纵向联邦线性回归实现-Federated Machine Learning Concept and Applications论文复现
本实验的算法实现思路来自这篇论文Federated Machine Learning Concept and Applications
文章目录
- 场景介绍
- 同态加密算法
-
- python的phe库实现了加法同态加密
-
- 角色1
- 角色2
- 传统的线性回归
- 纵向联邦线性回归
- 纵向联邦线性回归代码实现
-
- 导入工具包
- 准备数据
- 使用普通线性回归训练
-
- 搭建训练过程
- 纵向联邦线性回归实现
-
- 垂直切分数据集
- 客户端父类实现
- 客户端A类实现
- 客户端B类实现
- 调度发C类实现
- 搭建训练过程
- 训练流程实现
- 预测
场景介绍
现有同一个城市的两家公司A和B,A公司和B公司的业务范围不同,但所服务的业务对象大多都是该城市的人,所以A公司和B公司所持与的数据,样本ID重叠较多,样本特征重叠较少(因为业务逻辑不同)。而且B公司拥有标签y,A公司没有,所以A公司是无法单边建模的。B公司虽然可以单边建模,但由于样本特征数较少,建模效果不理想。现在出现了一种纵向联邦建模的技术,可以在保护参与方数据隐私的前提下进行联合学习,A和B这种情况的联邦学习属于纵向联邦学习。
同态加密算法
同态加密(英语:Homomorphic encryption)是一种加密形式,它允许人们对密文进行特定形式的代数运算得到仍然是加密的结果,将其解密所得到的结果与对明文进行同样的运算结果一样。分为半同态加密和全同态加密。
联邦学习通常采用半同态加密中的加法同态加密,即加密后加法和数乘的结果,与加密前一样
u + v = [ [ u ] ] + [ [ v ] ] k ∗ u = k ∗ [ [ u ] ] \begin{array}{l} u + v = [[u]] + [[v]]\\ k*u = k*[[u]] \end{array} u+v=[[u]]+[[v]]k∗u=k∗[[u]]
python的phe库实现了加法同态加密
使用以下命令进行安装
pip install phe
主要有两个角色,角色1:控制私钥和公钥。角色2:没有私钥,只有公钥。使用以下命令导入paillier包
from phe import paillier
角色1
生成公钥和私钥
public_key, private_key = paillier.generate_paillier_keypair()
有了公钥之后,可以对数字进行加密
secret_number_list = [3.141592653, 300, -4.6e-12]
encrypted_number_list = [public_key.encrypt(x) for x in secret_number_list]
encrypted_number = public_key.encrypt(3)
解密需要通过私钥
[keyring.decrypt(x) for x in encrypted_number_list]
>>>[3.141592653, 300, -4.6e-12]
角色2
角色2没有私钥,通常接受加密后的数字,然后与自己的未加密的数据进行运算,然后发送给角色1进行解密。可以通过一下两种方式实现:
1.显式的将加密数字的公钥取出,然后对自己的数据加密,进行运算
# 取出公钥
public_key = encrypted_number.public_key
# 对本地未加密的数据用公钥加密,然后将加密后的数据相加,发送给角色1进行解密
local_number = 10
encrypted_local_number = public_key.encrypt(local_number)
encrypted_sum = encrypted_local_number + encrypted_number
2.将为加密的数据与加密数据直接运算,phe库会帮你隐式的进行转换,这种运算支持以下三种方式
- 加密数字与标量相加
- 加密数字与加密数字相加
- 加密数字与标量相乘
a, b, c = encrypted_number_list
a_plus_5 = a + 5
a_plus_b = a + b
a_times_3_5 = a * 3.5
Numpy的array操作也支持,矩阵乘向量,向量加法等
import numpy as np
nc_mean = np.mean(encrypted_number_list)
enc_dot = np.dot(encrypted_number_list, [2, -400.1, 5318008])
传统的线性回归
传统的机器学习,若要联合多方进行建模,需要把数据合并到数据中心,然后再训练模型。设X为A和B合并后的数据, θ \theta θ为模型的参数,y为数据的标签。损失函数如下所示:
L = 1 2 n ∑ i = 1 n ( θ T x i + b − y i ) 2 + λ 2 ∣ ∣ θ ∣ ∣ 2 {\rm{L = }}\frac{1}{2n}\sum\limits_{i = 1}^n {{{({\theta ^T}{x_i} + b - {y_i})}^2} +\frac{ \lambda}{2} } ||\theta |{|^2} L=2n1i=1∑n(θTxi+b−yi)2+2λ∣∣θ∣∣2
损失函数对 θ \theta θ的梯度为:
∂ L ∂ θ = 1 n ∑ i = 1 n ( θ T x i + b − y i ) x i + λ θ \frac{{\partial {\rm{L}}}}{{\partial \theta }} = \frac{1}{n}\sum\limits_{i = 1}^n {({\theta ^T}{x_i} + b - {y_i}){x_i} + \lambda } \theta ∂θ∂L=n1i=1∑n(θTxi+b−yi)xi+λθ
最后采用梯度下降法,对参数进行更新
θ t + 1 = θ t − η ∂ L ∂ θ {\theta ^{t + 1}} = {\theta ^t} - \eta \frac{{\partial {\rm{L}}}}{{\partial \theta }} θt+1=θt−η∂θ∂L
纵向联邦线性回归
由于上述方法需要将数据移动到数据中心,对参与方的数据隐私造成了破坏,联邦学习的思想就是在不动参与发的数据的前提下将模型训练出来。对上面损失函数进行调整,令
θ T = ( θ A T θ B T ) x i = ( x i A , x i B ) \begin{array}{l} {\theta ^T} = \left( \begin{array}{l} \theta _A^T\\ \theta _B^T \end{array} \right)\\ \\ {x_i} = (x_i^{\rm{A}},x_i^B) \end{array} θT=(θATθBT)xi=(xiA,xiB)
x i A x_i^{\rm{A}} xiA和 x i B x_i^{\rm{B}} xiB分别表示A公司、B公司的本地数据, θ A T \theta _A^T θAT, θ B T \theta _B^T θBT分别表示A、B公司训练的本地模型
则目标函数变成:
L = 1 2 n ∑ i = 1 n ( θ A T x i A + θ B T x i B + b − y i ) 2 + λ 2 ( ∣ ∣ θ A T ∣ ∣ 2 + ∣ ∣ θ B T ∣ ∣ 2 ) {\rm{L = }}\frac{1}{{2n}}\sum\limits_{i = 1}^n {{{(\theta _A^Tx_i^{\rm{A}} + \theta _B^Tx_i^B + b - {y_i})}^2} + \frac{\lambda }{2}} (||\theta _A^T|{|^2} + ||\theta _B^T|{|^2}) L=2n1i=1∑n(θATxiA+θBTxiB+b−yi)2+2λ(∣∣θAT∣∣2+∣∣θBT∣∣2)
可以进一步简化 ,令
θ B T = ( θ B T b ) x i B = ( x i B , 1 ) \begin{array}{l} \theta _B^T = \left( \begin{array}{l} \theta _B^T\\ b \end{array} \right)\\ \\ x_i^B = (x_i^B,1) \end{array} θBT=(θBTb)xiB=(xiB,1)
将b合并到 θ B T \theta _B^T θBT中
损失函数变成:
L = 1 2 n ∑ i = 1 n ( θ A T x i A + θ B T x i B − y i ) 2 + λ 2 ( ∣ ∣ θ A T ∣ ∣ 2 + ∣ ∣ θ B T ∣ ∣ 2 ) {\rm{L = }}\frac{1}{{2n}}\sum\limits_{i = 1}^n {{{(\theta _A^Tx_i^{\rm{A}} + \theta _B^Tx_i^B - {y_i})}^2} + \frac{\lambda }{2}} (||\theta _A^T|{|^2} + ||\theta _B^T|{|^2}) L=2n1i=1∑n(θATxiA+θBTxiB−yi)2+2λ(∣∣θAT∣∣2+∣∣θBT∣∣2)
令
u i A = θ A T x i A u i B = θ B T x i B \begin{array}{l} u_i^A = \theta _A^Tx_i^{\rm{A}}\\ u_i^B = \theta _B^Tx_i^B \end{array} uiA=θATxiAuiB=θBTxiB
则加密后的损失函数为
[ [ L ] ] = [ [ 1 2 n ∑ i = 1 n ( u i A + u i B − y i ) 2 + λ 2 ( ∣ ∣ θ A T ∣ ∣ 2 + ∣ ∣ θ B T ∣ ∣ 2 ) ] ] {\rm{[[L]] = [[}}\frac{1}{{2n}}\sum\limits_{i = 1}^n {{{(u_i^A + u_i^B - {y_i})}^2} + \frac{\lambda }{2}} (||\theta _A^T|{|^2} + ||\theta _B^T|{|^2})]] [[L]]=[[2n1i=1∑n(uiA+uiB−yi)2+2λ(∣∣θAT∣∣2+∣∣θBT∣∣2)]]
令
[ [ L A ] ] = [ [ 1 2 ∑ i = 1 n ( u i A ) 2 + λ 2 ∣ ∣ θ A T ∣ ∣ 2 ] ] [ [ L B ] ] = [ [ 1 2 ∑ i = 1 n ( u i B − y i ) 2 + λ 2 ∣ ∣ θ B T ∣ ∣ 2 ] ] [ [ L A B ] ] = [ [ ∑ i = 1 n u i A ( u i B − y i ) ] ] \begin{array}{l} [[{L_A}]] = {\rm{[[}}\frac{1}{2}\sum\limits_{i = 1}^n {{{(u_i^A)}^2} + \frac{\lambda }{2}} ||\theta _A^T|{|^2}]]\\ \\ [[{L_B}]] = {\rm{[[}}\frac{1}{2}\sum\limits_{i = 1}^n {{{(u_i^B - {y_i})}^2} + \frac{\lambda }{2}} ||\theta _B^T|{|^2}]]\\ \\ [[{L_{AB}}]] = {\rm{[[}}\sum\limits_{i = 1}^n {u_i^A(u_i^B - {y_i})} ]] \end{array} [[LA]]=[[21i=1∑n(uiA)2+2λ∣∣θAT∣∣2]][[LB]]=[[21i=1∑n(uiB−yi)2+2λ∣∣θBT∣∣2]][[LAB]]=[[i=1∑nuiA(uiB−yi)]]
则
[ [ L ] ] = 1 n ( [ [ L A ] ] + [ [ L B ] ] + [ [ L A B ] ] ) [[L]] = \frac{1}{n}([[{L_A}]] + [[{L_B}]] + [[{L_{AB}}]]) [[L]]=n1([[LA]]+[[LB]]+[[LAB]])
令
[ [ d i ] ] = [ [ u i A ] ] + [ [ u i B − y i ] ] [[{d_i}]] = [[u_i^A]] + [[u_i^B - {y_i}]] [[di]]=[[uiA]]+[[uiB−yi]]
则损失函数对 θ A T \theta _A^T θAT, θ B T \theta _B^T θBT的梯度分别为:
[ [ ∂ L ∂ θ A ] ] = ∑ i [ [ d i ] ] x i A + [ [ λ θ A ] ] [ [ ∂ L ∂ θ B ] ] = ∑ i [ [ d i ] ] x i B + [ [ λ θ B ] ] \begin{array}{l} [[\frac{{\partial L}}{{\partial {\theta _A}}}]] = \sum\limits_i {[[{d_i}]]x_i^{\rm{A}} + [[\lambda {\theta _A}]]} \\ \\ [[\frac{{\partial L}}{{\partial {\theta _B}}}]] = \sum\limits_i {[[{d_i}]]x_i^B + [[\lambda {\theta _B}]]} \end{array} [[∂θA∂L]]=i∑[[di]]xiA+[[λθA]][[∂θB∂L]]=i∑[[di]]xiB+[[λθB]]
因为涉及到解密,所以私钥存放在调度方C,A和B都没有私钥进行解密,所以在交换中间结果是不会泄露隐私,发给C的加密梯度可以用一个随机数进行掩码,这个随机数只有A和B自己知道,所以梯度也不会直接暴露给C
训练过程整个算法流程如图所示

纵向联邦线性回归代码实现
导入工具包
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Ridge
import numpy as np
from sklearn.metrics import r2_score
from VFL_LinearRegression import *
from sklearn.metrics import mean_squared_error
from phe import paillier
准备数据
使用sklearn自带糖尿病数据集
dataset = load_diabetes()
X,y = dataset.data,dataset.target
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3)
# 堆叠一列1,把偏置合并到w中
X_train = np.column_stack((X_train,np.ones(len(X_train))))
X_test = np.column_stack((X_test,np.ones(len(X_test))))
# 打印数据形状
for temp in [X_train, X_test, y_train, y_test]:
print(temp.shape)
>>>
(309, 11)
(133, 11)
(309,)
(133,)
使用普通线性回归训练
先不切分数据,用传统的线性回归训练一遍,相当于把数据集中到数据中心,记录损失
训练参数配置
config = {
'lambda':0.4, #正则项系数
'lr':1e-2, # 学习率
'n_iters':10, # 训练轮数
}
搭建训练过程
weights = np.zeros(X_train.shape[1])
loss_history = []
for i in range(config['n_iters']):
L = 0.5 * np.sum(np.square(X_train.dot(weights) - y_train)) + 0.5 * config['lambda'] * np.sum(np.square(weights))
dL_w = X_train.T.dot(X_train.dot(weights) - y_train) + config['lambda'] * weights
weights = weights - config['lr'] * dL_w / len(X_train)
loss_history.append(L)
print('*'*8,L,'*'*8)
print('weights:{}'.format(weights))
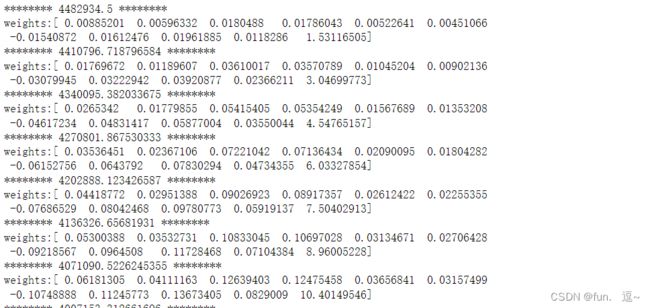
纵向联邦线性回归实现
垂直切分数据集
A获得X_train的前6个特征
B获得X_train剩下的特征和训练标签y
idx_A = list(range(6))
idx_B = list(range(6,11))
XA_train,XB_train = X_train[:,idx_A], X_train[:,idx_B]
XA_test,XB_test = X_test[:,idx_A], X_test[:,idx_B]
# 打印形状
for name,temp in zip(['XA_train','XB_train','XA_test','XB_test'],[XA_train,XB_train,XA_test,XB_test]):
print(name,temp.shape)
客户端父类实现
定义所以客户端的父类,具有共同的行为
class Client(object):
def __init__(self,config):
# 模型训练过程中产生的所有数据
self.data = {}
self.config = config
self.other_clinet = {}
def send_data(self,data,target_client):
target_client.data.update(data)
客户端A类实现
class ClientA(Client):
def __init__(self,X,config):
super().__init__(config)
self.X = X
# 初始化参数
self.weights = np.zeros(self.X.shape[1])
# 计算u_a
def compute_u_a(self):
u_a = self.X.dot(self.weights)
return u_a
# 计算加密梯度
def compute_encrypted_dL_a(self,encrypted_d):
encrypted_dL_a = self.X.T.dot(encrypted_d) + self.config['lambda'] * self.weights
return encrypted_dL_a
# 做predict
def predict(self,X_test):
u_a = X_test.dot(self.weights)
return u_a
# 计算[[u_a]],[[L_a]]发送给B方
def task_1(self,client_B_name):
dt = self.data
# 获取公钥
assert 'public_key' in dt.keys(),"Error: 'public_key' from C in step 1 not receive successfully"
public_key = dt['public_key']
u_a = self.compute_u_a()
encrypted_u_a = np.array([public_key.encrypt(x) for x in u_a])
u_a_square = u_a ** 2
L_a = 0.5*np.sum(u_a_square) + 0.5 * self.config['lambda'] * np.sum(self.weights**2)
encrypted_L_a = public_key.encrypt(L_a)
data_to_B = {'encrypted_u_a':encrypted_u_a,'encrypted_L_a':encrypted_L_a}
self.send_data(data_to_B,self.other_clinet[client_B_name])
# 计算加密梯度[[dL_a]],加上随机数之后,发送给C
def task_2(self,client_C_name):
dt = self.data
assert 'encrypted_d' in dt.keys(),"Error: 'encrypted_d' from B in step 1 not receive successfully"
encrypted_d = dt['encrypted_d']
encrypted_dL_a = self.compute_encrypted_dL_a(encrypted_d)
mask = np.random.rand(len(encrypted_dL_a))
encrypted_masked_dL_a = encrypted_dL_a + mask
self.data.update({'mask':mask})
data_to_C = {'encrypted_masked_dL_a':encrypted_masked_dL_a}
self.send_data(data_to_C,self.other_clinet[client_C_name])
# 获取解密后的masked梯度,减去mask,梯度下降更新
def task_3(self):
dt = self.data
assert 'mask' in dt.keys(),"Error: 'mask' form A in step 2 not receive successfully"
assert 'masked_dL_a' in dt.keys(), "Error: 'masked_dL_a' from C in step 1 not receive successfully"
mask = dt['mask']
masked_dL_a = dt['masked_dL_a']
dL_a = masked_dL_a - mask
# 注意这里的1/n
self.weights = self.weights - self.config['lr'] * dL_a / len(self.X)
print("A weights : {}".format(self.weights))
客户端B类实现
class ClientB(Client):
def __init__(self,X,y,config):
super().__init__(config)
self.X = X
self.y = y
self.weights = np.zeros(self.X.shape[1])
# 计算u_b
def compute_u_b(self):
u_b = self.X.dot(self.weights)
return u_b
# 计算加密梯度
def compute_encrypted_dL_b(self,encrypted_d):
encrypted_dL_b = self.X.T.dot(encrypted_d) + self.config['lambda'] * self.weights
return encrypted_dL_b
# 做predict
def predict(self,X_test):
u_b = X_test.dot(self.weights)
return u_b
# 计算[[d]] 发送给A方;计算[[L]],发送给C方
def task_1(self,client_A_name,client_C_name):
dt = self.data
assert 'encrypted_u_a' in dt.keys(),"Error: 'encrypted_u_a' from A in step 1 not receive successfully"
encrypted_u_a = dt['encrypted_u_a']
u_b = self.compute_u_b()
z_b = u_b - self.y
z_b_square = z_b**2
encrypted_d = encrypted_u_a + z_b
data_to_A = {'encrypted_d':encrypted_d}
self.data.update({'encrypted_d':encrypted_d})
assert 'encrypted_L_a' in dt.keys(),"Error,'encrypted_L_a' from A in step 1 not receive successfully"
encrypted_L_a = dt['encrypted_L_a']
L_b = 0.5 * np.sum(z_b_square) + 0.5 * self.config['lambda'] * np.sum(self.weights**2)
L_ab = np.sum(encrypted_u_a * z_b)
encrypted_L = encrypted_L_a + L_b + L_ab
data_to_C = {'encrypted_L':encrypted_L}
self.send_data(data_to_A,self.other_clinet[client_A_name])
self.send_data(data_to_C, self.other_clinet[client_C_name])
# 计算加密梯度[[dL_b]],mask之后发给C方
def task_2(self,client_C_name):
dt = self.data
assert 'encrypted_d' in dt.keys(),"Error: 'encrypted_d' from B in step 1 not receive successfully"
encrypted_d = dt['encrypted_d']
encrypted_dL_b = self.compute_encrypted_dL_b(encrypted_d)
mask = np.random.rand(len(encrypted_dL_b))
encrypted_masked_dL_b = encrypted_dL_b + mask
self.data.update({'mask':mask})
data_to_C = {'encrypted_masked_dL_b':encrypted_masked_dL_b}
self.send_data(data_to_C,self.other_clinet[client_C_name])
# 获取解密后的梯度,解mask,模型更新
def task_3(self):
dt = self.data
assert 'mask' in dt.keys(), "Error: 'mask' form B in step 2 not receive successfully"
assert 'masked_dL_b' in dt.keys(), "Error: 'masked_dL_b' from C in step 1 not receive successfully"
mask = dt['mask']
masked_dL_b = dt['masked_dL_b']
dL_b = masked_dL_b - mask
self.weights = self.weights - self.config['lr'] * dL_b / len(self.X)
print("B weights : {}".format(self.weights))
调度发C类实现
class ClientC(Client):
def __init__(self,config):
super().__init__(config)
self.loss_history = []
self.public_key = None
self.private_key = None
# 产生钥匙对,将公钥发送给A,B方
def task_1(self,client_A_name,client_B_name):
self.public_key,self.private_key = paillier.generate_paillier_keypair()
data_to_AB = {'public_key':self.public_key}
self.send_data(data_to_AB,self.other_clinet[client_A_name])
self.send_data(data_to_AB, self.other_clinet[client_B_name])
# 解密[[L]]、[[masked_dL_a]],[[masked_dL_b]],分别发送给A、B
def task_2(self,client_A_name,client_B_name):
dt = self.data
assert 'encrypted_L' in dt.keys(),"Error: 'encrypted_L' from B in step 2 not receive successfully"
assert 'encrypted_masked_dL_b' in dt.keys(), "Error: 'encrypted_masked_dL_b' from B in step 2 not receive successfully"
assert 'encrypted_masked_dL_a' in dt.keys(), "Error: 'encrypted_masked_dL_a' from A in step 2 not receive successfully"
encrypted_L = dt['encrypted_L']
encrypted_masked_dL_b = dt['encrypted_masked_dL_b']
encrypted_masked_dL_a = dt['encrypted_masked_dL_a']
L = self.private_key.decrypt(encrypted_L)
print('*'*8,L,'*'*8)
self.loss_history.append(L)
masked_dL_b = np.array([self.private_key.decrypt(x) for x in encrypted_masked_dL_b])
masked_dL_a = np.array([self.private_key.decrypt(x) for x in encrypted_masked_dL_a])
data_to_A = {'masked_dL_a':masked_dL_a}
data_to_B = {'masked_dL_b':masked_dL_b}
self.send_data(data_to_A, self.other_clinet[client_A_name])
self.send_data(data_to_B, self.other_clinet[client_B_name])
搭建训练过程
初始化客户端对象
clientA = ClientA(XA_train,config)
clientB = ClientB(XB_train,y_train,config)
clientC = ClientC(config)
建立连接
for client1 in [clientA,clientB,clientC]:
for name,client2 in zip(['A','B','C'],[clientA,clientB,clientC]):
if client1 is not client2:
client1.other_clinet[name] = client2
# 打印连接
for client1 in [clientA,clientB,clientC]:
print(client1.other_clinet)
>>>
{'B': <VFL_LinearRegression.ClientB object at 0x7ffae4ed6a90>, 'C': <VFL_LinearRegression.ClientC object at 0x7ffae52737f0>}
{'A': <VFL_LinearRegression.ClientA object at 0x7ffae52730a0>, 'C': <VFL_LinearRegression.ClientC object at 0x7ffae52737f0>}
{'A': <VFL_LinearRegression.ClientA object at 0x7ffae52730a0>, 'B': <VFL_LinearRegression.ClientB object at 0x7ffae4ed6a90>}
训练流程实现
一
- 初始化A的参数weights,初始化B的参数weights,C创建公钥和私钥,并将公钥发送给A,B
二
- A方计算[[u_a]] , [[L_a]]发送给B方
- B方计算[[d]]发送给A, 计算[[L]]发给C
三
- A方计算[[dL_a]],将[[masked_dL_a]] 发送给C
- B方计算[[dL_b]],将[[maksed_dL_b]]发送给C
- C方解密[[L]],[[masked_dL_a]]解密发送给A,[[maksed_dL_b]]发送给B
for i in range(config['n_iters']):
# 1.C创建钥匙对,分发公钥给A和B
clientC.task_1('A','B')
# 2.1 A方计算[[u_a]] , [[L_a]]发送给B方
clientA.task_1('B')
# 2.2 B方计算[[d]]发送给A, 计算[[L]]发给C
clientB.task_1('A','C')
# 3.1 A方计算[[dL_a]],将[[masked_dL_a]] 发送给C
clientA.task_2('C')
# 3.2 B方计算[[dL_b]],将[[maksed_dL_b]]发送给C
clientB.task_2('C')
# 3.3 解密[[L]],[[masked_dL_a]]解密发送给A,[[maksed_dL_b]]发送给B
clientC.task_2('A','B')
# 4.1 A、B方更新模型
clientA.task_3()
clientB.task_3()
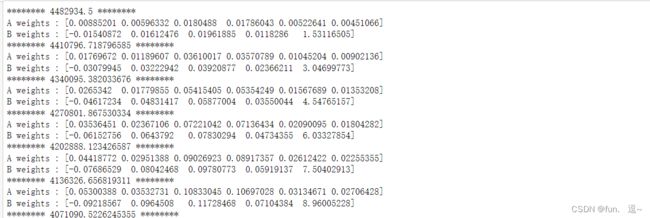
比较两种方法的损失
np.array(loss_history) - np.array(clientC.loss_history)
>>>
array([ 0.00000000e+00, -9.31322575e-10, -9.31322575e-10, -9.31322575e-10,
0.00000000e+00, -9.31322575e-10, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 4.65661287e-10])
可以看的误差非常小,所以损失是无损的
预测
根据论文的表述,在预测过程,需要A和B联合预测
y_pred = XA_test.dot(clientA.weights) + XB_test.dot(clientB.weights)
打印均方误差
mean_squared_error(y_test,y_pred)
>>>
25033.750801867864