0基础看-最大似然函数,原理,基本概念,例子
目录
1.最大似然估计的总体概念
2.基本概念与问题引出
3.最大似然估计原理
4.极大似然估计的公式[3]
5.极大似然估计的例子
参考文献
1.最大似然估计的总体概念
最大似然估计的功能:根据已有的数据(手中已经获取到的杂乱无章的数据,X的分布规律已知),估计模型的参数。其中这个参数可以是对应数据分布类型的均值、方差、协方差 ,也可以是系数向量
,也可以是系数向量 。
。
最大似然估计(Maximum Likelihood Estimate,MLE)似然也可以理解为可能性probability。
延伸一下,可以延伸至概率论(probabilty)和数理统计(statistics),两者是互逆的过程。概率论可以看成是由因推果,数理统计则是由果溯因[1]。
总结就是:概率是已知模型和参数,推数据。统计是已知数据,推模型和参数[2]。
其中本文涉及到的基本概念有:似然函数,先验概率,后验概率,贝叶斯分类
2.基本概念与问题引出
在说最大似然函数的基本概念前,先看一个很不错的文献[3]中的例子。是最最基本的贝叶斯决策(Bayes Decision)的例子。为方便描述现搬运如下。
经典的贝叶斯公式为: 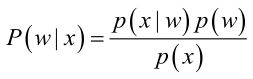
其中:p(w)为先验概率,表示每种类别分布的概率;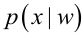 为类条件概率,表示在某种类别前提下,某事发生的概率;而
为类条件概率,表示在某种类别前提下,某事发生的概率;而 为后验概率,表示某事发生了,并且它属于某一类别的概率,有了这个后验概率,我们就可以对样本进行分类。后验概率越大,说明某事物属于这个类别的可能性越大,我们越有理由把它归到这个类别下。
为后验概率,表示某事发生了,并且它属于某一类别的概率,有了这个后验概率,我们就可以对样本进行分类。后验概率越大,说明某事物属于这个类别的可能性越大,我们越有理由把它归到这个类别下。
我们来看一个直观的例子:已知:在夏季,某公园男性穿凉鞋的概率为1/2,女性穿凉鞋的概率为2/3,并且该公园中男女比例通常为2:1,问题:若你在公园中随机遇到一个穿凉鞋的人,请问他的性别为男性或女性的概率分别为多少?从问题看,就是上面讲的,某事发生了,它属于某一类别的概率是多少?即后验概率。
设:
由已知可得:
男性和女性穿凉鞋相互独立,所以
(若只考虑分类问题,只需要比较后验概率的大小,的取值并不重要)。 由贝叶斯公式算出:

对应的图解为[5]: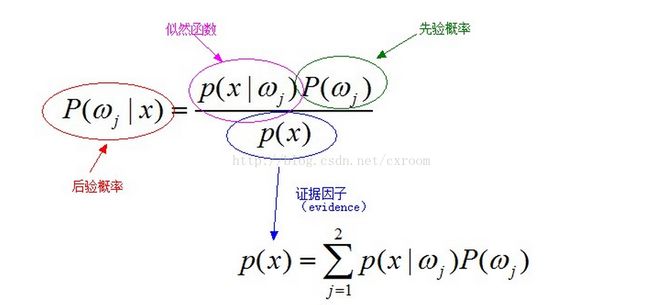
其中:什么是先验概率,后验概率,似然函数?
通俗的讲,先验概率就是事情尚未发生前,我们对该事发生概率的估计,例如全概率公式中P(B)就是先验概率,求解方法有很多种,全概率公式是一种,也可以根据经验等,例如抛一枚硬币头向上的概率为0.5。
后验概率则是表示在事情已经发生的条件下,要求该事发生原因是有某个因素引起的可能性的大小。
先验概率是在缺乏某个事实的情况下描述一个变量;而后验概率(Probability of outcomes of an experiment after it has been performed and a certain event has occured.)是在考虑了一个事实之后的条件概率。
如《概率论与数理统计 第四版 浙江大学》P20的例子:根据统计得知机器的良好率为95%,当生产出产品后,更新机器良好率为97%,其中95%是未发生事件的概率,97%为发生事件后调整的概率。
通过贝叶斯公式,利用先验概率、似然函数可以计算出后验概率。
似然函数的在书本中的意思就是 ,可以当做联合分布来理解。
,可以当做联合分布来理解。
3.最大似然估计原理
但是在实际问题中并不都是这样幸运的,我们能获得的数据可能只有有限数目的样本数据,而先验概率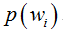 和类条件概率(各类的总体分布)
和类条件概率(各类的总体分布) 都是未知的。根据仅有的样本数据进行分类时,一种可行的办法是我们需要先对先验概率和类条件概率进行估计,然后再套用贝叶斯分类器。
都是未知的。根据仅有的样本数据进行分类时,一种可行的办法是我们需要先对先验概率和类条件概率进行估计,然后再套用贝叶斯分类器。
先验概率的估计较简单,1、每个样本所属的自然状态都是已知的(有监督学习);2、依靠经验;3、用训练样本中各类出现的频率估计。
类条件概率的估计(非常难),原因包括:概率密度函数包含了一个随机变量的全部信息;样本数据可能不多;特征向量x的维度可能很大等等。总之要直接估计类条件概率的密度函数很难。解决的办法就是,把估计完全未知的概率密度转化为估计参数。这里就将概率密度估计问题转化为参数估计问题,极大似然估计就是一种参数估计方法。当然了,概率密度函数的选取很重要,模型正确,在样本区域无穷时,我们会得到较准确的估计值,如果模型都错了,那估计半天的参数,肯定也没啥意义了。
上面说到,参数估计问题只是实际问题求解过程中的一种简化方法(由于直接估计类条件概率密度函数很困难)。所以能够使用极大似然估计方法的样本必须需要满足一些前提假设。
重要前提:训练样本的分布能代表样本的真实分布。每个样本集中的样本都是所谓独立同分布的随机变量 (Independent Identical Distribution,iid条件),且有充分的训练样本。
极大似然估计的原理是[6]:概率大的事件在一次观测中更容易发生; 在一次观测中发生了的事件其概率应该大。 总结起来,最大似然估计的目的就是,利用已知的样本结果,反推最有可能(最大概率)导致这样结果的参数值[3]。
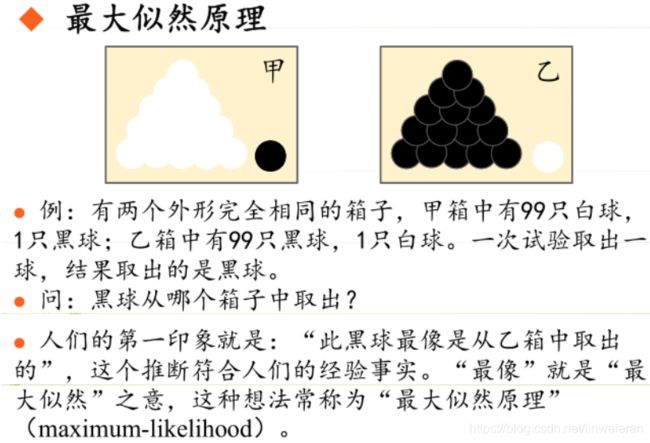
极大似然估计是建立在极大似然原理的基础上的一个统计方法,是概率论在统计学中的应用。极大似然估计提供了一种给定观察数据来评估模型参数的方法,即:“模型已定,参数未知”。通过若干次试验,观察其结果,利用试验结果得到某个参数值能够使样本出现的概率为最大,则称为极大似然估计。
4.极大似然估计的公式[3]
由于样本集中的样本都是独立同分布,可以只考虑一类样本集D,来估计参数向量θ。记已知的样本集为:

似然函数(linkehood function):联合概率密度函数 称为相对于
称为相对于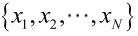 的θ的似然函数。
的θ的似然函数。
如果是参数空间 中能使似然函数
中能使似然函数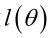 最大的θ值,则应该是“最可能”的参数值,那么就是θ的极大似然估计量。它是样本集的函数,记作:
最大的θ值,则应该是“最可能”的参数值,那么就是θ的极大似然估计量。它是样本集的函数,记作:

求解似然函数:
ML估计:求使得出现该组样本的概率最大的θ值。

实际中为了便于分析,定义了对数似然函数:
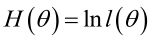

4.1 未知参数只有一个(θ为标量)
在似然函数满足连续、可微的正则条件下,极大似然估计量是下面微分方程的解:

4.2 未知参数有多个(θ为向量)
则θ可表示为具有S个分量的未知向量: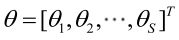
记梯度算子: 
若似然函数满足连续可导的条件,则最大似然估计量就是如下方程的解。

方程的解只是一个估计值,只有在样本数趋于无限多的时候,它才会接近于真实值。
5.极大似然估计的例子
之前看过很棒的文章现在找不到了。。。难受。。。找到继续写
参考文献[2,3]中有详细的例子,不再赘述。
----------------------------分割线----------------------找到原来的那个文章[7]了------------------------------
文献[7]中表述如下:
一:频率学派和贝叶斯学派的区别?
首先讲下,在概率统计上,有两个学派,一个是频率学派,一个是贝叶斯学派,“最大”似然是频率学派提出的。为什么将最大用引号呢,因为似然函数是两个学派共有的。那频率学派和贝叶斯学派有什么根本的区别呢?
你从名字就可以看出来他们关心的就是我有多大把握去圈出那个“唯一”的真实参数。而贝叶斯学派恰恰相反,他们关心参数空间里的“每一个值”,因为他们觉得我们又没有上帝视角,怎么可能知道哪个值是正确的呢?所以参数空间里的每个值都有可能是真实模型使用的值,区别只是概率不同而已。最好诠释这种差别的例子就是想象如果你的后验分布是双峰的,频率学派的方法会去选这两个峰当中较高的那一个对应的值作为他们的最好猜测,而贝叶斯学派则会同时报告这两个值,并给出对应的概率。
在二十世纪之前,频率学派发展很迅速很快占据了概率统计半壁江山,现在很多本科教材大量的篇幅使用的都是频率学派的认识。而贝叶斯学派的东西只是一笔带过,很大程度上是因为在贝叶斯学派中很多推断都是基于概率分布,直到上世纪90年代依靠电子计算机的迅速发展,以及抽样算法的进步(GIBBS采样)使得对于任何模型任何先验分布都可以有效地求出后验分布,贝叶斯学派才重新回到人们的视线当中。
二:.什么叫似然函数,它从直觉意义上表示什么意思,为什么要进行“最大”似然估计?为什么在最优化的时候需要取log?
2.1 什么叫似然函数?为什么进行最大似然估计?
似然的意思是可能性,它的意思和possibility的意思是一样的。
给定输出x时,关于参数θ的似然函数L(θ|x)(在数值上)等于给定参数θ后变量X的概率:

首先它表示的是所有样本同时发生的概率,而为什么需要最大的呢,因为当你样本已经拿到你手上了,即表示这个事件已经发生了,那么最大化,这个事件的概率,从而得到参数θ,在直觉上是有道理的。
2.2 为什么需要取log?
那么为什么在最优化的时候需要取log呢?有两点原因。
1.为了求解简单,在求导的时候。
2.为了避免数值的下溢。因为L(θ|x)是由很多概率相乘,而每个概率都是小于一的,如果样本量很大的时候,那么很容易导致L(θ|x)非常非常的小。
2.3 一个例子
举个例子,在历史上有很多人比价有探(zhi)索(zhang)性,有很多数学家做过相关的实验,比如:
德摩根: 实验次数:4092 正面次数:2048
蒲丰: 实验次数:4040 正面次数:2048
费勒: 实验次数:10000 正面次数:4979
罗曼诺夫斯基 :实验次数:80640 正面次数:39699
上面几位老哥,当然要数罗曼诺夫斯基,这位老哥掷了80640次,很执着,为了探索冥冥之中操纵自然规律的上帝。
下面我们用python求出,罗曼诺夫斯基掷了80640次,的似然函数,及相应的最大值!!!
求解:p:表示正面的概率,1-p:表示反面的概率。
![]()
对似然函数取log得到如下公式:
![]()
python代码为:
import math
import matplotlib.pyplot as plt
def iandfrange(start, *args):
"""
输入:函数可接收最多三个参数,依次分别是起始值,结束值和步长,可以做任意整数和小数的range功能
输出:返回值为包含起始值的,以起始值迭代加步长,直到最后一个<=结束值的值为止的一个列表
约定:
1.如果只传入2个参数,自动匹配给起始值和结束值,步长默认为1
2.如果只传入1个参数,自动匹配给结束值,起始值默认为0,步长默认为1
"""
try:
args[2]
except Exception as e:
pass
else:
raise Exception(ValueError, "The function receive three args!")
# 保证传入的3个参数能正确匹配到start,end和step三个变量上
try:
end, step = args[0], args[1]
except IndexError:
try:
end = args[0]
except IndexError:
end = start
start = 0
finally:
step = 1
# 参数正确性校验,包括对step是否是int或float的校验,提示用户输出数据可能只有start的校验以及start>=end的情况
try:
try:
a, b = str(step).split(".")
roundstep = len(b)
except Exception as e:
if isinstance(step, int):
roundstep = 0
else:
raise Exception(TypeError, "Sorry,the function not support the step type except integer or float!")
if start + step >= end:
print("The result list may include the 'start' value only!")
if start >= end:
raise Exception(ValueError,
"Please check you 'start' and 'end' value,may the 'start' greater or equle the 'end'!")
except TypeError as e:
print(e)
else:
pass
# 输出range序列
lista = []
while start < end:
lista.append(start)
start = round(start + step, roundstep)
return lista
# 最大似然函数
X = []
Y = []
def possibility():
result = {}
X = iandfrange(0.1, 1, 0.01)
for i in X:
y = 39640*math.log(i)+(80640-39640)*math.log(1-i) # 罗曼诺夫斯基投硬币,求其正面的概率
Y.append(y)
result[i] = Y
print(result)
y_max = max(Y)
x_max = X[Y.index(y_max)]
print(x_max)
print("正在画图:")
# 衡坐标表示每一个工作,纵坐标表示real_runtime 与 pred_runtime
print(len(X))
print(len(Y))
plt.scatter(X, Y, s=5, c="b") # 蓝色实际runtime
# plt.scatter(list(range(100, 200)), Y[100:200], s=5, c="m") # 酒红色预测runtime
# plt.plot(x, y_hat)
plt.show()
if __name__=="__main__":
possibility()运行结果为:
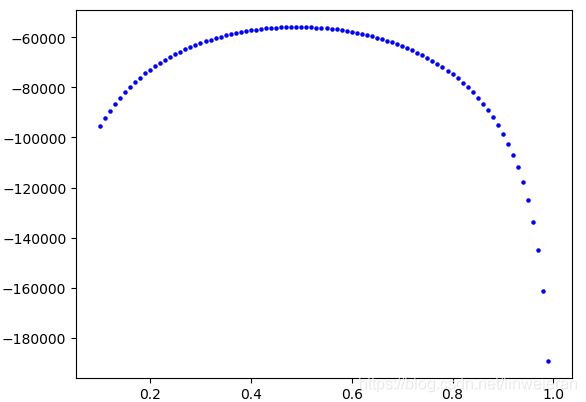
p=0.49
参考文献
[1] 伯努利分布的最大似然估计:https://www.cnblogs.com/canyangfeixue/p/9274141.html
[2] 详解最大似然估计(MLE)、最大后验概率估计(MAP),以及贝叶斯公式的理解:http://blog.csdn.net/u011508640/article/details/72815981
[3]极大似然估计详解:https://blog.csdn.net/zengxiantao1994/article/details/72787849
[4] 贝叶斯公式的直观理解(先验概率/后验概率):https://www.cnblogs.com/yemanxiaozu/p/7680761.html
[5] 先验概率、后验概率、条件概率:https://blog.csdn.net/cxroom/article/details/41452337
[6] 最大似然函数最大似然原理小结:最大似然估计法的一般步骤:例子:https://cloud.tencent.com/developer/article/1144944
[7] 全面理解似然函数与贝叶斯公式: https://blog.csdn.net/baidu_15238925/article/details/81291281