【论文笔记】:FCOS: Fully Convolutional One-Stage Object Detection
&Title:
- FCOS: Fully Convolutional One-Stage Object Detection
&Summary
本文提出了一种全卷积one-stage目标检测算法(FCOS),以逐像素预测的方式解决目标检测问题,类似于语义分割。目前最流行的不论是one-stage目标检测算法,如RetinaNet,SSD,YOLOv3,还是two-stage目标检测算法,如Faster R-CNN。这两类算法大都依赖于预定义的锚框(anchor boxes)。
相比之下,本文提出的目标检测算法FCOS不需要锚框。通过消除预定义的锚框,FCOS避免了与锚框相关的复杂计算,例如在训练期间计算重叠等,并且显著减少了训练内存。更重要的是,FCOS还避免了设定与锚框相关的所有超参数,这些参数通常对最终检测性能非常敏感。FCOS算法凭借唯一的后处理:非极大值抑制(NMS),实现了优于以前基于锚框的one-stage检测算法的效果。
主要过程:
首先以逐像素预测方式重新构造对象检测,接下来利用多级预测来改善召回率并解决重叠边界框导致的模糊性。最后提出的center-ness分支有助于抑制低质量检测到的边界框,并大幅提高整体性能。
最著名的无anchor的目标检测网络是YOLOv1算法,YOLO v1算法出现,告诉我们,回归网络也可以进行目标检测,但是该网络的召回率不要太低。它引入了cell的思想,7x7的来划分图片,每个cell只预测两个bbox,数量不要太少,召回率自然就很低了。所以本文引入了逐像素回归预测的思想,这样一来,就可以解决了召回率的问题了。框多了,但是重叠框也多了,低质量的框也多了。于是采用了基于FPN的多尺度策略,这里作者认为重叠的框的尺度变化比较大,所以采用FPN的多尺度预测,可以有效的解决不同尺度重叠的问题。同时引入了center-ness,来抑制偏离中心点的框,解决低质量bbox的问题。
&Research Objective
anchor-free + 基于语义分割的思想,提出了逐像素预测的方式来解决目标检测问题
&Problem Statement
anchor-based的不足之处:(计算量大+调参需要针对特定的数据集+比例不平衡)
- anchor-based detector的检测效果严重依赖于预先设定好的anchor类型. 对anchor进行微调, 可以在coco上得到将近4%左右的performance提升, 而这个微调过程又是特别麻烦.
- 因为anchor是预先设定好的, 所以它能检测到的object的尺度是固定的, 对于图像中尺度变化很大的object, 特别是small object很难检测到.
- 因为anchor的设计原则, 导致在训练时, 属于negative的anchor数量远远大于positive的anchor数量. 虽然这个问题可以通过类似focal loss, OHEM的方法抑制, 但问题仍然存在
- 同样是由于anchor的数量过多, 训练占用的内存就更大, 计算消耗也就更大.
&Method(s)
基于以上的原因, 既然anchor-based detector有这样那样的局限性, 那为何不能直接抛弃anchor, 直接使用卷积网络, 得到最后的object bounding box? 文章就提出了FCOS, 抛弃anchor, 而是类似于关键点检测的方法, 在网络最后的featuremap上的每一个位置, 输出box的信息. 概括而言, 如下图所示:

FCOS对于输出的每一个位置, 都预测一个4D vector, 用来表示box的左右上下边界离这个位置的距离. 这个类似预测4D vector的anchor-free网络, 在FCOS之前就出现过, FCOS除了这个工作外, 真正的亮点是额外加了一个center-ness branch. 这个center-ness branch是用来辅助最后的inference的. 就和上图右边的图片展示的那样, 同一个位置, 可以用来表示两个不同的box, 那么用哪个比较合适呢? 很简单, 对这个位置进行打分, 这样远离需要检测的目标中心位置的位置, 分数会较低, 这样就把当前这个位置表示的box的分数降低, 在NMS的时候就可以把这个box抑制掉. 网络的整体结构如下:

可以看到网络最后一共有三个branch输出, 最终的结果是要先对表示该类的box和对应的center-ness score相乘再做NMS.
&Evaluation
略
&Conclusion
- 虽然Yolo-v1也是anchor-free算法,区别在于,yolo-v1只利用了目标的中心区域的点做预测,因此recall较低。而FCOS利用了目标的整个区域内的点,recall和anchor-based算法相当;
- 尽管centerness确实带来效果上的明显提升,但是缺乏理论可解释性;(我的理解:可能存在几个点的center-ness的值是一样的,这样回归时,就很难学到他们各自的特征,这样就很难学到一个好的网络,来对他们进行有效的分类)
- 作为一种新的anchor-free算法,它的效果确实超过了yolo-v1、cornernet、FSAF,但是,既然是one-stage算法,推理速度是固有优势,而论文中却始终未提速度,可见,开发anchor-free且速度较快的检测算法,还有一段路要走。
注:结论来自:https://blog.csdn.net/diligent_321/article/details/89069018
&Notes
contribution:
- 使用语义分割的思想来解决目标检测问题;
- 摒弃了目标检测中常见的anchor boxes和object proposal,使得不需要调优涉及anchor boxes和object proposal的超参数(hyper-parameters);
- 训练过程中避免大量计算GT boxes和anchor boxes 之间的IoU,使得训练过程占用内存更低;
- 提出的可以FCOS代替二阶段检测中的RPN,且性能更优;
主要优点:
- 因为输出是pixel-based预测,所以可以复用semantic segmentation方向的tricks;
- 可以修改FCOS的输出分支,用于解决instance segmentation和keypoint detection任务;
以下有些内容摘自:https://blog.csdn.net/qiu931110/article/details/89073244
逐像素回归
本文提出的FCOS算法为了提升召回率,则对目标物体框中的所有点都进行边界框预测。当然这种逐像素的边界框预测肯定会导致最终预测得到的边界框质量不高,因此作者在后续还会提出弥补策略。(见后)
FCOS目标检测算法在边界框预测中使用的策略和YOLOv1有所不同,本文提出的预测策略如下:


基于FPN的多尺度策略
基于anchor的检测算法,由于较大的降采样操作而导致的低召回率可以通过降低正anchor所需的IOU阈值做一定程度上的补偿,可以进行召回率的提升。
对于FCOS算法,如果降采样的尺度过大,那么网络不可能召回一个在最终特征图上没有位置编码的对象的初始框的,基于此作者提出了基于FPN的多尺度策略。(虽然作者在文中说,即使没有FPN策略,逐像素检测网络在召回率上表现的也不逊色基于anchor的网络。)
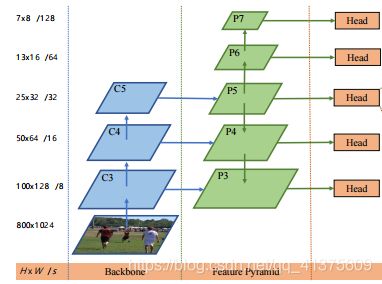
如上图所示,FCOS算法那使用了{P3, P4, P5, P6, P7}这五个尺度的特征映射。其中P3、P4、P5由主干CNNs网络的特征层 C3、C4、C5经过一个1*1的卷积得到的,而,P6、P7则是接着P5进行了步长为2的卷积操作得到的(相当于降采样,看注解)。最终对这五个尺度都做逐像素回归。
当然,本文为了能够更好的利用这种多尺度特征,在每一个尺度的特征层都限定了边界框回归的范围,不让其野蛮生长。(基于anchor的检测网络也有类似策略,比如YOLOv3中将不同大小的anchor分配到不同特征层级中作回归)更具体地说,作者首先计算所有特征层上每个位置的回归目标
第一:计算当前层级中的回归目标:l、t、r、b。
第二:判断max(l, t, r, b) > mi 或者 max(l, t, r, b) < mi -1是否满足。
第三:若满足,则不对此边界框进行回归预测。
第四:mi是作为当前尺度特征层的最大回归距离。
而且这种约束带来的额外的效果在于,由于不同尺寸的物体被分配到不同的特征层进行回归,又由于大部分重叠发生在尺寸相差较大的物体之间,因此多尺度预测可以在很大程度上缓解目标框重叠情况下的预测性能。
也就是如果重叠的两个object尺寸没有相差较大的话,这一部分就显得多余了,另外,这一部分是怎么做到的提高召回率的???难以理解
center-ness
center-ness,可以译成中心点打分,它表征了当前像素点是否处于ground truth target的中心区域
由于FCOS算法使用了逐像素回归策略,在提升召回率的同时,会产生许多低质量的中心点偏移较多的预测边界框。基于此,作者提出了一个简单而有效的策略center-ness来抑制这些低质量检测到的边界框,且该策略不引入任何超参数。
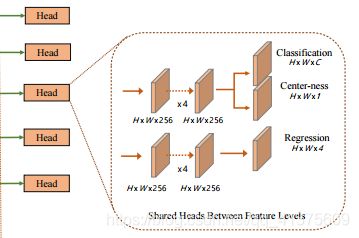
如上图所示,center-ness策略在每一个层级预测中添加了一个分支,该分支与分类并行,相当于给网络添加了一个损失,而该损失保证了预测的边界框尽可能的靠近中心。 该损失的公式如下,其中l,r,t,b表示的为如下图左图中所示的预测值。


注:这边原博理解成是在网络中添加了一个损失,个人认为这样理解容易误导。本来论文中的解释很明白了。论文中意思是,center-ness的值乘上分类的等分当做最终的等分。偏离中心的点,center-ness的 值越小越接近0,而越中心的点,则center-ness的点越接近1,这样就能很好的降低原理中心的bbox,在NMS的过程中,就可以很容易的剔除掉这些低质量的框,提高检测性能。
而该策略之所以能够有效,主要是在训练的过程中我们会约束上述公式中的值,使得其接近于0,这就导致如下图右图中的蓝色框中的短边能够向黄边靠近,使得分布在目标位置边缘的低质量框能够尽可能的靠近中心。这样的话,在最终使用该网络的过程中,非极大值抑制(NMS)就可以滤除这些低质量的边界框,提高检测性能。
推荐阅读
- FCOS算法详解
- 【论文笔记】:YOLO v1
- 目标检测论文:FCOS: Fully Convolutional One-Stage Object Detection及其PyTorch实现