基于LightGBM分类实现英雄联盟数据预测(二)
基于LightGBM分类实现英雄联盟数据预测(二)
这里写目录标题
- 基于LightGBM分类实现英雄联盟数据预测(二)
-
-
- Step5:利用 LightGBM 进行训练与预测
-
plt.figure(figsize=(18,14))
#cmap即colormaps 获取图谱使用plt.get_cmap(‘xxx’) 其值有很多,
#如官网:https://matplotlib.org/users/colormaps.html 或https://matplotlib.org/examples/color/colormaps_reference.html
sns.heatmap(round(x.corr(),2), cmap='Greys', annot=True)
plt.show()

同时我们画出各个特征之间的相关性热力图,颜色越深代表特征之间相关性越强,我们剔除那些相关性较强的冗余特征。
# 去除冗余特征
drop_cols = ['redAvgLevel','blueAvgLevel']
x.drop(drop_cols, axis=1, inplace=True)
sns.set(style='whitegrid', palette='muted')
# 构造两个新特征
x['wardsPlacedDiff'] = x['blueWardsPlaced'] - x['redWardsPlaced']
x['wardsDestroyedDiff'] = x['blueWardsDestroyed'] - x['redWardsDestroyed']
data = x[['blueWardsPlaced','blueWardsDestroyed','wardsPlacedDiff','wardsDestroyedDiff']].sample(1000)
data_std = (data - data.mean()) / data.std()
data = pd.concat([y, data_std], axis=1)
data = pd.melt(data, id_vars='blueWins', var_name='Features', value_name='Values')
plt.figure(figsize=(10,6))
sns.swarmplot(x='Features', y='Values', hue='blueWins', data=data)
plt.xticks(rotation=45)
plt.show()

我们画出了插眼数量的散点图,发现不存在插眼数量与游戏胜负间的显著规律。猜测由于钻石分段以上在哪插眼在哪好排眼都是套路,所以数据中前十分钟插眼数拔眼数对游戏的影响不大。所以我们暂时先把这些特征去掉。
## 去除和眼位相关的特征
drop_cols = ['blueWardsPlaced','blueWardsDestroyed','wardsPlacedDiff',
'wardsDestroyedDiff','redWardsPlaced','redWardsDestroyed']
x.drop(drop_cols, axis=1, inplace=True)
x['killsDiff'] = x['blueKills'] - x['blueDeaths']
x['assistsDiff'] = x['blueAssists'] - x['redAssists']
x[['blueKills','blueDeaths','blueAssists','killsDiff','assistsDiff','redAssists']].hist(figsize=(12,10), bins=20)
plt.show()

我们发现击杀、死亡与助攻数的数据分布差别不大。但是击杀减去死亡、助攻减去死亡的分布与原分布差别很大,因此我们新构造这么两个特征。
data = x[['blueKills','blueDeaths','blueAssists','killsDiff','assistsDiff','redAssists']].sample(1000)
data_std = (data - data.mean()) / data.std()
data = pd.concat([y, data_std], axis=1)
data = pd.melt(data, id_vars='blueWins', var_name='Features', value_name='Values')
plt.figure(figsize=(10,6))
sns.swarmplot(x='Features', y='Values', hue='blueWins', data=data)
plt.xticks(rotation=45)
plt.show()

一些特征两两组合后对于数据的划分能力也有提升。
x['dragonsDiff'] = x['blueDragons'] - x['redDragons']
x['heraldsDiff'] = x['blueHeralds'] - x['redHeralds']
x['eliteDiff'] = x['blueEliteMonsters'] - x['redEliteMonsters']
data = pd.concat([y, x], axis=1)
eliteGroup = data.groupby(['eliteDiff'])['blueWins'].mean()
dragonGroup = data.groupby(['dragonsDiff'])['blueWins'].mean()
heraldGroup = data.groupby(['heraldsDiff'])['blueWins'].mean()
fig, ax = plt.subplots(1,3, figsize=(15,4))
eliteGroup.plot(kind='bar', ax=ax[0])
dragonGroup.plot(kind='bar', ax=ax[1])
heraldGroup.plot(kind='bar', ax=ax[2])
print(eliteGroup)
print(dragonGroup)
print(heraldGroup)
plt.show()
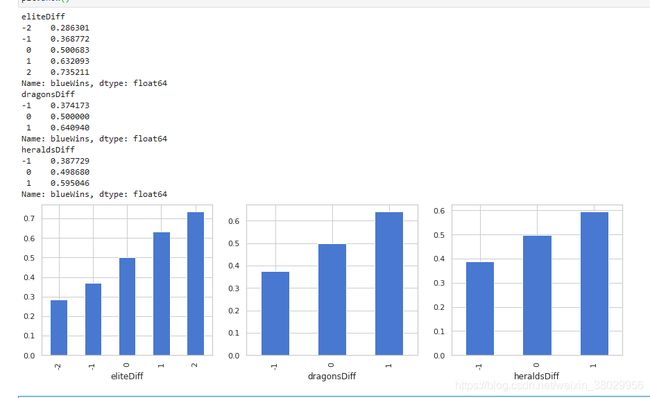
我们构造了两队之间是否拿到龙、是否拿到峡谷先锋、击杀大型野怪的数量差值,发现在游戏的前期拿到龙比拿到峡谷先锋更容易获得胜利。拿到大型野怪的数量和胜率也存在着强相关。
x['towerDiff'] = x['blueTowersDestroyed'] - x['redTowersDestroyed']
data = pd.concat([y, x], axis=1)
towerGroup = data.groupby(['towerDiff'])['blueWins']
print(towerGroup.count())
print(towerGroup.mean())
fig, ax = plt.subplots(1,2,figsize=(15,5))
towerGroup.mean().plot(kind='line', ax=ax[0])
ax[0].set_title('Proportion of Blue Wins')
ax[0].set_ylabel('Proportion')
towerGroup.count().plot(kind='line', ax=ax[1])
ax[1].set_title('Count of Towers Destroyed')
ax[1].set_ylabel('Count')

推塔是英雄联盟这个游戏的核心,因此推塔数量可能与游戏的胜负有很大关系。我们绘图发现,尽管前十分钟推掉第一座防御塔的概率很低,但是一旦某只队伍推掉第一座防御塔,获得游戏的胜率将大大增加
Step5:利用 LightGBM 进行训练与预测
## 为了正确评估模型性能,将数据划分为训练集和测试集,并在训练集上训练模型,在测试集上验证模型性能。
from sklearn.model_selection import train_test_split
## 导入LightGBM模型
from lightgbm.sklearn import LGBMClassifier
## 选择其类别为0和1的样本 (不包括类别为2的样本),因为blueWins 只有0和1
data_target_part = y
data_features_part = x
## 测试集大小为20%, 80%/20%分
x_train, x_test, y_train, y_test = train_test_split(data_features_part, data_target_part, test_size = 0.2, random_state = 2020)
## 定义 LightGBM 模型
clf = LGBMClassifier()
# 在训练集上训练LightGBM模型
clf.fit(x_train, y_train)
## 在训练集和测试集上分布利用训练好的模型进行预测
train_predict = clf.predict(x_train)
test_predict = clf.predict(x_test)
from sklearn import metrics
## 利用accuracy(准确度)【预测正确的样本数目占总预测样本数目的比例】评估模型效果
print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_train,train_predict))
print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_test,test_predict))
## 查看混淆矩阵 (预测值和真实值的各类情况统计矩阵)
confusion_matrix_result = metrics.confusion_matrix(test_predict,y_test)
print('The confusion matrix result:\n',confusion_matrix_result)
# 利用热力图对于结果进行可视化
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_matrix_result, annot=True, cmap='Blues')
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.show()