Discrete Opinion Tree Induction for Aspect-based Sentiment Analysis 论文阅读笔记
一、作者
Chenhua Chen、Zhiyang Teng、Zhongqing Wang、Yue Zhang
School of Engineering, Westlake University, China
Institute of Advanced Technology, Westlake Institute for Advanced Study
Soochow University
二、背景
如何为每一个方面词定位相应的意见上下文是 ABSA 任务的关键挑战。最近的一些研究希望通过依赖树中的句法依赖来捕获方面和意见上下文之间的交互。事实上,尽管句法依赖能取得一定的效果,但它仍然会面临一些限制:首先,依赖解析器会在低资源域中表现地更差,甚至在面对低资源语言变得不可用;其次,依赖树通常情况下也不会针对方面情感分类来进行优化,一些现有的优化也只是针对节点分层,而没有优化依赖关系。
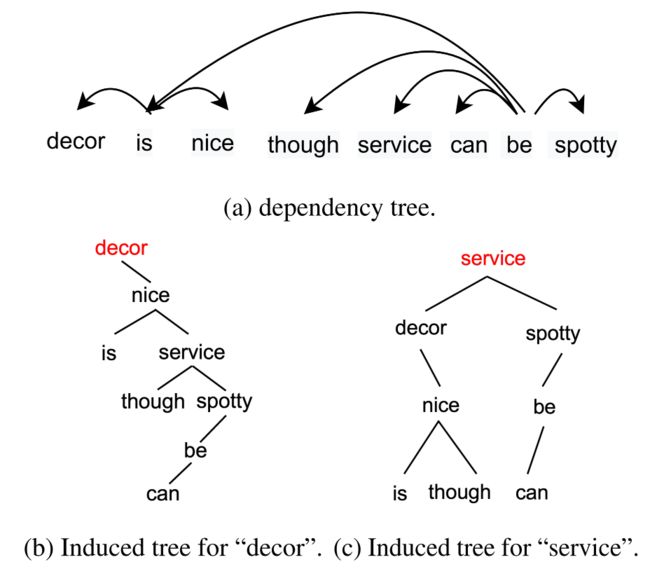
三、创新点
在本文中,作者提出了一个用于为每一个方面自动诱导离散意见树的模型。具体来说,该模型会从根节点开始,通过在当前节点的每一侧各选择一个子节点来构建树结构,并持续递归这个分割过程,以获得一个词汇化的二叉诱导树(induced tree),而后生成的诱导树将会作为输入被送到图卷积网络来训练情感分类器。
四、具体实现
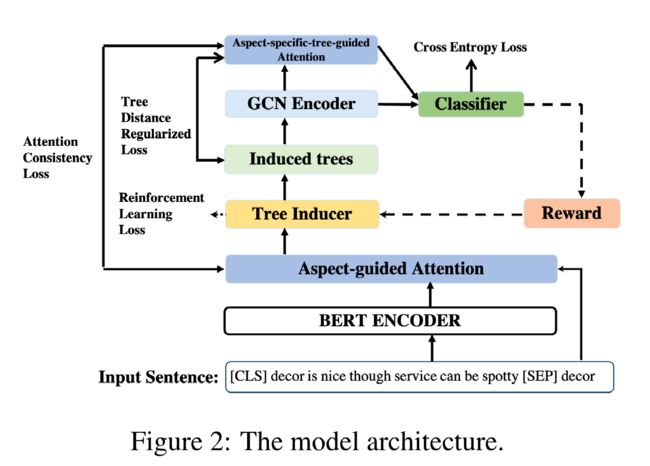
1.基于意见树的分类器
意见树将输入的句子表示为 x = w 1 w 2 … w n x = w_1w_2\dots w_n x=w1w2…wn,将方面表示为 a = w b w b + 1 … w e a = w_bw_{b+1}\dots w_e a=wbwb+1…we,其中 w i w_i wi 表示第 i i i 个单词。对于每一棵意见树来说,二叉树的每一个节点都代表一个单词跨度,通过对二叉树进行中序遍历可以恢复原始句子,而在理想情况下根节点附近的节点应该包含相应的意见词。
下图中介绍了意见树生成算法的具体实现,其中 v i j \mathbf{v}_i^j vij 表示范围 [ i , j ] [i, j] [i,j] 中单词对方面 a a a 的极性 y y y 贡献分数。算法首先将方面范围 [ b , e ] [b, e] [b,e] 作为根节点,然后分别从方面词左右两侧选择得分最高的节点作为左右孩子节点,再然后通过递归调用构建函数来构造意见二叉树。其中,贡献分数的计算可以表示为 v p = u p σ ( W p H + W a , p h a ) \mathbf{v}^p = \mathbf{u}_p\sigma(\mathbf{W}_p\mathbf{H} + \mathbf{W}_{a,p}\mathbf{h}_a) vp=upσ(WpH+Wa,pha),公式中的 σ \sigma σ 代表 R e L U \mathrm{ReLU} ReLU 激活函数, H \mathbf{H} H 为通过将 [ C L S ] w 1 w 2 … w n [ S E P ] w b w b + 1 … w e [\mathrm{CLS}]\ w_1\ w_2\ \dots\ w_n\ [\mathrm{SEP}]\ w_b\ w_{b+1}\ \dots\ w_e [CLS] w1 w2 … wn [SEP] wb wb+1 … we 输入 BERT 得到的方面特定的句子表示, h a \mathbf{h}_a ha 则表示通过将 H b H b + 1 … H e \mathbf{H}_b \mathbf{H}_{b+1}\dots\mathbf{H}_e HbHb+1…He 求和池化得到的方面表示。

基于生成的意见树 t t t 和句子表示 H \mathbf{H} H,作者通过图卷积网络来学习每一个词的向量表示。首先,将意见树转化为一个无向图 G G G,该无向图的每一个节点表示一个单词,边通过邻接矩阵 A \mathbf{A} A 来表示。邻接矩阵的构造规则如下:
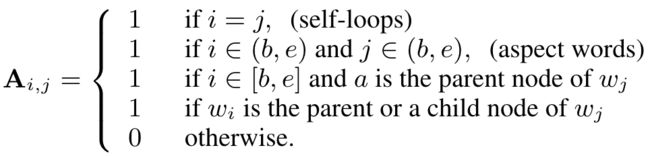
基于邻接矩阵 A A A 和第 l − 1 l-1 l−1 层的表示矩阵 H l − 1 \mathbf{H}^{l-1} Hl−1,通过 GCNs 可以得到第 l l l 层的表示 H l = f ( A H l − 1 W l + b l ) \mathbf{H}^l = f(\mathbf{A}\mathbf{H}^{l-1}\mathbf{W}^l + \mathbf{b}^l) Hl=f(AHl−1Wl+bl),其中 f f f 为激活函数,其余为模型参数,而 GCNs 第一层的输入 H 0 \mathbf{H}^0 H0 即为 BERT 给出的 H \mathbf{H} H。
基于 GCNs 的处理结果,最终的方面特定的特征表示 c \mathbf{c} c 的计算如下图所示,其中 α t \alpha_t αt 为方面 a a a 对第 t 个单词的注意力分数。
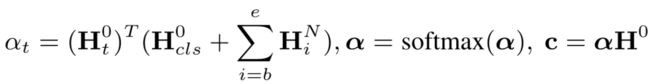
基于最终的特征表示 c \mathbf{c} c,最终预测的情感分布为 p = s o f t m a x ( W c c + b c ) \mathbf{p} = \mathrm{softmax} (\mathbf{W}_c\mathbf{c} + \mathbf{b}_c) p=softmax(Wcc+bc)。
2.情感分类器的训练
情感分类器的训练通过最大化训练样本的对数似然来实现,训练的目标是最小化 L s u p = − ∑ i = 1 ∣ D ∣ ∑ a ∈ x i log p i , y a \mathcal{L}_{\mathrm{sup}} = -\displaystyle\sum_{i=1}^{|D|}\displaystyle\sum_{a\in x_i}\log\mathbf{p}_{i,y_a} Lsup=−i=1∑∣D∣a∈xi∑logpi,ya,其中 ∣ D ∣ |D| ∣D∣ 为训练集的大小, y a y_a ya 是第 i 个句子中的方面 a 的情感标签, p i , y a \mathbf{p}_{i,y_a} pi,ya 为上一步中得到的情感分布。
此外,作者认为靠近根节点的单词应该得到更高的注意力权重,给定意见树 t,作者计算了每个节点到根节点的最短路径,并通过 KL 散度函数来对注意力分数和正则化后的距离之间的关系进行协调。