StackGAN++/StackGAN-v2论文阅读笔记
参考:
https://blog.csdn.net/Forlogen/article/details/94015212
StackGAN++是StackGAN的研究团队又提出来的一种改进版本,也叫做StackGAN-v2,StackGAN也被叫做StackGAN-v1
StackGAN++可以用于有条件和无条件的图像生成。
有条件的图像生成,就比如论文中的使用文字生成图片。
无条件的图像生成,即不加任何约束信息(作为比较,约束信息可以理解为有条件生成中的文本),类似于GAN网络中,使用噪声向量输入到网络,生成图片。

下面就分两部分介绍
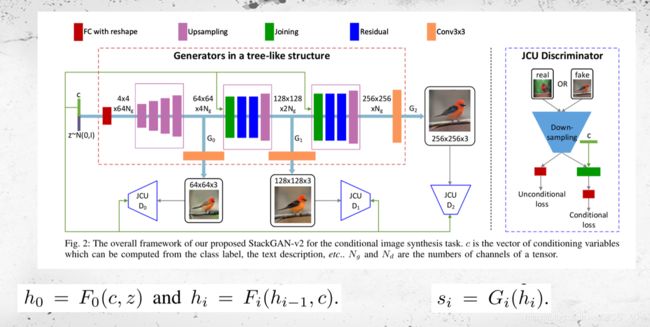

有条件的图像生成(文本生成图片)
网络结构如上图,条件信息指的是输入的文本信息,如网络结构图中的c,这里的c并不是直接的文本embedding,而是embedding经过了条件增强后,得到的向量表示。(条件增强在后面介绍)
在最初一层,网络的输入为c和噪声z,输出为![]() 。在之后每一层,输入为上一层的输出
。在之后每一层,输入为上一层的输出![]() 和c,输出为
和c,输出为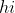 ,每一层的神经网络(包含采样、连接、残差块)用
,每一层的神经网络(包含采样、连接、残差块)用![]() 表示。具体公式如下:
表示。具体公式如下:
![]()
在每一层对数据进行![]() 操作后得到,再进入到每一层的生成器中,输出
操作后得到,再进入到每一层的生成器中,输出![]() ,每层的生成器公式如下:
,每层的生成器公式如下:
![]()
在有条件图像生成任务中,判别器不仅要对图像是否真实作出判断,同时还要对图像与文本是否符合作出判断。判断图像是否真实,输入只有噪声z,无需文本约束信息c;判断图像与文本是否符合,输入不仅要有噪声z,同时还要有文本约束信息c。所以,判别器的损失包括这两部分,具体公式如下:
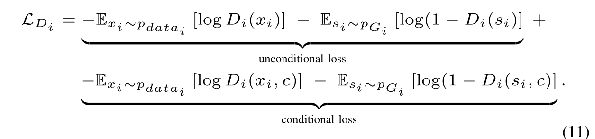
对上述公式做介绍
第一部分:图像是否真实的判断。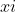 表示真实图像,来自
表示真实图像,来自![]() 分布,判别器应该识别的结果为1(表示真),
分布,判别器应该识别的结果为1(表示真),![]() 是生成图片,判别器应该识别它的结果为0(表示假)。综上,总的结果应该越小
是生成图片,判别器应该识别它的结果为0(表示假)。综上,总的结果应该越小
第二部分:图像与文本是否贴合。表示真实图像,c表示文本约束信息,组合起来可理解为真实图片和对应的真实描述,判别器对这一组合的判别结果应该为1。相应的,![]() 表示生成的图片,c表示文本约束信息,组合起来可以理解为生成的假图片与文本描述,判别器对这一组合的判别结果应该为0。综上,总的结果应该越小。
表示生成的图片,c表示文本约束信息,组合起来可以理解为生成的假图片与文本描述,判别器对这一组合的判别结果应该为0。综上,总的结果应该越小。
综合这两部分,应该最小化判别器的Loss函数。
生成器的损失函数类似于判别器,也分为两部分。使得图像尽可能的真实,且贴合文本描述。具体公式如下:
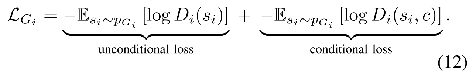
对上述公式做介绍
第一部分:使得图像尽可能真实。![]() 表示生成的图片,生成器G希望
表示生成的图片,生成器G希望![]() 尽可能的骗过判别器D,因此经判别器识别后的结果应该尽可能为1。综上,左边结果应该越小
尽可能的骗过判别器D,因此经判别器识别后的结果应该尽可能为1。综上,左边结果应该越小
第二部分:图像与文本贴合。![]() 表示生成的图片,c表示文本约束信息,这两个组合起来可以理解为生成的假图片与文本描述,生成器G希望判别器对这一组合的判别结果应该为1。综上,右边结果应该越小。
表示生成的图片,c表示文本约束信息,这两个组合起来可以理解为生成的假图片与文本描述,生成器G希望判别器对这一组合的判别结果应该为1。综上,右边结果应该越小。
综合这两部分,应该最小化生成器的Loss函数。
补充条件增强:
Conditioning Augmentation(条件增强技术)
如果直接把 φ(t) 放入生成器,这个特征空间的维度一般比较高(>100)而训练数据是有限的,所以会造成特征空间不连续,不利于生成器的训练,作者提出的Conditioning Augmenetation是从独立的高斯分布 N(μ(φt) , Σ(φt)) 中随机采样得到隐含变量,再放入生成器。其中 μ(φ(t)) 和 Σ(φ(t)) 是关于 φ(t) 的均值和方差函数。
为了增强平滑度和避免过拟合,为生成器的损失函数增加了以下的正则项


无条件的图像生成
网络结构同最上面的图
在最初一层,网络的输入为噪声z,输出为![]() 。在之后每一层,输入为上一层的输出
。在之后每一层,输入为上一层的输出![]() 和z,输出为,每一层的神经网络(包含采样、连接、残差块)用
和z,输出为,每一层的神经网络(包含采样、连接、残差块)用![]() 表示。具体公式如下:
表示。具体公式如下:

在每一层对数据进行![]() 操作后得到,再进入到每一层的生成器中,输出
操作后得到,再进入到每一层的生成器中,输出![]() ,每层的生成器公式如下:
,每层的生成器公式如下:
![]()
在有条件图像生成任务中,判别器仅要对图像是否真实作出判断=。判断图像是否真实,输入只有噪声z,无需文本约束信息c。具体公式如下:
![]()
公式解释同上面有条件的图像生成,不再赘述。应最小化判别器的Loss函数。

生成器的损失函数类似于判别器,使得图像尽可能的真实。具体公式如下:

公式解释同上面有条件的图像生成,不再赘述。应最小化生成器的Loss函数。生成器的Loss等于各阶段的Loss之和。
颜色一致性
论文中还提出了color-consistency regularization颜色一致性准则,它是指在整个图像的生成过程中,不同分辨率图像可能细节部分会有不同,但是它们在结构和颜色的基本方面应是一致的。color-consistency regularization所做的就是最小化不同分辨率图像下μ 和Σ 的差别。

因此,生成器的Loss要改变为如下形式:

要保持生成图片的真实和颜色的一致性。
论文中指出,生成器的Loss,只用在无条件图像生成中,因为在条件图像生成任务中,所附件的条件已经提供了一种很强的限制,这种低尺度下的限制就没有那么重要了。因此,论文中的数据把有条件生成中的设为了50.0,而有条件生成中的为0。

总结
整体上来说,StackGAN++做为StackGAN的改进版,它可以以端到端的方式生成更好质量的图像,而且训练过程更加稳定。但是StackGAN分阶段的训练方式收敛速度更加快,所需的GPU内存也更少。