专家系统TBE算子调优
专家系统TBE算子调优
详情指路视频专栏:https://www.bilibili.com/video/BV1j34y1J7Cd
MindStudio介绍
MindStudio提供在AI开发所需的一站式开发环境,支持模型开发、算子开发以及应用开发三个主流程中的开发任务,依靠模型可视化、算力测试、IDE本地仿真调试等功能,MindStudio能够帮助您在一个工具上就能高效便捷地完成AI应用开发,MindStudio采用了插件化扩展机制,开发者可以通过开发插件来扩展已有功能。本实验使用的MindStudio版本为5.0.RC1,安装请参考MindStudio安装教程(https://www.hiascend.com/document/detail/zh/mindstudio/50RC1/instg/ instg_000002.html)。
交付件介绍
实现流程
在使用MindStudio中专家系统的算子优化分析功能进行自定义算子调优的时候,因为专家系统的算子优化分析功能只关注于算子实现部分的优化分析,所以对于自定义算子的开发只需要完成一部分步骤即可,算子分析、算子代码实现、算子信息库定义、算子UT测试,然后通过专家系统中的算子优化分析功能进行算子问题的分析和优化,下面展示了本实验的流程图。

- 环境搭建与配置:本实验的环境由华为提供,MindStudio安装教程请参考([https://www.hiascend.com/document/detail/zh/mindstudio/50RC1/inst /instg_000002.html](https://www.hiascend.com/document/detail/zh/mindstudio/50RC1/inst /instg_000002.html))。安装完MindStudio后开始在MindStudio中配置CANN,CANN配置参考([https://gitee.com/ascend/docs-openmind/blob/ master/guide/common/tutorials/%E6%98%87%E8%85%BE%E7%94%9F%E6%80%81%E4%BC%97%E6%99%BA%E5%AE%9E%E9%AA%8C%E5%AE%A4%E7%BD%91%E7%BB%9C%E8%BF%9E%E6%8E%A5%E6%8C%87%E5%AF%BC.md](https://gitee.com/ascend/docs-openmind/blob/ master/guide/common/tutorials/昇腾生态众智实验室网络连接指导.md))
- 算子工程创建:通过MindStudio工具创建算子工程,创建完之后工具会自动生成算子工程目录及相应的文件模板,开发者可以基于这些模板进行算子开发。
- 算子分析:在开发算子代码之前需要分析算子的数学表达式,输入、输出以及计算逻辑的实现,明确需要调用的TBE DSL接口。若是使用的第三方开源网络,网络中有昇腾AI处理器不支持的算子,可以根据第三方开源网站中的算子实现进行分析,推理出算子的数学表达式
- 算子代码实现:算子使用的TBE框架的实现过程。
- 算子信息库定义:算子信息配置文件用于将算子的相关信息注册到算子信息库中,包括算子的输入输出dtype、format以及输入shape信息。网络运行时,FE会根据算子信息库中的算子信息做基本校验,判断是否需要为算子插入合适的转换节点,并根据算子信息库中信息找到对应的算子实现文件进行编译,生成算子二进制文件进行执行。
- 算子的UT测试:即单元测试(Unit Test),仿真环境下验证算子实现的功能正确性,包括算子逻辑实现代码及算子原型定义实现代码。
- 算子问题分析:根据专家系统显现的问题进行分析。
- 算子调优:根据专家系统提出来的建议进行调优。
代码工程
本实验基于MindStudio的代码工程结构如下所示。
.
|-- CMakeLists.txt
|-- MyOperator26.iml
|-- build //编译生成的中间文件
|-- cmake //编译相关公共文件存放目录
|-- cmake-build //编译相关生成文件存放目录
|-- framework //算子插件实现文件目录
|-- op_proto //算子IR定义文件目录
| |-- CMakeLists.txt
| |-- sort.cc //算子IR定义的.c文件
| `-- sort.h //算子IR定义的.h头文件
|-- tbe //TBE算子文件目录
| |-- CMakeLists.txt //编译规则文件,会被算子工程根目录中的CMakeLists.txt文件调用
| |-- impl
| | `-- sort.py
`-- testcases //工程ut测试和st测试相关代码目录
|-- CMakeLists.txt
`-- ut //算子UT测试目录
`-- ops_test
|-- CMakeLists.txt
|-- sort
| |-- CMakeLists.txt //用于编译可执行文件
| |-- test_sort_impl.py //算子实现代码的测试用例文件
`-- test_main.cc //测试用例调用总入口
文章介绍
文章详细记录了如何使用MindStudio中的算子优化分析功能去优化TBE算子,包括算子工程创建、算子分析、算子代码实现、算子信息库定义、算子UT测试、专家系统算子问题分析和专家系统算子调优。第三节介绍了MindStudio算子工程的创建。第四节介绍了TBE自定义算子开发算子基本概念、算子的分析,包括算子的输入输出,属性等。第五节介绍了专家系统算子优化分析。第六节介绍了整个流程中遇到的问题和解决方案。第七节介绍MindStudio的更多的内容。
算子工程创建
-
打开MindStudio进入算子工程创建界面
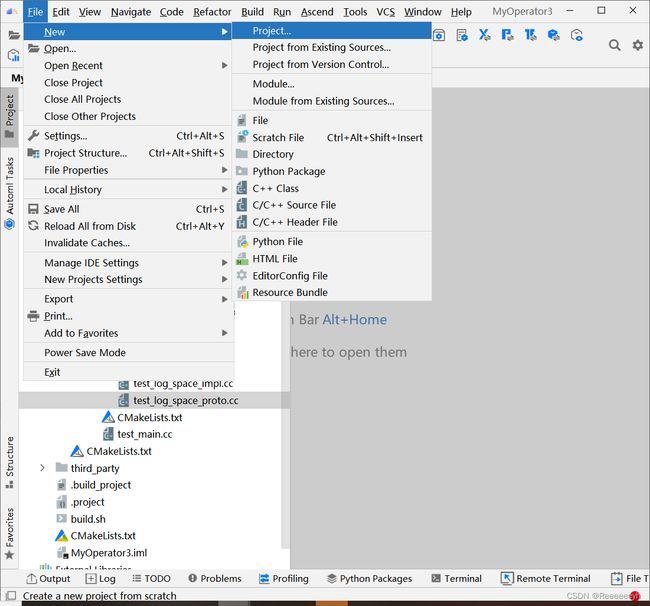
首次登录MindStudio:在MindStudio欢迎界面中单击“New Project”,进入创建工程界面。

非首次登录MindStudio:在顶部菜单栏中选择“File > New > Project…”,进入创建工程界面。
-
创建算子工程
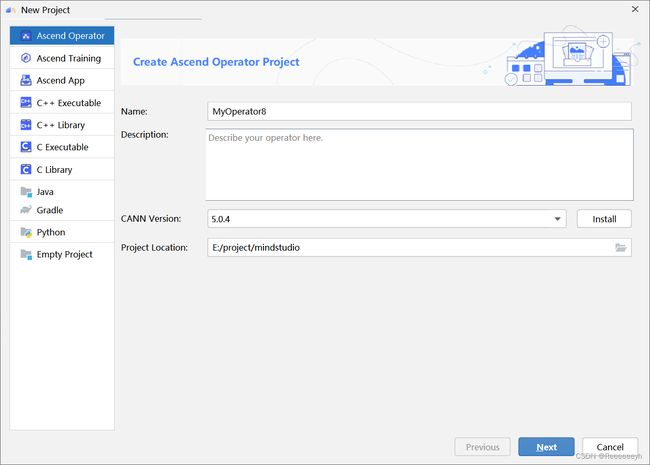
左侧导航栏选择“Ascend Operator”,如图所示,在右侧配置算子工程信息,配置示例如下表。
| 参数 | 参数说明 | 示例 |
| ---------------- | ------------------------------------------------------------ | -------------------- |
| Name | 工程名称,用户自行配置。名称必须以字母开头,数字或字母结尾,只能包含字母、数字、中划线和下划线,且长度不能超过64个字符。 | MyOperator26 |
| Description | 工程描述信息,自行配置。 | 可选配置 |
| CANN Version | 当前CANN的版本号 | 选择当前CANN的版本号 |
| Project Location | 工程的存储路径。 | 保持默认 |
单击“Next”,在弹出的页面中配置算子相关信息,选择Empty Template,如下表算子信息配置。

| 参数 | 参数说明 |
| ---------------- | ------------------------------------------------------------ |
| Empty Template | 表示创建空的算子工程。选择此选项,下方会显示“Operator Type”配置项,请在此处输入需要创建的算子的类型,请根据算子分析进行配置。 |
| Operator Type | 算子名称 |
| Plugin Framework | 算子所在模型文件的框架类型。如果选择“Sample Template”创建算子工程时不显示此配置项。
MindSpore
PyTorch
TensorFlow
Caffe
ONNX |
| Compute Unit | 有以下两种选项,选择“Sample Template”创建算子工程时不显示此配置项。
AI Core / Vector Core:算子如果运行在AI Core或者Vector Core上,则代表是TBE算子。
AICPU:算子如果运行在AICPU上,则代表是AICPU算子。
如果“Plugin Framework”选择“MindSpore”, 则仅支持选择“AI Core / Vector Core” |
-
单击“Finish”,完成算子工程的创建。
若工作窗口已打开其他工程,会出现如图所示提示。
选择“This Window”,则直接在当前工作窗口打开新创建的工程。
选择“New Window”,则新建一个工作窗口打开新创建的工程。

TBE自定义算子开发
TBE算子基本概念介绍
要认识TBE就要先了解TVM。TVM(Tensor Virtual Machine)是为了解决不同平台的神经网络模型难以在其他硬件平台便捷的运行,无法充分利用新平台的运算性能的问题而诞生出来的开源深度学习编译栈,它通过统一的中间表达(Intermediate Representation)堆栈连接深度学习模型和后端硬件平台,通过统一的结构优化Schedule,可以支持CPU、GPU和特定的加速器平台和语言。TVM的架构详细介绍请参考https://tvm.apache.org/。
TBE(Tensor Boost Engine)提供了基于TVM框架的自定义算子开发能力,通过TBE提供的API可以完成相应神经网络算子的开发。TBE工具给用户提供了多层灵活的算子开发方式,用户可以根据对硬件的理解程度自由选择,利用工具的优化和代码生成能力,生成昇腾AI处理器的高性能可执行算子。
算子分析
-
sort算子的功能:将输入张量的元素按照给定的维度按值升序或者降序排序。返回一个命名元组(值,索引),其中值是排序后的值,索引是原始输入张量中元素的索引。
-
属性:
sort算子有两个属性,分别为axis和descending,代表排序的维度和是升序还是降序。
axis类型为int32,descending类型为bool
axis和descending属性都是可选的,默认是-1和false,即默认排序最后一个轴、降序排序。
-
输入和输出:
sort算子有一个输入:x,输出为y1,y2。
本样例中算子的输入支持的数据类型为float16,算子输出y1的数据类型为float16,y2的数据类型为int32。
算子输入支持所有shape,输出shape与输入shape相同。
算子输入和输出支持的format为:ND。
-
确定算子开发方式及使用的计算接口:本次sort算子的开发使用的是MindStudio工具,通过调用TIK提供的API接口来实现sort算子的功能。
-
明确算子实现文件名称、算子实现函数名称以及算子的类型(OpType):算子类型定义为Sort。算子的实现文件名称及实现函数名称将首字母转换小写字符,定义为sort。
-
通过以上分析,得到Sort算子的设计规格如下:
算子类型(OpType): Sort
算子属性: name: axis; shape: (,1); data type: int32; default: -1;
name: descending; shape: (,1); data type: bool; default: -1;
算子输入: name: x; shape: all; data type: float16; format: ND;
算子输出: name: y1; shape: all; data type: float16; format: ND;
name: y2; shape: all; data type: float16; format: ND;
算子实现使用的主要TIK接口: tik_instance = tik.Tik(); tik_instance.Tensor();
算子实现文件/实现函数名称: sort;
算子代码实现
用户调用TIK API编写算子对应的Python程序后,TIK会将其转化为TIK DSL(TIK DSL是一种DSL语言,它可以在比CCE更高的抽象层次上定义CCEC程序的行为),经过编译器编译后生成CCEC文件(CCEC代码目前对于TIK编程人员无法感知),再经过CCE编译器编译后生成可运行在昇腾AI处理器上的应用程序。TBE TIK的算子实现流程如下图所示:

通过调用TBE TIK接口,在算子工程下的“tbe/impl/sort.py”文件中进行Sort算子的实现,包括算子函数定义、算子入参校验、compute过程实现及调度与编译。其关键代码如下所示:





算子信息库定义
需要通过配置算子信息文件,将算子的相关信息注册到算子信息库中。算子信息库主要体现算子在昇腾AI处理器上物理实现的限制,包括算子的输入输出dtype、format以及输入shape信息。网络运行时,FE会根据算子信息库中的算子信息做基本校验,判断是否需要为算子插入合适的转换节点,并根据算子信息库中信息找到对应的算子实现文件进行编译,生成算子二进制文件进行执行。
进入“tbe/op_info_cfg.ai_core.soc_version”目录,配置算子信息库文件“sort.ini”。soc_version为当前昇腾AI处理器的版本,例如ascend310、ascend910等。开发者需要基于MindStudio自动生成的sort.ini文件进行修改,修改后的Sort算子的算子信息定义如下所示。

| 信息 | Sort算子配置 | 说明 |
|---|---|---|
| [OpType] | [Sort] | 算子类型,以英文半角方括号,标识一个算子信息开始,根据算子分析,算子类型为Sort。 |
| input0.name | x | Sort算子的第一个输入tensor的名称,根据算子分析,输入名称为x,所以此处配置为x,且需要跟算子原型定义中的名称保持一致。 |
| input0.dtype | input0.dtype=float16 | 定义输入tensor支持的数据类型与数据排布格式。根据算子分析,Sort算子的输入数据类型支持float16; |
| input0.format | input0.format= ND | 支持的数据排布格式有ND。说明:若算子输入支持多种规格,算子输入的dtype与format需要一一对应、按对应顺序进行配置,列出算子支持的所有dtype与format的组合,中间以“,”分隔。 |
| input0.shape | all | 定义输入tensor支持的形状。 |
| input0.paramType | required | 定义输入tensor的类型。dynamic:表示该输入是动态个数,可能是1个,也可能是多个。optional:表示该输入为可选,可以有1个,也可以不存在。required:表示该输入有且仅有1个。Sort算子的input0为固定输入1个,此处配置为required。 |
| output1.name | y1 | 此配置项代表Sort算子的第一个输出tensor的名称,根据算子分析,第一个输出名称为y1,所以此处配置为y1,且需要跟算子原型定义中的名称保持一致。 |
| output1.dtype | output1.dtype=float16 | 定义输入tensor支持的数据类型与数据排布格式。根据算子分析,Sort算子的输入数据类型支持float16; |
| output1.format | output1.format= ND | 支持的数据排布格式有ND。 |
| output1.shape | all | 定义输入tensor支持的形状。 |
| output1.paramType | required | 定义输入tensor的类型。Sort算子的output1为固定1个输出,此处配置为required。 |
| output2.name | y2 | Sort算子的输出tensor的名称,根据算子分析,算子的输出名称为y2,所以此处配置为y2,且需要跟算子原型定义中的名称保持一致。 |
| output2.dtype | output2.dtype=int32 | 定义输出tensor支持的数据类型与数据排布格式。根据算子分析,Sort算子的输出数据类型支持float16;支持的数据排布格式有ND。 |
| output2.format | output2.format=ND | 支持的数据排布格式有ND。 |
| output2.shape | all | 定义输出tensor支持的形状。 |
| output2.paramType | required | 定义输出tensor的类型。Sort算子的output1为固定输出1个,此处配置为required。 |
算子UT测试
UT(Unit Test:单元测试)是开发人员进行单算子运行验证的手段之一,主要目的是:1)、测试算子代码的正确性,验证输入输出结果与设计的一致性。2)、UT侧重于保证算子程序能够跑通,选取的场景组合应能覆盖算子代码的所有分支(一般来说覆盖率要达到100%),从而降低不同场景下算子代码的编译失败率。下面展示UT测试步骤:
-
创建UT测试用例。创建UT测试用例,有以下两种方式:
右键单击算子工程根目录,选择“New Cases > TBE UT Case”。
若已经存在了算子的UT测试用例,可以右键单击“testcases”目录,或者“testcases > ut”目录,选择“New Cases > TBE UT Case”,创建UT测试用例。
在弹出的算子选择界面,选择需要创建UT测试用例的算子,单击OK,如下图所示。

创建完成后,会在算子工程根目录下生成testcases文件夹,目录结构如下所示:
├── MyOperator26 //工程根目录 │ ├── testcases │ │ ├── libs // gtest框架,为第三方依赖,用户无需关注 │ │ ├── ut │ │ │ ├── ops_test │ │ │ │ ├── sort │ │ │ │ │ ├── CMakeLists.txt //用于编译可执行文件 │ │ │ │ │ ├── test_sort_impl.py //算子实现代码的测试用例文件 │ │ │ │ │ ├── test_sort_proto.cc //算子原型定义代码的测试用例文件 │ │ │ │ ├── CMakeLists.txt //用于编译可执行文件 │ │ │ │ ├── test_main.cc //测试用例调用总入口 │ │ │ ├ CMakeLists.txt -
编写算子实现代码的UT Python测试用例。在“testcases/ut/ops_test/ sort/test_sort_impl.py”文件中,编写算子实现代码的UT Python测试用例,计算出算子执行结果,并取回结果和预期结果进行比较,来测试算子逻辑的正确性。

注:
测试用例params中字段和字段取值范围需根据算子实现文件入口参数确定。输入tensor中的"ori_shape"和"ori_format"字段为可选字段,但若使用参数校验修饰器检验参数"ori_shape"和"ori_format"字段必选。
可参见UT测试接口参考查看每个测试类接口的使用方法。若要与期望数据进行结果的比对,请使用add_precision_case接口。
-
运行算子实现文件的UT测试用例。
开发人员可以执行当前工程中所有算子的UT测试用例,也可以执行单个算子的UT测试用例。

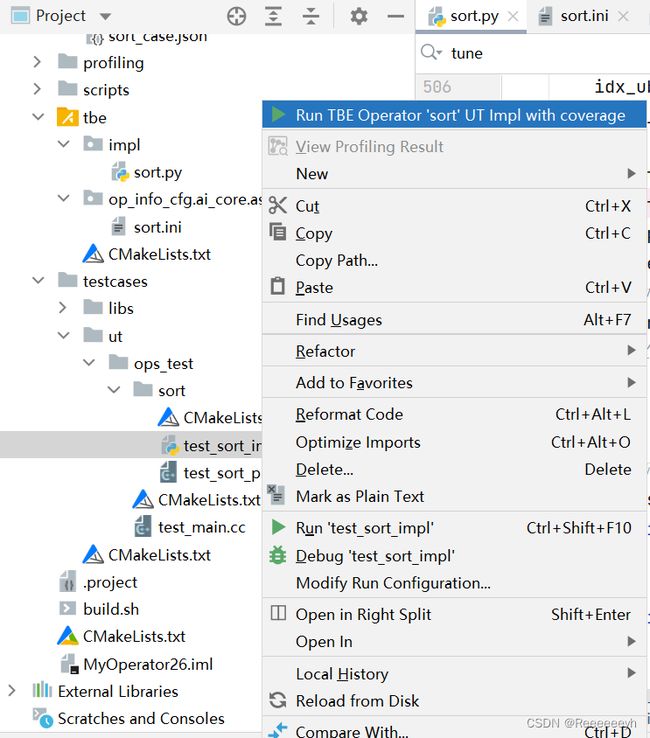
右键单击“testcases/ut/aicpu_test”文件夹,选择Run AI CPU Operator‘All’UT Impl with coverage,运行整个文件夹下算子实现代码的测试用例。
右键单击“testcases/ut/aicpu_test/算子名称”文件夹,选择Run AI CPU Operator ‘算子名称’ UT Impl with coverage,运行单个算子实现代码的测试用例。
第一次运行时会弹出运行配置页面,请参考配置,然后单击Run。后续如需修改运行配置,请参考修改运行配置。
| 参数 | 说明 |
| ------------- | ------------------------------------------------------------ |
| Name | 运行配置名称,用户可以自定义。 |
| Test Type | 选择ut_impl。 |
| Compute Unit | 选择计算单元:l AI Core/Vector Core;l AI CPU。选择不同的计算单元可以实现AI Core/Vector Core和AICPU_UT测试配置界面的切换。 |
| Operator Name | 选择运行的测试用例。all表示运行所有用例。其他表示运行某个算子下的测试用例。 |
| Case Names | 勾选需要运行的测试用例,即算子实现代码的UT C++测试用例。支持全选和全不选所有测试用例。 |
查看运行结果,运行完成后,通过界面下方的日志打印窗口,查看运行结果。结果中展示此次一共运行几个用例,如下图。

专家系统优化分析
背景介绍
在算子开发结束和整网运行出现算子性能不达标两种场景下,需要对算子进行调优。算子调优对开发者的要求比较高,需要开发者对底层和框架有一定的了解,同时具备一定的算子调优经验。算子优化分析可以协助开发者迅速找到算子性能瓶颈,并给出相应的优化手段,能够有效提升开发者算子调优的效率。本节以TBE中的Sort算子为例,介绍通过专家系统算子优化分析功能,自动识别算子中存在的问题,给出优化建议,根据优化建议进行优化,提升模型整体性能。
专家系统操作
-
单击算子工程界面“Run > Edit Configurations…”或单击如下图所示菜单,进入运行UT测试配置界面。

-
配置算子参数时勾选“Enable Advisor”。如下图所示

只有当Test Type参数选择ut_impl,Target参数选择Simulator_TMModel,且Case Names参数仅勾选一项Case时,才允许勾选“Enable Advisor”开启算子专家系统功能;当Target选择其他选项或Case Names参数勾选多个case时,“Enable Advisor”选项不显示。
-
单击“OK”完成算子工程信息的配置。
-
单击算子工程界面“Run >Run”或单击下图所示菜单,运行算子UT测试。

-
在这里我们使用了两类UT测试case来测试Sort算子的性能,一类是排序轴数小于2048的场景,另一类是排序轴数大于2048的场景。
在使用排序轴数目小于2048场景的UT测试案例的时候,得到如下结果输出。
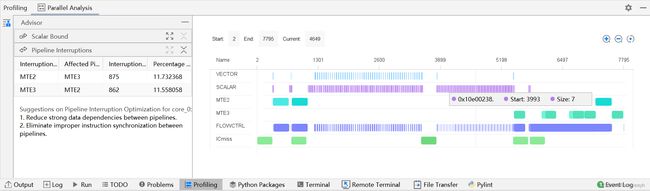
在使用排序排序轴数目大于2048场景下,得到的输出结果如下。

问题分析
针对占比最大的流水进行分析,主要从三个维度进行:
- 其它流水导致的流水不连续。
- 指令入队列导致的流水不连续。
- pipe_barrier(PIPE_ALL)导致的流水打断。
根据分析的结果,对上述三个维度造成影响的周期数进行排序,结果展示如下:
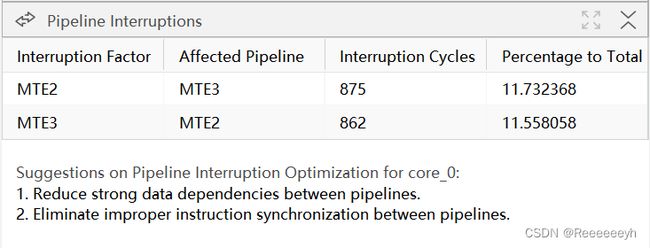
MTE2:表示将数据从Global Memory搬运到Unified Buffer,Vector完成计算后将结果写回Unified Buffer。
MTE3:表示将计算结果搬回Global Memory。
MTE2和MTE3的功能如下图所示。

对于专家系统展示的分析结果,其字段解释如下表格所示。
| 字段 | 说明 |
|---|---|
| Pipeline Interruption | 分析流水打断。 |
| Interruption Factor | 流水打断因素。 |
| Affected Pipeline | 受影响的流水。 |
| Interruption Cycles | 流水打断的周期数。 |
| Percentage to Total | 打断周期数占总周期数的百分比。 |
-
Reduce strong data dependencies between pipelines.
优化不合理的流水依赖。
-
Eliminate improper instruction syschronization between pipelines.
消除流水间不合理的指令同步。
故根据上述关于专家系统算子优化分析功能的结果展示分析,Sort算子的实现部分针对于排序轴数小于2048的场景存在不合理的流水线依赖问题和流水间不合理指令同步问题。
问题解决
根据优化建议,需要重点需要优化轴数小于2048的场景下Sort算子的代码实现部分,在这部分中存在着不合理的流水依赖和同步指令,对于这部分的分析根据开发经验,可能会有数据内存地址踩踏问题出现,即可能存在冗余的重复指令问题,再参考专家系统的分析建议,如下图

即显示MTE2和MTE3影响了指令流水的打断,对此首先想到data_move指令,即数据的内存和外存之间的搬运指令,是否存在着不合理的可以优化的部分。通过寻找使用data_move的代码模块并测试发现下图中的tik循环可以省略,由于这个不必要的tik循环,导致了出现冗余重复的指令,里面的repeat_times也可以提出到外面进行统一计算,减少了对BLOCK和num_16的数据依赖,也优化了不合理的指令。

进行优化后重新测试的结果如下图所示,可以看到对于排序轴数小于2048的情况下,已经没有流水打断提示了,即优化是有效的。

使用专家系统总结
通过专家系统工具的分析,可以快速找出算子实现的效率和性能问题。并根据向量流水等不同维度的分析(三个维度分析请参考https://www.hiascend.com/document/detail/zh/mindstudio/50RC1/msug/msug_000349.html),给出对应的优化建议。根据优化意见和开发经验分析,可以有针对性的进行性能分析,改进实现代码,提升了算子调优效率。
经验总结
- UT测试的时候出现如下问题,case不能识别,显示缺少absl-py模块。


解决方法:本地默认的Python环境中安装absl-py模块,而不是在配置的Python编译器中安装absl-py模块,它识别的时候是根据本地的默认的Python环境识别的。
- 使用专家系统时,在tmmodel模式下出现算子case识别不出来。

解决方法:打开UT的代码,没有精度测试case,使用add_precision_case()添加精度测试case,如果使用add_case方式是无法识别的。
- 有时候使用专家系统的时候出现如下问题。测试案例显示测试成功,但是不能拉起专家系统。
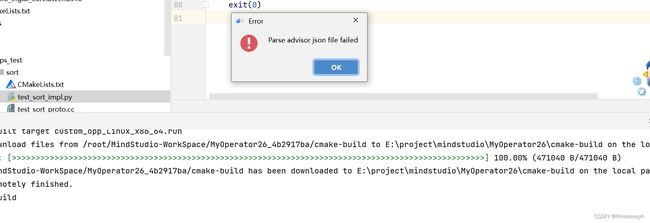
解决方法:方法一:检查UT测试代码是否有问题,方法二:尝试关闭MindStudio,并重新打开项目运行测试,暂时不明什么原因导致,但确实是有效的解决方法。
关于MindStudio更多的内容
如果需要了解关于MindStudio更多的信息,请查阅昇腾社区中MindStudio的用户手册(https://www.hiascend.com/document/detail/zh/mindstudio /50RC1/msug/msug_000433.html),里面有算子开发、模型开发等各种使用操作的详细介绍。
如果在使用MindStudio过程中遇到任何问题,也可以在昇腾社区中的昇腾论坛(https://www.huaweicloud.com/s/JU1pbmRTdHVkaW_mkK3lu7ol/t_60_p_1)里进行提问,会有华为内部技术人员对其进行解答,如下图。