论文阅读:How to Put Users in Control of their Data in Federated TopN Recommendation with Learning toRank

Author:Vito Walter Anelli, Yashar Deldjoo, Tommaso Di Noia, Antonio Ferrara, Fedelucio Narducci∗
论文地址
Motivation:
推荐服务被大量应用在一些以用户为中心的应用程序中,它缓解信息过载和帮助用户在大量可能性中做出选择。数据所有权是一个关键问题,**因为用户可能不愿意与中央服务器共享他们的敏感偏好。**但是现存的推荐模型都是以数据获得和收集为基础的。
为了处理这个问题,提出了FPL(short for Federated Pair-wise Learning),这是一个用户协作训练中心分解模型,同时可以控制从其设备传出的敏感数据量。
提出的方法通过遵循联邦学习原则来实现成对学习到排序的优化,该原则最初的构想是为了减轻传统机器学习的隐私风险。
本论文基于成对排序推荐算法BPRMF讨论。
Contribute:
1.提出了FPL,是一个在协同推荐的联邦因子分解模型。FPL拓展了最先进的因子分解方法去建立一个推荐系统,它使用户能够控制其敏感数据。FPL主要利用非敏感数据(e.g.用户未访问过的位置)达到具有竞争力的准确性,同时在准确性和隐私性之间达到了一个满意的平衡。
2.在POI领域做了大量实验,验证提出的FPL的推荐准确性和多样性。实验表明,FPL可以提供高质量的推荐性能同时可以让用户控制要共享的敏感数据量。
Method:
遵循联邦学习原则。中心服务器Server协调Clients(用户的集合)。
Server知道所有物品集合,每个Clients(用户)仅知道他自己交互的物品。
建立模型
Server:![]() Q是物品表征矩阵,b是物品偏差
Q是物品表征矩阵,b是物品偏差
Clients:![]()
![]() P是用户表征矩阵
P是用户表征矩阵
核心思想
BPRMF使得正物品交互得分高于负物品交互得分。FPL思想是CLients(用户)上传Server所有交互的负物品梯度以及 π概率的交互正物品的梯度。π就是一个可控的用户上传敏感信息的概率值。
(1) Distribution:Server随机挑选一个用户子集并且传递给它们参数θs。
(2) Computation:每个用户u从数据集Ku生成T个triples(u,i,j),训练BPRMF更新pu,qi,bi,qj,bj。
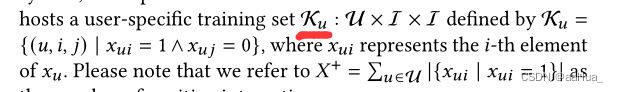
(3) Transmission:step(2)在每个clients计算得到的梯度,需要发回Server来部分更新的梯度(ΔΘs,u)。在这里clients仅发回物品的梯度,用户的梯度不传递。物品的梯度全部传回的只有负物品的交互梯度,并引入参数π可控的传回正物品的交互梯度。
仅全部传回负物品交互梯度理由:因为BPRMF做的是成对排序,全部回传正物品和负物品的梯度会使Server重构Ku(例如,通过分析Δbi和Δbj的正负号),因此会泄露隐私。
(4) Global aggregation:Server聚合接收到的梯度去更新Q(物品表征矩阵)和b(物品偏差)。
Dataset:


the Foursquare dataset:为了模拟单个国家的设备联合,提取了三个国家(即巴西、加拿大和意大利)的签入,以获得具有不同大小/稀疏性特征的数据集。
Baselines:
Random、Top-Pop、VAE 、BPR-MF、FCF、sFPL(每轮仅随机选择1个client训练并且T=1)、pFPL(每轮选择全部client训练并且T=1)
Eeperiments

实验的目标是评估是否可以和一个集中式成对学习方法做性能对比同时允许用户去控制他们的数据。
关注accuracy指标:VAE在三个数据集中效果都是最优的(However,who is familiar with VAE knows that, since it restricts training data by applying k-core, it does not always produce recommendations for all the users.?这句话说VAE是啥意思我不太明白,有懂得大牛指点一下 )。重点关注BPRMF和FPL。sFPL优于BPRMF(P@10、R@10)并且有相似的多样性值(IC@10、G@10)(多样性这里我觉得差别挺大的,为啥作者说相似? )。
FPL也优于FCF,同时也保护了隐私,FCF共享所有rating的物品梯度。

对于三个数据集的调和平均(harmonic mean)结果如上图。发现最好的结果可能与π=1(全部回传正负物品梯度)不相关。
sFPL与pFPl(并行,每轮全部用户)相比,提出的模型可以和集中式成对学习方法(BPRMF)有相当的推荐性能,同时增加并行性不会显著影响结果。
对比π [0.1,…,1.0]:最好的性能很少与π=1相关。相反,模型训练(π [0.1,…,1.0])达到峰值后,随着π增加,模型性能会衰减。但是在很少的案例中如在Brazil数据集中,不同的π值结果很相近。
一般的行为表明模型学习利用正物品去获取有关受欢迎程度的信息(This consideration is coherent with the mathematical formulation of the learning procedure, and it is also supported by the observation that for Canada and Italy FPL reaches the peak before with respect to Brazil.这句话怎么理解? )。
成对学习特点:越dense的数据集,增加正物品的数量会导致流行项目增加过多。