数字IC验证:电路基础知识(数字IC、SOC等)
文章目录
- 0 SOC结构
- 1 数字IC设计的流程
-
- 1.1 逻辑综合的流程
- 2 电路基础
-
- 2.1 三极管BJT
- 2.2 MOSFET
- 2.3 CMOS
- 2.4 锁存器与触发器:RS/D/JK/T
- 2.5 最大项,最小项
- 2.6 加法器的种类和区别
- 2.7 SRAM的结构和基本原理
- 2.8 竞争与冒险
- 3 Verilog基础
-
- 3.1 阻塞和非阻塞
- 3.2 状态机
- 3.3 可综合&不可综合
- 4 时序分析
-
- 4.1 亚稳态与双稳态
- 4.2 建立时间与保持时间
- 4.3 时钟偏差skew和时钟抖动jitter
- 4.4 复位
- 4.5 跨时钟域
- 4.6 同步FIFO和异步FIFO
- 5 计算机体系架构/SOC
-
- 5.1 CPU的基本结构
- 5.2 Cache的作用
- 5.3 AMBA总线协议
- 5.4 FPGA的基本结构
- 5.5 通信协议
- 5.6 DMA
- 5.7 流水线Pipeline
- 6 低功耗
- 7 其他
-
- 7.1 Python
- 7.2 Matlab
- 7.3 C
- 7.4 C++
- 7.4 卷积神经网络
写在前面:
本文主要为笔者准备数字IC秋招时学习的一些技术问题。主要意向岗位是数字IC验证。希望对大家有帮助,共同进步。也希望自己能拿到一个满意的offer!
0 SOC结构
下图画了一个SOC结构图,SOC包含了很多模块,即IP,如CPU、DSP、USB外设、Memory、DMA等,它们通过总线如AHB、AXI连接。通常是先设计好每个IP模块,最后集成到一起,成为SOC。

1 数字IC设计的流程
- 制定设计需求,即SPEC(Specification)。做芯片之前要先做市场调研,根据市场需求来设计芯片的SPEC,由架构工程师来设计芯片架构,包括芯片的功能和具体指标。
2.确定了SPEC后,要进行系统级设计,为了降低成本,不是一开始就写RTL,要先用算法进行模拟仿真,就是用系统建模语言,比如Matlab,C,C++来对各个模块进行描述,模拟仿真来确定SPEC的可行性,如果可行的话,最后就输出一个具体的设计需求文档。- 得到设计需求文档之后,就要进行前端设计。首先是进行RTL设计,就是写verilog,用到的EDA工具有Synopsys 的VCS,这个过程结束中还要进行风格代码检查,同时验证工程师也要根据SPEC来对RTL做功能仿真,比如用System
Verilog搭建testbench来验证RTL设计的功能是否满足,用到比如说Mentor的QuestaSim或者Cadence的Xcelium,有的还会用FPGA做原型验证。验证通过了之后,下一步就是逻辑综合,就是将RTL代码转化成门级电路,比如用Design
Compiler生成网表文件。还要进行STA静态时序分析,也就是套用一些时序模型来针对电路分析有没有时序为例,比如建立时间、保持时间等。- 前面的步骤都通过之后,就把网表文件给后端。后端设计就是做Place&Route,过DRC、LVS,PEX。
- 这些都过了之后,后端最终会生成GDSII格式的文件,就可以找工厂流片了,流片回来的demo要再做测试。失败了就打回去改,成功了就可以做出产品发布了。
1.1 逻辑综合的流程
逻辑综合是将RTL电路转换成基于具体工艺库的门级网表。分为三个阶段:
- 转译:把电路转换成EDA内部数据库,这个数据库跟工艺库是独立无关的;
- 优化:根据工作频率、面积、功耗来对电路进行优化,进而推断出满足设计指标要求的门级网表
- 映射:将门级网表映射到晶圆厂给定的工艺库上,最终形成该工艺库对应的门级网表。
常用的逻辑综合工具为Design Complier (DC)。DC在综合过程中会把电路划分为以下处理对象:Design, Port, Clock, Cell, Reference, Net, Pin。
DC逻辑综合的流程:
- 预综合过程:启动DC -> 设置各种库文件(link_library, target library, symbol library) -> 创建启动脚本文件 -> 读入设计文件(analyze, elaborate, read_file) -> DC中的设计对象 -> 各种模块划分 -> Verilog的编码
- 施加设计约束:设计环境约束(set_operating_conditions, set_wire_load, set_drive, set_driving_cell, set_load, set_fanout_load)
- 设置时序约束:设计规则DRC的约束(set_max_transition, set_max_fanout, set_max_capacitance) -> 优化的约束(create clock -> set_clock_skew -> set_input_delay -> set_output_delay -> set_max_area)
- 设计综合
- 后综合
2 电路基础
2.1 三极管BJT
BJT是Bipolar Junction Transistor。Bipolar指的是有两种载流子,电子和空穴;Junction指的是PN结,有两个PN结结合在一起;Transistor就是晶体管。
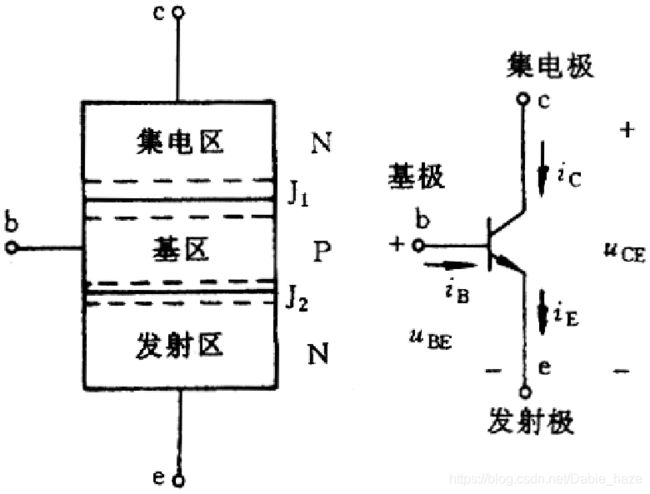
三极管有三个极:集电极、发射极和基极。对应有三种接法:共集电极、共发射极和共基极。比如说共发射极,就是输入和输出回路共用了发射极,三极管的输入电压是 V B E V_{BE} VBE,输入电流是 I B I_B IB,输出电压是 V C E V_{CE} VCE,输出电流是 I C I_C IC。三极管的工作状态主要分为截止区、放大区和饱和区,还有击穿区。截止区的发射结和集电结都反偏( V B E ≤ V B E ( o n ) V_{BE} ≤V_{BE(on)} VBE≤VBE(on)),输出电流几乎为0;放大区是发射结正偏,集电结反偏( V B E > V B E ( o n ) , V C > V B > V E V_{BE} >V_{BE(on)}, V_C > V_B > V_E VBE>VBE(on),VC>VB>VE),输出电流 I C I_C IC和输入电压 V B E V_{BE} VBE成近似线性;饱和区是发射结和集电结都正偏,( V B E > V B E ( o n ) , V B > V C V_{BE} >V_{BE(on)}, V_B > V_C VBE>VBE(on),VB>VC),输出电流达到饱和,不再随着输入电压增大而增大;但输入电压增大到一定程度,管子就击穿了。
2.2 MOSFET
MOS (Mental-Oxide-Semiconductor)就是金属氧化物半导体,是它最初的制作材料,不过现在已经不用金属氧化物了,改用多晶硅了。FET (Field-Effect-Transistor)指的是场效应管,是指载流子的运动形成了沟道,形成了电场。
MOS管有4个极:栅极、源极、漏极、体极。根据沟道类型分为NMOS和PMOS。
根据沟道的形成,MOS管的工作状态分了三种:截止区、线性区、饱和区。截止区 V g s < V_{gs} < Vgs< 阈值电压 V T V_T VT, 没有沟道;线性区 V G S > V T , V d s ≤ V g s − V T V_{GS} > V_T, V_{ds} ≤ V_{gs} - V_T VGS>VT,Vds≤Vgs−VT,有沟道形成,根据沟道的类型分为NMOS和PMOS,如NMOS,栅极和源极之间的外加电压 V g s V_{gs} Vgs,让漏极和源极之间的半导体层的载流子,也就是电子累积,靠近栅极,形成一个N型的反型层,就是N型沟道。但是只有沟道是没有电流的,还需要增大漏极和源极之间的电压 V d s V_{ds} Vds,吸引电子靠近源极,才有沟道电流 I d s I_{ds} Ids, I d s I_{ds} Ids 随着 V g s V_{gs} Vgs的增大而接近线性增大,并且靠近源极处的电子更多,沟道更宽,靠近漏极处沟道宽度随着 V d s V_{ds} Vds的增大,越来越窄;直到漏极的沟道夹断,只有靠近源极处还有沟道,就是饱和区,对应 V g s > V T , V d s > V g s − V T V_{gs} > V_T, V_{ds} > V_{gs} - V_T Vgs>VT,Vds>Vgs−VT,饱和区 I d s I_{ds} Ids不再随着 V g s V_{gs} Vgs增大而增大。
BJT和MOS区别:
- BJT是电流驱动型的,功耗大,传输延迟小,基极电流限制了它的集成度没法很高。
- MOS管是电压驱动型的,功耗小,输入阻抗大,输出阻抗小,栅极几乎没有电流,因此集成度高。
MOS管栅极的SiO2层形成多晶硅而不是直接覆盖金属:
最早的栅极二氧化硅绝缘层上覆盖的是金属,在做栅极之前先做好源和漏,源漏退火后才能做栅极,因为栅极用金属不能承受高温。同时栅极的金属和互连的金属线是一起做的,为了保证栅极和源漏能连接起来,所以栅极和源漏的重叠部分要求比较宽(0.5um以上),导致栅源和栅漏的重叠电容很大。而多晶硅的熔点高,并且可以掺杂后的电阻低,可以先做多晶硅的栅极,再做源漏阱,然后退火。并且随着MOS管尺寸越做越小,用多晶硅也不用考虑栅极和源漏之间重叠宽度的问题。
2.3 CMOS
下拉网络里,输入驱动NMOS的栅极,上拉网络里,输入驱动PMOS的栅极,因为NMOS传强0,PMOS传强1,这样输出总是强驱动的。
2.4 锁存器与触发器:RS/D/JK/T
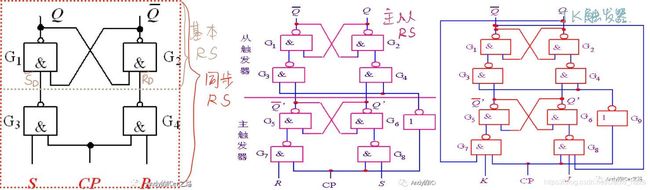
- RS锁存器&触发器:是锁存器,电平触发。基本的RS锁存器是当S=1&R=0时,输出Q=1;S=0&R=1时,输出Q=0;R=S=0时状态保持;但是不能同时给R=S=1,输出 Q Q Q和 Q ‾ \overline Q Q同时置1之后会不确定。
同步RS锁存器:加了同步时钟,只有CLK=1时,输出状态会改变,其他时候,状态保持。时钟有效时,输出逻辑和基本RS锁存器一样。此外,同步RS锁存器有空翻现象,即CLK=1时,S和R若多次改变,每次改变都会影响输出,会出现每个时钟脉冲下输出状态会发生很多次转换,但时序电路我们一般都希望每个时钟节拍最多对应一次电路的输出转变。
为了解决同步RS锁存器的空翻现象,就有了主从RS触发器,级联两个同步RS触发器,连接RS输入的触发器是主触发器, C L K CLK CLK是时控信号,连接 Q Q Q和 Q ‾ \overline Q Q输出的是从触发器, C L K ‾ \overline {CLK} CLK是时控信号。两个时控信号的组合让只有时钟下降沿时输出转变,解决空翻现象。 - JK触发器:(JK触发器是主从RS触发器加了反馈,解决了RS触发器不允许R=S=1的约束)有两个激励信号J和K,输出 Q n + 1 = J n ⋅ Q n ‾ + K n ‾ ⋅ Q n Q^{n+1} = J^n·\overline {Q^n} + \overline {K^n}·Q^n Qn+1=Jn⋅Qn+Kn⋅Qn,时钟边沿触发,J=0&K=1时置0(复位)、J=1&K=0时置1,J=K=0时保持(状态不变)、J=K=1时翻转(状态翻转)。
- D触发器:(JK触发器+一个反相器: J = D J = D J=D, K = D ‾ K = \overline D K=D)次态方程 Q n + 1 = D n Q^{n+1}=D^n Qn+1=Dn,时钟边沿触发
- T触发器:(JK触发器的J=K=T)异或操作, Q n + 1 = T n ⊕ Q n Q^{n+1}=T^n⊕Q^n Qn+1=Tn⊕Qn,时钟边沿触发
- 触发器和锁存器的区别:触发器是边沿触发,锁存器是电平触发。锁存器在不锁存数据时,输出会随输入变化,但一旦锁存数据,输出不受输入影响。
2.5 最大项,最小项
最大项即最小项的取反/补集。如对于3变量 A = 0 , B = 0 , C = 0 A=0, B=0, C=0 A=0,B=0,C=0,则最小项为 A ‾ B ‾ C ‾ \overline A \overline B \overline C ABC,最大项为 A + B + C A+B+C A+B+C
2.6 加法器的种类和区别
- 1-bit的半加器:sum = A xor B, C_out = A·B
- 1-bit的全加器:两个半加器和一个或门实现全加器,sum = (A xor B) xor C_in, C_out = (A xor B) · C_in + A·B
- Ripple-Carry Adder行波进位加法器:N个全加器直接级联,前级的C_out连后级的C_in,缺点是加法器的延时高,电路工作频率低。延时 t a d d e r = ( n − 1 ) ∗ t c a r r y + t s u m t_{adder} = (n-1)*t_{carry} + t_{sum} tadder=(n−1)∗tcarry+tsum,其中 t c a r r y t_{carry} tcarry 是每个全加器里C_in到C_out的延时, t s u m t_{sum} tsum 是C_in到sum的延时
- Carry-Bypass Adder进位旁路加法器:在最后加一个选择器,选择器的输入是第一级的C_in和最后一级的C_out,选择信号是BP,BP等于每一级全加器的两个输入的异或相与,如果BP=1说明每一级的进位都是输入传递到输出,所以选择器选择直接输出第一级的C_in,而不用进行进位传递,降低了延时
- Carry-Select Adder进位选择加法器:每一级的内部先算好C_in来0和1时分别输出的结果,再根据实际的C_in用mux选,降低了延时
- Carry-Look-Ahead Adder超前进位加法器:引入了生成信号和传播信号的概念,对于第i级全加器,生成信号Gi=Ai与Bi,传播信号Pi=Ai或Bi,有一个推论是Ci+1 = Gi:j + Pi:j ·Ci(第i+1级的进位输出Ci+1 = Gi:j 或上 Pi:j和第i级的进位相与的结果),通过这个推论可以实现降比特运算,每一级的进位的都可以通过第一级进位加一个组合电路产生,高位运算不需要低位一级级传递,直接由第一级算出来,因此速度很快,但是如果位数比较高,额外增加的组合电路会导致电路变得很复杂。
2.7 SRAM的结构和基本原理
- SRAM的结构:主要是一个Memory的array阵列,里面是具体存放的数据;通过control模块来控制读写操作,控制模块有CS片选端,WE(Write Enable)和OE(Output Enable);还有row decoder和column decoder,功能类似是一个N输入的选择器,用来选择具体哪一行和哪一列;还有一般会有个FIFO,来作为写memory时候的缓冲;memory输出那边还有一个Sense Amplifier,是一个放大器,因为数据信号是0还是1,是通过电平来判断的,但是比如说在某一行,01的变化在电压上的体现其实很小,所以Sense Amplifier是通过把这种电压上的微小变化放大到可以判断出逻辑0还是1的电平变化。
- SRAM的读写操作:
(1)读数据:首先通过地址总线来传地址,送到整个SRAM的Addr 输入引脚;之后用CS具体选到某一个SRAM里,把地址送到row decorder和column decoder里;然后使能OE来知道是要读出数据;之后decorder定位到的地址里的数据读出来,从Dout送到数据总线。
(2)写数据:通过地址总线传地址,送到Addr输入引脚;并且数据总线把数据传到Data in引脚;然后CS片选选到某一个SRAM,使能WE,并且通过送到decorder的地址来定位到要写数据的具体某一行某一列,然后把数据写进去。 - SRAM和DRAM:都是可擦除的,也就是掉电数据会消失的。SRAM主要用在CPU cache里,因为它的访问速度很快,但它存储量不大;DRAM一般用在主Memory里,需要周期性地刷新,因为DRAM的cell是一个MOS管+一个电容组成的,通过电容的电压来判断数据时0还是1,但是因为是电容,电容里储存的电荷是会慢慢泄露的,所以需要周期刷新,充电。而SRAM的一个cell单元是4个MOS管+2个电阻组成,通过改变MOS管的导通截止来改变数据是0还是1。
2.8 竞争与冒险
- 什么是竞争与冒险:在组合逻辑中,由于向相反方向变化的输入信号经过不同的路径,有不同的延时,导致到达某个门的时间不一致,叫竞争(Race);由于竞争现象所引起的电路输出产生了毛刺,就叫冒险(Hazard)。有竞争不一定有冒险,但出现了冒险一定存在竞争。
- 如何判断是否存在竞争与冒险:(1)通过布尔表达式来判断:如果布尔表达式中有相反的信号,比如Y=A·B+A_not·C,当B和C都为1的时候,如果A的值跳转,就会发生竞争,进而在跳转的过渡时间段可能会产生毛刺,也就是冒险。(2)通过卡诺图来判断:如果有相切的框,就可能会有竞争冒险。
- 竞争与冒险的解决方法:用D-FF,格雷码计数器,同步电路等消除竞争与冒险。(1)修改逻辑设计,增加冗余项,比如对布尔表达式添加消去项,比如Y=A·B+A_not·C,可以添加消去项BC。(2)引入封锁脉冲,也就是负脉冲,在输入信号发生竞争的时间段内,把可能产生毛刺的门锁住,不过要求封锁脉冲的宽度不应小于过渡时间(毛刺的时间)且与输出信号转换同步。(3)引入选通脉冲,在毛刺结束后,再选通稳定的信号输出,不过对脉冲宽度和产生的时间有严格要求。(4)在门电路的输出端引入滤波电容,来滤掉毛刺,但输出波形本身的边沿也会被滤得更平滑。(5)改用时序逻辑,用D-FF打一拍,对于D触发器的数据输入端,只要毛刺不出现在时钟沿并且没有建立时间和保持时间违例,输出就不会有冒险。(6)转换成格雷码再输入,因为格雷码每次只有1bit变化
- 冒险的分类:根据冒险的产生原因分为逻辑冒险和功能冒险:逻辑冒险是指因为电路中一个输入信号发生变化产生的冒险,比如对应的布尔表达式里有A和A非,这种因为A的变化产生的冒险就是逻辑冒险;功能冒险指因为两个或者多个信号同时发生变化,但到达门的输入端有时间差而产生了毛刺,叫功能冒险。根据输出信号中毛刺的个数,分为静态冒险和动态冒险:由于信号和电路的延迟,在输出信号产生了单个毛刺,就叫静态冒险;产生了多个毛刺,就是动态冒险。
3 Verilog基础
gen语句的使用,怎么避免latch
手撕代码部分:帧头检测、无毛刺时钟切换、按键去抖动,红绿灯、斐波那契数列求解器、fir滤波器等等。然后用verilog的语法写tb
3.1 阻塞和非阻塞
- 阻塞:阻塞语句在执行完后才会执行下一个语句(assign一定要用阻塞=)
- 非阻塞:当前语句的执行不会阻塞下一语句的执行,非阻塞语句之间是并行的(<=)
3.2 状态机
- 分类:Moore状态机和Mealy状态机。二者的次态都取决于当前状态和当前输入。
- Moore状态机的输出只取决于当前状态,与当前输入无关,就是每个状态对应一个输出。
- Mealy状态机的输出不仅取决于当前状态,还取决于当前输入。如果不对输出做同步处理,输出容易出现glitch, 由于输出不仅取决于状态还取决于输入,因此输出的译码电路会更复杂,可以认为mealy能跑的频率比moore更低一点
3.3 可综合&不可综合
- 可综合:always, assign, begin, end, case, wire, tri, supply0, supply1, reg, integer, default, for, function, and, nand, or, nor, xor, xnor, buf, not, bufif0,bufif1, notif0, notif1, if, inout, input, instantitation, module, negedge, posedge, operators, output, parameter
- 不可综合:time, defparam, $finish, fork, join, initial, delays, UDP, wait
- 视EDA工具而定:casex, casez, wand, triand, wor, trior, real, disable, forever, arrays, memories, repeat, task, while
4 时序分析
4.1 亚稳态与双稳态
- 什么是亚稳态:在数字电路中,比如说一个触发器的输出信号从0翻转到1时,理想的转换是瞬间完成的,但是实际的器件一定会有延时,而从0到1之间就会有一段不稳定的中间电平,也就是高阈值电平 V H V_H VH和低阈值电平 V L V_L VL之间,输出就无法判断是1还是0,具体的电平值和达到稳态的时间都不确定,这一段状态就是亚稳态。
- 亚稳态如何产生:当一个触发器的输入信号违反了触发器的建立时间和保持时间的约束时,比如说建立时间要求输入信号最晚要在时钟有效沿之前的 t s e t u p t_{setup} tsetup时间段到来且稳定下来的,也就是达到一个确定的电平;保持时间就是输入信号最晚要在时钟有效沿到来之后的 t h o l d t_{hold} thold时间段内保持稳定。如果建立时间或者保持时间的约束违反了,那么这个触发器时钟捕捉到的输入信号可能就处在中间电平,产生亚稳态,如果这个亚稳态信号的稳定时间超过一个时钟周期,就会被后级电路捕捉到,把这种不确定性或者说亚稳态往后级传。
- 亚稳态的危害:对于本级触发器来说,亚稳态可能会导致电平的误判;而除了本级,亚稳态还会往后级传播。
- 如何降低亚稳态的危害:受器件本身的不理想特性的限制,亚稳态不能完全消除,但可以通过减少亚稳态被触发器捕捉到的概率来降低亚稳态给电路带来危害。平均故障间隔时间MTBF就描述了这种概率,MTBF越大,表示这种概率越小。MTBF跟亚稳态的稳定时间成正比,跟建立时间和保持时间,还有时钟频率和数据变化频率成反比。所以如果要降低亚稳态的危害,也就是要增大MTBF,可以通过比如:(1)用建立时间和保持时间更短的触发器;(2)降低时钟频率;(3)降低数据变化的频率,尤其是跨时钟域的话,尽量避免对变化频率高的数据进行采样;(4)如果一定要跨时钟域高速采样,可以用两级或者更多级的触发器来进行同步:如果在第一级触发器亚稳态维持了超过一个周期,到第二级可能会稳定下来,因为亚稳态的时间一般不超过一个周期,两级同步器的稳定概率更大。如果两级不够,也可以再多加几级。不过这有一种可能是跨时钟采样失败,比如输入信号由0变到1之间的亚稳态从第一级传到了第二级,第二级时钟有效沿到来时可能捕捉到的电平刚好被判定为0,就是在第二级逻辑误判了。不过这种起码不会造成亚稳态往后级传播。对于逻辑误判的话,就可以在设计层面来降低误判的概率,比如说格雷码计数器,异步FIFO里就比较常用,通过格雷码的相邻码只有1比特跳转的特性来降低误码率。
4.2 建立时间与保持时间
- 建立时间定义:输入信号在时钟有效沿到来之前要保持稳定的最短时间。比如传输门和反相器组成的主从D触发器,时钟信号到来之前,主锁存器里的交叉耦合反相器要把数据信号D锁住,也就是稳定住,这段时间就是数据信号经过的那几个反相器和一个传输门的总延迟,被定义为建立时间。
保持时间的定义:输入信号在时钟有效沿到来之后要保持稳定的最短时间。时钟信号到从锁存器之前,数据信号要在时钟信号到达之前在即将打开的传输门的输入端保持稳定,这段时间就是从锁存器的数据端那个反相器的延迟减去时钟的反相器延迟,被定义为保持时间。 - 建立时间和保持时间相关的因素:就是触发器内部传输门和反相器的延时,具体来说主要是触发器本身的结构、工艺
- 建立时间的约束: t c l k ≥ t s e t u p + t c 2 q + t l o g i c , m a x − t s k e w + 2 t j i t t e r t_{clk}≥t_{setup}+t_{c2q}+t_{logic,max}-t_{skew}+2t_{jitter} tclk≥tsetup+tc2q+tlogic,max−tskew+2tjitter
保持时间的约束: t h o l d + t s k e w + 2 t j i t t e r ≤ t l o g i c , m i n + t c 2 q t_{hold}+t_{skew}+2t_{jitter}≤t_{logic,min}+t_{c2q} thold+tskew+2tjitter≤tlogic,min+tc2q
其中 t c 2 q t_{c2q} tc2q指clk达到触发器与数据从Q端输出之间的传输延时;clock skew指的是时钟到达不同的触发器的时间差;clock jitter是实际时钟相比于理想时钟达到某个触发器的延迟。 - 建立时间违例的解决方法:降低时钟频率;换用更快的触发器让 t c 2 q t_{c2q} tc2q减小;采用正的clock skew;降低组合逻辑的最大路径延时,比如中间加一级触发器把组合逻辑的延时一分为二
保持时间违例的解决方法:减小clock skew,或者用负skew;增大组合逻辑的最小路径延时,比如加buffer;插入低电平有效的锁存器,高电平期间锁存器输出保持不变,相当于把数据多保持了半个时钟周期
4.3 时钟偏差skew和时钟抖动jitter
- 什么是时钟偏差clock skew和时钟抖动jitter:时钟偏差skew是对于不同的寄存器而言的,指同一个时钟到不同寄存器的时间差,也就是时钟从前级到后级的传播延迟。时钟抖动jitter是对于某一个寄存器而言的,每次时钟沿到达寄存器的时钟周期不是绝对理想的,会有波动。
- 为什么会产生它们:这两个是时钟的不理想性,比如时钟信号发生器因为供电电源等原因,本身产生时钟的时候没法保证每个时钟周期是绝对理想,固定不变的,会引起时钟抖动jitter;还有因为工艺上前后级的互连线的延时无法忽略,引起时钟偏差skew;温度变化也可能会引起时钟偏差skew。
4.4 复位
异步复位和同步复位的区别是什么,优缺点是什么,如何在复位阶段避免亚稳态的产生
- 同步复位:优点:可以使所设计的系统成为100%的同步时序电路,有利于时序分析和仿真器的仿真;因为同步复位只效时钟沿有效,可以滤除复位信号上高于时钟频率的毛刺。缺点:复位信号的有效时长必须大于时钟周期,才能保证在时钟沿被识别并且复位,还要考虑时钟偏移skew、组合逻辑路径延时、复位延时等因素。并且由于大多器件库里的触发器都只有异步复位,如果用同步复位,需要在数据输入端再加一个与门,让同步复位信号和数据信号相与的结果送到触发器的输入端,会耗费较多的电路资源
- 异步复位:优点:不用考虑复位有效时长的问题,设计相对简单;由于大多器件库里的触发器都有异步复位端口,可以节约资源;缺点:复位信号容易受到毛刺的影响;复位释放时如果刚好在时钟有效沿附近,容易受亚稳态影响,导致应该释放时无法确定现在的复位信号电平是1还是0
- 异步复位需要注意:输入端需滤除毛刺并做抗干扰处理(使用专用的异步复位IO),放置干扰;需要同步释放,防止亚稳态的出现
- 异步复位,同步释放:
4.5 跨时钟域
什么情况算跨时钟域,什么情况不算跨时钟域,什么情况下可以不处理,常见的跨时钟域方法有哪些,快到慢,慢到快,多bit,单bit这些分别应该怎么处理
- 跨时钟域是什么:比如总线信号和从机的信号在不同的时钟频率下工作,其中的数据信号传输就需要进行跨时钟域处理,因为不同时钟域下数据信号的频率和相位不一样,如果不处理直接传会导致建立时间与保持时间违例,有数据丢失,或者产生亚稳态。
- 跨时钟域同步方法:
单比特:(1)如果是慢时钟域到快时钟域,用两级触发器来同步。如果在第一级触发器亚稳态维持了超过一个周期,到第二级可能会稳定下来,因为亚稳态的时间一般不超过一个周期,两级同步器的稳定概率更大。如果两级不够,也可以再多加几级。不过这有一种可能是跨时钟采样失败,比如输入信号由0变到1之间的亚稳态从第一级传到了第二级,第二级时钟有效沿到来时可能捕捉到的电平刚好被判定为0,就是在第二级逻辑误判了。不过这种起码不会造成亚稳态往后级传播。对于逻辑误判的话,就可以在设计层面来降低误判的概率,比如说格雷码计数器,通过格雷码的相邻码只有1比特跳转的特性来降低误码率。(2)如果是快时钟域到慢时钟域同步,且数据信号只有快时钟域的一个周期,在慢时钟域可能会捕捉不到数据信号,可以用握手协议来处理:先在快时钟域对数据信号进行展宽,产生request信号 -> 经过慢时钟域的两个周期,在两级触发器同步后,得到慢时钟域的request_sync信号 -> 取慢时钟域request_sync信号上升沿之后的一个周期,拉高data_out -> 之后把慢时钟域request_sync信号再用两级触发器传回快时钟域,在快时钟域发出一个acknowledge信号 -> ack信号的下一个上升沿快时钟域把request信号拉低,握手结束。
多比特:(1)对于非连续信号,并且数据变化速率低于接收时钟,可以用握手协议。(2)如果是连续信号或者数据变化较快的非连续信号,就用异步FIFO和格雷码转换,通过格雷码相邻码只有1位变化的特性,把多比特当做一个序列,转换为格雷码,XXXXXXX: - 两拍同步和三拍同步的差异:
- FIFO内数据如何保证绝对稳定:
4.6 同步FIFO和异步FIFO
-
FIFO的作用,什么时候需要FIFO:(1)写数据频率快的时候做数据缓冲:当写数据的频率较快,或者突发写入时,而读数据的频率相对较低时,通过使用一定深度的FIFO,可以起到数据缓冲、暂存的功能。(2)数据传输频率不一样,比如跨时钟域传输时:主要是用异步FIFO,可以对不同时钟域的信号进行同步,并通过格雷码来降低多比特跨时钟域传输时发生亚稳态的概率。(3)数据宽度不一样时的传输,比如一个是8位的IP,总线上是16位的,就可以用一个FIFOXXXX
-
FIFO空满标志的生成:在读写指针多加一位MSB作为折回标志位,每次读写指针越过最后一个FIFO地址时,就对MSB加1,其他位归0。对于二进制码,如果读写指针的其余位相等就判断空满:MSB折回标志位相同说明读写指针折回次数相等,FIFO为空;MSB标志位不同说明写指针比读指针多折回一次,FIFO为满。对于格雷码,FIFO空的判断还是一样:读写指针完全相等;FIFO满是读写指针的高两位相反&其余位相等(原因:比如一个深度为8的FIFO,读写指针一共4位(3+1),假设读指针一直不动是0000,写指针写了8个,即跳了8次(0->8),FIFO满,格雷码是1100,和读指针0000相比较就是高两位相反&其余位相等)。
-
同步FIFO:读时钟和写时钟是一个时钟。包括读写指针的逻辑、读写数据的逻辑、计数器的逻辑和空满逻辑。读写指针和读写数据的逻辑(读使能且FIFO非空 -> 读指针+1,读指针对应的mem赋值给data_out,写使能且FIFO非满 -> 写指针+1,data_in赋值给写指针对应的mem);计数器的逻辑(读使能且FIFO非空 -> 计数器+1,写使能且FIFO非满 -> 计数器-1);空满逻辑(计数器=0就是空;计数器=FIFO深度就是慢)
-
异步FIFO:读时钟和写时钟在不同的时钟域里,常用来作不同时钟域同步时数据传输的缓冲区。包括读写控制模块、两个同步模块、和一个双端口RAM。读写控制模块里把读写指针的二进制码转换成格雷码,之后输出到两个同步模块里,用两级触发器来做同步,并且进行空满逻辑判断,把读指针同步到写指针的时钟域来判断FIFO满标志;把写指针同步到读时钟域来判断空标志。具体的读写数据就是通过双端口RAM进行的,实际的memory地址是二进制码进行读写。

-
假空和假满:假空是因为一开始FIFO是空的,并且检测到读写指针完全相等,但是紧接着来了写操作,FIFO中有了新数据,由于同步模块的滞后性,同步到读时钟域的写地址没有及时更新,读时钟域还是产生了空信号,就是假空;类似的假满是一开始FIFO是满的,但是紧接着来了读操作,FIFO实际上非满但因为同步模块的延迟产生了满信号。(假空和假满相当于提前一点告诉FIFO是空或者满了,不会产生错误,但是会对FIFO的性能有一点点影响,相当于少了一个。)
-
假设写时钟比读时钟快,那么当读地址+1,再同步到写时钟后,如果这期间有了写push操作,那会不会导致写指针超过读指针,造成FIFO溢出呢? 不会。这个讨论的是边界情况。比如读指针+1传过去之前,如果写指针已经等于读指针-1,那么满信号已经是1了,也就是假满,这时候来了写操作,FIFO也不允许往里写。
-
异步FIFO为什么需要格雷码,不直接用二进制码? 比如在多比特跨时钟域时,如果是用二进制码,跨时钟域时,在一个时钟沿会有多个bit同时翻转,在另外一个时钟域采到的时候由于两级触发器稳定需要1个或者2个周期,多个bit同时翻转可能会出现误码,而格雷码的特性是相邻码只有一位变化,多比特跨时钟域时传输结果要么是保持上一个数据,要么是当前的正确数据。所以异步FIFO需要一个二进制码到格雷码的转换电路,先在原时钟域把地址转换成格雷码,然后把这个格雷码同步到另一个时钟域,做空满状态的检测(把读指针同步到写指针来判断满状态,写指针同步到读指针来判断空状态)
-
异步FIFO是否可能读指针比写指针多折回一次? 不可能,因为假设读指针多折回一次,说明读的次数比写的次数多了一轮,但是如果没有数据(也就是FIFO为空的情况),是不会继续往外读的,读指针就不会动,不会出现读指针比写指针甚至还多折回了一次的情况
-
为什么异步FIFO是读指针同步到写指针来判断满,写指针同步到读指针来判断空,不能反过来? 因为在读时钟域,FIFO空不空是关键,因为空的时候不能往外读;在写时钟域,FIFO满不满是关键,因为满的时候不能往里写。而跨时钟域同步的时候,同步模块是会有延迟的,所以要在读时钟域这边判断FIFO是否空,写时钟域判断FIFO是否满。假设是在读时钟域来判断满,刚刚写指针同步过来的时候现在判断到FIFO满了,但是在这中间的延迟的一段时间里,可能写时钟域又来了个写操作,但读时钟域这边因为延迟,实际的满标志还没更新,写时钟域不知道满了,又往里写了一个,就会造成写溢出。所以这个判断不能反过来。
-
读写时钟频率相差较大时,是否会造成multi-bit的问题(慢时钟域同步快时钟域时,在慢时钟域的一个周期中,经历了两次或多次快时钟域的上升沿,那么对应的格雷码就会有两个或多个bits发生变化,这个不会产生多个bits同步的问题吗):不会,虽然慢时钟域同步过来的最终数据和之前的数据有多bit的变化,但这些多bit的翻转在快时钟域不是同时发生的。一般说的单bit还是多bit发生变化是针对每一个(源时钟域的)时钟沿而言的,而虽然多次时钟沿之后,格雷码的最后一个时钟沿的变化结果和第一次时钟沿相比有多bit的变化,但是对于每次时钟沿,格雷码还是最多只有1bit的变化,最终同步触发器输出要么是保持前一个值,要么是更新后的值,这两个值都是合理的,不会导致FIFO空满逻辑判断错误。总结来说,慢时钟采快时钟会出现漏采,但是不会导致功能错误(比如溢出或underflow),不过空满信号的判断会更保守,FIFO的效率会降低。
-
Memory的取址用格雷码吗? Memory的取址用二进制码,要同步指针才把二进制码转成格雷码,同步过去之后直接通过格雷码来判断空满。
-
如何设计一个深度不是2的幂次的FIFO? 利用格雷码的对称性,也就是格雷码从全0开始写,第N位从0变成1时,之后的数的N-1位会关于前半段轴对称,比N位高的还是不变。比如说要设计一个深度为n的FIFO,需要用[log2(n)]+1位格雷码(比如深度为5,需要用4位格雷码)利用4位格雷码一共16个码字的对称轴往0000的方向取5个作为指针编码,再加上第5个关于对称轴对称的码字,也就是MSB改成1的码字。
-
空满标志位的设置set和清空clear分别有多少延迟? 空满的set是立即生效的,比如在写时钟域判断满,把读指针的格雷码同步过来与写指针判断,判断之后立即更新满标志。但空满的clear是有两个周期的延迟,因为两级同步器是延迟两个周期:当空标志=1时,读时钟域采样到的写指针和读指针相同,如果现在写时钟域来了一个写操作,这个写操作需要经过两级同步器才能被读时钟域看到,再更新空标志,所以空标志的clear会有两个读时钟周期的延迟;而满标志的clear会有两个写时钟周期的延迟。
-
快时钟域同步慢时钟域时,在快时钟域会否引起写溢出(full+1)或者读溢出(emtpy+1)? 不会。核心点在于满判断是在写时钟域,空判断是在读时钟域,而不是反过来。对于写溢出的讨论,也就是写时钟比读时钟快,边界情况是full-1,full和full+1,假设现在full-1,要写数据,判断到当前没有满,所以可以往里写,但是此时下一次判断是同步了慢时钟域的读时钟,读指针会有延迟,同步过来的读指针最多会比实际的更小,或者相等,在写时钟域判断的满其实是更保守的满,而写时钟更快,只要追上了保守的读指针,就会标志到full,不允许再写了,更不会出现继续出现full+1的情况。但是如果满判断是在读时钟域,那么假设写时钟更快,在读时钟域看到的写指针比实际的更小,也就是实际的写指针比同步过来的更大,就会因为同步的延迟导致满判断的延迟,产生写溢出。
-
**复位信号会导致读写指针复位时产生multi-bit同步的问题吗?**不会,因为一般是读写指针分别有一个复位信号,在本时钟域进行复位操作,不需要多比特跨时钟域再复位。(如果只有一个时钟域有复位信号,就应该把复位信号打两拍同步过去,再对另一个时钟域的读写指针复位,而不是把读写指针同步过来,再复位完又同步回去)
5 计算机体系架构/SOC
流水线的好处,流水线带来什么问题,如何解决,cache的作用
5.1 CPU的基本结构
- 主要分为控制单元、ALU、存储单元。
控制单元首先从存储器取出各种指令,放在指令寄存器IR里,之后做指令译码来分析要做什么操作。 ALU做算术运算(加减乘等)和逻辑运算(移位等),ALU是接收控制单元的command来运算的。存储单元有缓存和寄存器组,里面保存一些等待处理的数据,还有ALU的运算结果。
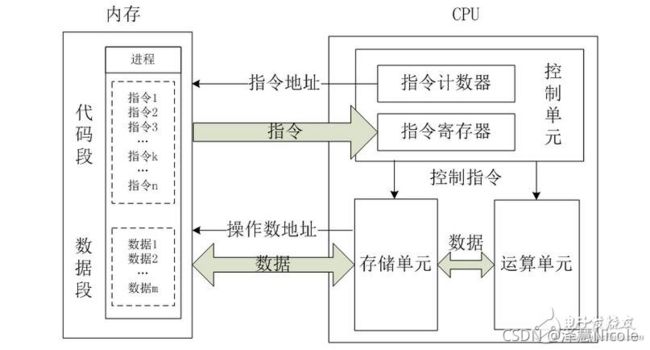
- 运行过程:
IF:取指令,CPU的控制器从内存读取一条指令并放入指令寄存器。指令的格式一般是操作码和操作数的地址组成
ID:指令译码:指令寄存器中的指令经过译码,决定该指令应进行何种操作(就是指令里的操作码)、操作数在哪里(操作数的地址)
OF:取操作数
EX:执行指令,进行运算
修改指令计数器,决定下一个指令的地址
5.2 Cache的作用
5.3 AMBA总线协议
他们的特性,应用于什么场景,有什么特点,有什么区别,为什么能够应用于这种场景,什么是outstanding,什么是out of order,什么是interleaving,如何握手,突发有什么特点,总线的流水线是什么意思
- AHB和APB
- 总线握手
5.4 FPGA的基本结构
FPGA是可编程逻辑单元,有
- 可编程的IO单元
- 可编程的逻辑单元:LUT和寄存器构成,通过LUT来实现组合逻辑
- 布线资源:包括(全局性的)专用布线资源、长线资源、短线资源等
- 嵌入式RAM:可以配置为单端口RAM,双端口RAM,CAM,FIFO等
- 底层嵌入式功能单元:如DSP、PLL等
- 内嵌专用硬核:(不是每个FPGA都有)通用性较弱的硬核
5.5 通信协议
- UART:(异步全双工)接口信号有TX和RX,TX用于发送数据,RX用于接收数据。数据传输前,发送端和接收端都要设置一样的波特率。传输时,发送端先发出一个0表示起始位,后面跟着数据位,数据位的最后有一个奇偶校验位,最后有高电平的停止位(可以是1/1.5/2位),空闲位是1,表示没有数据传输。
- SPI:(同步全双工)是一个主设备对应多个从设备。接口有CS(片选信号,用来选定通信的从设备),SDI(数据输入),SDO(数据输出),SCLK(时钟信号)。提供SCLK串行时钟的是主设备,剩下的是从设备。先用CS片选信号来选定从设备,通信时数据在时钟的上升或者下降沿由发送端的SDO输出,在紧接着的时钟沿(下降或者上升沿)由接收端的SDI读入,完成一位数据的传输。(一位一位传的)
SPI全双工时,高位在前先传,低位在后 - IIC:(同步半双工)只有一个时钟线SCL和一个数据线SDA。比如A给B发数据,二者的时钟线和数据线要对应接好,最开始时钟线和数据线上的电平都是高电平,然后A发送端先把数据线拉低,等到数据线变成低电平后,再把SCL拉低(这两个动作构成了通信的起始信号),之后数据线SDA就可以发送数据了,同时时钟线发送脉冲,并且时钟线会在上升沿对数据线进行采样,所以数据线必须在时钟线是高电平时保持有效,在低电平时发送下一个数据。
IIC规定一次传8位数据,数据传输结束后发送端释放SDA,时钟线要再发一个脉冲(第九个脉冲),来触发接收端拉低数据线,表示确认(ACK信号)。最后时钟线先变成高电平,数据线再变成高电平(这两个动作是结束标志)。
如果接收端没有把数据线拉低,发送端会停止发送下一帧数据。IIC总线上每个设备都有唯一的IIC地址,数据包传输时要先发送地址位,再发数据。一个地址字节由7个地址位(可以挂128个设备)+1个指示位组成(0表示写,1表示读)
5.6 DMA
DMA(Direct Memory Access,直接存储器访问),在实现DMA传输时,不需要通过CPU调度,是由DMA直接控制总线。即DMA传输前,CPU要把总线控制权交给DMA控制器,而在结束DMA传输后,DMA控制器应立即把总线控制权再交回给CPU。一个完整的DMA传输过程必须经过DMA请求、DMA响应、DMA传输、DMA结束4个步骤。
- 请求:CPU对DMA控制器初始化,并向I/O接口发出操作命令,I/O接口提出DMA请求。
- 响应:DMA控制器对DMA请求判别优先级及屏蔽,向总线裁决逻辑提出总线请求。当CPU执行完当前总线周期即可释放总线控制权。此时,总线裁决逻辑输出总线应答,表示DMA已经响应,通过DMA控制器通知I/O接口开始DMA传输。
- 传输:DMA控制器获得总线控制权后,CPU即刻挂起或只执行内部操作,由DMA控制器输出读写命令,直接控制RAM与I/O接口进行DMA传输。
在DMA控制器的控制下,在存储器和外部设备之间直接进行数据传送,在传送过程中不需要中央处理器的参与。开始时需提供要传送的数据的起始位置和数据长度。 - 结束:当完成规定的成批数据传送后,DMA控制器即释放总线控制权,并向I/O接口发出结束信号。当I/O接口收到结束信号后,一方面停 止I/O设备的工作,另一方面向CPU提出中断请求,使CPU从不介入的状态解脱,并执行一段检查本次DMA传输操作正确性的代码。最后,带着本次操作结果及状态继续执行原来的程序。
DMA传输方式无需CPU直接控制传输,通过硬件为RAM与I/O设备开辟一条直接传送数据的通路,使CPU的效率大为提高。
5.7 流水线Pipeline
https://blog.csdn.net/weixin_41832850/article/details/98856042
6 低功耗
- 功耗的组成:动态功耗有switching power翻转功耗(充放电电容引起的。和负载电容、电压、01翻转的频率、时钟频率有关)、short circuit power短路功耗(瞬时的短路引起的,比如说反相器,输入信号翻转时,中间会有很短的时间PMOS和NMOS同时导通,形成短路电流。和电压、MOS管的阈值电压、01翻转的频率有关);静态功耗是因为漏电流引起的,包括subthreshold leakage亚阈值漏电流(亚阈值状态下MOS管的漏电流)、Gate leakage栅极漏电流(因为工艺方面,栅极不是完全绝缘的,从栅极到衬底有一部分漏电流)、Bias junction leakage反向偏置结漏电流(是MOS管理少数载流子漂移运动形成的反向偏置结导致的电流)
- 各部分功耗的降低方法:动态功耗里,switching power翻转功耗(降低电压、降低01翻转的频率、降低时钟频率减小负载电容)、短路功耗(降低电压、降低01翻转的频率、降低时钟频率、选用阈值电压更大的MOS管)
7 其他
7.1 Python
- numpy和pandas
7.2 Matlab
- 常用库函数
7.3 C
- 指针:指向变量的地址,比如int* p = &a。指针本身的类型是int*,指向的是a的地址。二级指针是指向指针的指针,int** p2 = &p。二级指针本身的类型是int**,指向的是p的地址。
- struct和union:
(1)struct结构体是一个集合,里面可以包含各种不同类型的变量或数组.
(2)union联合体是
(3)区别:struct的各个成员会占用不同的内存,互相之间没有影响,它占用的内存大于等于所有成员占用的内存总和(成员之间可能会有缝隙);union的所有成员共占一段内存,同一时刻只能保存一个成员的值,如果对新的成员赋值会把旧的值覆盖掉,所以修改一个成员会影响其余所有成员,它占用的内存等于最长的成员占用的内存。
7.4 C++
- vector:
7.4 卷积神经网络
卷积神经网络
2. 什么是神经网络
3. 什么是卷积神经网络:图像输入 -> 提取特征 -> 卷积 -> 池化 -> 激活函数(sigmoid, tanh, relu) -> 深度神经网络 -> 全连接层 -> 卷积神经网络 -> 常见几种卷积神经网络(LeNet, AlexNet, VGGNet, ResNet)