MapReduce)
- 存储层(Hadoop分布式文件系统)
除了上面提到的两个核心组件,Hadoop的框架还包括以下两个模块:
- Hadoop通用:这是Java库和其他Hadoop组件所需的实用工具
- Hadoop YARN :这是作业调度和集群资源管理的框架
注:本实验主要涉及到:HDFS(分布式文件系统)、YARN(资源管理和调度框架)、以及MapReduce(离线计算)。
2.2 Hadoop组成架构
(1)HDFS架构简述

注:上述的master、slave1、slave2均是主机名(结点名)。
- NameNode :NameNode是HDFS部分的核心;NameNode又称为Master,储存着HDFS的元数据(即分布式文件系统中所有文件的目录树,并且跟踪追查整个Hadoop集群中的文件);NameNode本身不储存实际的数据或者是数据集,数据本身是储存在DataNode中;注意当NameNode这个节点关闭之后整个Hadoop集群将无法访问。
- DataNode:DataNode负责将实际的数据储存在HDFS中,DataNode也称作Slave,并且NameNode和DataNode会保持通信不断;如果某个DataNode关闭了之后并不会影响数据和整个集群的可用性,NameNode会将后续的任务交给其他启动着的DataNode;DataNode 会定期(dfs.heartbeat.interval 配置项配置,默认是 3 秒)向 NameNode 发送心跳,如果 NameNode 长时间没有接受到 DataNode 发送的心跳, NameNode 就会认为该 DataNode 失效;block 汇报时间间隔取参数 dfs.blockreport.intervalMsec,参数未配置的话默认为 6 小时。
- Secondary NameNode:Secondary NameNode主要是用于定期合并并且命名空间镜像的编辑日志;Secondary NameNode中保存了一份和NameNode一致的镜像文件(fsimage)和编辑日志(edits);如果NameNode发生故障是则可以从Secondary NameNode恢复数据。
保存作业的数据、配置信息等等,最后的结果也是保存在HDFS上面
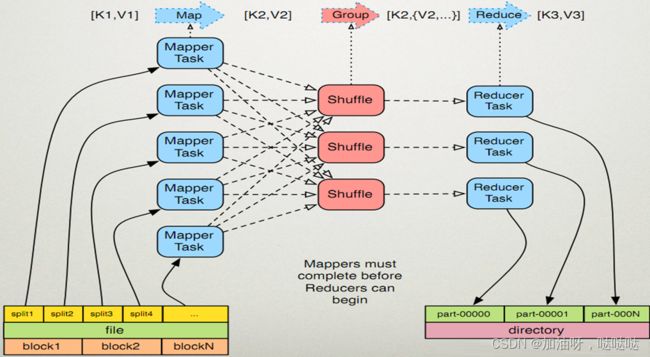
- Map阶段:映射或映射器的工作是处理输入数据。一般输入数据以存储在HDFS的文件或目录的形式,输入文件被传递到映射器功能线路,映射器处理该数据,并创建数据的若干小块。
- Reduce阶段:这个阶段是Shuffle阶段和Reduce阶段的组合。减速器的工作是处理该来自映射器中的数据。处理之后,它产生一组新的输出,这将被存储在HDFS。
(2)YARN架构简述

- ResourceManager: ResourceManager主要是负责与客户端交互,处理来自客户端的请求;启动和管理ApplicationMaster,并且在其运行失败的时候再重新启动它;管理NodeManager,接收来自NodeManager的资源汇报信息,并向NodeManager下达管理指令;资源管理与调度,接收来自ApplicationMaster的资源申请请求,并为之分配资源。
- NodeManager: NodeManager主要负责启动后向ResourceManager注册,然后与之保持通信,通过心跳汇报自己的状态以及接受来自RM的指令;监控节点的健康状态,并与ResourceManager同步;管理节点上所有的Container的生命周期,监控Container的资源使用情况,以及Container运行产生的日志,NodeManager会向ResourceManager汇报Container的状态信息;管理分布式缓存,以及不同应用程序的其他附属要求。
(3)MapReduce架构简述
MapReduce计划分三个阶段执行,即映射阶段,shuffle阶段,并减少阶段。

- Client客户端:用户可以通过Client客户端将自己编写的一些MapReduce程序给提交到JobTracker;也可以通过其提供的一些API查看一些作业的运行状态。
- JobTracker:JobTracker主要是负责作业调度和资源的监控;JobTracker如果发现有一些作业失败的情况,就会将对应任务给转移到其他的结点;JobTracker同时也会追踪任务的执行进度和资源的使用情况,并将这些情况转发给Task Scheduler(任务调度器),Task Scheduler调度器在资源出现空闲的时候会将这些资源分配给合适的作业。
- TaskTracker:TaskTracker会周期性的通过心跳(Heartbeat)将自己结点的资源使用情况以及作业的运行进度发送给JobTracker,同时也会接收JobTracker发送回来的指令并执行;TaskTracker使用“slot”等量划分本节点上的资源量。“slot”代表计算资源(CPU、内存等),一个Task获取到一个slot后才有机会运行,而Hadoop调度器的作用就是将各个TaskTracker上的空闲slot分配给Task使用;slot分为Map slot和Reduce slot两种,分别供Map Task和Reduce Task使用。TaskTracker通过slot数目(可配置参数)限定Task的并发度。
- Map Task:Map Task会将对应的数据解析成一个键值对(key/value),最后调用用户的map()函数处理,将临时的结果储存在本地的磁盘上,其中一个临时的结果会被划分成若干块,每一块会被一个Reduce Task处理。
- Reduce Task:将排序好了的键值对一次读取,再调用用户的reduce()函数进行处理,最后将处理结果储存在HDFS上面。
在一个MapReduce工作过程中:
- 由Hadoop发送Map和Reduce任务到集群的相应服务器;
- 框架管理数据传递,例如发出任务的所有节点之间的集群周围的详细信息,验证任务完成,和复制数据;
- 大部分的计算发生在与在本地磁盘上,可以减少网络通信量数据的节点;
- 给定的任务完成后,将收集并减少了数据,以一个合适的结果发送回Hadoop服务器。
2.3 HDFS常用命令
- 运行jar包:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar wordcount /input /output - 文件系统操作:
hadoop fs -cat | ls|mkdir - 上传文件:
hadoop dfs -put ./testdata.txt /testdata - 递归删除目录及文件:
hadoop fs -rmr /testdata - 删除文件:
hadoop fs -rm /testdata.txt
3.实验准备
3.1 平台选择
- VMware Workstation 16 Pro
- Ubuntu20.04 LTS
- Java 1.8.0_351
- Hadoop 3.3.4
3.2 VMware 16 安装
安装比较简单,可参考如下链接: VMware Workstation Pro 16 安装教程
3.3 Ubuntu20.04 LTS安装
安装比较简单,可参考如下链接:VMware16.0上安装ubuntu20.04
安装Ubuntu后,需要换源,换为国内源,方面下载软件,环境比较简单,可参考如下链接:Ubuntu20.04换源
注意:安装Ubuntu时,建议断网安装。在安装时,如果联网,会自动更新软件,因为源为国外的,下载速度很慢,需花较多时间安装。
3.4 java安装
(1)下载安装包
进入官网下载安装包(现在需要登录Oracle才能下载,没有的话先去注册)
Java SE Development Kit 8 Downloads

(2)解压文件
# 新建目录
sudo mkdir /usr/local/java
# 解压java安装包至 /usr/local/java
sudo tar jdk-8u351-linux-x64.tar.gz -C /usr/local/java
(3)添加环境变量
将java环境变量添加至Ubuntu全局环境变量中
dd@wdn:~/wdn_hdfs$ sudo vim /etc/profile
# 在profile文件最后追加以下内容
# java
export JAVA_HOME=/usr/local/java/jdk1.8.0_351
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH
export JAVA_PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin
export PATH=$PATH:${JAVA_PATH}
# 保存,退出
:wq
# source命令更新环境变量
dd@wdn:~/wdn_hdfs$ source /etc/profile
(4)验证是否安装成功
然后查看java版本,结果是1.8版本,说明安装成功
dd@wdn:~/wdn_hdfs$ java -version
java version "1.8.0_351"
Java(TM) SE Runtime Environment (build 1.8.0_351-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.351-b10, mixed mode)
3.5 SSH安装
如果要使用可选的启动和停止脚本,则必须安装ssh并运行sshd才能使用管理远程Hadoop守护进程的Hadoop脚本。此外,建议还安装pdsh以更好地管理ssh资源
dd@wdn:~/wdn_hdfs$ sudo apt install ssh
dd@wdn:~/wdn_hdfs$ sudo apt install pdsh
3.6 Hadoop下载安装
请从[Apache镜像](Apache Downloads)下载Hadoop软件,版本为 hadoop 3.3.4 。
解压Hadoop安装包文件
# 解压
dd@wdn:~/wdn_hdfs$ sudo tar -zxvf hadoop-3.3.4.tar.gz
# 查看解压文件
dd@wdn:~/wdn_hdfs$ cd hadoop-3.3.4/
dd@wdn:~/wdn_hdfs/hadoop-3.3.4$ ls
bin include libexec licenses-binary NOTICE-binary README.txt share
etc lib LICENSE-binary LICENSE.txt NOTICE.txt sbin
然后查看hadoop版本,检查是否安装成功
dd@wdn:~/wdn_hdfs/hadoop-3.3.4$ bin/hadoop version
Hadoop 3.3.4
Source code repository https://github.com/apache/hadoop.git -r a585a73c3e02ac62350c136643a5e7f6095a3dbb
Compiled by stevel on 2022-07-29T12:32Z
Compiled with protoc 3.7.1
From source with checksum fb9dd8918a7b8a5b430d61af858f6ec
This command was run using /home/dd/wdn_hdfs/hadoop-3.3.4/share/hadoop/common/hadoop-common-3.3.4.jar
编辑etc/hadoop/hadoop-env.sh文件,设置java环境变量
# vim 打开 etc/hadoop/hadoop-env.sh 文件
dd@wdn:~/wdn_hdfs/hadoop-3.3.4$ vim etc/hadoop/hadoop-env.sh
# 编辑 etc/hadoop/hadoop-env.sh 文件,增加java环境变量
export JAVA_HOME=/usr/local/java/jdk1.8.0_351
# 退出,保存
使用hadoop命令验证是否配置成功,若显示命令使用文档,则配置成功
dd@wdn:~/wdn_hdfs/hadoop-3.3.4$ bin/hadoop
Usage: hadoop [OPTIONS] SUBCOMMAND [SUBCOMMAND OPTIONS]
or hadoop [OPTIONS] CLASSNAME [CLASSNAME OPTIONS]
where CLASSNAME is a user-provided Java class
....
SUBCOMMAND may print help when invoked w/o parameters or with -h.
4.Hadoop伪分布式
Hadoop也可以在单个节点上以伪分布式模式运行,其中每个Hadoop守护进程在单独的Java进程中运行。
4.1 配置
(1)etc/hadoop/core-site.xml 文件配置
在每个结点中都要配置本文件。该配置表示,HDFS的主节点访问地址为localhost:9000。在伪分布式模式下,结点只有一个,主结点和从结点都为本节点,所以可以通过localhost找到主结点。如果在分布式模式下,此处loaclhost应当使用主结点的实际 IP 地址。
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://localhost:9000value>
property>
configuration>
(2)etc/hadoop/hdfs-site.xml 文件配置
该文件表示HDFS中每个文件有1个备份,如果在分布式模式下,最好设置为3
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
configuration>
4.2 设置无密码SSH
该步骤的目的是为了在启动Hadoop的过程中,免去输入Linux登录密码。在分布式模式下,如果省略该步骤,就会要求主结点为每个从结点输入密码
现在检查是否可以通过ssh连接到本地主机,而无需密码:
dd@wdn:~/wdn_hdfs/hadoop-3.3.4$ ssh localhost
The authenticity of host 'localhost (127.0.0.1)' can't be established.
无法在没有密码短语的情况下ssh到localhost,请执行以下命令:
dd@wdn:~/wdn_hdfs/hadoop-3.3.4$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
dd@wdn:~/wdn_hdfs/hadoop-3.3.4$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
dd@wdn:~/wdn_hdfs/hadoop-3.3.4$ chmod 0600 ~/.ssh/authorized_keys
4.3 运行
(1)格式化文件系统
namenode即为HDFS主结点,该命令为格式化,在后续实验中,如果出现未知错误无法解决,可以重新格式化。
dd@wdn:~/wdn_hdfs/hadoop-3.3.4$ bin/hdfs namenode -format
2022-12-17 22:28:54,654 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = wdn/127.0.1.1
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 3.3.4
STARTUP_MSG: classpath = /home/dd/wdn_hdfs/hadoop-3.3.4/etc/hadoop:/home/dd/wdn_hdfs/hadoop-applicationhistoryservice-3.3.4.jar:/home/dd/wdn_hdfs/hadoop-3.3.4/share/hadoop/yarn/hadoop-yarn-applications-distributedshell-3.3.4.jar
...
STARTUP_MSG: build = https://github.com/apache/hadoop.git -r a585a73c3e02ac62350c136643a5e7f6095a3dbb; compiled by 'stevel' on 2022-07-29T12:32Z
STARTUP_MSG: java = 1.8.0_351
************************************************************/
2022-12-17 22:28:54,662 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT]
...
2022-12-17 22:28:55,544 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown.
2022-12-17 22:28:55,550 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at wdn/127.0.1.1
************************************************************/
(2)启动NameNode和DataNode
namenode为主结点,datanode为从结点,该命令启动所有。
dd@wdn:~/wdn_hdfs/hadoop-3.3.4$ sbin/start-dfs.sh
Starting namenodes on [localhost]
Starting datanodes
Starting secondary namenodes [wdn]
Hadoop守护程序日志输出被写入$HADOOP_LOG_DIR目录(默认为$HADOOP_HOME/logs)。
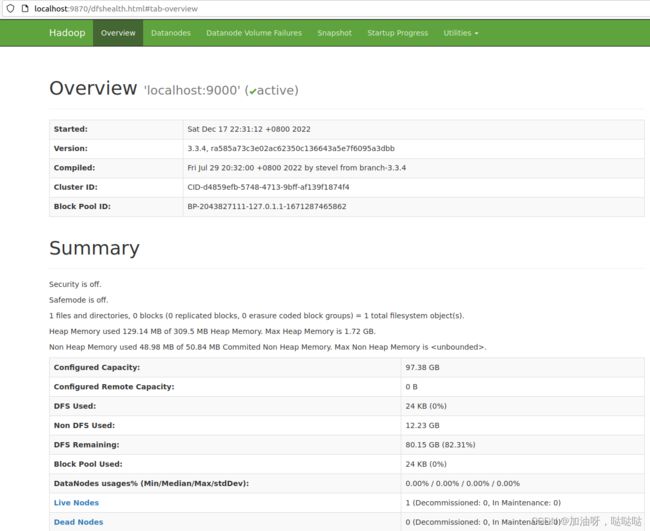
(3)浏览NameNode的web界面
默认情况下,它位于:http://localhost:9870/
(4)制作执行MapReduce作业所需的HDFS目录
建立一个文件,名字可以自己起
dd@wdn:~/wdn_hdfs/hadoop-3.3.4$ bin/hdfs dfs -mkdir /user
dd@wdn:~/wdn_hdfs/hadoop-3.3.4$ bin/hdfs dfs -mkdir /user/wdn
(5)将输入文件复制到分布式文件系统
其中:
- input文件夹用来放MapReduce作业的输入文件
- put后的第一个参数就是输入文件,这里使用的是hadoop所有xml配置文件,也可以自行选择任意文件
dd@wdn:~/wdn_hdfs/hadoop-3.3.4$ bin/hdfs dfs -mkdir -p input
dd@wdn:~/wdn_hdfs/hadoop-3.3.4$ bin/hdfs dfs -put etc/hadoop/*.xml input
(6)运行提供的一些示例
运行hadoop example当中的grep程序,该程序的具体作用可以自行查阅资料
dd@wdn:~/wdn_hdfs/hadoop-3.3.4$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar grep input output 'dfs[a-z.]+'
2022-12-17 22:44:11,757 INFO impl.MetricsConfig: Loaded properties from hadoop-metrics2.properties
....
File System Counters
FILE: Number of bytes read=282303
FILE: Number of bytes written=918208
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=11765
HDFS: Number of bytes written=0
HDFS: Number of read operations=5
HDFS: Number of large read operations=0
HDFS: Number of write operations=1
HDFS: Number of bytes read erasure-coded=0
Map-Reduce Framework
Map input records=275
Map output records=1
Map output bytes=17
Map output materialized bytes=25
Input split bytes=118
Combine input records=1
Combine output records=1
Spilled Records=1
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=60
Total committed heap usage (bytes)=388497408
File Input Format Counters
Bytes Read=11765
...
2022-12-17 22:44:15,567 INFO mapreduce.Job: Counters: 36
File System Counters
FILE: Number of bytes read=1143072
FILE: Number of bytes written=3661477
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=59544
HDFS: Number of bytes written=233
HDFS: Number of read operations=73
HDFS: Number of large read operations=0
HDFS: Number of write operations=14
HDFS: Number of bytes read erasure-coded=0
Map-Reduce Framework
Map input records=1
Map output records=1
Map output bytes=17
Map output materialized bytes=25
Input split bytes=128
Combine input records=0
Combine output records=0
Reduce input groups=1
Reduce shuffle bytes=25
Reduce input records=1
Reduce output records=1
Spilled Records=2
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=0
Total committed heap usage (bytes)=1460666368
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=111
File Output Format Counters
Bytes Written=11
(7)检查输出文件
将输出文件从分布式文件系统复制到本地文件系统并检查它们
dd@wdn:~/wdn_hdfs/hadoop-3.3.4$ bin/hdfs dfs -get output output
dd@wdn:~/wdn_hdfs/hadoop-3.3.4$ cat output/*
1 dfsadmin
1 dfs.replication
dd@wdn:~/wdn_hdfs/hadoop-3.3.4$ bin/hdfs dfs -cat output/*
1 dfsadmin
1 dfs.replication
(8)停止Hadoop集群
dd@wdn:~/wdn_hdfs/hadoop-3.3.4$ sbin/stop-dfs.sh
Stopping namenodes on [localhost]
Stopping datanodes
Stopping secondary namenodes [wdn]
4.4 单个节点YARN
通过设置一些参数并另外运行ResourceManager守护程序和NodeManager守护程序,可以在YARN上以伪分布式模式运行MapReduce作业。
以下指令假设已执行上述指令的1~4步骤
(1)配置参数
etc/hadoop/mapred-site.xml 文件配置
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.application.classpathname>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*value>
property>
configuration>
etc/hadoop/yarn-site.xml 文件配置
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.env-whitelistname>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOMEvalue>
property>
configuration>
(2)启动ResourceManager守护程序和NodeManager守护程序
dd@wdn:~/wdn_hdfs/hadoop-3.3.4$ sbin/start-yarn.sh
Starting resourcemanager
Starting nodemanagers
(3)浏览ResourceManager的web界面;
默认情况下,它位于 http://localhost:8088

(4)运行MapReduce作业
提交一个MapReduce作业到YARN上
hadoop的根目录下找到有一个share/hadoop/mapreduce 下,有一个hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar,这是hadoop提供的一个mapreduce测试jar文件。
输入命令:hadoop jar [jar文件地址] 别名 参数1 参数2
dd@wdn:~/wdn_hdfs/hadoop-3.3.4$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar pi 2 3
Number of Maps = 2
Samples per Map = 3
Wrote input for Map #0
Wrote input for Map #1
Starting Job
2022-12-18 14:52:29,787 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at /0.0.0.0:8032
2022-12-18 14:52:30,510 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/dd/.staging/job_1671346336225_0001
2022-12-18 14:52:30,847 INFO input.FileInputFormat: Total input files to process : 2
...
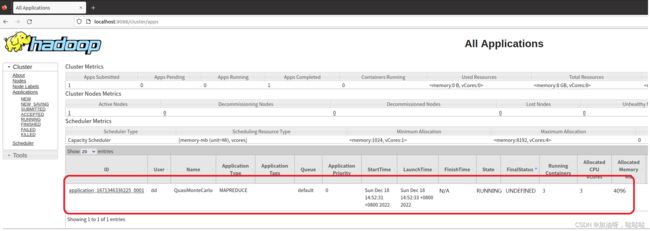
进入yarn的管理界面,如下就可以看到运行状态的任务:
(5)停止YARN
完成后,使用以下命令停止守护程序。
dd@wdn:~/wdn_hdfs/hadoop-3.3.4$ sbin/stop-yarn.sh
Stopping nodemanagers
Stopping resourcemanager
5.Hadoop完全分布式
需要三台虚拟机操作,其中一台为master主节点,两台为子节点;IP分配如下:
master:192.168.118.129slave1:192.168.118.130slave2:192.168.118.131
Note:hadoop根目录:/home/dd/wdn_hdfs/hadoop-3.3.4
5.1 Hadoop核心文件配置
(1)etc/hadoop/hadoop-env.sh 文件配置
export JAVA_HOME=/usr/local/java/jdk1.8.0_351
# dd是我自己的用户名
export HDFS_NAMENODE_USER=dd
export HDFS_DATANODE_USER=dd
export HDFS_SECONDARYNAMENODE_USER=dd
export YARN_RESOURCEMANAGER_USER=dd
export YARN_NODEMANAGER_USER=dd
(2)etc/hadoop/core-site.xml 文件配置
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://master:8020value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/home/dd/wdn_hdfs/hadoop-3.3.4/tmpvalue>
property>
<property>
<name>hadoop.http.staticuser.username>
<value>ddvalue>
property>
configuration>
(3)etc/hadoop/hdfs-site.xml 文件配置
<configuration>
<property>
<name>dfs.namenode.http-addressname>
<value>master:9870value>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>slave2:9868value>
property>
configuration>
(4)etc/hadoop/yarn-site.xml 文件配置
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>slave1value>
property>
<property>
<name>yarn.nodemanager.env-whitelistname>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOMEvalue>
property>
<property>
<name>yarn.application.classpathname>
<value>/home/dd/wdn_hdfs/hadoop-3.3.4/etc/hadoop:/home/dd/wdn_hdfs/hadoop-3.3.4/share/hadoop/common/lib/*:/home/dd/wdn_hdfs/hadoop-3.3.4/share/hadoop/common/*:/home/dd/wdn_hdfs/hadoop-3.3.4/share/hadoop/hdfs:/home/dd/wdn_hdfs/hadoop-3.3.4/share/hadoop/hdfs/lib/*:/home/dd/wdn_hdfs/hadoop-3.3.4/share/hadoop/hdfs/*:/home/dd/wdn_hdfs/hadoop-3.3.4/share/hadoop/mapreduce/*:/home/dd/wdn_hdfs/hadoop-3.3.4/share/hadoop/yarn:/home/dd/wdn_hdfs/hadoop-3.3.4/share/hadoop/yarn/lib/*:/home/dd/wdn_hdfs/hadoop-3.3.4/share/hadoop/yarn/*
value>
property>
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
<property>
<name>yarn.log.server.urlname>
<value>http://slave1:19888/jobhistory/logsvalue>
property>
<property>
<name>yarn.log-aggregation.retain-secondsname>
<value>604800value>
property>
<property>
<name>yarn.nodemanager.vmem-check-enabledname>
<value>falsevalue>
property>
configuration>
(5)etc/hadoop/mapred-site.xml 文件配置
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.application.classpathname>
<value>/home/dd/wdn_hdfs/hadoop-3.3.4/share/hadoop/mapreduce/*:/home/dd/wdn_hdfs/hadoop-3.3.4/share/hadoop/mapreduce/lib/*value>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>slave1:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>slave1:19888value>
property>
configuration>
(6)workers 文件配置
master
slave1
slave2
这里的master是此台虚拟机的主机名,slave1、slave2是后面我们将会克隆的另外两台虚拟机的主机名。
5.2 Hadoop从属结点虚拟机克隆、以及配置
(1)克隆虚拟机
关闭master主结点的虚拟机,克隆虚拟机,最终克隆三台虚拟机:

(2)修改IP及主机名
设置master节点IP为192.168.118.129,主机名为master

设置slave1节点IP为192.168.118.130,主机名为slave1
设置slave2节点IP为192.168.118.131,主机名为slave2
(4)虚拟机间IP地址映射
设置master、slave1、slave2节点的IP地址映射
# 打开 hosts 文件
dd@master:~$ sudo vim /etc/hosts
# 增加IP地址映射
192.168.118.129 master
192.168.118.130 slave1
192.168.118.131 slave2
# 保存
:wq

5.3 三台虚拟机之间的SSH免密登录访问
(1)安装SSH
分别在三台机器的命令行中输入以下命令安装SSH服务端,因为Ubuntu操作系统已经默认安装了SSH的客户端,所以这里只需要安装SSH服务端就好了。
sudo apt-get install openssh-server
(2)节点master配置
然后依次执行以下的命令:
# 生成密钥
dd@master:~/.ssh$ ssh-keygen -t rsa
# 将生成的密钥添加到同一目录下的authorized_keys授权文件中
dd@master:~/.ssh$ cat ./id_rsa.pub >> ./authorized_keys
# 显示生成文件
dd@master:~/.ssh$ ls
authorized_keys id_rsa id_rsa.pub
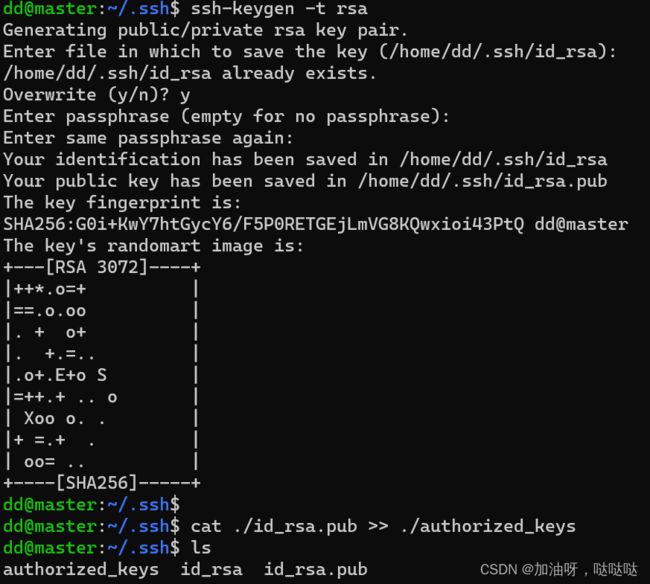
其中:
- authorized_keys:授权文件
- id_rsa.pub:密钥
然后在将master的公钥发送到slave1和slave2两台机器上去
# 发送至slave1
dd@master:~/.ssh$ scp id_rsa.pub dd@slave1:~/.ssh/master_rsa.pub
# 发送至slave2
dd@master:~/.ssh$ scp id_rsa.pub dd@slave2:~/.ssh/master_rsa.pub

(3)节点slave1配置
然后依次执行以下的命令:
# 生成密钥
dd@slave1:~/.ssh$ ssh-keygen -t rsa
# 将生成的密钥添加到同一目录下的authorized_keys授权文件中
dd@slave1:~/.ssh$ cat ./id_rsa.pub >> ./authorized_keys
# 显示生成文件
dd@slave1:~/.ssh$ ls
authorized_keys id_rsa id_rsa.pub master_rsa.pub

其中:
- authorized_keys:授权文件
- id_rsa.pub:密钥
然后在将slave1的公钥发送到master和slave2两台机器上去
# 发送至master
dd@slave1:~/.ssh$ scp id_rsa.pub dd@master:~/.ssh/slave1_rsa.pub
# 发送至slave2
dd@slave1:~/.ssh$ scp id_rsa.pub dd@slave2:~/.ssh/slave1_rsa.pub
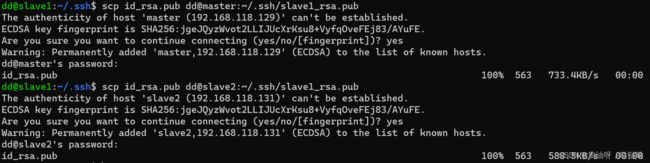
(4)节点slave2配置
然后依次执行以下的命令:
# 生成密钥
dd@slave2:~/.ssh$ ssh-keygen -t rsa
# 将生成的密钥添加到同一目录下的authorized_keys授权文件中
dd@slave2:~/.ssh$ cat ./id_rsa.pub >> ./authorized_keys
# 显示生成文件
dd@slave2:~/.ssh$ ls
authorized_keys id_rsa id_rsa.pub master_rsa.pub slave1_rsa.pub
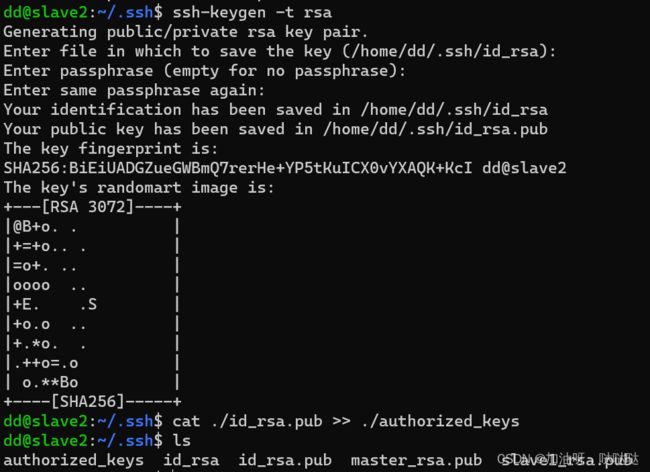
其中:
- authorized_keys:授权文件
- id_rsa.pub:密钥
然后在将slave2的公钥发送到slave1和master两台机器上去
# 发送至master
dd@slave2:~/.ssh$ scp id_rsa.pub dd@master:~/.ssh/slave2_rsa.pub
# 发送至slave2
dd@slave2:~/.ssh$ scp id_rsa.pub dd@slave1:~/.ssh/slave2_rsa.pub
(5)将密钥添加到授权文件中
在master中执行以下命令将slave1和slave2的密钥添加到授权文件当中:
dd@master:~/.ssh$ ls
authorized_keys id_rsa id_rsa.pub known_hosts slave1_rsa.pub slave2_rsa.pub
# 添加slave1的密钥到授权文件中
dd@master:~/.ssh$ cat ./slave1_rsa.pub >> ./authorized_keys
# 添加slave2的密钥到授权文件中
dd@master:~/.ssh$ cat ./slave2_rsa.pub >> ./authorized_keys
# 配置权限
chmod 0600 authorized_keys
在slave1中执行以下命令将master和slave2的密钥添加到授权文件当中:
dd@slave1:~/.ssh$ ls
authorized_keys id_rsa id_rsa.pub known_hosts master_rsa.pub slave2_rsa.pub
# 添加master的密钥到授权文件中
dd@slave1:~/.ssh$ cat ./master_rsa.pub >> ./authorized_keys
# 添加slave2的密钥到授权文件中
dd@slave1:~/.ssh$ cat ./slave2_rsa.pub >> ./authorized_keys
# 配置权限
chmod 0600 authorized_keys
在slave2中执行以下命令将slave1和master的密钥添加到授权文件当中:
dd@slave2:~/.ssh$ ls
authorized_keys id_rsa id_rsa.pub known_hosts master_rsa.pub slave1_rsa.pub
# 添加master的密钥到授权文件中
dd@slave2:~/.ssh$ cat ./master_rsa.pub >> ./authorized_keys
# 添加slave1的密钥到授权文件中
dd@slave2:~/.ssh$ cat ./slave1_rsa.pub >> ./authorized_keys
# 配置权限
chmod 0600 authorized_keys
(6)测试
配置好了之后可以分别测试一下配置是否成功(第一次连接会输一次密码,后面就不会让你输密码了,可以第一次连上后再exit断开,再测试第二次,看看效果):

其余两个节点也可以免密登录,此处不再演示。
5.4 Hadoop集群规划
| 主机名 | NN | JJN | DN | RM | NM | SNN |
|---|---|---|---|---|---|---|
| master | NameNode | DataNode | NodeManager | |||
| slave1 | JournalNode | DataNode | ResourceManager | NodeManager | ||
| slave2 | DataNode | NodeManager | SecondaryNameNode |
5.5 Hadoop集群运行
(1)master节点
第一次启动集群,需要将文件系统初始化,输入以下命令:
# 进入hadoop-3.3.4的安装目录
dd@master:~$ cd wdn_hdfs/hadoop-3.3.4/
dd@master:~/wdn_hdfs/hadoop-3.3.4$ pwd
/home/dd/wdn_hdfs/hadoop-3.3.4
# 初始化HDFS文件系统
dd@master:~/wdn_hdfs/hadoop-3.3.4$ bin/hdfs namenode -format
WARNING: /home/dd/wdn_hdfs/hadoop-3.3.4/logs does not exist. Creating.
2022-12-18 18:04:51,256 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = master/127.0.1.1
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 3.3.4
STARTUP_MSG: classpath = /home/dd/wdn_hdfs/hadoop-3.3.4/etc/hadoop
...
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at master/127.0.1.1
************************************************************/
注意:只有第一次启动集群需要初始化HDFS文件系统,如果后续再执行初始化文件系统(格式化NameNode)由于每次初始化都会产生新的集群id,会导致NameNode和DataNode的集群id不一样,导致集群找不到以往的数据。如果非要再格式化一次,那就把三台机器下的/home/dd/wdn_hdfs/hadoop-3.3.4/目录下的tmp和logs文件夹删除,再格式化NameNode。
初始化完文件系统后,继续输入,启动HDFS:
# 启动HDFS
dd@master:~/wdn_hdfs/hadoop-3.3.4$ sbin/start-dfs.sh
Starting namenodes on [master]
Starting datanodes
Starting secondary namenodes [slave2]
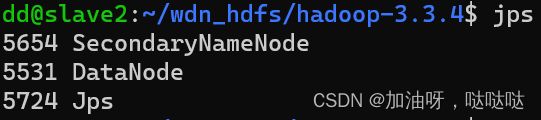
然后在三台虚拟机中分别输入jps命令查看是否启动成功:
- master:

- slave1:

- slave2:
(2)slave1节点中启动YARN
因为我们配置的ResourceManager结点是slave1,所以在slave1中执行下面的命令:
# 转到hadoop-3.3.4的安装目录下
dd@slave1:~$ cd ~/wdn_hdfs/hadoop-3.3.4/
# 启动yarn
dd@slave1:~/wdn_hdfs/hadoop-3.3.4$ sbin/start-yarn.sh
Starting resourcemanager
resourcemanager is running as process 3668. Stop it first and ensure /tmp/hadoop-dd-resourcemanager.pid file is empty before retry.
Starting nodemanagers
slave1: Warning: Permanently added 'slave1' (ECDSA) to the list of known hosts.
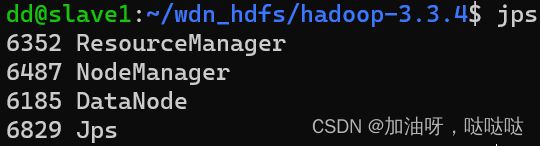
在三台机器中执行jps查看是否启动成功:
- master:

- slave1:
- slave2:

(3)在Web端验证HDFS和YARN是否启动成功
打开浏览器输入 :http://master:9870
如果出现以下Hadoop页面则说明HDFS配置成功:

再输入网址(ResourceManager):http://slave1:8088
出现以下页面则说明启动成功:

(4)文件上传文件测试,以及Wordcount功能测试
按照以下命令创建并进入word.txt文件:
# 创建上传文件
dd@master:~/wdn_hdfs/hadoop-3.3.4$ mkdir input
dd@master:~/wdn_hdfs/hadoop-3.3.4$ touch input/word.txt
dd@master:~/wdn_hdfs/hadoop-3.3.4$ chmod 777 input/word.txt
dd@master:~/wdn_hdfs/hadoop-3.3.4$ vim input/word.txt
然后在文件中添加以下内容以供测试:
hello hadoop hive hbase spark flink
hello hadoop hive hbase spark
hello hadoop hive hbase
hello hadoop hive
hello hadoop
hello
添加完成后退出文本编辑,然后再输入以下命令:
# 将word.txt文件传送到HDFS下的/input目录下
dd@master:~/wdn_hdfs/hadoop-3.3.4$ bin/hadoop fs -put /home/dd/wdn_hdfs/hadoop-3.3.4/input/word.txt /input
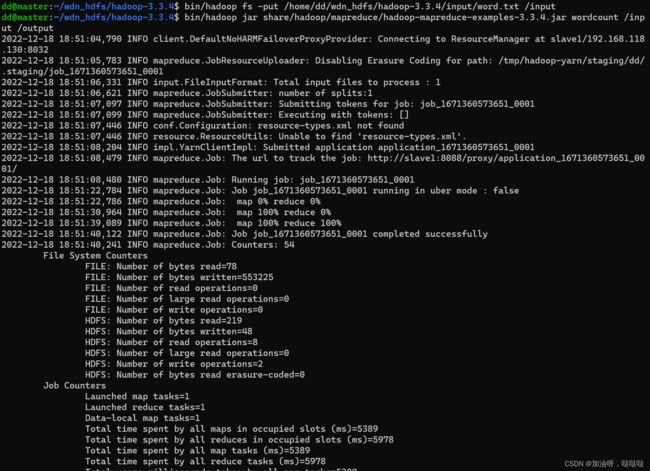
# 执行wordcount程序来对文件中的单词计数
dd@master:~/wdn_hdfs/hadoop-3.3.4$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar wordcount /
input /output
然后可以输入一下语句来查看统计的结果:
# 转到运行程序是设置的输出目录下面并查看其中的文件
dd@master:~/wdn_hdfs/hadoop-3.3.4$ bin/hdfs dfs -ls /output
Found 2 items
-rw-r--r-- 3 dd supergroup 0 2022-12-18 18:51 /output/_SUCCESS
-rw-r--r-- 3 dd supergroup 48 2022-12-18 18:51 /output/part-r-00000
Wordcount程序运行的结果所在:
# 查看这个结果储存文件
dd@master:~/wdn_hdfs/hadoop-3.3.4$ bin/hdfs dfs -cat /output/part-r-00000
flink 1
hadoop 5
hbase 3
hello 6
hive 4
spark 2
最后的统计结果就如下图所示:

除了命令行这种查看方式也可以在web端查看:
打开浏览器输入:http://master:9870
进入到如下页面:


(5)启动历史服务器
转到slave1节点下启动历史服务器服务:
# 启动历史服务器
dd@slave1:~/wdn_hdfs/hadoop-3.3.4$ bin/mapred --daemon start historyserver

然后回到浏览器输入以下网址:http://slave1:8088/cluster
然后再点击history可查看此任务执行的历史信息:

点开logs后,可以看到历史记录:

(6)关闭Hadoop集群
进入master节点,进入命令行输入以下命令关闭HDFS:
# master节点,关闭dfs
dd@master:~/wdn_hdfs/hadoop-3.3.4$ sbin/stop-dfs.sh
Stopping namenodes on [master]
Stopping datanodes
Stopping secondary namenodes [slave2]
进入slave1节点下去输入以下命令关闭YARN和历史服务器:
# slave1节点,关闭YARN
dd@slave1:~/wdn_hdfs/hadoop-3.3.4$ sbin/stop-yarn.sh
Stopping nodemanagers
Stopping resourcemanager
# slave1节点,关闭history服务
dd@slave1:~/wdn_hdfs/hadoop-3.3.4$ bin/mapred --daemon stop historyserver
6.出现问题
6.1 pdsh rcmd: socket: Permission denied
错误位置:伪分布式运行第二步启动时出现此问题
错误信息:
dd@wdn:~/wdn_hdfs/hadoop-3.3.4$ sbin/start-dfs.sh
Starting namenodes on [localhost]
pdsh@wdn: localhost: rcmd: socket: Permission denied
Starting datanodes
pdsh@wdn: localhost: rcmd: socket: Permission denied
Starting secondary namenodes [wdn]
pdsh@wdn: wdn: rcmd: socket: Permission denied
解决方法:
dd@wdn:~$ export PDSH_RCMD_TYPE=ssh
dd@wdn:~$ source ~/.bashrc
6.2 INFO ipc.Client: Retrying connect to server
错误位置:完全分布式上传文件出现此错误
错误信息:
# 上传文件
dd@master:~/wdn_hdfs/hadoop-3.3.4$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar wordcount /input /output
2022-12-18 18:40:41,240 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at slave1/192.168.118.130:8032
2022-12-18 18:40:43,001 INFO ipc.Client: Retrying connect to server: slave1/192.168.118.130:8032. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
2022-12-18 18:40:44,003 INFO ipc.Client: Retrying connect to server: slave1/192.168.118.130:8032. Already tried 1 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
2022-12-18 18:40:45,005 INFO ipc.Client: Retrying connect to server: slave1/192.168.118.130:8032. Already tried 2 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
解决方法:
找到/etc/hosts文件,用sudo命令打开,将127.0.0.1和127.0.1.1的映射注释掉即可。
注意:如果及设计的是分布式的,就要把master和slave中的hosts文件都要修改,伪分布式的就无所谓了,因为它只有一个配置文件。
# 打开hosts文件
dd@master:~/wdn_hdfs/hadoop-3.3.4$ sudo vim /etc/hosts
[sudo] password for dd:
# 注释映射
# 127.0.0.1 localhost
# 127.0.1.1 master
192.168.118.129 master
192.168.118.130 slave1
192.168.118.131 slave2
# 关闭保存
:wq
7.实验总结
7.1 HDFS优点总结
- 支持任意超大文件存储;硬件节点可不断扩展,低成本存储(真实案例为:4000节点,目前最大5000节点);
- 对上层应用屏蔽分布式部署结构,提供统一的文件系统访问接口,感觉就是一个大硬盘;应用无需知道文件具体存放位置,使用简单;
- 文件分块存储(1块缺省64MB),不同块可分布在不同机器节点上,通过元数据记录文件块位置;应用顺序读取各个块;
- 系统设计为高容错性,允许廉价PC故障;每块文件数据在不同机器节点上保存3份;这种备份的另一个好处是可方便不同应用就近读取,提高访问效率。
7.2 HDFS缺点总结
- 适合大数据文件保存和分析,不适合小文件,由于分布存储需要从不同节点读取数据,效率反而没有集中存储高;一次写入多次读取,不支持文件修改;
- 是最基础的大数据技术,基于文件系统层面提供文件访问能力,不如数据库技术强大,但也是海量数据库技术的底层依托;
- 文件系统接口完全不同于传统文件系统,应用需要重新开发。
7.3 实验总结
通过本次实验,简单掌握了Hadoop整体的搭建过程,由于笔记本电脑性能不足,搭建三台虚拟机导致电脑数次崩溃,网页查看时多次出错。在Hadoop完全分布式的安装配置过程中,遇到许许多多的问题,安装jdk,配置环境变量,安装ssh等等。同时在本次实验中认识到了自己的不足,在以后的学习中需要进一步努力。实验考验是一个人的耐心,实验步骤要一步一步地做,每一步都要严谨认真。今后会加强对Linux系统知识的掌握,力求手到擒来。