屏蔽预训练模型的权重。 只训练最后一层的全连接的权重。_Bert模型压缩
bert模型压缩一般可以从架构改进,量化压缩和模型蒸馏三个角度考虑下面分三点来介绍工作。
架构改进
Albert
a little bert主要是嵌入层的因式分解和跨层参数共享
1、嵌入层参数因式分解
a. 从建模角度来讲,wordpiece向量应该是不依赖于当前内容的(context-independent),而transformer所学习到的表示应该是依赖内容的。所以把E和H分开可以更高效地利用参数,因为理论上存储了context信息的H要远大于E。
b. 从实践角度来讲,NLP任务中的vocab size本来就很大,如果E=H的话,模型参数量就容易很大,而且embedding在实际的训练中更新地也比较稀疏。
paper实验取的128,因为E的大小跟实验效果不是正相关关系
2、跨层参数共享
只共享feed-forward network的参数、只共享attention的参数、共享全部参数。ALBERT默认是共享全部参数的,而且跨层参数共享还让输入和输出的embedding的L2距离和余弦相似度比较更加稳定。
2、NSP任务改进-SOP
后BERT时代很多研究(XLNet、RoBERTa)都发现next sentence prediction没什么用处,所以作者也审视了一下这个问题,认为NSP之所以没用是因为这个任务不仅包含了句间关系预测,也包含了主题预测,而主题预测显然更简单些(比如一句话来自新闻财经,一句话来自文学小说),模型会倾向于通过主题的关联去预测。因此换成了SOP(sentence order prediction),预测两句话有没有被交换过顺序。
量化与蒸馏
量化 会降低模型权重的数值精度。通常情况下,使用 FP32(32 位浮点)来训练模型,然后可以将其量化为 FP16(16 位浮点),INT8(8 位整数),甚至将其量化为 INT4 或 INT1。于是模型尺寸将随之减小 2 倍、4 倍、8 倍或 32 倍。这称为 post-training quantization。
另一个选项是量化感知训练(也是较为困难和较为不成熟的)。
修剪 即从模型中删除一些不重要或不太重要的权重(有时会是神经元),从而产生稀疏的权重矩阵(或较小的图层)。甚至还有一些研究直接去除掉与 Transformer 的注意力头相对应的整个矩阵。
量化,可以使用 TensorFlow Lite(用于设备上推断的 TensorFlow 的部分)来执行。TensorFlow Lite 提供了在移动设备、嵌入式设备和 IoT 设备上转换和运行 TensorFlow 模型的工具,它支持训练后量化和量化感知训练。
模型蒸馏
基础理论
目标都是最小化student和teacher的KL divergence,不过需要有一个参数T作为平滑概率的参数
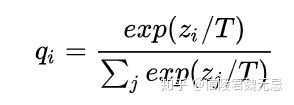
目标函数如下:
a. 只使用soft targets:在蒸馏时teacher使用新的softmax产生soft targets;student使用新的softmax在transfer set上学习,和teacher使用相同的T。
b. 同时使用sotf和hard targets:student的目标函数是hard target和soft target目标函数的加权平均,使用hard target时T=1,soft target时T和teacher的一样。Hinton的经验是给hard target的权重小一点。另外要注意的是,因为在求梯度(导数)时新的目标函数会导致梯度是以前的 ,所以要再乘上 ,不然T变了的话hard target不减小(T=1),但soft target会变。
c. 直接用logits的MSE
下面讲两篇论文
TinyBert ICLR2020
目标跟其他的distillation bert一样,都是减少transformer的层数以及hidden size的大小。
模型大小减少1/7,速度提高九倍,性能没有明显下降。
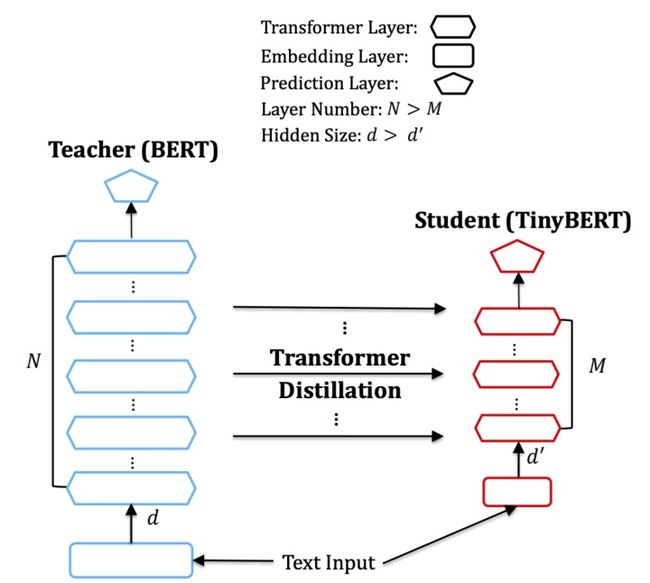
分为三个层次的distillation,分别是
1. Embedding-layer Distillation
目标是减小teacher和student的嵌入层的MSE,但是他们的维度d是不一样的,所以要经过一个线性转换W,讲student的embedding转换到teacher embedding空间里面去之后计算MSE,loss表达为

2. Transformer-layer Distillation
tiny-bert采用的是k层蒸馏的方式,如果teacher BERT 一共有 12 层,若是设置 student BERT 为 4 层,就是每隔 3 层计算一个 transformer loss。student 第 1 层 transformer 对应 teacher 第 3 层,第 2 层对应第 6 层,第 3 层对应第 9 层,第 4 层对应第 12 层。每一层的 transformer loss 又分为两部分组成,attention based distillation 和 hidden states based distillation。
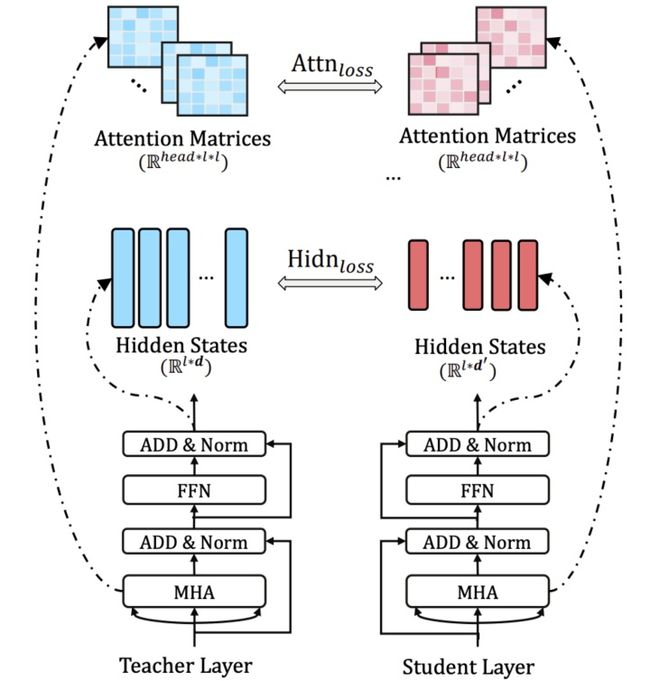
2.1 Attention based loss
这个 loss 是受到斯坦福和 Facebook 联合发表的论文,What Does BERT Look At? An Analysis of BERT’s Attention 的启发。这篇论文研究了 attention 权重到底学到了什么,实验发现与语义还有语法相关的词比如第一个动词宾语,第一个介词宾语,以及[CLS], [SEP], 逗号等 token,有很高的注意力权重。为了确保这部分信息能被 student 网络学到,TinyBERT 在 loss 设计中加上了 student 和 teacher 的 attention matrix 的 MSE。
loss是多个头注意力矩阵的平均。
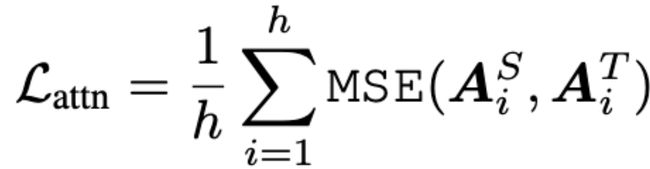
2.2 hidden states based distillation
student transformer 和 teacher transformer 的隐层输出,这里不需要像attention loss那样平均多个头了,因为是多个头输出结果的loss了,同样用Wh把student的embedding投影到teacher的embedding空间计算mse
3. Prediction-Layer Distillation
计算了 teacher 输出的概率分布和 student 输出的概率分布的 softmax 交叉熵。这一层的实现和具体任务相关,我们的两个实验分别采取了 BERT 原生的 masked language model loss + next sentence loss 和单任务的 classification softmax cross-entropy.
在 TinyBERT 中,这个 loss 是 teacher BERT 预测的概率和 student BERT 预测概率的 softmax 交叉熵,在 BERT-PKD 模型中,这个 loss 是 teacher BERT 和 student BERT 的交叉熵和 student BERT 和 hard target( one-hot)的交叉熵的加权平均。
最后的loss
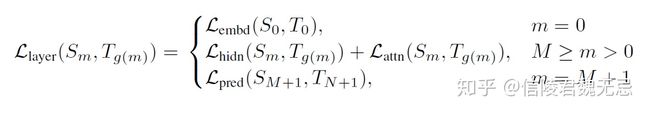
实验来说是先进行intermediate layer的distillation(0<=m<=M),然后进行prediction layer的distillation(m = M+1)
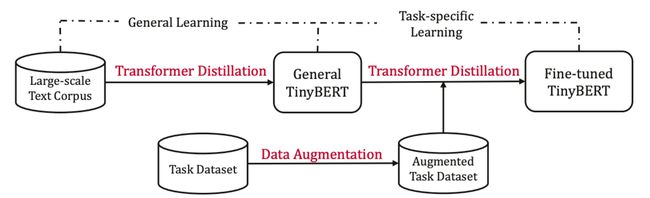
4.两阶段蒸馏
1、大规模预训练数据上蒸馏出来一个student,不过这种general的蒸馏对下游任务影响较小
2、task data上finetune bert,student用1蒸馏出来的参数初始化,再进行蒸馏得到task-specific student
Fast-Bert ACL2020
目标在于减少inference的时间,砍掉一些置信度高的样本,这个貌似CV里面就有
就是在每层Transformer后都去预测样本标签,如果某样本预测结果的置信度很高,就不用继续计算了。论文把这个逻辑称为样本自适应机制(Sample-wise adaptive mechanism),就是自适应调整每个样本的计算量,容易的样本通过一两层就可以预测出来,较难的样本则需要走完全程。
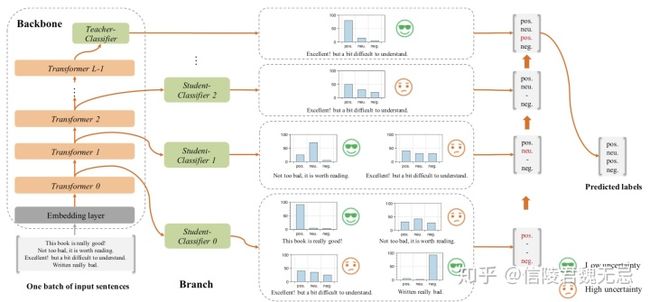
这里的分支Classifier都是最后一层的分类器蒸馏来的,作者将这称为自蒸馏(Self-distillation)。就是在预训练和精调阶段都只更新主干参数,精调完后freeze主干参数,用分支分类器(图中的student)蒸馏主干分类器(图中的teacher)的概率分布。
之所以叫自蒸馏,是因为之前的蒸馏都是用两个模型去做,一个模型学习另一个模型的知识,而FastBERT是自己(分支)蒸馏自己(主干)的知识。值得注意的是,蒸馏时需要freeze主干部分,保证pretrain和finetune阶段学习的知识不被影响,仅用brach 来尽可能的拟合teacher的分布。
可以看到,非蒸馏的结果没有蒸馏要好。个人认为是合理的,因为这两种方式在精调阶段的目标不一样。非自蒸馏是在精调阶段训练所有分类器,目标函数有所改变,迫使前几层编码器抽取更多的任务feature。但BERT强大的能力与网络深度的相关性很大,所以过早地判断不一定准确,致使效果下降。
同时,自蒸馏还有一点重要的好处,就是不再依赖于标注数据。蒸馏的效果可以通过源源不断的无标签数据来提升。
了解模型结构之后,训练与推理也就很自然了。只比普通的BERT模型多了自蒸馏这个步骤:
分为如下几个阶段:
Pre-training:同BERT系模型是一样的,网上那么多开源的模型也可以随意拿来~
Fine-tuning for Backbone:主干精调,也就是给BERT最后一层加上分类器,用任务数据训练,这里也用不到分支分类器,可以尽情地优化
Self-distillation for branch:分支自蒸馏,用无标签任务数据就可以,将主干分类器预测的概率分布蒸馏给分支分类器。这里使用KL散度衡量分布距离,loss是所有分支分类器与主干分类器的KL散度之和
Adaptive inference:自适应推理,及根据分支分类器的结果对样本进行层层过滤,简单的直接给结果,困难的继续预测。这里用熵衡量不确定性,N是class数量
