双重差分法之PSM - DID
这次推文的内容主要是介绍选择偏差及其导致的内生性问题,以及缓解这种内生性问题的倾向得分匹配法(Propensity Score Matching,PSM),并且用一实例介绍一下如何将PSM与DID结合,即PSM - DID在Stata中的具体操作。
(本文首发于个人微信公众号DMETP,欢迎关注!)
注:推文中的公式与代码块均可左右滑动;需要本次推送所使用的数据和代码的朋友,可以在公众号后台回复关键词psmdid~
文章目录
-
- 一、选择偏差与内生性
-
- 1.1 结论可信吗?
- 1.2 样本选择性偏差与自选择偏差
- 1.3 随机分组与依可测变量选择
- 1.4 倾向得分匹配
- 1.5 PSM + DID
- 二、PSM - DID的实现
-
- 2.1 数据初步处理
- 2.2 截面PSM - DID
- 2.3 逐年PSM - DID
一、选择偏差与内生性
1.1 结论可信吗?
先举两个例子。
-
例1:进行一项调查,调查内容是去不去医院是否会影响个人健康,因此向医院里的各类人员发放问卷并得出其健康状况,最后发现去医院不利于个人健康。
-
例2:评估一项污染防治政策的政策效果,选择期初污染程度基本一致的地区作为样本,并根据各地区意愿决定其是否实施该项政策,3年后政策实施地的污染指标明显低于未实施该政策的地区,结论是这项政策有效。
以上问卷调查和政策评估的结论可信吗?
例1的问题很明显,去医院的大多是健康状况不佳的患者,因此从逻辑上来说正是人们健康状况不佳才选择去医院,而不是因为他们去了医院才导致健康状况不佳。为了得到更令人信服的结论,应该将调查人群(样本)扩大至所有场合,而不仅仅是医院。与之类似的案例还有,在健身房调查健身对脱发的影响等。
例2的问题不易看出,从DID的角度来看,“期初污染程度基本一致”说明平行趋势检验基本通过,因此直观上政策实施地(处理组)的污染指标(结果变量y)与未实施政策地区(控制组)的污染指标的差值就是政策的处理效应,差值为负(假设指标越小污染程度越低)说明政策有效。但是,还应该看到的是,“根据各地区意愿决定其是否实施该项政策”,也就是说各地区是否实施该项政策是自己选择的。实际上,某地是否实施政策更多基于地理区位、经济发展和产业结构等因素的考量。这也与现实情况吻合,政策一般都在先行示范区率先实施,而这些示范区经济发展水平都较高。
那为什么说例2的政策评估结论不可信呢?
从计量的角度分析,影响某地是否实施政策(即处理组虚拟变量du的取值)的因素也会影响该地区的污染指标(y),这些因素可以分为可观测因素与不可观测因素。
首先,可观测说明可度量,这些可观测变量与y相关,因此可以将其引入到我们的模型中,虽然可能与du存在共线性,但一定程度的共线性不是问题。问题是我们无法找出所有的可观测变量(或者可观测变量以非线性的形式影响结果变量),而这部分没有引入模型中的可观测变量(或者可观测变量的非线性形式)就被放到扰动项中,造成扰动项与du相关,即存在内生性,最后导致did项的估计系数存在偏误。
其次,不可观测说明不可度量,因此这部分不可观测因素必然就在扰动项中,同样会存在内生性问题,造成估计偏误。
1.2 样本选择性偏差与自选择偏差
例1和例2存在的问题本质上是不同的。
例1存在的问题是样本的选择不随机,即我们只获取了医院的样本,而没有随机调查其他场所。某些影响样本选择过程的因素也会影响到y,因此这些因素被放到扰动项中,造成选择过程与干扰项相关,存在内生性问题,这被称为样本选择性偏差(Sample Selection Bias)。然而,当我们重新审视样本选择性偏差导致内生性的逻辑时,可以发现所谓的“样本选择过程”并不是一个特定的变量,也没有放到我们的模型中,那为什么会导致解释变量与扰动项相关?Hansen在《ECONOMETRICS(V 2021)》第27章第9小节给出了推导,并且还介绍了一种流行的解决方法——Heckman两步法,下期推送将用一具体实例讲解Heckman两步法在Stata中如何操作。
例2存在的问题是变量的选择不随机,换言之,各地区对是否实施政策有着自己的“小九九”。du的取值不随机,而是和其他因素相关,而这些因素又被放到扰动项中,造成解释变量与干扰项相关,存在内生性问题,这被称为自选择偏差(Self-Selection Bias)。若是由可观测变量导致的自选择偏差,可以使用PSM方法予以解决,这也是本次推文的主要内容之一。
综合来看,样本选择性偏差和自选择偏差都属于选择偏差(Selection Bias),只是侧重的角度不同,一个侧重的是样本的选择不随机,一个侧重的是变量的选择不随机,但都表明一个观点:非随机化实验将导致内生性。那么问题来了,什么是“非随机化实验”?先从为什么需要随机化实验说起,最后引出PSM - DID。
1.3 随机分组与依可测变量选择
还是以一个例子来分析。
假设要评估一项实验的效果,也就是考察个体 A A A在接受试验( D i = 1 D_i=1 Di=1)后他的结果变量y的变化。最理想也是最不现实的一种评估方法是找出这个人在平行时空中的个体 A ′ A' A′,并让 A ′ A' A′不接受实验( D i = 0 D_i=0 Di=0),相同的一段时间后分别得到结果变量并将其作差,这个差值就是此次实验的参与者平均处理效应(Average Treatment Effect on the Treated,ATT),也就是我们要考察的实验效果。用公式来表达就是:
A T T = E ( y 1 i ∣ D i = 1 ) − E ( y 0 i ∣ D i = 1 ) (1) ATT=E(y_{1i}~|~D_i=1)-E(y_{0i}~|~D_i=1) \tag{1} ATT=E(y1i ∣ Di=1)−E(y0i ∣ Di=1)(1)
其中, y i = { y 1 i , i f D i = 1 y 0 i , i f D i = 0 y_i=\begin{cases}y_{1i}~,~if~D_i=1\\y_{0i}~,~if~D_i=0\\\end{cases} yi={y1i , if Di=1y0i , if Di=0。
但是,平行时空中的个体一般是无法找到的(至少现在不能~),现实中,我们更多的是用参与实验个体的结果变量 y 1 i y_{1i} y1i与未参与实验个体的结果变量 y 0 i y_{0i} y0i作差(即全部样本的平均处理效应,Average Treatment Effect,ATE),以ATE来代替ATT,如下式(2):
A T E = E ( y 1 i ∣ D i = 1 ) − E ( y 0 i ∣ D i = 0 ) = E ( y 1 i ∣ D i = 1 ) − E ( y 0 i ∣ D i = 1 ) ⏟ ATT + E ( y 0 i ∣ D i = 1 ) − E ( y 0 i ∣ D i = 0 ) ⏟ 选择偏差 (2) ATE=E(y_{1i}~|~D_i=1)-E(y_{0i}~|~D_i=0)=\underbrace{E(y_{1i}~|~D_i=1)-E(y_{0i}~|~D_i=1)}_{\text{ATT}}+\underbrace{E(y_{0i}~|~D_i=1)-E(y_{0i}~|~D_i=0)}_{\text{选择偏差}} \tag{2} ATE=E(y1i ∣ Di=1)−E(y0i ∣ Di=0)=ATT E(y1i ∣ Di=1)−E(y0i ∣ Di=1)+选择偏差 E(y0i ∣ Di=1)−E(y0i ∣ Di=0)(2)
然而,正如式(2)所示,第二个等号右边可以分解为两个部分,第一部分是我们需要的ATT,第二部分是选择偏差。也就是说,当我们将处理组的 y 1 i y_{1i} y1i与控制组的 y 0 i y_{0i} y0i直接作差时,这个差值并不能代表纯粹的政策处理效应,即 A T E ≠ A T T ATE\not=ATT ATE=ATT(即便平行趋势检验通过)。
而为了使 A T E = A T T ATE=ATT ATE=ATT,其中一个思路就是消掉选择偏差这一部分,怎么消除?假设条件期望等于无条件期望;怎么实现条件期望等于无条件期望?假设 y y y均值独立于 D D D;怎么实现 y y y均值独立于 D D D?随机分组。
也就是说,如果处理组的选择是随机的,就能实现处理组虚拟变量与结果变量均值独立,从而推出 A T E = A T T ATE=ATT ATE=ATT。换言之,只要处理组的选择是随机的,两组间的 y y y之差就是我们需要的参与组平均处理效应ATT。
问题是,现实中处理组的选择是非随机的,即存在前文所说的自选择偏差,各个样本做出是否参与实验的决策是一种内生化的行为。那么,如果我们找到决定个体是否参与实验的因素,然后在控制组中匹配到这些因素与处理组相等的样本,最后将这些样本作为我们真正参与评估的控制组,这样是否就能说明处理组的选择是近似随机的呢?答案是可以的,Rosenbaum & Rubin(1983)给出了证明。
[2] Rosenbaum P R, Rubin D B. The Central Role of the Propensity Score in Observational Studies for Causal Effects[J]. Biometrika, 1983, 70(01): 41-55.
简单捋一下上文的逻辑,估计ATT最理想的方法是找到参与实验的个体在平行时空的自己,并假设平行时空的自己没有参与实验,最后作差得出最纯粹的ATT,但是找到平行时空的自己不现实;退而求其次,我们可以使用随机分组的处理组与控制组,作差得到ATT,但现实中个体是否参与实验的选择不随机;为了得到随机化分组的样本,找出影响个体是否参与实验的因素,控制两组间因素的取值相等,最后利用处理后的分组样本作差得到ATT。
其中,当决定个体是否参与实验的因素是可观测因素时,个体的决策就是依可观测变量选择;当决定个体是否参与实验的因素是不可观测因素时,个体的决策就是依不可观测变量选择。由于不可观测因素不可度量,而将控制组样本与处理组样本匹配时需要准确识别出这些因素,因此以下匹配方法都是基于可观测变量(协变量)来设计的。
1.4 倾向得分匹配
关于怎么匹配又是一个问题。
如果决定个体是否参与实验的可观测变量是一个单一协变量,那么我们只要在控制组中找到与处理组协变量取值相等的样本作为我们的被匹配对象。然而,决定个体决策的协变量并非单一,而是一个由多个协变量构成的多维向量 x i \pmb{x_i} xixixi,直接使用 x i \pmb{x_i} xixixi进行匹配可能遇到数据稀疏的问题。一种可行的思路是将多维向量进行降维,降维的方法解决数据稀疏问题的同时还保留了足够多的信息。实际使用中的方法主要有以下两种。
-
一是使用距离函数,如马氏距离。
-
二是倾向得分匹配PSM。
由于距离函数不是本文关注的重点,并且距离函数有其固有缺陷,因此这次不做赘述,详情参阅陈强(2014)《高级计量经济学及Stata应用(第二版)》第542页。
PSM主要有以下三个步骤。
-
选择协变量。实际应用中,多数论文直接将基础回归所使用的控制变量作为协变量,这种做法的基本逻辑在于要求协变量与 y y y相关,但问题在于这些控制变量不一定与处理组变量 D D D相关,即便相关,也可能是协变量的高次项或交互项与 D D D相关。更稳妥的做法是根据相关文献找出同时影响 y y y与 D D D的变量,但相关数据可能很难找到,因此直接使用控制变量作为协变量其实是一种妥协,但还是要仔细甄别每一个控制变量是否在理论上真正影响到 D D D,并且也要做协变量高次项或交互性的敏感性分析。
-
估计倾向得分值。 D D D作为被解释变量,协变量作为解释变量,由于 D D D是一个二元哑变量,因此使用
logit模型或probit模型,应用中更多使用logit模型。logit回归之后会得到各个样本的倾向得分值(在psmatch2中将生成_pscore变量,_pscore介于 [ 0 , 1 ] [0,1] [0,1]之间),之后就是根据_pscore进行第三步的匹配。 -
根据
_pscore进行匹配。最常用的是卡尺最近邻匹配,其他匹配方法参阅陈强(2014)《高级计量经济学及Stata应用(第二版)》第545页。卡尺最近邻匹配基于最近邻匹配,最近邻匹配需要设置邻居数(neighbor(#1)),也就是说根据倾向得分值最接近的原则,每一个处理组样本匹配到#1个处理组样本,但如果控制组样本的倾向得分值与处理组样本差距太大,这样的匹配是没有多大意义的,因此需要还设置一个卡尺(caliper(#2)),即控制一个阈值界限,界限内的控制组样本可以作为匹配对象,界限外的样本则被忽视。
1.5 PSM + DID
PSM和DID是天生绝配!
为何这么说?
因为现实中的政策本质上是一种非随机化实验(或称,准自然实验),因此政策效应评估所使用的DID方法难免存在自选择偏差,而使用PSM方法可以为每一个处理组样本匹配到特定的控制组样本,使得准自然实验近似随机,注意是近似,因为影响决策的不可观测因素在两组间仍然存在差异。
如,石大千等(2018)为了使实验组和控制组城市在各方面特征上尽可能地相似,消除选择偏差,选择PSM - DID方法以便更准确地评估智慧城市建设降低环境污染的效应。王雄元和卜落凡(2019)认为开通“中欧班列”的枢纽城市自身交通基础设施较好,且上市公司分布存在区域集聚现象,为了消除选择偏差采用PSM - DID方法进行稳健性检验。丁宁等(2020)考虑到绿色信贷和银行成本效率之间可能存在内生性,为了解决这个问题,采用了PSM - DID方法。郭晔和房芳(2021)为了缓解实验组和对照组企业之间的其他差异对研究结果的干扰,同样采用了PSM - DID方法。其他采用PSM - DID方法缓解因选择偏差导致的内生性问题的文献还有孙琳琳等(2020)、陆菁等(2021)和余东升等(2021)等。
[4] 石大千, 丁海, 卫平, 刘建江. 智慧城市建设能否降低环境污染[J]. 中国工业经济, 2018(06): 117-135.
[5] 王雄元, 卜落凡. 国际出口贸易与企业创新——基于“中欧班列”开通的准自然实验研究[J]. 中国工业经济, 2019(10): 80-98.
[6] 丁宁, 任亦侬, 左颖. 绿色信贷政策得不偿失还是得偿所愿?——基于资源配置视角的PSM-DID成本效率分析[J]. 金融研究, 2020(04): 112-130.
[7] 郭晔, 房芳. 新型货币政策担保品框架的绿色效应[J]. 金融研究, 2021(01): 91-110.
[8] 孙琳琳, 杨浩, 郑海涛. 土地确权对中国农户资本投资的影响——基于异质性农户模型的微观分析[J]. 经济研究, 2020, 55(11): 156-173.
[9] 陆菁, 鄢云, 王韬璇. 绿色信贷政策的微观效应研究——基于技术创新与资源再配置的视角[J]. 中国工业经济, 2021(01): 174-192.
[10] 余东升, 李小平, 李慧. “一带一路”倡议能否降低城市环境污染?——来自准自然实验的证据[J]. 统计研究, 2021, 38(06): 44-56.
然而,PSM - DID也并非是解决选择偏差的灵丹妙药,除了PSM本身不能控制因不可观测因素导致的组间差异,在与DID结合时还存在一个更为关键的问题。
从本质上来说,PSM适用于截面数据,而DID仅仅适用于时间 - 截面的面板数据。
-
对于PSM,每一个处理组样本匹配到的都是同一个时点的控制组样本,相应得到的
ATT仅仅是同一个时点上的ATT。下文psmatch2的输出结果中,ATT那一行结果就仅仅代表同一个时点上的参与者平均处理效应。 -
对于DID,由于同时从时间与截面两个维度进行差分,所以DID本身适用的条件就是面板数据。因此,由PSM匹配到的样本原本并不能直接用到DID中做回归。
面对两者适用数据类型的不同,现阶段的文献大致有两种解决思路。
-
第一,将面板数据视为截面数据再匹配。如上文参考文献中的绝大多数。
-
第二,逐期匹配。如,Heyman et al.(2007)、Bockerman & Ilmakunnas(2009)等。
[11] Heyman F, Sjoholm F, Tingvall P G. Is There Really a Foreign Ownership Wage Premium? Evidence from Matched Employer-Employee Data[J]. Journal of International Economics, 2007, 73(02): 355-376.
[12] Bockerman P, Ilmakunnas P. Unemployment and Self-Assessed Health: Evidence from Panel Data[J]. Health Economics, 2009, 18(02): 161-179.
然而,谢申祥等(2021)指出了这两种方法的不足。
-
第一,将面板数据转化为截面数据进行处理存在“自匹配”问题。
-
第二,逐期匹配将导致匹配对象在政策前后不一致。
[13] 谢申祥, 范鹏飞, 宛圆渊. 传统PSM-DID模型的改进与应用[J]. 统计研究, 2021, 38(02): 146-160.
虽然传统的研究思路存在一定程度的不足,但本次推送还是按照传统的设计思路介绍一下PSM - DID如何在Stata中实现。
具体来说,本次推送将使用李青原和章尹赛楠(2021)公布在《中国工业经济》官网的原始数据,首先,分别采用截面PSM与逐年PSM两种方法获得匹配样本,之后将匹配样本进行DID回归,并比较匹配后的回归结果与匹配前的基准回归结果,进而验证结论的稳健性。
[14] 李青原, 章尹赛楠. 金融开放与资源配置效率——来自外资银行进入中国的证据[J]. 中国工业经济, 2021(05): 95-113.
事实上,这篇文章也注意到了选择偏差的问题,但却是采用自助法(Bootstrapping)进行重复随机抽样(抽取500次,每次抽取1,000个样本),然后将抽取到的样本进行回归,最后重复随机抽样的结果与基准回归结果无实质性差异,从而证明了结论的稳健性。因此,本次推送将是从PSM的角度对基准回归结果进行复盘和二次验证。
二、PSM - DID的实现
2.1 数据初步处理
在PSM和DID之前先定义路径、设置图片输出格式(Stata自带的图片主题太丑~)、定义控制变量(协变量)和回归命令选择项的全局暂元以及生成处理组虚拟变量,然后保存好初步处理的原始数据。
其中,处理组虚拟变量原始数据集中是没有的,因为多期DID直接结合时间虚拟变量与分组虚拟变量构成did项(数据集中的变量名为FB)。由于官网放出的原始代码给出了三段政策时间节点,以及各个时点政策实施地区的城市代码或省份代码,我们根据这个信息可以生成处理组虚拟变量treated。
*- 定义路径
cd "C:\Users\KEMOSABE\Desktop\psm-did"
*- 设置图片输出样式
graph set window fontface "Times New Roman"
graph set window fontfacesans "宋体"
set scheme s1color
use 行业数据.dta, clear
*- 定义全局暂元
global xlist "ADM PPE ADV RD HHI INDSIZE NFIRMS FCFIRM MARGIN LEVDISP SIZEDISP ENTRYR EXITR"
global regopt "absorb(city ind3) cluster(city#ind3 city#year) keepsing"
*- 生成处理组虚拟变量
gen treated = ( city == 5101 | city == 5000 | city == 2102 | city == 3501 ///
| city == 4401 | city == 3701 | city == 3201 | city == 3702 ///
| city == 3101 | city == 4403 | city == 1200 | city == 4201 ///
| city == 4404 | prov == 44 | prov == 45 | prov == 43 ///
| prov == 32 | prov == 33 | city == 1100 | city == 5301 ///
| city == 2101 | city == 3502 | city == 6101 | city == 2201 ///
| city == 2301 | city == 6201 | city == 6401 )
save psmdata.dta, replace
2.2 截面PSM - DID
由于psmatch2为外部命令,因此第一次使用该命令时需要键入如下代码进行安装。
ssc install psmatch2, replace
在使用psmatch2命令前,首先设置了一个随机种子并将样本进行随机排序,这么做的原因是在匹配控制组样本时,如果有几个样本的倾向得分值相同,系统会优先选择排序靠前的样本。当然,不进行随机排序直接使用原始数据集的默认样本顺序问题也不大。
**# 一、截面匹配
use psmdata.dta, clear
**# 1.1 卡尺最近邻匹配(1:2)
set seed 0000
gen norvar_1 = rnormal()
sort norvar_1
psmatch2 treated $xlist , outcome(TFPQD_OP) logit neighbor(2) ties common ///
ate caliper(0.05)
save csdata.dta, replace
-
treated是本例中的分组变量。 -
$xlist是协变量的全局暂元,纯粹为了演示,这里直接使用基础回归中的控制变量,实际使用中一定要结合其他文献及敏感性分析挑选出适合的协变量。 -
outcome(TFPQD_OP)括号里面填的是结果变量(这里是TFPQD_OP),即基准回归中的被解释变量y,括号里可以填入多个结果变量。 -
logit表明使用logit模型估计倾向得分值,默认使用probit模型。 -
neighbor(2)表明使用最近邻匹配,括号里填入2说明使用1:2的匹配方法,即一个处理组样本最多匹配2个控制组样本。至于为什么是2?因为使用1:1的配对方式最后的结果不好看~ -
ties说明如果多个控制组样本的倾向得分值相同并且处于这个得分值的样本应该作为被匹配对象,那么匹配样本的结果变量取它们的均值,默认按照样本的排列顺序进行选择。这同时说明,如果加上ties,那么数据集是否提前排序就不怎么重要了。 -
common表示只对倾向得分值共同取值范围内的样本进行匹配。也就是说,两组样本的倾向得分值如果不在共同取值范围内,则直接被排除,从一开始就没有匹配资格。默认对所有样本进行匹配。 -
ate表示同时汇报ATE、ATU和ATT,默认只汇报ATT。ATE和ATT前文有介绍,ATU是非参与者的平均处理效应(Average Treatment Effect on the Untreated),我们重点关注的是ATT。 -
caliper(0.05)表示卡尺设置为0.05,即控制组样本的倾向得分值如果在处理组样本倾向得分值±0.05以外,直接没有被匹配的资格。因此,如果选择项同时包括neighbor(#)和caliper(#),则说明使用卡尺最近邻匹配。至于为什么是0.05?道理同neighbor(2)~
关于psmatch2其他选择项的详细说明,请键入如下代码进行了解。
help psmatch2
psmatch2的运行结果包括三部分的内容。
Logistic regression Number of obs = 81,567
LR chi2(13) = 5973.89
Prob > chi2 = 0.0000
Log likelihood = -53407.844 Pseudo R2 = 0.0530
------------------------------------------------------------------------------
treated | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
ADM | 2.303432 .1007328 22.87 0.000 2.105999 2.500865
PPE | -1.222116 .0342674 -35.66 0.000 -1.289279 -1.154953
ADV | 21.56327 3.731756 5.78 0.000 14.24917 28.87738
RD | 18.12885 3.306851 5.48 0.000 11.64754 24.61016
HHI | -.4729895 .065837 -7.18 0.000 -.6020276 -.3439513
INDSIZE | .0015667 .0103893 0.15 0.880 -.018796 .0219294
NFIRMS | .4045981 .0190289 21.26 0.000 .3673021 .441894
FCFIRM | 2.685802 .1414342 18.99 0.000 2.408596 2.963008
MARGIN | .8316006 .0620282 13.41 0.000 .7100276 .9531736
LEVDISP | -2.178396 .0987579 -22.06 0.000 -2.371958 -1.984835
SIZEDISP | .2341893 .0247433 9.46 0.000 .1856934 .2826852
ENTRYR | -.0103419 .0385426 -0.27 0.788 -.0858841 .0652002
EXITR | -.1123095 .0605613 -1.85 0.064 -.2310075 .0063884
_cons | -.9478736 .1123736 -8.44 0.000 -1.168122 -.7276253
------------------------------------------------------------------------------
----------------------------------------------------------------------------------------
Variable Sample | Treated Controls Difference S.E. T-stat
----------------------------+-----------------------------------------------------------
TFPQD_OP Unmatched | 2.24921913 2.35179198 -.102572852 .006214925 -16.50
ATT | 2.24921615 2.35605481 -.106838668 .008017304 -13.33
ATU | 2.35179488 2.28215595 -.069638929 . .
ATE | -.089340447 . .
----------------------------+-----------------------------------------------------------
Note: S.E. does not take into account that the propensity score is estimated.
psmatch2: | psmatch2: Common
Treatment | support
assignment | Off suppo On suppor | Total
-----------+----------------------+----------
Untreated | 1 38,367 | 38,368
Treated | 1 43,198 | 43,199
-----------+----------------------+----------
Total | 2 81,565 | 81,567
-
第一部分是
logit回归结果,在这里没有多大意义。 -
第二部分则重点关注
ATT的大小与显著性。在未匹配前(Unmatched那一行),平均处理效应为-0.1026,且在1%的水平下显著(t值的绝对值大于2.58);匹配后,参与者的平均处理效应ATT为-0.1068,同样在1%的水平下显著。结果虽好,但不能开心太早,因为这里的ATT仅仅是参与者实施政策对结果变量的影响,双重差分只在截面维度进行了差分,时间维度并未考虑,换言之,这不是我们需要的DID的处理效应。反之,就算ATT不显著关系也不大,因为我们PSM的目的是获得匹配样本,真正的DID回归在之后。 -
第三部分考察两组在共同取值范围内(
On support那一列)的样本量。可以看到,处理组和控制组都分别只有一个样本在共同取值范围外,这说明绝大多数样本(特别是控制组样本)都有资格参与匹配。
接下来是平衡性检验(Balance Test)。即检验匹配后协变量取值在两组间是否存在显著差异,如果差异不明显,则说明匹配效果好,使用这样的匹配样本进行DID回归就比较合适。平衡性检验主要有两种。
- 一是度量两组间协变量的标准化均值的偏差
%bias。如果匹配后协变量的%bias小于10%,且明显小于未匹配前的%bias,则说明对于这个协变量来说,两组间并无差距。%bias的计算公式如下。
KaTeX parse error: Undefined control sequence: \label at position 97: …^2)/2}} \tag{3}\̲l̲a̲b̲e̲l̲{eq3}
- 二是通过t检验来判断各个协变量的取值在两组间是否存在系统性偏差。t检验的原假设(
H0)是“两组间协变量的取值不存在系统性偏差”,因此我们的目标是最终接受H0。
psmatch2自带两个估计后检验命令,一个是pstest,用于进行平衡性检验;一个是psgraph,用柱状图的方式直观呈现出两组间满足共同支撑假设(即倾向得分值在共同取值范围内)样本的分布情况。
**# 1.2 平衡性检验
pstest, both graph saving(balancing_assumption, replace)
graph export "balancing_assumption.emf", replace
psgraph, saving(common_support, replace)
graph export "common_support.emf", replace
-
both表示同时显示匹配前后两组间各变量的平衡情况。 -
graph表示图示各变量匹配前后的平衡情况。 -
saving表示将图形保存为Stata可以识别的*.gph格式,方便后续修改。 -
graph export表示将图形输出为*.emf矢量图,方便插入到论文中。
pstest的运行结果如下,包括两张表和一幅图(图 1)。
----------------------------------------------------------------------------------------
Unmatched | Mean %reduct | t-test | V(T)/
Variable Matched | Treated Control %bias |bias| | t p>|t| | V(C)
--------------------------+----------------------------------+---------------+----------
ADM U | .07524 .06583 11.5 | 16.40 0.000 | 1.07*
M | .07524 .07762 -2.9 74.7 | -3.92 0.000 | 0.77*
| | |
PPE U | .34533 .40875 -29.7 | -42.32 0.000 | 0.93*
M | .34532 .34725 -0.9 96.9 | -1.36 0.173 | 1.02*
| | |
ADV U | .00044 .00036 4.4 | 6.22 0.000 | 1.26*
M | .00044 .00042 1.1 75.5 | 1.50 0.133 | 1.03*
| | |
RD U | .00047 .0003 6.9 | 9.77 0.000 | 1.63*
M | .00047 .00045 0.5 92.1 | 0.72 0.470 | 1.03*
| | |
HHI U | .2341 .26739 -19.8 | -28.19 0.000 | 0.95*
M | .23409 .23365 0.3 98.7 | 0.38 0.703 | 0.97*
| | |
INDSIZE U | 13.279 12.873 29.9 | 42.60 0.000 | 1.01
M | 13.279 13.291 -0.9 96.9 | -1.31 0.189 | 0.85*
| | |
NFIRMS U | 2.6806 2.3742 37.9 | 53.74 0.000 | 1.35*
M | 2.6807 2.6892 -1.1 97.2 | -1.41 0.159 | 0.89*
| | |
FCFIRM U | .01606 .00744 15.2 | 21.47 0.000 | 2.16*
M | .01606 .01534 1.3 91.7 | 1.60 0.109 | 1.01
| | |
MARGIN U | .8387 .83491 2.9 | 4.17 0.000 | 1.01
M | .8387 .83786 0.6 77.9 | 0.95 0.343 | 0.99
| | |
LEVDISP U | .25657 .26916 -16.9 | -24.11 0.000 | 0.81*
M | .25656 .25834 -2.4 85.9 | -3.69 0.000 | 0.99
| | |
SIZEDISP U | 1.211 1.1797 8.3 | 11.88 0.000 | 0.85*
M | 1.211 1.2131 -0.5 93.4 | -0.83 0.405 | 0.97*
| | |
ENTRYR U | .081 .08743 -3.4 | -4.82 0.000 | 0.92*
M | .081 .07818 1.5 56.1 | 2.25 0.024 | 1.05*
| | |
EXITR U | .03935 .0459 -5.4 | -7.74 0.000 | 0.81*
M | .03935 .04031 -0.8 85.4 | -1.21 0.225 | 0.96*
| | |
----------------------------------------------------------------------------------------
* if variance ratio outside [0.98; 1.02] for U and [0.98; 1.02] for M
-----------------------------------------------------------------------------------
Sample | Ps R2 LR chi2 p>chi2 MeanBias MedBias B R %Var
-----------+-----------------------------------------------------------------------
Unmatched | 0.053 5936.79 0.000 14.8 11.5 55.2* 1.17 85
Matched | 0.000 45.01 0.000 1.1 0.9 4.6 0.91 77
-----------------------------------------------------------------------------------
* if B>25%, R outside [0.5; 2]
(file balancing_assumption.gph saved)
第一张表是我们关注的重点。可以看到,所有协变量的%bias均小于10%,且都明显小于匹配前的%bias,%bias的绝对值较匹配前大幅下降了56.1%~98.7%;除ADM、LEVDISP和ENTRYR这三个协变量外,其余协变量均不拒绝“两组间协变量的取值不存在系统性偏差”的原假设。
第二张表是匹配前后logit回归的情况,其中Unmatched那一行是匹配前的回归结果,与psmatch2运行后第一张表保持一致,Matched那一行是匹配后的logit回归情况。可以看到,匹配后回归结果中伪R方(Ps R2)明显变小,这说明匹配后两组间的所有协变量取值差异性都不大,从而对logit回归中的被解释变量的变动没有太大的解释力。

图 1和第一张表的结果保持一致,即所有协变量的%bias均小于10%,并且都明显小于匹配前的%bias。
psgraph的运行结果如图 2。同样,图 2和前文psmatch2运行结果中的第三张表保持一致,即处理组和控制组的绝大多数样本都在共同取值范围内,而不在共同取值范围内的样本的倾向得分值比较极端(从图片中暂时无法看出是极端大还是极端小)。

然后我们还可以考察一下两组倾向得分值在匹配前后是否存在差异,这里可以使用核密度图来直观体现。如果匹配前两组间的核密度曲线偏差比较大,而匹配后核密度曲线比较接近,说明匹配效果好。
**# 1.3 倾向得分值的核密度图
sum _pscore if treated == 1, detail // 处理组的倾向得分均值为0.5632
*- 匹配前
sum _pscore if treated == 0, detail
twoway(kdensity _pscore if treated == 1, lpattern(solid) ///
lcolor(black) ///
lwidth(thin) ///
scheme(qleanmono) ///
ytitle("{stSans:核}""{stSans:密}""{stSans:度}", ///
size(medlarge) orientation(h)) ///
xtitle("{stSans:匹配前的倾向得分值}", ///
size(medlarge)) ///
xline(0.5632 , lpattern(solid) lcolor(black)) ///
xline(`r(mean)', lpattern(dash) lcolor(black)) ///
saving(kensity_cs_before, replace)) ///
(kdensity _pscore if treated == 0, lpattern(dash)), ///
xlabel( , labsize(medlarge) format(%02.1f)) ///
ylabel(0(1)4, labsize(medlarge)) ///
legend(label(1 "{stSans:处理组}") ///
label(2 "{stSans:控制组}") ///
size(medlarge) position(1) symxsize(10))
graph export "kensity_cs_before.emf", replace
discard
*- 匹配后
sum _pscore if treated == 0 & _weight != ., detail
twoway(kdensity _pscore if treated == 1, lpattern(solid) ///
lcolor(black) ///
lwidth(thin) ///
scheme(qleanmono) ///
ytitle("{stSans:核}""{stSans:密}""{stSans:度}", ///
size(medlarge) orientation(h)) ///
xtitle("{stSans:匹配后的倾向得分值}", ///
size(medlarge)) ///
xline(0.5632 , lpattern(solid) lcolor(black)) ///
xline(`r(mean)', lpattern(dash) lcolor(black)) ///
saving(kensity_cs_after, replace)) ///
(kdensity _pscore if treated == 0 & _weight != ., lpattern(dash)), ///
xlabel( , labsize(medlarge) format(%02.1f)) ///
ylabel(0(1)4, labsize(medlarge)) ///
legend(label(1 "{stSans:处理组}") ///
label(2 "{stSans:控制组}") ///
size(medlarge) position(1) symxsize(10))
graph export "kensity_cs_after.emf", replace
discard
以上代码的运行结果如下图 3和图 4。
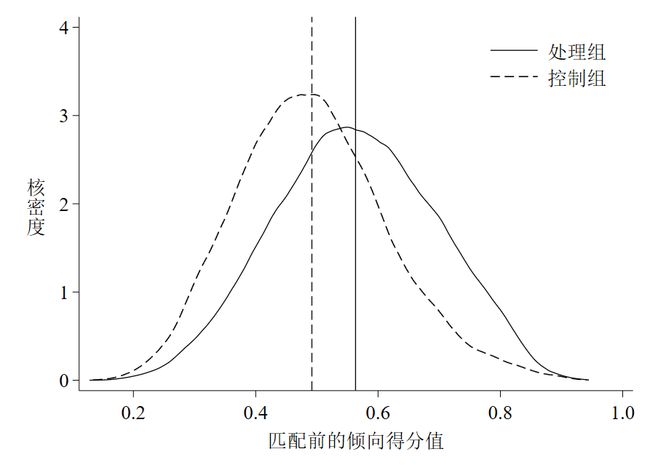

可以看到,匹配前后两条核密度曲线偏差都较大,但匹配后两条曲线更为接近了,这点可以从均值距离缩小看出(图中垂直于横轴的实线是处理组样本倾向得分值的均值线,虚线是控制组的均值线)。因此,一定程度上可以说明我们的匹配还是有效果的(虽然效果不太明显~)。
最后就是利用PSM后的样本进行DID回归,并将回归结果与基准回归结果进行比较。
回归需要样本,那么如何获取匹配后的样本呢?
打开Stata的数据编辑器,可以观察到psmatch2在我们的数据集中生成了几个新变量,如下图 5。
![]()
-
_pscore是样本的倾向得分值。 -
_treated是处理组虚拟变量,和我们手动生成的treated保持一致。 -
_support是样本是否满足共同支撑假设的虚拟变量,即如果样本处于共同取值范围内,该变量取值为1,否则为0。 -
_weight是一个关键变量。- 对于处理组样本来说,该变量为空说明没有参与匹配(即未满足共同支撑假设),或者参与匹配了但在卡尺范围内暂未匹配到控制组样本;如果匹配成功了,该变量取值为1(奇了怪了,部分处理组样本该变量取值居然不等于1,甚至不为整!)。
- 对于控制组样本来说,该变量为空说明样本不满足共同支撑假设或在卡尺范围内没有匹配成功;对于匹配成功的样本,该变量可能取整也可能不取整,这取决于样本匹配成功的次数。具体来说,如果是
1:1无放回匹配,则每个处理组样本最多匹配成功一次,并且控制组样本也最多被匹配一次,因此对于控制组中匹配成功的样本来说,_weight只可能等于1;如果是1:1有放回匹配,则每个处理组样本最多匹配成功一次,而控制组样本可能被匹配k次,因此对于控制组中匹配成功的样本来说,_weight的取值为大于等于1的整数;如果是1:m的有放回匹配(psmatch2只允许在1:1匹配中设置无放回选项),则一个处理组样本最多可以匹配到m个对象,因此被匹配到的对象所占的权重为 1 / m 1/m 1/m,那么对于控制组样本来说,如果它被匹配到了k次,那么它的总权重就是 k × 1 m k×\frac{1}{m} k×m1,即_weight取值为 k m \frac{k}{m} mk。如果我们想要知道在1:m无放回匹配中,控制组样本被匹配的次数k,那么就只要将它们的_weight乘以m即可。因此,_weight的取值表明了样本是否参与匹配以及样本的重要性程度。
-
_TFPQD_OP代表样本匹配到对象的结果变量(这里是TFPQD_OP)的均值。 -
_id是psmatch2自动为每一个样本赋予的唯一识别编码。 -
_n1和n2代表样本匹配对象在_id中的编码,由于这里是1:2匹配,所以有两个。 -
_nn表示处理组样本匹配到的控制组样本的个数。 -
_pdif表示样本的倾向得分值与_n1样本倾向得分值之差的绝对值。
由此可知,只要样本的_weight不为空,就代表该样本参与了匹配,就可以将这些样本代入到DID回归模型中进行参数估计,而且一定程度上缓解了基准回归中存在的选择偏差问题,进一步还可以与基准回归结果进行比较以检验其稳健性。
事实上,多数文献都是按照这个思路进行的,当然,也有部分文献直接选择满足共同支撑假说的样本代入到DID回归模型中,如李青原和肖泽华(2020)。
[15] 李青原, 肖泽华. 异质性环境规制工具与企业绿色创新激励——来自上市企业绿色专利的证据[J]. 经济研究, 2020, 55(09): 192-208.
但是,这样可能忽视了一个关键问题。无论是使用权重不为空的样本还是使用满足共同支撑假设的样本进行回归,都忽视了一个基本事实,那就是被匹配的控制组样本可能作为多个处理组样本的匹配对象,因此不同权重的控制组样本在总体的控制组样本中的重要性程度是不一样的。权重越大,说明被匹配上的次数越多,参与回归时越应该被重视,因此一种可行的办法是根据权来重复制控制组中被匹配上的样本,也就是所谓的频数加权回归。
所以,在进行回归结果对比时,除了需要包括两个基准回归、一个使用权重不为空的样本进行的回归和一个使用使用满足共同支撑假设的样本进行的回归,还需要包括一个考虑样本重要性的频数加权回归。
**# 1.4 回归结果对比
use csdata.dta, clear
*- 基准回归1(混合OLS)
qui: reg TFPQD_OP FB $xlist , cluster(city)
est store m1
*- 基准回归2(固定效应模型)
qui: reghdfe TFPQD_OP FB $xlist , $regopt
est store m2
*- PSM-DID1(使用权重不为空的样本)
qui: reghdfe TFPQD_OP FB $xlist if _weight != ., $regopt
est store m3
*- PSM-DID2(使用满足共同支撑假设的样本)
qui: reghdfe TFPQD_OP FB $xlist if _support == 1, $regopt
est store m4
*- PSM-DID3(使用频数加权回归)
gen weight = _weight * 2
replace weight = 1 if treated == 1 & _weight != .
qui: reghdfe TFPQD_OP FB $xlist [fweight = weight], $regopt
est store m5
*- 回归结果输出
local mlist_1 "m1 m2 m3 m4 m5"
reg2docx `mlist_1' using 截面匹配回归结果对比.docx, b(%6.4f) t(%6.4f) ///
scalars(N r2_a(%6.4f)) noconstant replace ///
mtitles("OLS" "FE" "Weight!=." "On_Support" "Weight_Reg") ///
title("基准回归及截面PSM-DID结果")
其中,频数加权回归除了可以使用Stata自带的fweight方法,还可以考虑直接将样本复制进而回归,这种思路来源于黄河泉(2017)在经管之家论坛的回答,最终结果与fweight方法完全一致。
gen weight = _weight * 2
replace weight = 1 if treated == 1 & _weight != .
keep if weight != .
expand weight
reghdfe TFPQD_OP FB $xlist , $regopt
est store m5
基准回归及截面PSM - DID回归结果如下。
--------------------------------------------------------------------------------------------
(1) (2) (3) (4) (5)
OLS FE Weight!=. On_Support Weight_Reg
--------------------------------------------------------------------------------------------
FB -0.1243*** -0.0496*** -0.0545*** -0.0497*** -0.0422***
(-5.2480) (-3.6531) (-3.9823) (-3.6550) (-2.9228)
ADM 1.0682*** 0.8719*** 0.9287*** 0.8719*** 0.9839***
(17.6388) (18.0260) (16.1842) (18.0262) (12.0535)
PPE -0.1183*** -0.0845*** -0.0784*** -0.0845*** -0.0813***
(-4.3488) (-5.4869) (-4.3384) (-5.4864) (-3.6168)
ADV 3.4239* 0.4029 1.6045 0.3975 2.3618
(1.9284) (0.2547) (0.8734) (0.2513) (0.9525)
RD -1.1993 -3.5116*** -3.4516** -3.4852*** -4.2360*
(-0.8120) (-2.6572) (-2.1919) (-2.6371) (-1.8977)
HHI -0.0284 0.1391*** 0.1347*** 0.1393*** 0.0702
(-0.5123) (3.7371) (3.2368) (3.7409) (1.3515)
INDSIZE 0.1061*** 0.0398*** 0.0425*** 0.0398*** 0.0541***
(6.4798) (5.1231) (5.1566) (5.1227) (5.1725)
NFIRMS -0.2011*** -0.1012*** -0.1048*** -0.1012*** -0.1324***
(-7.0272) (-8.2637) (-7.9029) (-8.2608) (-7.5215)
FCFIRM 0.2561** -0.0343 0.0229 -0.0335 0.0774
(2.5595) (-0.5604) (0.2952) (-0.5472) (0.6958)
MARGIN 0.2333*** 0.2377*** 0.2472*** 0.2377*** 0.2808***
(6.6555) (8.2641) (7.5753) (8.2641) (6.3765)
LEVDISP 1.8228*** 1.1270*** 1.1118*** 1.1271*** 1.0811***
(15.3788) (20.1912) (17.9101) (20.1920) (13.5927)
SIZEDISP 0.1373*** 0.0678*** 0.0667*** 0.0678*** 0.0785***
(5.2810) (4.5861) (4.0912) (4.5819) (3.8797)
ENTRYR 0.0735*** 0.0732*** 0.0573** 0.0732*** 0.0684***
(2.9277) (3.2806) (2.4976) (3.2805) (2.6353)
EXITR 0.0560* 0.0491* 0.0420 0.0492* -0.0326
(1.7687) (1.7444) (1.3206) (1.7474) (-0.8330)
--------------------------------------------------------------------------------------------
N 81567 81567 60078 81565 116882
r2_a 0.0646 0.1613 0.1548 0.1613 0.1592
--------------------------------------------------------------------------------------------
t statistics in parentheses
* p<0.1, ** p<0.05, *** p<0.01
可以看到,核心解释变量外资银行进入(FB)在五个回归中均显著为负,且第(3)(4)(5)列FB系数值大小与第(2)列相差不大,其余控制变量的系数也符合预期,这说明当考虑到选择偏差问题后,基准回归结果依旧稳健。
此外,观察各回归中实际参与回归的样本数N可以发现,因为第(3)列使用的是权重不为空的样本,即PSM匹配成功的样本,因此样本量相比基础回归有所减少,且减少幅度较大;第(3)列使用的是满足共同支撑假设的样本,由于只有两个样本不满足假设,因此参与回归的样本只比基础回归少两个;第(4)列由于是根据权重进行的频数加权回归,实际参与回归的样本会根据权重进行复制,因此最终有116,882个样本参与回归。
2.3 逐年PSM - DID
逐年PSM - DID的整个流程与截面PSM - DID大致相似,也是通过PSM获得匹配后样本,然后再将样本代入DID模型中参与回归,最后比较回归结果以验证稳健性。
首先还是进行1:2的卡尺最近邻匹配。
**# 二、逐年匹配
use psmdata.dta, clear
**# 2.1 卡尺最近邻匹配(1:2)
forvalue i = 1998/2007{
preserve
capture {
keep if year == `i'
set seed 0000
gen norvar_2 = rnormal()
sort norvar_2
psmatch2 treated $xlist , outcome(TFPQD_OP) logit neighbor(2) ///
ties common ate caliper(0.05)
save `i'.dta, replace
}
restore
}
clear all
use 1998.dta, clear
forvalue k =1999/2007 {
capture {
append using `k'.dta
}
}
save ybydata.dta, replace
明显可以看出,与截面PSM - DID相比这里多了两个循环。
-
第一个循环的作用是逐年进行PSM,并将各年份PSM结果保存,最后获得1998年至2007年共10年的匹配后数据集。其中,
preserve和restore方便高效使用数据,即不用在循环中写入use psmdata.dta, clear。capture{}是为了避免某些年份数据缺失导致Stata报错并停止运行,当然,这里的年份都是连续的。 -
第二个循环的作用是将各年份匹配后数据纵向合并至一个数据集中,生成我们回归需要的面板数据。
capture{}的作用同上。
之后是绘制倾向得分值的核密度图(当然,先进行平衡性检验也行)。
**# 2.2 倾向得分值的核密度图
sum _pscore if treated == 1, detail // 处理组的倾向得分均值为0.5698
*- 匹配前
sum _pscore if treated == 0, detail
twoway(kdensity _pscore if treated == 1, lpattern(solid) ///
lcolor(black) ///
lwidth(thin) ///
scheme(qleanmono) ///
ytitle("{stSans:核}""{stSans:密}""{stSans:度}", ///
size(medlarge) orientation(h)) ///
xtitle("{stSans:匹配前的倾向得分值}", ///
size(medlarge)) ///
xline(0.5698 , lpattern(solid) lcolor(black)) ///
xline(`r(mean)', lpattern(dash) lcolor(black)) ///
saving(kensity_yby_before, replace)) ///
(kdensity _pscore if treated == 0, lpattern(dash)), ///
xlabel( , labsize(medlarge) format(%02.1f)) ///
ylabel(0(1)3, labsize(medlarge)) ///
legend(label(1 "{stSans:处理组}") ///
label(2 "{stSans:控制组}") ///
size(medlarge) position(1) symxsize(10))
graph export "kensity_yby_before.emf", replace
discard
*- 匹配后
sum _pscore if treated == 0 & _weight != ., detail
twoway(kdensity _pscore if treated == 1, lpattern(solid) ///
lcolor(black) ///
lwidth(thin) ///
scheme(qleanmono) ///
ytitle("{stSans:核}""{stSans:密}""{stSans:度}", ///
size(medlarge) orientation(h)) ///
xtitle("{stSans:匹配后的倾向得分值}", ///
size(medlarge)) ///
xline(0.5698 , lpattern(solid) lcolor(black)) ///
xline(`r(mean)', lpattern(dash) lcolor(black)) ///
saving(kensity_yby_after, replace)) ///
(kdensity _pscore if treated == 0 & _weight != ., lpattern(dash)), ///
xlabel( , labsize(medlarge) format(%02.1f)) ///
ylabel(0(1)3, labsize(medlarge)) ///
legend(label(1 "{stSans:处理组}") ///
label(2 "{stSans:控制组}") ///
size(medlarge) position(1) symxsize(10))
graph export "kensity_yby_after.emf", replace
discard
结果如图 6和图 7。

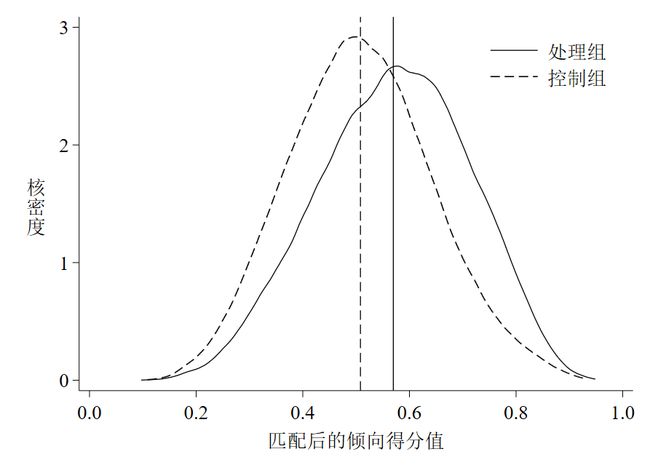
与截面PSM的结果类似,匹配前后两条核密度曲线偏差都比较大,但匹配后均值线距离缩短,两条曲线更加接近,因此一定程度上可以说明逐年匹配有效。
然后是逐年PSM的平衡性检验。
与截面PSM不同的是,由于逐年PSM是一年一年进行匹配的,因此考察各协变量在两组间是否存在系统性偏差只能在同一年份中进行比较,不同年份的匹配样本没有可比性,而且合并成面板数据后再进行平衡性检验Stata在技术上也不可行。这里参考谢申祥等(2021)的方法,比较匹配前后不同年份logit回归结果,即,如果匹配后各协变量的系数值减小、变得不显著和伪R方明显减小,则说明在不同年份两组的协变量不存在系统性偏差。
**# 2.3 逐年平衡性检验
*- 匹配前
forvalue i = 1998/2007 {
capture {
qui: logit treated $xlist i.ind3 if year == `i', vce(cluster prov)
est store ybyb`i'
}
}
local ybyblist ybyb1998 ybyb1999 ybyb2000 ybyb2001 ybyb2002 ///
ybyb2003 ybyb2004 ybyb2005 ybyb2006 ybyb2007
reg2docx `ybyblist' using 逐年平衡性检验结果_匹配前.docx, b(%6.4f) t(%6.4f) ///
scalars(N r2_p(%6.4f)) noconstant replace ///
indicate("Industry = *.ind3") ///
mtitles("1998b" "1999b" "2000b" "2001b" "2002b" ///
"2003b" "2004b" "2005b" "2006b" "2007b") ///
title("逐年平衡性检验_匹配前")
*- 匹配后
forvalue i = 1998/2007 {
capture {
qui: logit treated $xlist i.ind3 ///
if year == `i' & _weight != ., vce(cluster prov)
est store ybya`i'
}
}
local ybyalist ybya1998 ybya1999 ybya2000 ybya2001 ybya2002 ///
ybya2003 ybya2004 ybya2005 ybya2006 ybya2007
reg2docx `ybyalist' using 逐年平衡性检验结果_匹配后.docx, b(%6.4f) t(%6.4f) ///
scalars(N r2_p(%6.4f)) noconstant replace ///
indicate("Industry = *.ind3") ///
mtitles("1998a" "1999a" "2000a" "2001a" "2002a" ///
"2003a" "2004a" "2005a" "2006a" "2007a") ///
title("逐年平衡性检验_匹配后")
以上代码的运行结果如下。
*- 匹配前
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
(1) (2) (3) (4) (5) (6) (7) (8) (9) (10)
1998b 1999b 2000b 2001b 2002b 2003b 2004b 2005b 2006b 2007b
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
treated
ADM 2.2684*** 2.3222*** 2.0865*** 1.9288** 1.4294* 2.0740** 2.0784* 1.5288 2.3137 2.7268**
(2.7355) (2.5959) (2.8096) (2.4781) (1.9008) (2.0923) (1.9458) (0.9822) (1.3856) (2.1562)
PPE -0.5244** -0.3025 -0.7743*** -0.5716** -0.7099*** -0.6272** -1.0487*** -1.0451*** -0.8431* -0.9608**
(-2.2990) (-1.5852) (-3.4052) (-2.3569) (-2.6279) (-2.2244) (-3.5397) (-2.7774) (-1.9164) (-2.1682)
ADV 0.0000 0.0000 0.0000 13.4355 0.0000 0.0000 26.4667** 34.6121** 31.8339** 16.2578
(.) (.) (.) (1.0514) (.) (.) (2.4702) (2.2337) (2.2127) (1.2177)
RD 0.0000 0.0000 0.0000 10.9171 0.0000 0.0000 0.0000 -1.3296 14.1701 8.3546
(.) (.) (.) (1.2536) (.) (.) (.) (-0.1238) (1.5283) (0.7065)
HHI -1.6439* -1.6918** -1.1028 -1.2699 -1.0869 -0.6338 0.0072 0.0714 -0.0496 0.0429
(-1.7219) (-1.9652) (-1.3282) (-1.4922) (-1.4629) (-0.8633) (0.0148) (0.1513) (-0.0896) (0.0784)
INDSIZE 0.5445* 0.4829* 0.3557 0.3033 0.2376 0.1528 -0.2555 -0.0907 -0.1805 -0.2358
(1.7667) (1.8760) (1.4057) (1.1672) (0.9226) (0.6146) (-1.2398) (-0.4178) (-0.7170) (-0.9694)
NFIRMS -0.3930 -0.2420 0.0200 0.1023 0.2644 0.3734 0.9632*** 0.6899** 0.7769** 0.8697**
(-0.6612) (-0.4746) (0.0427) (0.2083) (0.5603) (0.8035) (2.7205) (1.9736) (2.0972) (2.4071)
FCFIRM 1.6635 0.7963 1.6429 1.1912 0.7410 0.6982 2.0390** 0.8335 1.1705 1.5674*
(0.9054) (0.4392) (1.1530) (0.6450) (0.5633) (0.6334) (2.1761) (0.6433) (1.3389) (1.6736)
MARGIN 1.5995*** 1.4034*** 1.0741*** 1.2462*** 0.4034 0.8745** 1.2484** -0.3829 0.7840 0.1712
(3.5296) (3.5031) (2.8690) (3.1566) (0.8275) (2.0900) (2.3096) (-0.3499) (0.6127) (0.1870)
LEVDISP -0.9378 -0.8800 -1.3296 -1.3270 -0.9001 -1.1339 -0.9631 -1.2057 -1.6036 -1.5013
(-0.4328) (-0.5331) (-0.7892) (-0.7769) (-0.5507) (-0.6717) (-0.5041) (-0.6542) (-0.9766) (-0.9726)
SIZEDISP -0.0741 0.0517 0.0790 0.1699 0.1840 0.1689 0.5612*** 0.3714 0.5487** 0.6102**
(-0.2874) (0.2080) (0.3297) (0.7125) (0.6938) (0.7498) (2.7553) (1.4051) (2.1442) (2.1618)
ENTRYR 0.0000 -0.0619 0.9535* 0.2964 0.0387 0.0183 0.0348 -0.6241 -0.6629** -0.6837**
(.) (-0.1157) (1.7572) (0.5243) (0.1305) (0.0435) (0.1230) (-0.6853) (-2.1473) (-2.3081)
EXITR -0.9139 0.7341 0.0460 -0.5761 -0.3070 0.2523 0.8344** 0.0524 -0.5910 -0.5330
(-1.1158) (1.1616) (0.0659) (-0.8138) (-0.6607) (0.4841) (2.0014) (0.1361) (-0.9383) (-0.7851)
_cons -8.6621*** -8.8834*** -7.3079*** -6.6187** -5.6780** -5.4720** -2.9528 -2.3179 -2.4977 -1.5174
(-2.7961) (-3.3483) (-2.6862) (-2.2210) (-2.1561) (-2.1240) (-1.0200) (-0.8532) (-0.7556) (-0.4968)
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Industry Yes Yes Yes Yes Yes Yes Yes Yes Yes Yes
N 6303 6600 6656 6845 7187 7601 9057 9428 10221 11207
r2_p 0.1321 0.1301 0.1337 0.1368 0.1369 0.1351 0.1578 0.1351 0.1314 0.1368
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
t statistics in parentheses
* p<0.1, ** p<0.05, *** p<0.01
*- 匹配后
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
(1) (2) (3) (4) (5) (6) (7) (8) (9) (10)
1998a 1999a 2000a 2001a 2002a 2003a 2004a 2005a 2006a 2007a
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
treated
ADM 0.8186 0.7099 1.0169 0.8462 0.1525 0.7434 0.0853 0.3600 0.8061 0.7568
(1.0061) (0.8124) (1.3867) (1.0619) (0.2048) (0.8235) (0.0714) (0.2385) (0.4899) (0.5814)
PPE 0.2349 0.3703* 0.1335 0.1864 0.2028 0.0637 -0.0651 -0.1128 -0.0983 -0.1607
(0.9089) (1.9154) (0.5660) (0.7556) (0.7784) (0.2231) (-0.2131) (-0.2964) (-0.2179) (-0.3868)
ADV 0.0000 0.0000 0.0000 6.5454 0.0000 0.0000 15.1587 4.7196 12.2655 -1.5428
(.) (.) (.) (0.6044) (.) (.) (1.3536) (0.2908) (0.8152) (-0.1188)
RD 0.0000 0.0000 0.0000 -8.3398 0.0000 0.0000 0.0000 -9.1278 -0.9288 -12.7757
(.) (.) (.) (-0.6978) (.) (.) (.) (-0.9596) (-0.0959) (-0.9324)
HHI -0.4786 -0.4828 -0.4323 -0.6529 -0.4950 -0.2469 -0.0630 -0.0505 0.2196 0.0863
(-0.5030) (-0.5685) (-0.5165) (-0.7708) (-0.6700) (-0.3173) (-0.1331) (-0.1042) (0.4048) (0.1496)
INDSIZE 0.2424 0.2039 0.0910 0.1361 0.1026 0.0569 -0.0786 0.0223 -0.0374 -0.1057
(0.7698) (0.8281) (0.3584) (0.5155) (0.3942) (0.2317) (-0.4091) (0.1061) (-0.1454) (-0.4386)
NFIRMS -0.1716 -0.0790 0.1095 0.0273 0.0924 0.1564 0.3901 0.2145 0.3206 0.4058
(-0.2827) (-0.1616) (0.2372) (0.0546) (0.1948) (0.3406) (1.1371) (0.6342) (0.8572) (1.1148)
FCFIRM 0.1643 -0.2306 -0.7050 -0.5302 -1.3960 -0.7499 -0.6088 -1.3333 -0.8095 -0.5513
(0.0941) (-0.1382) (-0.5092) (-0.3022) (-1.0856) (-0.7352) (-0.7719) (-1.0874) (-0.9200) (-0.6073)
MARGIN 1.1374** 0.7720* 0.7420* 0.5409 0.3343 0.4295 0.2948 -0.3597 0.3036 -0.0030
(2.3418) (1.7993) (1.9478) (1.2911) (0.6710) (1.0841) (0.5314) (-0.3368) (0.2356) (-0.0033)
LEVDISP -0.0022 0.2363 0.0725 0.5919 0.2944 0.4385 0.2644 0.2651 -0.0433 0.0963
(-0.0011) (0.1432) (0.0417) (0.3263) (0.1779) (0.2698) (0.1413) (0.1424) (-0.0264) (0.0619)
SIZEDISP -0.0387 0.0307 0.1642 0.1315 0.2040 0.2365 0.3054 0.1376 0.1875 0.2849
(-0.1369) (0.1286) (0.6774) (0.5625) (0.8189) (1.0679) (1.5141) (0.5676) (0.6690) (1.0209)
ENTRYR 0.0000 -0.0030 0.4019 0.0722 -0.2552 0.0391 -0.0099 -0.1736 -0.2510 -0.2626
(.) (-0.0054) (0.7407) (0.1290) (-0.8574) (0.0951) (-0.0325) (-0.2006) (-0.7387) (-0.9214)
EXITR -0.3475 0.1600 0.3100 -0.0141 -0.1314 0.2665 0.3176 0.1137 -0.0595 -0.1399
(-0.4376) (0.2422) (0.4429) (-0.0211) (-0.2864) (0.4944) (0.7820) (0.2809) (-0.0983) (-0.2001)
_cons -2.7021 -5.7169** -4.4212 -4.1241 -3.9158 -3.7323 -2.6553 -2.7141 -2.6220 -1.8506
(-0.9521) (-2.2631) (-1.6429) (-1.4217) (-1.4988) (-1.4734) (-0.9617) (-1.0106) (-0.7973) (-0.6046)
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Industry Yes Yes Yes Yes Yes Yes Yes Yes Yes Yes
N 4576 4769 4813 4889 5168 5557 6418 6732 7387 8048
r2_p 0.0907 0.0934 0.0894 0.0931 0.0878 0.0917 0.0951 0.0836 0.0767 0.0797
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
t statistics in parentheses
* p<0.1, ** p<0.05, *** p<0.01
可以看到,匹配后各年份绝大多数协变量的系数值减小(少数几个协变量因为共线性而被omitted),并且系数大多变得不显著,而且所有回归的伪R方明显减小,这说明在不同年份两组的协变量不存在系统性偏差。
最后是回归结果的对比。
**# 2.4 回归结果对比
use ybydata.dta, clear
*- 基准回归1(混合OLS)
qui: reg TFPQD_OP FB $xlist , cluster(city)
est store m1
*- 基准回归2(固定效应模型)
qui: reghdfe TFPQD_OP FB $xlist , $regopt
est store m2
*- PSM-DID1(使用权重不为空的样本)
qui: reghdfe TFPQD_OP FB $xlist if _weight != ., $regopt
est store m6
*- PSM-DID2(使用满足共同支撑假设的样本)
qui: reghdfe TFPQD_OP FB $xlist if _support == 1, $regopt
est store m7
*- PSM-DID3(使用频数加权回归)
gen weight = _weight * 2
replace weight = 1 if treated == 1 & _weight != .
qui: reghdfe TFPQD_OP FB $xlist [fweight = weight], $regopt
est store m8
*- 回归结果输出
local mlist_2 "m1 m2 m6 m7 m8"
reg2docx `mlist_2' using 逐年匹配回归结果对比.docx, b(%6.4f) t(%6.4f) ///
scalars(N r2_a(%6.4f)) noconstant replace ///
mtitles("OLS" "FE" "Weight!=." "On_Support" "Weight_Reg") ///
title("基准回归及逐年PSM-DID结果")
运行结果如下。回归结果与截面PSM - DID基本一致,因此也同样可以说明基准回归结果在考虑到选择偏差问题之后依然稳健。
--------------------------------------------------------------------------------------------
(1) (2) (3) (4) (5)
OLS FE Weight!=. On_Support Weight_Reg
--------------------------------------------------------------------------------------------
FB -0.1243*** -0.0496*** -0.0493*** -0.0498*** -0.0466***
(-5.2480) (-3.6531) (-3.5125) (-3.6669) (-3.1779)
ADM 1.0682*** 0.8719*** 0.8917*** 0.8712*** 0.9117***
(17.6388) (18.0260) (15.3250) (17.9650) (11.4538)
PPE -0.1183*** -0.0845*** -0.0899*** -0.0848*** -0.1136***
(-4.3488) (-5.4869) (-4.8695) (-5.5008) (-4.9564)
ADV 3.4239* 0.4029 0.3887 0.3767 4.4924
(1.9284) (0.2547) (0.1959) (0.2374) (1.5339)
RD -1.1993 -3.5116*** -5.1446*** -3.5391*** -5.2116**
(-0.8120) (-2.6572) (-2.9252) (-2.6649) (-2.1192)
HHI -0.0284 0.1391*** 0.1510*** 0.1392*** 0.0911*
(-0.5123) (3.7371) (3.6121) (3.7313) (1.7278)
INDSIZE 0.1061*** 0.0398*** 0.0363*** 0.0397*** 0.0459***
(6.4798) (5.1231) (4.1622) (5.1027) (4.3791)
NFIRMS -0.2011*** -0.1012*** -0.0975*** -0.1011*** -0.1199***
(-7.0272) (-8.2637) (-6.9857) (-8.2429) (-6.8619)
FCFIRM 0.2561** -0.0343 -0.1043 -0.0388 0.0600
(2.5595) (-0.5604) (-1.3284) (-0.6256) (0.6081)
MARGIN 0.2333*** 0.2377*** 0.2238*** 0.2368*** 0.3077***
(6.6555) (8.2641) (6.8292) (8.2343) (7.1966)
LEVDISP 1.8228*** 1.1270*** 1.1647*** 1.1270*** 1.1589***
(15.3788) (20.1912) (18.2101) (20.1705) (14.0951)
SIZEDISP 0.1373*** 0.0678*** 0.0637*** 0.0678*** 0.0712***
(5.2810) (4.5861) (3.8471) (4.5825) (3.5551)
ENTRYR 0.0735*** 0.0732*** 0.0635*** 0.0743*** 0.0563**
(2.9277) (3.2806) (2.6220) (3.3212) (2.0777)
EXITR 0.0560* 0.0491* 0.0468 0.0483* 0.0201
(1.7687) (1.7444) (1.4509) (1.7128) (0.4843)
--------------------------------------------------------------------------------------------
N 81567 81567 58926 81507 116269
r2_a 0.0646 0.1613 0.1548 0.1612 0.1590
--------------------------------------------------------------------------------------------
t statistics in parentheses
* p<0.1, ** p<0.05, *** p<0.01