SiamMask阅读翻译笔记
目录
Section1:方法引言
Seciton2 :related work:简要概述相关的、代表性的,目标跟踪和半监督VOS实现的成果。
Section 3: descrption our proposal:详细描述方法
section 4: 评估,分别在跟踪和视频分割两个相关领域评估算法
其他:
原文名称:Fast Online Object Tracking and Segmentation: A Unifying Approach
github代码及paper:https://github.com/foolwood/SiamMask
Section1:方法引言
SiamMask:仅靠一次框选输入,就能完成实时跟踪+快速分割。通过二值分割任务,提升了siameseFC的离线训练过程。训练之后,只用一次初始化框,就能在线实时(55fps)完成任意目标的分割、任意角度定框。
online 有2层意思:1)视频是实时的输入流;2)跟踪算法不能利用未来的某帧视频来预测当前目标的位置;
用框(包括轴对齐框和旋转框)标注有2个好处:1)数据标注的开销减少;2)快速和简单的初始化过程;
半监督视频目标分割:就是当在第一帧中确定一个任意的目标后,算法可以跟踪出它的位置。这篇论文中的目标描述,是一个代表像素点是否属于目标的、二值化的分割mask。显然,像素级的目标预测比只用框标注需要用到更多的计算资源,传统的算法是每帧几秒的速度,研究更快速的方法近年来称高涨趋势,但最快的依然没有实现实时(作者的创新点伏笔)。
SiamMask方法:是一个多任务学习的方法,来同时解决实时的跟踪、标注mask这两个问题。灵感的来源是:SiameseFC和YouTube-VOS,前者在离线训练情况下,成功实现了百万量级视频帧对(原图和label成对)时的快速标注,后者是一个最近开放的像素级标注的视频标注数据集。
SiamMask要做的是保持离线训练能力、和算法的在线速度,同时重新定义了目标用框表示的方法,即作者要用mask表示目标。(立下flag)。SiamMask同时训练了三个任务的孪生网络,每个任务分支对应一个不同的策略,实现在新的一帧中建立跟踪目标和候选区域的关联。具体地三个任务分别是:1)相似度测量,即衡量出,目标物体与多个滑动窗口中的候选区域,产生一个能反映物体位置的密集响应映射。为提炼信息,2)同时又开了两个深层任务,包括RPN生成的框和基于二值分割的分类任务。其中,二值图在分割和跟踪时,只用于离线的计算分割损失。3)在这个结构中,每个任务都是一个共享的CNN网络,最终的损失是把三个输出结果的求和。
Seciton2 :related work:简要概述相关的、代表性的,目标跟踪和半监督VOS实现的成果。
(1)目标追踪方面
跟踪问题的解决方法中,当前最流行的范式是,从视频的第一帧中提供的背景信息中,在线训练一个判别分类器,然后update it。例如,1)使用相关滤波器的在线判别分类器,判断任意目标的模板和2d翻译,这个方法对“检测式跟踪”来说,非常快速和高效,它提高了多通道构想、空间约束和深度特征等方法的采用。2)离线训练的视频帧对的相似度函数,在验证阶段,这个函数可以在新的视频帧上,简单地评估相似度。尤其是,siameseFC方法,通过region proposals区域生成方法、hard negative mining 难负样本挖掘、ensembling融合和memory networks记忆网络等调优方法,显著地提高了跟踪算法的性能。
上面这些目标追踪的算法,使用的是框来进行目标的初始化和位置预测,简单方便的另一面是,一个框并不能很好地代表或者叫拟合我们的追踪目标,完成这一目标,就需要一个能基于初始化的框产生二值化mask的跟踪器。而这样的跟踪方式并不多见,仅有:1)基于超像素的方法by Yeo,这一方法的缺陷是慢4fps,当使用cnn网络后,更是会有60倍的速度下降,速度暴跌至0.1fps,这样的速度对于跟踪和vos来说都不具有竞争力。2)perazzi的方法,因为在验证阶段的调优过程,也很慢。
(2)半监督式的视频目标分割方面:semi-supervised video object segmentation
有以下几种复合vos的方法:1)BOT类的方法一般认为,跟踪器接收到的帧数据是顺序式的,一般关注在实现超过典型视频帧的速度,相反地,VOS算法更关注目标物体的精确表示。为了有效利用视频帧的连贯特性,有方法提出将第一帧的分割结果,通过图形标注方法,传播至时间上相邻的帧上,比如spatio-temporal MRF方法,其中时域相关性用光流模型,空域相关性用CNN模型表达;2)另一种方法,独立的处理视频帧,与大多数的跟踪方法相似,不考虑时间的信息,依靠事先训练的全卷积网络来分类,然后验证阶段用第一帧提供的背景mask进行调优。类似的,MaskTrack方法是从开始的单个图像训练,在验证阶段利用最近帧mask预测和光流的时间信息,作为网络的输入。
为了提高分割精度,VOS的方法们通常在test阶段会增加调优、数据增强、光流等计算密集型操作,这些方法的特征是低速不能实时操作,所以即便是几秒钟的视频,需要几分钟甚至几个小时来进行VOS。这一领域亟需能提高速度的方法,据调研,相对较快的方法有:1)Yang,在test阶段,使用了一个叫modulator的超网络meta-network,来快速适应分割网络的参数。2)Wug的方法没有使用任何调优策略,而是采用一个多阶段训练的编解码孪生网络(encoder-decoder Siamese architecture)。这些方法都低于10fps(比SiamMask方法慢10倍)。
Section 3: descrption our proposal:详细描述方法
SiamMask采用SiamFC全卷积孪生网络和SiamRPN,来实现在线可操作和快速。
(1)SiamFC
是跟踪系统这座大厦的基石,它采用离线训练的全卷积网络,来完成模板 z 和大一点的搜索域 x 的比较,然后得到一个密集响应图(response map),其中,z 是一个w*h大小、以目标对象为中心裁剪图, x 是大一些的裁剪图、以最后一次估计的目标的位置为中心。这两个输入经过相同的CNN网络 ![]() , 生成两个互相关的特征图Eq1:
, 生成两个互相关的特征图Eq1:![]() 。
。
其中,响应图的每一个空间元素,代表了候选框(RoW)的响应。例如,![]() ,编码表示了模板z和x中的第n个候选窗之间的相似度,对于SiamFC,卷积目标是响应图中的最大值,代表了搜索区域x中的目标所在位置。为了使每个RoW来包含跟踪目标的更丰富信息,这里做了个修改,将上面的互相关方程Eq1,改为一个深度互相关,生成的是一个多通道的响应图。逻辑损失设为
,编码表示了模板z和x中的第n个候选窗之间的相似度,对于SiamFC,卷积目标是响应图中的最大值,代表了搜索区域x中的目标所在位置。为了使每个RoW来包含跟踪目标的更丰富信息,这里做了个修改,将上面的互相关方程Eq1,改为一个深度互相关,生成的是一个多通道的响应图。逻辑损失设为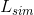 .
.
(2)SiamRPN
基于RPN分支极大地提高了SiamFC生成候选框的速度,同时实现了使用可变纵横比的框来估计目标的位置。尤其,SiamRPN中每个RoW编码了锚点k和相应的目标或背景分数的集合。所以,SiamRPN输出预测框位置 和分类得分
和分类得分![]() ,这两个输出分支采用了平滑L1和交叉熵损失来训练。
,这两个输出分支采用了平滑L1和交叉熵损失来训练。
(3)SiamMask
1)mask生成分支:与现有的跟踪方法依赖低分辨目标表示不同,SiamMask提出了生成逐帧二值分割mask也很重要的观点,同时也说明了一个全卷积网络产生的RoW中也编码了生成像素级二值mask的必要信息,只需要用额外的分支和loss来扩展现有的Siamese 跟踪器。
使用简单的二层神经网络![]() (含可学习的参数φ)来预测每个RoW对应的w*h的二值mask
(含可学习的参数φ)来预测每个RoW对应的w*h的二值mask 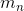 ,Eq.2:
,Eq.2:![]() 。
。
方程中可以看出,mask的预测是关于分割x和目标z的方程,这样,z可以作为分割过程的参考,对每一个不同的参考图像z,网络将为x产生一个不同的分割mask。
2)损失方程设定:在训练过程中,每个RoW标注了一个二值标签,与一个像素级的大小为W*h的mask 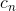 关联。
关联。![]() 表示在第n个RoW中的目标mask的像素点(i,j)对应的标签。mask预测的损失方程是一个对所有RoWs的二值逻辑回归:
表示在第n个RoW中的目标mask的像素点(i,j)对应的标签。mask预测的损失方程是一个对所有RoWs的二值逻辑回归:
分类层hφ包含的w*h个分类器,每个分类器用来判断某个特定的输入像素是否属于候选窗中的目标对象,Lmask正RoWs.
3)FCN和Mask R-CNN式的语义分割方法,会在整个网络中维护一个明确的空间信息表,SiamMask从扁平化的目标表示生成的mask,示例中是有深度互相关生成的17*17的RoWs。负责分割任务的hφ网络由两层1*1的卷积层构成,分别是256通道和63^2个通道,这使得每个像素分类器可以充分利用RoW中的信息,并对x中对应的候选窗有一个完整的view,这对于辨别与目标相似的实例的干扰很重要。为了产生一个更精确的目标mask,采用了由上采样层和Skip connections构成的多提炼模型,合并低高分辨率特征。
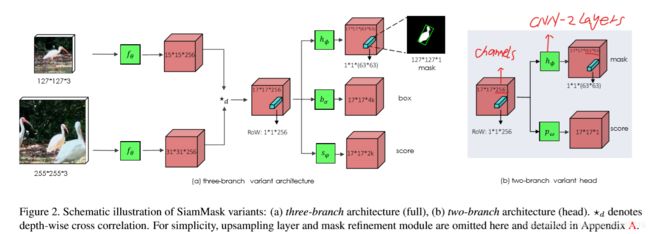
4)两个网络形式变体:在实验中,我们用分割分支和损失方程Lmask增强了SiamFC和SiamRPN的结构,实现了两分支和三分支的变形SiamMask。这两个分支的优化损失方程是:![]() 和
和![]() ,对于
,对于![]() ,当锚点框的IOU大于0.6时,RoW是正值(yn=1),否则为负(yn = -1 )。对于
,当锚点框的IOU大于0.6时,RoW是正值(yn=1),否则为负(yn = -1 )。对于![]() ,与eq3中定正负的策略相同(属于为正,不属于为负)。不考虑寻找方程中的超参数,只简单借鉴另一篇论文中的经验,设定λ1 = 32 ,λ2 = λ3 = 1。SiamMask网络中的这两个变体结构如下图:
,与eq3中定正负的策略相同(属于为正,不属于为负)。不考虑寻找方程中的超参数,只简单借鉴另一篇论文中的经验,设定λ1 = 32 ,λ2 = λ3 = 1。SiamMask网络中的这两个变体结构如下图:
5)动态框的生成:VOS需要二值mask、传统VOT算法需要框代表最终目标位置,文章提出了三种由二值mask生成bounding box的策略:轴对齐矩形框Min-Max、方向可旋转的最小框MBR、Opt approaches自动生成框优化策略。

6)实施细节:
A、网络结构方面,连个变体网络使用了ResNet-50作为![]() 的主干。用步长为1的卷积操作将输出层的步长减少为8,以在更深的网络层上获得更高的空间分辨率。采用膨胀卷积扩大了接受域。给共享的主干网络
的主干。用步长为1的卷积操作将输出层的步长减少为8,以在更深的网络层上获得更高的空间分辨率。采用膨胀卷积扩大了接受域。给共享的主干网络![]() 增加了非共享的调整层。
增加了非共享的调整层。
B、训练阶段:采用127*127的模板、255*255的搜索域,并随机地抖动模板和搜索域。主干网络提前在ImageNet-1k分类任务上进行训练,准备阶段使用了SGD,学习率线性地提高后下降,用COCO、ImageNet-VID和YouTube-VOS训练模型。
C、推论:在跟踪阶段,SiamMask每帧预测一次,在两个变体网络中,用分类分支的最大得分的位置作为输出mask,使用逐帧的激活函数,实现mask分支的二值化操作。在两分支变体中,第一帧之后的视频中,会将输出的mask放入Min-Max Box,作为裁剪下一帧搜索区域的参考。而在三分之变体中,是使用最高得分的box分支结果作为下一帧裁剪的参考。
section 4: 评估,分别在跟踪和视频分割两个相关领域评估算法
(1)VOT评估
1)数据集和评估指标:VOT-2016和VOT-2018,标注都采用的旋转框。采用VOT-2016是为了说明不同目标表示类型是如何影响跟踪性能的,第一个实验,评价指标采用mIOU和AP@{0.5,0.7}IOU,然后和在VOT-2018上使用官方VOT工具包的EAO对比,EAO是一个同时评估跟踪器的精度和鲁棒性的方法。
2)描述目标的重要性:现有的跟踪方法一般用固定尺寸或可变长宽比的轴对齐矩形框来预测,本实验的研究兴趣点在探究用一个逐帧的二值mask可以提高跟踪性能到何种程度,为了聚焦在表示精确上,本次实验忽略时域方面采用随机的方式来帧采样,这个方法,已经在从VOT-2016视频序列中,随机裁剪的搜索域数据集上进行了验证。
表1中对三分支变体的结果,用Min-max,MBR和Opt方法进行比较,同时将SiamFC和SiamRPN上用固定和可变长宽比的描述方式作为参考,同时考虑三种可以逐帧获取背景信息并且作为不同表示策略上限的oracles:第一个:固定长宽比oracle使用逐帧北背景区域,但是按照第一帧产生的轴对齐框来固定了长宽比。第二个:Min-Max oracle使用旋转背景矩形框的最小包裹矩形来产生轴对齐框。第三个:MBR oracle使用背景的旋转的最小矩形框。这三个oracle可以分别代表SiamFC、SiamRPN和SiamMask的性能上限。

总之,实验表明了MBR策略从目标的二值mask产生旋转框的方法,较轴对齐的框生成策略,有明显优势。
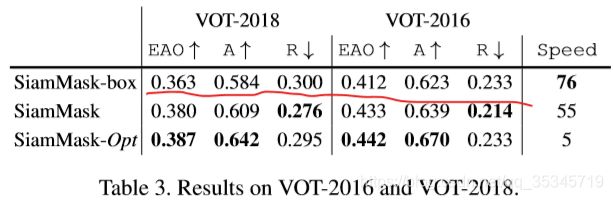
3)VOT-2018和VOT-2016上测试结果:表2中拿:两个变体的SiamMask、MBR策略和Opt策略,与VOT-2018上5个最新发表的跟踪方法作对比。

上表的对比结果,可以看出三点:A、SiamMask-Opt的性能最高,但是由于框产生策略耗费算力,导致速度降低不能实时。B、SiamMask三分支变体在实时情况下,EAO可以很高;C、即便是二分支的变体,也可以与最好的SA-Siam-R同等水平,比其他的实时算法有明显优势。
这是由于,SiamMask依靠更丰富的目标表示,且SA_Siam_R也是通过多旋转和缩放的bounding box来进行更精确的目标表示方法,只是他们的表示方法仍然是局限在固定的长宽比框上,使他们算法提升的空间有限。
下表说明了框生成分支对性能提升的影响。
(2)半监督VOS评估:突出实时和初始化简单的特点
1)数据集和参数设置:DAVIS-2016和DAVIS-2017和YouTube-VOS。评测指标:Jaccard index相似 系数来表示区域相似度,F测度来表示外廓准确度。每个测量C考虑平均Cm,返回Co, decayCD。
2)DAVIS和YouTube-VOS上的结果:比其他的方法,突出实时快速准确。结果如下三个图:
(3)实验分析:
1)网络结构:从下表的结果中看出三个结论:A、第一行显示更新f0的网络结构,可以实现性能提升,但是会降低速度。B、二分支和三分支的SiamMask明显提高了SiamFC和SiamRPN的基线。C、refinement方法对外形精确度提升很关键。
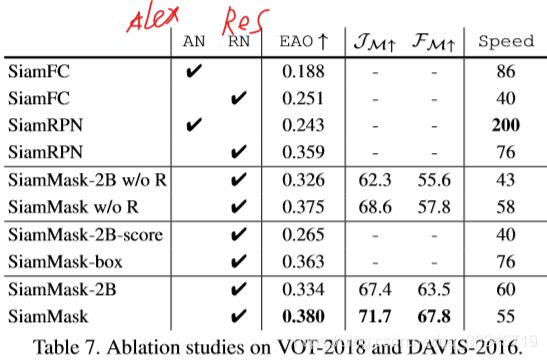
2)多任务训练:在表7中看出两个变体的提升效果。
3)时效性:在NVIDIA RTX2080GPU,55或60fps,相对于两分支和三分支能够实时,最大的耗费算力的是特征图的产生f0.
4)失败案例:如下图所示,对于目标运动模糊和非物体的实例,方法失败,这两种情况下,应关注在从前景图中分辨出模糊的目标。

其他:
(1)涉及到的应用场景:
跟踪+分割需要同时进行的场景:自动监视(automatic surveillance)、汽车导航(vehicle navigation)、视频标注(video labelling)、人机交互(human-computer interaction)、动作识别(activity recognition).
像素级需求的应用:视频编辑(video editing)和转描技术(rotoscoping)、
(2)涉及的数据集:
VOT-2018实时追踪、DAVIS-2017属于半监督VOS(vos的算法初始化,常用的方法包括调优fine tuning、数据增强data augmentation、光流法optical flow)。