Few-shot Object Detection via Feature Reweighting论文学习以及复现
复现Few-shot Object Detection via Feature Reweighting论文代码
- 写在前面
- 本电脑配置
- 环境配置
-
- Prepare dataset
- Base Training
-
- Train The Model
- Evaluate the Model
写在前面
最近在看Few-shot Object Detection的开篇之作,看完论文后,打算先开始复现论文代码,跑跑看。
论文: link.
代码: link.
看完一遍论文后感觉似懂非懂,只了解了大概的框架,做了一些注释,后面需要再仔细看几遍。
以下记录我配置环境的过程以及其中遇到的问题:(这篇文章记录了我配置环境的过程,感觉比较啰嗦,我整理一个配置环境的简洁版本以及如何跑自己的数据集,见:Few-shot Object Detection via Feature Reweighting跑自己的数据集.)
本电脑配置
ubantu20.04,使用专业版pycharm(2021.3.1)软件(也可以在终端操作)配置
环境配置
作者的代码是基于 https://github.com/marvis/pytorch-yolo2 并使用 Python 2.7 和 PyTorch 0.3.1 开发的。一开始看到python2.7有点蒙,现在好像python3使用比较多?一开始走了一段弯路,我配置环境经常使用Anaconda(Anaconda则是一个打包的集合,里面预装好了conda、某个版本的python、众多packages、科学计算工具等等,所以也称为Python的一种发行版。)配置,用来比较方便,查阅资料可知(link),Anacona2.xxx对应python2.7.xxx版本,Anaconda3.xxx对应python3.xxx,于是我尝试同时安装两个版本的Anaconda的,找到一篇博客(基于Windows下)把Anaconda2安装在Anaconda3的安装路径下(link),着在ubantu上试一试,结果从官网下载Anaconda2太慢了,我打开pycharm看了一会发现好像可以选择python2.7的解释器?!?!,创建基于python2.7的解释器(自动创建了虚拟环境)后,继续下一步。

从代码链接下载代码后,查看requirements.txt文件
# -*- coding: utf-8 -*-
https://download.pytorch.org/whl/cpu/torch-0.3.1-cp27-cp27mu-linux_x86_64.whl ; sys_platform == "linux2"
torchvision == 0.2.2
future
easydict
numpy
opencv-python == 3.4.2
发现有个sys_platform == “linux2”,我查了下表示是表示操作系统,链接,大概的意思就是以前的版本区分linux2和linux3,后来改版后不区分了,变为linux,我查看了下我的(pycharm控制台输入sys.paltform)一开始是linux,然后我安装torch-0.3.1-cp27-cp27mu-linux_x86_64.whl 这个的时候显示平台不支持,没办法只能查资料看怎么解决,尝试能不能改为linux2,搜了好久都没有找到相关的资料,就先搁置了。
第二天,我发现又可以了,直接执行pip install -r requirements.txt比较顺利,只是该了一个地方:显示requirements.txt中opencv版本不匹配,没有3.4.2,只有3.4.2.16/17,我修改equirements.txt中opencv版本为3.4.2.16后,再执行pip install -r requirements.txt,没有报错,基本成功了,我输入sys.platform,发现变为linux2了(比较疑惑…,算了接着弄后面吧)。 总的来说,我整理了下思路步骤:
总的来说,我整理了下思路步骤:
(1)在pycharm中先创建基于python2.7的解释器(虚拟环境)
(2)执行requirements.txt
(3)如果遇到opencv版本不匹配的问题,如它报错显示只有3.4.2.16/17之类的,那就想修改requirements.txt的opencv版本为3.4.2.16/17,再执行requirements.txt
#执行Readme
接下来按照Readme的步骤执行:
Prepare dataset
执行
wget https://pjreddie.com/media/files/VOCtrainval_11-May-2012.tar
wget https://pjreddie.com/media/files/VOCtrainval_06-Nov-2007.tar
wget https://pjreddie.com/media/files/VOCtest_06-Nov-2007.tar
我下载后,执行解压命令时,解压失败,然后我手动解压,接着执行
wget http://pjreddie.com/media/files/voc_label.py
python voc_label.py
执行python voc_label.py 显示文件找不到,然后我查看后,发现有个文件夹(2012的那个)里的数据与2007的文件夹相比少了一些数据,我觉得可能是下载的时候的出现了问题,我把所有的数据集删除后,重新下载,这时出现了问题,
下载到99%报错了,显示“错误 (核心已转储)”

找了好多资料后,才解决这个问题,解决方法:链接: link.按照这篇博客所说的方法修改后,就可以下载数据集了。有时候每下载一次就要用这个方法修改一次,但还有时候修改了没有用!!!,直接暴力复制链接在浏览器下载。

切记:
要按照作者的解压语句解压,不建议手动解压。我和同学讨论语句解压和手动解压这个问题,发现了一个神奇的现象: 运行解压语句,会把相同名称的文家夹合并起来,最后合成一个名为VOCdevkit的大文件夹(好神奇!!!),手动解压的话,会得到三个相应的文件夹,里面也包含着一些文件夹。语句解压相当于帮你把三个压缩包里的内容(相同名字的文件夹)合并了,以便后面使用。手动解压也行,在执行代码的时候修改路径准确对应就行,方便点的话
解压语句如下:
tar xf VOCtrainval_11-May-2012.tar
tar xf VOCtrainval_06-Nov-2007.tar
tar xf VOCtest_06-Nov-2007.tar
下载完成,解压完成,然后把所有文件放在一个名为voc的文件夹下面(方便后面操作),如下图:

(上图中,voc文件夹中多了几个文件,那是执行后面的步骤产生的,看了后面的代码发现,这里把文件都放在voc以便于后面的操作)
下一步Generate few-shot image list To use our few-shot datasets,进入工程所在的目录,执行
python scripts/convert_fewlist.py
直接执行会报错,先分析一下scripts/convert_fewlist.py 的作用,这个文件的目的主要是修改路径,生成小样本图片的列表,文件中具有批量修改小样本图片的列表的操作。
在这里要完成修改路径,才能执行这个py文件:
修改路径:
// 第8行
parser.add_argument('--droot', type=str, default='/home/wtz/me/fewshot/voc'
修改default后面的内容 ,定位到voc文件夹。
Base Training
下一步修改 Pascal 数据的 Cfg 更改 data/metayolo.data 文件
metayolo=1
metain_type=2
data=voc
neg = 1
rand = 0
novel = data/voc_novels.txt // file contains novel splits
novelid = 0 // which split to use
scale = 1
meta = data/voc_traindict_full.txt
train = $DATA_ROOT/voc_train.txt
valid = $DATA_ROOT/2007_test.txt
backup = backup/metayolo
gpus=1,2,3,4
复制过去记得把
// file contains novel splits
// which split to use
删除,这个只是解释前面的参数的,如果不删除后面运行会报错,issues上也有人题了这个问题: link。
Train The Model
python train_meta.py cfg/metayolo.data cfg/darknet_dynamic.cfg cfg/reweighting_net.cfg darknet19_448.conv.23
执行训练的时候报错了
错误1:No such file or directory: 'backup/metayolo_novel0_neg1
显示找不到这个文件,检查之后发现确实没有这个文件夹,issues有人讨论了这个问题link.,我看了之后他们所说的解决方法就是:在工程下面创建一个名为backup的空文件夹。
按照这个方法创建文件夹后,运行后没有报这个错误,但是新的错误又出现了:

根据报错查看后,发现缺少一个文件voc_metadict1_full,isuues上有人提出这个问题链接: link.但是没有解决方案,查询很多资料都没有找到相关的信息,然后去请教了学长,学长说可能是超参数配置文件、数据集索引文件、加权文家等,要先读懂代码才能把这个文件做出来。
所以开始仔细读代码喽~~~
…
…
…
额,感觉好多函数都需要查资料…
…
这几天看代码,感觉很慢,代码比较多读起来有点难,感觉效率不是很高。
…
我仔细看了下错误,发现好像并不是因为缺少这个voc_metadict1_full.txt,查看了运行Train_meta.py所调用的metatune.data、darknet_dynamic.cfg 、reweighting_net.cfg配置文件,发现文件路径以及文件中的路径没改,怪不得报错了,主要修改metatune.data文件,darknet_dynamic.cfg 、reweighting_net.cfg为网络的一些参数,不用改。
修改metatune.data文件:
修改1:
a.修改voc_train.txt文件的位置索引
train = /home/wtz/me/fewshot/voc_train.txt
b.voc_train.txt文件是数据集的位置索引,也需要改,改为自己的数据集所在的位置,修改文件中的索引路径的py文件如:
# coding:UTF-8
import argparse
import random
import os
import numpy as np
from os import path
parser = argparse.ArgumentParser()
parser.add_argument('--droot', type=str, default='/home/wtz/me/fewshot/voc')
# parser.add_argument('--droot', type=str, default='/home/bykang/voc')
args = parser.parse_args()
args.droot = args.droot.rstrip('/')
tgt_folder = path.join(args.droot, 'voclist')
src_folder = '/home/wtz/me/fewshot/1'
print('===> Converting few-shot name lists.. ')
for name_list in sorted(os.listdir(src_folder)):
print(' | On ' + name_list)
# Read from src
with open(path.join(src_folder, name_list), 'r') as f:
names = f.readlines()
# Replace data root
names = [name.replace('/home/bykang/voc', args.droot)
for name in names]
with open(path.join(args.droot, 'voclist', name_list), 'w') as f:
f.writelines(names)
这是我根据作者的代码改的,src_folder 为修改前的文件所在的位置,tgt_folder 为修改后的文件所在的位置。
修改2:
a.修改voc_traindict_bbox_5shot.txt文件的位置索引
meta = data/voc_traindict_bbox_5shot.txt
b.修改voc_traindict_bbox_5shot.txt中的位置索引,修改索引的py文件见修改1。
修改3:
a.修改2007_test.txt文件的位置索引
valid = /home/wtz/me/fewshot/voc/2007_test.txt
b.修改voc_traindict_bbox_5shot.txt中的位置索引,修改索引的py文件见修改1。
以上就是把对应的文件、数据集的位置修改正确。
修改完后,再运行
python train_meta.py cfg/metayolo.data cfg/darknet_dynamic.cfg cfg/reweighting_net.cfg darknet19_448.conv.23
又报错了,如下:

显示raise AssertionError(“Torch not compiled with CUDA enabled”)
AssertionError: Torch not compiled with CUDA enabled
Torch编译的时候没有可用的CUDA?
… … … … … … … … … … … … … … … … … … … . … . . . … … . … … . . . .
经过很长时间的尝试,一直在弄cuda的问题,总结如下:
(1)只安装了cuda而没有安装pytorch框架,cuda是用不了的,安装cuda以及对应的pytorch框架,建议去官网选择安装,pytorch.

需要更早版本的在上面点击Previous Pytorch Versions选择,如conda install pytorch1.2.0 torchvision0.4.0 cudatoolkit=9.2 -c pytorch(为cuda9.2和pytorch1.2版本)
自己单独下载的话,要注意cuda和pytorch的对应!
验证cuda是否能用
a.没有在虚拟环境里安装的cuda(即没有进入虚拟环境,直接在终端里按装的cuda),验证方法如下:
哦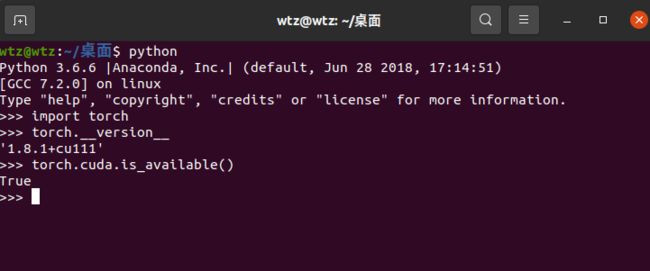
返回True表示cuda可以用,返回False表示cuda不能用。
b.如果是在虚拟环境中安装的cuda,我们进入虚拟环境,进行测试,如果有pycharm的话,直接在控制台运行语句测试:

返回True表示cuda可以用,返回False表示cuda不能用。
(2)在虚拟环境里和不在虚拟环境安装的cuda是不通用的,所以配环境的时候直接在虚拟环境里安装cuda…等。
在虚拟环境里安装了cuda9.2+pytorch1.4
pip install torch==1.4.0+cu92 torchvision==0.5.0+cu92 -f https://download.pytorch.org/whl/torch_stable.html
解决了raise AssertionError(“Torch not compiled with CUDA enabled”)
AssertionError: Torch not compiled with CUDA enabled的问题(这里的版本我是作了个尝试,报着试试的心态安装的,其他版本可能也行,但是有些版本如cuda11.1+pytorch1.8.1就不可以,可能和所创建的虚拟环境,使用的python版本有关吧)
再运行语句
python train_meta.py cfg/metayolo.data cfg/darknet_dynamic.cfg cfg/reweighting_net.cfg darknet19_448.conv.23
报错如下:

Traceback (most recent call last):
File "train_meta.py", line 88, in <module>
model.load_weights(weightfile)
File "/home/wtz/me/fewshot/Fewshot_Detection-master/darknet_meta.py", line 378, in load_weights
start = load_conv_bn(buf, start, model[0], model[1])
File "/home/wtz/me/fewshot/Fewshot_Detection-master/cfg.py", line 455, in load_conv_bn
conv_model.weight.data.copy_(torch.from_numpy(buf[start:start+num_w])); start = start + num_w
RuntimeError: The size of tensor a (3) must match the size of tensor b (864) at non-singleton dimension 3
RuntimeError:张量 a (3) 的大小必须与非单维 3 的张量 b (864) 的大小相匹配 ???
维度不同,可能需要转换维度对应起来,issue上有人提了类似的问题链接: link.
解决方法:
修改cfg.py455行:
# conv_model.weight.data.copy_(torch.from_numpy(buf[start:start+num_w])); start = start + num_w
conv_model.weight.data.copy_(torch.from_numpy(buf[start:start + num_w]).reshape_as(conv_model.weight.data));start = start + num_w
return
加了个reshape_as(conv_model.weight.data))转换维度
再运行语句
python train_meta.py cfg/metayolo.data cfg/darknet_dynamic.cfg cfg/reweighting_net.cfg darknet19_448.conv.23
报错如下:
 显示RuntimeError: cuda runtime error (38) : no CUDA-capable device is detected at /pytorch/aten/src/THC/THCGeneral.cpp:50,查了一些解决方法: link.查看显卡编号为0:
显示RuntimeError: cuda runtime error (38) : no CUDA-capable device is detected at /pytorch/aten/src/THC/THCGeneral.cpp:50,查了一些解决方法: link.查看显卡编号为0:
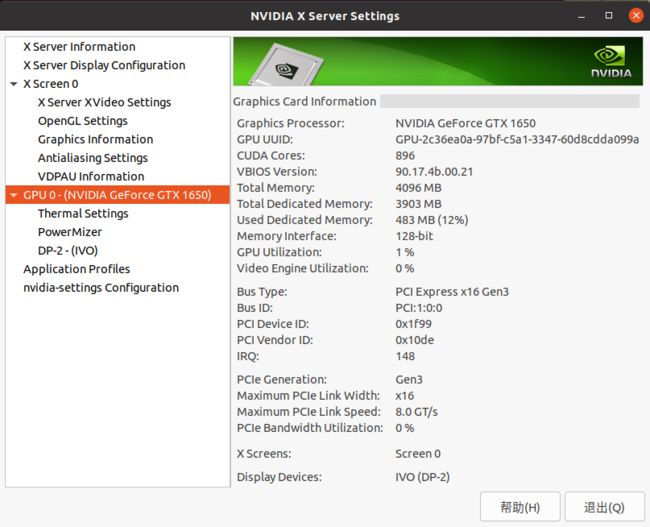 修改配置文件metatune.data、metayolo.data 中的 gpu = 0。
修改配置文件metatune.data、metayolo.data 中的 gpu = 0。
再运行语句
python train_meta.py cfg/metayolo.data cfg/darknet_dynamic.cfg cfg/reweighting_net.cfg darknet19_448.conv.23
报错如下:
 显示RuntimeError: CUDA out of memory. Tried to allocate 1.32 GiB (GPU 0; 3.81 GiB total capacity; 2.13 GiB already allocated; 364.25 MiB free; 2.25 GiB reserved in total by PyTorch)
显示RuntimeError: CUDA out of memory. Tried to allocate 1.32 GiB (GPU 0; 3.81 GiB total capacity; 2.13 GiB already allocated; 364.25 MiB free; 2.25 GiB reserved in total by PyTorch)
然后我减少数据集的数量,3张数据集训练、2张数据集训练,出现了新的问题: 调试检查后发现维度不对应,需要修改维度,issue上也有人提出并说了解决方案link.:
调试检查后发现维度不对应,需要修改维度,issue上也有人提出并说了解决方案link.:
// 修改295~298行 为:
pred_boxes[0] = x.data.view(nB*nA*nH*nW) + grid_x
pred_boxes[1] = y.data.view(nB*nA*nH*nW) + grid_y
pred_boxes[2] = torch.exp(w.data).view(nB*nA*nH*nW) * anchor_w
pred_boxes[3] = torch.exp(h.data).view(nB*nA*nH*nW) * anchor_h
继续运行,出现问题: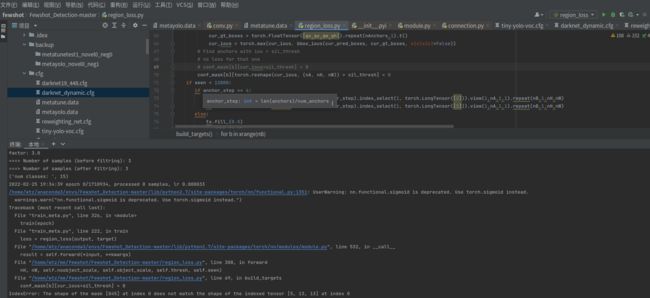 issue上有人提出并说了解决方案link.:
issue上有人提出并说了解决方案link.:
// 修改 conf_mask[b][cur_ious>sil_thresh] = 0 为:
conf_mask[b][torch.reshape(cur_ious, (nA, nH, nW)) > sil_thresh] = 0
继续运行,出现问题:
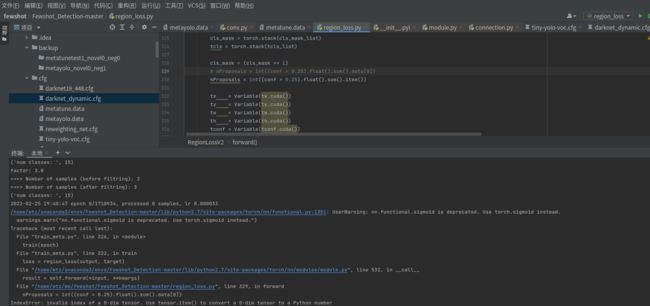 问题分析及解决link.
问题分析及解决link.
#将原语句:
train_loss+=loss.data[0]
#修改为:
train_loss+=loss.item()
继续运行,出现问题:
这个问题查了很多资料,发现都没有解决,issue上也没人讨论这个问题,经过我一步一步调试,发现是维度不匹配的问题,修改如下:
// cls_mask 改为 cls_mask.view(-1) 维度就匹配了
tcls = Variable(tcls.view(-1)[cls_mask.view(-1)].long().cuda())
接着运行,出现问题:
 RuntimeError: shape ‘[30, 5, 6, 13, 13]’ is invalid for input of size 5070
RuntimeError: shape ‘[30, 5, 6, 13, 13]’ is invalid for input of size 5070
这个问题我调试后发现它是有概率出现的,我在调试的时候,他没有报错,然后运行就报错了,而且是偶尔出现的?!?!?!我觉得应该问题不大,也有可能是数据集太少了的原因吧。
我刚开运行的时候,发现跑了4个epoch后就报这个错误了,能跑4个epoch环境应该没啥的问题了吧,我决定仔细读代码,学习、了解整个网络。感觉对网路还不是太熟,有时候调参数不太方便。
…
昨天调试了一下午,大概了解了整个代码的训练过程,训练的时候会用到voc_traindict_full.txt里对应类别的图片,我看了下,每个类别
都有好多图片,数据量很大,这可能是导致Cuda内存不足的的一个原因吧。我把每个类的图片减少到4张左右,发现还是训练不了,Cuda内存还是不足。我尝试删除类别进行训练。如果要改变类别数,需要修改的地方有点多,主要在训练所用的配置文件涉及类别的文件以及cfg.py文件中voc_classes,后面换数据集的时候再仔细记录吧。比较难受的是,我改完类别之后,运行报错了:浮点数例外 (核心已转储),网上资料特别少,不知道怎么解决,后来又把类别改回去了,继续运行,依然只能训练集张图片,修改darknet_dynamic.cfg中的max_batches后,发现训练的时候的epoch减少了,并且可以运行17个epoch了,max_batches的值与epoch数目的计算有关,在train_meta.py可以找相应的语句。运行完之后,又不能运行了!!!Cuda内存又不足了!!!后来听同学说,把配置文件中的momentum=0改为0之后就可以运行了,我试了下,果然可以,momentum=0好像是梯度更新的时候用的,我觉得改为0后,网络在训练的时候就会变的“小”一点,所以就可以运行了。先这样吧,先训练一个全重,进行下一步!
Evaluate the Model
训练后得到权重000010.weights,路径为backup/metayolo_novel0_neg1/000010.weights,然后运行:
// Remember to change the corresponding path of 000010.weights
python valid_ensemble.py cfg/metayolo.data cfg/darknet_dynamic.cfg cfg/reweighting_net.cfg backup/metayolo_novel0_neg1/000010.weights
报错如下:

issue上没人讨论,进行调试检查,问题出现在cfg.py的文件419行:
conv_model.weight.data.copy_(torch.from_numpy(buf[start:start+num_w]).view(conv_model.weight.data.shape));
conv_model.weight.data的维度为[30,1024,1,1],torch.from_numpy(buf[start:start+num_w]的维度为[32700,],需要把维度转换为[30,1024,1,1],链接: link.(解决方法来自这篇文章):
conv_model.weight.data.copy_(torch.from_numpy(buf[start:start+num_w]).view(conv_model.weight.data.shape));
关于warning的修改,尽量别改,我在后面测试的发现报错了,一直解决不了问题,后面直接换了测试的py,没有改过warning的,就没有问题了…/
作者默认使用的是 5shot.txt,我报Cuda内存不足了,尝试改用1shot.txt.结果还是不行,Cuda 内存空间不足,就先这样吧,等熟悉下代码换数据集后在运行看看,后面估价得到服务器上跑了。
后面的Few-shot Tuning部分,也是用train_meta.py文件,和前面的配置文件有点不同,我尝试运行后一也是cuda内存不足的问题,我觉得应该环境应该没多大问题了。下一步打算换数据集试试。
【4.24更新】
已经更换了数据集,实现从同一个类,不同场景的迁移(1对1),作者是15base类 迁移到 5novel类,目前还没完成弄完,等全部训练、测试完等再来更新吧,上面我是基于pycharm配python2.7的,其实可以直接创建 conda create -n name python=2.7。
【7.09】
最近又跑了一遍作者的数据集并做了测试,解决了一直困扰我好久好久的问题(测试的时候老是爆cuda,自己一直没意识到测试时其实不需要进行梯度更新,报错的语句前加 with torch.no grad 就可以了(记得训练的时候注释了,测试的时候再使用),我看issue上没人提这个问题,真的是毫无头绪,直到前几天才搜到这个问题的解决方法。测试完发现,对应的新类的AP和论文中的差不多,但是基类的AP却降得很厉害,Mean AP比论文低0.2左右!!!
(未完,后面接着更新…)