TBE DSL开发方式实现Tensorflow BatchNorm算子开发全流程
TBE DSL开发方式实现Tensorflow BatchNorm算子开发全流程
本文使用MindStudio作为IDE,TBE DSL为开发方式实现的BatchNorm算子开发流程,对应bilibili视频链接:基于MindStudio和TBE DSL的Tensorflow BatchNorm算子开发_哔哩哔哩_bilibili使用MindStudio作为IDE,TBE DSL开发方式开发的Tensorflow BatchNorm算子。如若有疑惑,可进入昇腾官网,在昇腾论坛中技术提问与技术交流,附昇腾论坛链接:https://bbs.huaweicloud.com/forum/forum-726-1.htm https://www.bilibili.com/video/BV17U4y1m7G4
https://www.bilibili.com/video/BV17U4y1m7G4
1. DSL算子基本概念
1.1 算子
深度学习算法由一个个计算单元组成,我们称这些计算单元为算子(Operator,简称OP)。在网络模型中,算子对应层中的计算逻辑,例如:卷积层(Convolution Layer)是一个算子;全连接层(Fully connected Layer, FC layer)中的权值求和过程,是一个算子。
对每一个独立的算子,用户需要编写算子描述文件,描述算子的整体逻辑、计算步骤以及相关硬件平台信息等。然后用深度学习编译器对算子描述文件进行编译,生成可在特定硬件平台上运行的二进制文件后,将待处理数据作为输入,运行算子即可得到期望输出。将神经网络所有被拆分后的算子都按照上述过程处理后, 再按照输入输出关系串联起来即可得到整网运行结果。

图1 算子全流程执行
1.2 TBE算子
TVM
随着深度学习的广泛应用,大量的深度学习框架及深度学习硬件平台应运而生,但不同平台的神经网络模型难以在其他硬件平台便捷的运行,无法充分利用新平台的运算性能。TVM(Tensor Virtual Machine)的诞生解决了以上问题,它是一个开源深度学习编译栈,它通过统一的中间表达(Intermediate Representation)堆栈连接深度学习模型和后端硬件平台,通过统一的结构优化Schedule,可以支持CPU、GPU和特定的加速器平台和语言。
TBE算子
TBE(Tensor Boost Engine)提供了基于开源深度学习编译栈TVM框架的自定义算子开发能力,运行在昇腾AI处理器的AI Core上,通过TBE提供的API可以完成相应神经网络算子的开发。
一个完整的TBE算子包含四部分:算子原型定义、对应开源框架的算子适配插件、算子信息库定义和算子实现。

图2 TBE算子全流程执行
昇腾AI软件栈提供了TBE(Tensor Boost Engine:张量加速引擎)算子开发框架,开发者可以基于此框
架使用Python语言开发自定义算子,通过TBE进行算子开发有以下几种方式:
-
DSL(Domain-Specific Language)开发
-
TIK(Tensor Iterator Kernel)开发
1.3 DSL算子
为了方便开发者进行自定义算子开发,TBE(Tensor Boost Engine)提供了一套计算接口供开发者用于组装算子的计算逻辑,使得70%以上的算子可以基于这些接口进行开发,极大的降低自定义算子的开发难度。TBE提供的这套计算接口,称之为DSL(Domain-Specific Language)。基于DSL开发的算子,可以直接使用TBE提供的Auto Schedule机制,自动完成调度过程,省去最复杂的调度编写过程。

图3 DSL算子介绍
DSL功能框架
-
开发者调用TBE提供的DSL接口进行计算逻辑的描述,指明算子的计算方法和步骤。
-
计算逻辑开发完成后,开发者可调用Auto Schedule接口,启动自动调度,自动调度时TBE会根据计算类型自动选择合适的调度模板,完成数据切块和数据流向的划分,确保在硬件执行上达到最优。
-
Auto Schedule调度完成后,会生成类似于TVM的I R(Intermediate Representation)的中间表示。
-
编译优化(Pass)会对算子生成的IR进行编译优化,优化的方式有双缓冲(Double Buffer)、流水线(Pipeline)同步、内存分配管理、指令映射、分块适配矩阵计算单元等。
-
算子经Pass处理后,由CodeGen生成类C代码的临时文件,这个临时代码文件可通过编译器生成算子的实现文件,可被网络模型直接加载调用。
TBE DSL提供的计算接口主要涵盖向量运算,包括Math、NN、Reduce、卷积、矩阵计算等接口。详细的接口介绍请参见[TBE DSL]。
2. 算子开发流程
算子开发通常包括:算子分析、创建算子工程、算子实现、编译、UT测试、ST测试、部署。

图4 算子开发流程介绍
1. 算子分析:确定算子功能、输入、输出,算子开发方式、算子OpType以及算子实现函数名称等。
2. 工程创建:通过MindStudio工具创建TBE算子工程,创建完成后,会自动生成算子工程目录及相应的文件模板,开发者可以基于这些模板进行算子开发。
3. 算子开发:
(1)算子代码实现:描述算子的实现过程。
(2)算子原型定义:算子原型定义规定了在昇腾AI处理器上可运行算子的约束,主要包含定义算子输入、输出、属性和取值范围,基本参数的校验和shape的推导,原型定义的信息会被注册到GE的算子原型库中。网络运行时,GE会调用算子原型库的校验接口进行基本参数的校验,校验通过后,会根据原型库中的推导函数推导每个节点的输出shape与dtype,进行输出tensor的静态内存的分配。
(3)算子信息定义:算子信息配置文件用于将算子的相关信息注册到算子信息库中,包括算子的输入输出dtype、format以及输入shape信息。网络运行时,FE会根据算子信息库中的算子信息做基本校验,判断是否需要为算子插入合适的转换节点,并根据算子信息库中信息找到对应的算子实现文件进行编译,生成算子二进制文件进行执行。
(4)算子适配插件实现:基于第三方框架(TensorFlow/Caffe)进行自定义算子开发的场景,开发人员完成自定义算子的实现代码后,需要进行插件的开发将基于Tensorflow/Caffe的算子映射成适配昇腾AI处理器的算子,将算子信息注册到GE中。基于TensorFlow/Caffe框架的网络运行时,首先会加载并调用GE中的插件信息,将TensorFlow/Caffe网络中的算子进行解析并映射成昇腾AI处理器中的算子。
(5)算子实现验证。
通过测试用例来验证算子实现代码的功能正确性和逻辑正确性。
- UT测试:即单元测试(Unit Test),仿真环境下验证算子实现的功能正确性,包括算子逻辑实现代码及算子原型定义实现代码。
- ST测试:即系统测试(System Test),可以自动生成测试用例,在真实的硬件环境中,验证算子功能的正确性。
4. 算子编译:将算子插件实现文件、算子原型定义文件、算子信息定义文件编译成算子插件、算子原型库、算子信息库。
5.算子部署:将算子实现文件、编译后的算子插件、算子原型库、算子信息库部署到昇腾AI处理器算子库,为后续算子在网络中运行构造必要条件。
3. 算子分析
进行算子开发前,开发者应首先进行算子分析,算子分析包含:明确算子的功能及数学表达式,选择算子开发方式(DSL方式或者TIK方式),根据所选的算子开发方式提供的API接口实现算子逻辑;明确详细算子规格,例如算子输入输出的数据类型、形态,算子实现的文件名、函数名等。

图5 算子分析流程
分析算子算法原理,提取算子的数学表达式

BatchNorm算子实现分为训练时的计算逻辑实现和推理时的计算逻辑实现
-
训练时,如上述表达式所示,以一个mini-batch长度的输入数据为计算基本单元进行归一化处理。
-
推理时,以实际输入长度的数据为计算单位进行归一化处理。
明确BatchNorm算子开发方式及使用接口
TBE DSL可为BatchNorm算子提供的接口:
-
tbe.dsl.vadd:两个tensor按元素相加
-
tbe.dsl.vadds:将tensor中每个元素加上标量scalar
-
tbe.dsl.vsqrt:对tensor中的每个元素取平方根
-
tbe.dsl.vsub:两个tensor按元素相减
-
tbe.dsl.vdiv:两个tensor按元素相除
-
tbe.dsl.vmul:两个tensor按元素相乘
-
tbe.dsl.vmuls:将raw_tensor中每个元素乘上标量scalar
上述接口满足BatchNorm算子的实现要求,选择TBE DSL方式进行算子实现是可行的。
4. MindStudio创建Tensorflow TBE算子工程
4.1 环境准备
CANN环境
进行自定义算子开发前,需要完成驱动及CANN软件的安装,详情可参见《CANN软件安装指南》。
MindStudio环境
使用MindStudio进行算子开发需配置Python、Java等环境,详情可参见《MindStudio安装指南》。
其他环境
除了手册中要求的环境依赖,也需要安装tensorflow,推荐1.15版本。如果采用windows和linux 的公开发环境,需要在本地和远端均配置好所需环境。
4.2 MindStudio创建BatchNorm算子工程
打开MindStudio, 选择New Project,在左边选择Ascend Operator,CANN version选择CANN版本,点击Next。

图6 创建算子工程
远程配置CANN,点击install,点击Remote Connection后的+,配置远程SSH连接,配置好后点击Test Connection,出现 ”Sucessfully connected!“即配置成功。
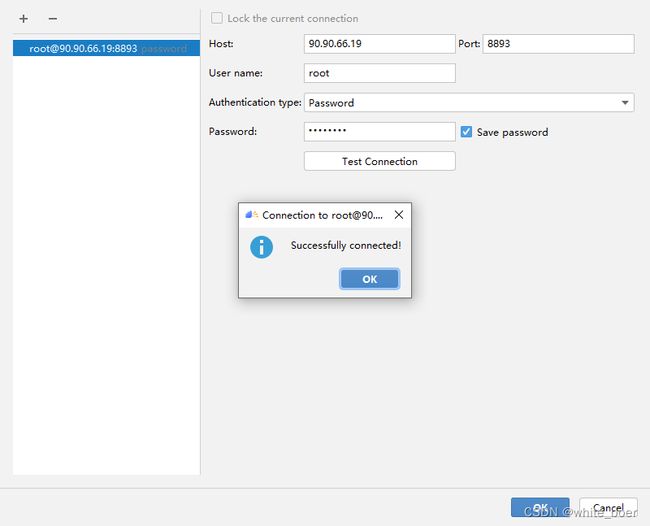
图7 远程连接
配置SSH远程链接后,选择服务器上安装的CANN版本,点击OK,等待配置完成。
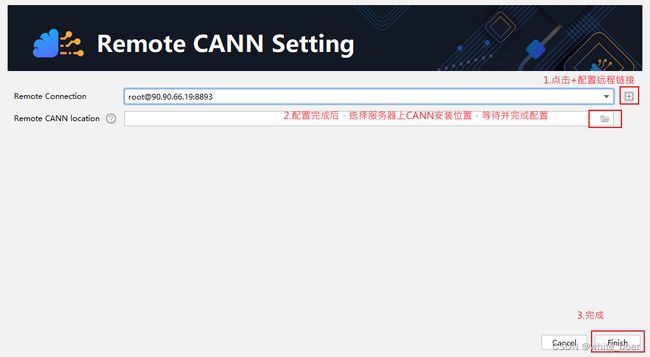
图8 远程加载CANN
点击Next后,选择DSL方式的TensorFlow的BatchNorm算子开发样例,完成创建。

图9 创建BatchNorm算子工程
4.3 算子工程配置Python SDK
在MindStudio界面左上角,选择File->Project Structure。
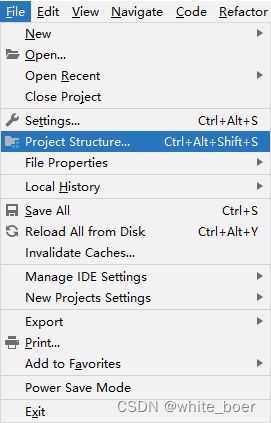
图10 打开Python SDK配置窗口
在弹出的窗口中,点击左侧的SDKs,点击上方的“+”添加Python SDK,从本地环境中导入Python3.7.5。

图11 本地添加Python SDK
再点击窗口左侧的Project,选择上一步添加的Python SDK。

图12 Project配置Python SDK
最后点击窗口左侧的Modules,点击“+”后选择Python,为Python Interpreter选择上述添加的Python SDK后,点击OK即可为算子工程添加好Python SDK。

图13 Modules添加Python SDK

图14 Modules配置Python SDK
5. BatchNorm算子工程结构和交付件
5.1 算子工程结构
创建好的BachNorm算子如案例下,主要对算子原型文件、实现文件、信息库文件和插件适配文件这四类文件进行开发。

图15 算子工程结构
5.2 算子原型
本案例中的BatchNorm算子原型为Tensorflow中的tf.nn.batch_normalization。
tf.nn.batch_normalization(
x, mean, variance, offset, scale, variance_epsilon, name=None
)5.3 插件适配文件
插件适配文件实现将Tensorflow网络中的算子进行解析并映射成昇腾AI处理器中的算子。

图16 插件适配文件
5.4 Python实现文件
通过调用TBE DSL接口,在算子工程下的“tbe/impl/batch_norm.py”文件中进行BatchNorm算子的实现,主要包括算子函数定义、算子入参校验、compute过程实现及调度与编译。
检测数据维度
def _check_shape_dims(shape, data_format, is_x=False):
if data_format == "NC1HWC0":
if len(shape) != 5:
error_detail = "The input shape only support 5D Tensor, len(shape) != 5, len(shape) = %s" % len(shape)
error_manager_vector.raise_err_input_shape_invalid("batch_norm", "len(shape)", error_detail)
elif data_format == "NDC1HWC0":
if len(shape) != 6:
error_detail = "The input shape only support 6D Tensor, len(shape) != 6, len(shape) = %s" % len(shape)
error_manager_vector.raise_err_input_shape_invalid("batch_norm", "len(shape)", error_detail)
elif is_x:
if len(shape) != 4:
error_detail = "The input shape only support 4D Tensor, len(shape) != 4, len(shape) = %s" % len(shape)
error_manager_vector.raise_err_input_shape_invalid("batch_norm", "len(shape)", error_detail)
else:
if len(shape) != 1:
error_detail = "The input shape only support 1D Tensor, len(shape) != 1, len(shape) = %s" % len(shape)
error_manager_vector.raise_err_input_shape_invalid("batch_norm", "len(shape)", error_detail)检验BatchNorm算子输入数据维度、数据排布格式
def _shape_check(shape_x, shape_scale, shape_offset,
mean, variance, is_training, data_format):
_check_shape_dims(shape_x, data_format, True)
_check_shape_dims(shape_scale, data_format)
_check_shape_dims(shape_offset, data_format)
para_check.check_shape(shape_x, param_name="x")
para_check.check_shape(shape_scale, param_name="scale")
para_check.check_shape(shape_offset, param_name="offset")
_check_dims_equal(shape_x, shape_scale, data_format)
_check_dims_equal(shape_x, shape_offset, data_format)
if not is_training:
shape_mean = mean.get("shape")
shape_variance = variance.get("shape")
para_check.check_shape(shape_mean, param_name="mean")
para_check.check_shape(shape_variance, param_name="variance")
_check_shape_dims(shape_mean, data_format)
_check_shape_dims(shape_variance, data_format)
_check_dims_equal(shape_x, shape_mean, data_format)
_check_dims_equal(shape_x, shape_variance, data_format)
elif mean is not None or variance is not None:
error_detail = "Estimated_mean or estimated_variance must be empty for training"
error_manager_vector.raise_err_specific_reson("batch_norm", error_detail)BatchNorm算子调用TBE DSL接口计算过程
def _output_data_y_compute(x, mean, variance, scale, offset, epsilon):
shape_x = shape_util.shape_to_list(x.shape)
y_add = tbe.vadds(variance, epsilon) #方差+epsilong
y_sqrt = tbe.vsqrt(y_add) #开根号
var_sub = tbe.vsub(x, mean) #x-均值
y_norm = tbe.vdiv(var_sub, y_sqrt) #归一化计算
scale_broad = tbe.broadcast(scale, shape_x) #scale广播与shape_x相同
offset_broad = tbe.broadcast(offset, shape_x) #offset广播与shape_x相同
res = tbe.vadd(tbe.vmul(scale_broad, y_norm), offset_broad) # res=scale*y_norm+offset
return resBatchNorm算子在推理时的计算逻辑实现
def _fused_batch_norm_inf_compute(x, scale, offset, mean, variance,
epsilon, is_py, format_data):
shape_x = shape_util.shape_to_list(x.shape)
is_cast = False
if x.dtype == "float16" and \
tbe_platform.cce_conf.api_check_support("te.lang.cce.vdiv", "float32"):
is_cast = True
x = tbe.cast_to(x, "float32")
mean_broadcast = tbe.broadcast(mean, shape_x)
var_broadcast = tbe.broadcast(variance, shape_x)
res_y = _output_data_y_compute(x, mean_broadcast, var_broadcast,
scale, offset, epsilon)
if is_cast:
res_y = tbe.cast_to(res_y, "float16")
if format_data == "NHWC":
axis = [0, 1, 2]
else:
axis = [0, 2, 3]
scaler_zero = 0.0
res_batch_mean = tbe.vadds(mean, scaler_zero)
res_batch_var = tbe.vadds(variance, scaler_zero)
if format_data not in ("NC1HWC0", "NDC1HWC0"):
res_batch_mean = tbe.sum(res_batch_mean, axis, False)
res_batch_var = tbe.sum(res_batch_var, axis, False)
res = [res_y, res_batch_mean, res_batch_var]
if not is_py:
res_reserve_space_1 = tbe.vadds(mean, scaler_zero)
res_reserve_space_2 = tbe.vadds(variance, scaler_zero)
if format_data not in ("NC1HWC0", "NDC1HWC0"):
res_reserve_space_1 = tbe.sum(res_reserve_space_1, axis, False)
res_reserve_space_2 = tbe.sum(res_reserve_space_2, axis, False)
res = res + [res_reserve_space_1, res_reserve_space_2]
return resBatchNorm算子在训练时的计算逻辑实现
def _fused_batch_norm_train_compute(x, scale, offset, epsilon,
is_py, format_data):
is_cast = False
if x.dtype == "float16" and \
tbe_platform.cce_conf.api_check_support("te.lang.cce.vdiv", "float32"):
is_cast = True
x = tbe.cast_to(x, "float32")
shape_x = shape_util.shape_to_list(x.shape)
if format_data == "NHWC":
axis = [0, 1, 2]
num = shape_x[0]*shape_x[1]*shape_x[2]
else:
axis = [0, 2, 3]
num = shape_x[0]*shape_x[2]*shape_x[3]
num_rec = 1.0/num
# 根据x的维度C计算保存均值
mean_sum = tbe.sum(x, axis, True)
mean_muls = tbe.vmuls(mean_sum, num_rec)
mean_broad = tbe.broadcast(mean_muls, shape_x)
# 根据x的维度C计算保存方差var
var_sub = tbe.vsub(x, mean_broad)
var_mul = tbe.vmul(var_sub, var_sub)
var_sum = tbe.sum(var_mul, axis, True)
var_muls = tbe.vmuls(var_sum, num_rec)
var = tbe.broadcast(var_muls, shape_x)
res_y = _output_data_y_compute(x, mean_broad, var, scale, offset, epsilon)
if is_cast:
res_y = tbe.cast_to(res_y, "float16")
res_batch_mean = tbe.vmuls(mean_sum, num_rec)
if format_data not in ("NC1HWC0", "NDC1HWC0"):
res_batch_mean = tbe.sum(res_batch_mean, axis, False)
if num == 1:
batch_var_scaler = 0.0
else:
batch_var_scaler = float(num)/(num - 1)
res_batch_var = tbe.vmuls(var_muls, batch_var_scaler)
if format_data not in ("NC1HWC0", "NDC1HWC0"):
res_batch_var = tbe.sum(res_batch_var, axis, False)
res = [res_y, res_batch_mean, res_batch_var]
if not is_py:
res_reserve_space_1 = tbe.vmuls(mean_sum, num_rec)
res_reserve_space_2 = tbe.vmuls(var_sum, num_rec)
if format_data not in ("NC1HWC0", "NDC1HWC0"):
res_reserve_space_1 = tbe.sum(res_reserve_space_1, axis, False)
res_reserve_space_2 = tbe.sum(res_reserve_space_2, axis, False)
res = res + [res_reserve_space_1, res_reserve_space_2]
return res总结BatchNorm算子在推理和训练时的计算逻辑实现compute函数
-
参数is_training=True时,调用训练时的计算逻辑实现compute函数
-
参数is_training=False时,调用推理时的计算逻辑实现compute函数
def batch_norm_compute(x, scale, offset, mean, variance, y,
batch_mean, batch_variance, reserve_space_1,
reserve_space_2, epsilon=0.001,
data_format="NHWC", is_training=True,
kernel_name="batch_norm"):
format_data = y.get("format")
is_py = reserve_space_1 is None
if is_training:
res = _fused_batch_norm_train_compute(x, scale, offset,
epsilon, is_py, format_data)
else:
res = _fused_batch_norm_inf_compute(x, scale, offset, mean, variance,
epsilon, is_py, format_data)
return res算子定义函数的实现,声明了算子输入信息、输出信息以及内核名称等信息,包含了上述的算子输入/输出/属性的校验、算子实现、调度与编译。
def batch_norm(x, scale, offset, mean, variance, y, batch_mean,
batch_variance, reserve_space_1, reserve_space_2,
epsilon=0.0001, data_format="NHWC",
is_training=True, kernel_name="batch_norm"):-
获取算子输入tensor与数据格式
shape_x = x.get("shape")
format_data = x.get("format")
if len(shape_x) == 2:
shape_x = list(shape_x) + [1, 1]
format_data = "NCHW"
elif len(shape_x) == 3:
shape_x = list(shape_x) + [1]
format_data = "NCHW"
elif format_data == "ND":
rest_num = functools.reduce(lambda x, y: x * y, shape_x[3:])
shape_x = list(shape_x[:3]) + [rest_num]
format_data = "NCHW"
shape_scale = scale.get("shape")
shape_offset = offset.get("shape")
if not is_training:
shape_mean = mean.get("shape")
shape_variance = variance.get("shape")
dtype_x = x.get("dtype")
dtype_scale = scale.get("dtype")
dtype_offset = offset.get("dtype")
if not is_training:
dtype_mean = mean.get("dtype")
dtype_variance = variance.get("dtype")
para_check.check_dtype(dtype_mean.lower(), ("float32", "float16"), param_name="mean")
para_check.check_dtype(dtype_variance.lower(), ("float32", "float16"), param_name="variance")-
检验数据是否符合规范
_format_check(x, data_format) -
检验算子输入shape、数据排布格式
_shape_check(shape_x, shape_scale, shape_offset, mean,
variance, is_training, format_data)-
检验算子输入类型
para_check.check_dtype(dtype_x.lower(), ("float16", "float32"), param_name="x")
para_check.check_dtype(dtype_scale.lower(), ("float32", "float16"), param_name="scale")
para_check.check_dtype(dtype_offset.lower(), ("float32", "float16"), param_name="offset")-
根据算子输入格式定义不同参数的shape
if format_data == "NHWC":
shape_scale = [1, 1, 1] + list(shape_scale)
shape_offset = [1, 1, 1] + list(shape_offset)
if not is_training:
shape_mean = [1, 1, 1] + list(shape_mean)
shape_variance = [1, 1, 1] + list(shape_variance)
elif format_data == "NCHW":
shape_scale = [1] + list(shape_scale) + [1, 1]
shape_offset = [1] + list(shape_offset) + [1, 1]
if not is_training:
shape_mean = [1] + list(shape_mean) + [1, 1]
shape_variance = [1] + list(shape_variance) + [1, 1]
elif format_data == "NDC1HWC0":
shape_x = [shape_x[0] * shape_x[1], shape_x[2], shape_x[3], shape_x[4], shape_x[5]]
shape_scale = [shape_scale[0] * shape_scale[1], shape_scale[2], shape_scale[3], shape_scale[4], shape_scale[5]]
shape_offset = shape_scale
if not is_training:
shape_mean = [shape_mean[0] * shape_mean[1], shape_mean[2], shape_mean[3], shape_mean[4], shape_mean[5]]
shape_variance = [shape_variance[0] * shape_variance[1], shape_variance[2], shape_variance[3], shape_variance[4], shape_variance[5]]-
使用TVM的placeholder接口对输入tensor进行占位,返回tensor对象
x_input = tvm.placeholder(shape_x, name="x_input", dtype=dtype_x.lower())
scale_input = tvm.placeholder(shape_scale, name="scale_input",
dtype=dtype_scale.lower())
offset_input = tvm.placeholder(shape_offset, name="offset_input",
dtype=dtype_offset.lower())
if is_training:
mean_input, variance_input = [], []
else:
mean_input = tvm.placeholder(shape_mean, name="mean_input",
dtype=dtype_mean.lower())
variance_input = tvm.placeholder(shape_variance, name="variance_input",
dtype=dtype_variance.lower())-
调用compute实现函数
res = batch_norm_compute(x_input, scale_input, offset_input, mean_input,
variance_input, y, batch_mean,
batch_variance, reserve_space_1,
reserve_space_2,
epsilon, data_format,
is_training, kernel_name)-
自动调度
with tvm.target.cce():
sch = tbe.auto_schedule(res)-
编译配置
if is_training:
tensor_list = [x_input, scale_input, offset_input] + list(res)
else:
tensor_list = [x_input, scale_input, offset_input,
mean_input, variance_input] + list(res)
config = {"name": kernel_name,
"tensor_list": tensor_list}
tbe.cce_build_code(sch, config)5.5 算子原型文件
算子原型定义规定了在昇腾AI处理器上可运行算子的约束,主要体现算子的数学含义,包含定义算子输入、输出和属性信息,基本参数的校验和shape的推导,原型定义的信息会被注册到GE的算子原型库中。网络模型生成时,GE会调用算子原型库的校验接口进行基本参数的校验,校验通过后,会根据原型库中的推导函数推导每个节点的输出shape与dtype,进行输出tensor的静态内存的分配。
算子的IR用于进行算子的描述,包括算子输入输出信息,属性信息等,用于把算子注册到算子原型库中,需要在算子的工程目录的/op_proto/算子名称.h 和 /op_proto/算子名称.cc文件中进行实现。
算子IR头文件.h
/*宏定义*/
#ifndef BATCH_NORM_H
#define BATCH_NORM_H
/*包含头文件*/
#include "graph/operator_reg.h"
/*原型注册*/
/*INPUT与.OUTPUT分别为算子的输入、输出Tensor的名称与数据类型,输入输出的顺序需要与算子代码实现函数形参顺序以及算子信息定义中参数的顺序保持一致。*/
namespace ge {
REG_OP(BatchNorm) /*与插件适配文件中的算子类型保存一致,BatchNorm*/
.INPUT(x, TensorType({DT_FLOAT16, DT_FLOAT}))
.INPUT(scale, TensorType({DT_FLOAT}))
.INPUT(offset, TensorType({DT_FLOAT}))
.OPTIONAL_INPUT(mean, TensorType({DT_FLOAT}))
.OPTIONAL_INPUT(variance, TensorType({DT_FLOAT}))
.OUTPUT(y, TensorType({DT_FLOAT16, DT_FLOAT}))
.OUTPUT(batch_mean, TensorType({DT_FLOAT}))
.OUTPUT(batch_variance, TensorType({DT_FLOAT}))
.OUTPUT(reserve_space_1, TensorType({DT_FLOAT}))
.OUTPUT(reserve_space_2, TensorType({DT_FLOAT}))
.OUTPUT(reserve_space_3, TensorType({DT_FLOAT}))
.ATTR(epsilon, Float, 0.0001)
.ATTR(data_format, String, "NHWC")
.ATTR(is_training, Bool, true)
.OP_END_FACTORY_REG(BatchNorm)
} // namespace ge
/*结束条件编译*/
#endif // BATCH_NORM_H算子IR定义的.cc文件
IR实现的cc文件中主要实现如下两个功能:
-
算子参数的校验,实现程序健壮性并提高定位效率,对应Verify函数。
-
根据算子的输入张量描述、算子逻辑及算子属性,推理出算子的输出张量描述,包括张量的形状、数据类型及数据排布格式等信息。这样算子构图准备阶段就可以为所有的张量静态分配内存,避免动态内存分配带来的开销,对应InferShape函数。
Verify函数主要校验算子内在关联关系,例如对于多输入算子,多个tensor的dtype需要保持一致,此时需要校验多个输入的dtype,其他情况dtype不需要校验。
实现Verify函数
IMPLEMT_VERIFIER(BatchNorm, BatchNormVerify) {
if (!CheckTwoInputDtypeSame(op, "scale", "offset")) {
return GRAPH_FAILED;
}
return GRAPH_SUCCESS;
}InferShape流程负责推导TensorDesc中的dtype与shape,只要全图所有首节点的TensorDesc确定了,就可以逐个向下传播,再由算子自身实现的Shape推导能力,就可以将全图所有OP的输入输出TensorDesc推导出来,推导结束后,全图的dtype与shape的规格就完全连续了。InferShape函数详细可参见算子原型定义。
实现InferShape函数
IMPLEMT_INFERFUNC(BatchNorm, BatchNormInferShape) {
std::string data_format;
if (op.GetAttr("data_format", data_format) == GRAPH_SUCCESS) {
if (data_format != "NHWC" && data_format != "NCHW") {
string expected_format_list = ConcatString("NHWC, NCHW");
std::string err_msg = GetInputFormatNotSupportErrMsg("data_format", expected_format_list, data_format);
VECTOR_INFER_SHAPE_INNER_ERR_REPORT(op.GetName(), err_msg);
return GRAPH_FAILED;
}
}
if (!OneInOneOutDynamicInfer(op, "x", {"y"})) {
return GRAPH_FAILED;
}
if (!OneInOneOutDynamicInfer(op, "scale", {"batch_mean", "batch_variance", "reserve_space_1", "reserve_space_2"})) {
return GRAPH_FAILED;
}
std::vector oShapeVector;
auto op_info = OpDescUtils::GetOpDescFromOperator(op);
auto output_desc = op_info->MutableOutputDesc("reserve_space_3");
if (output_desc != nullptr) {
output_desc->SetShape(GeShape(oShapeVector));
output_desc->SetDataType(DT_FLOAT);
}
return GRAPH_SUCCESS;
} 注册infershape方法和Verify方法
INFER_FUNC_REG(BatchNorm, BatchNormInferShape);
VERIFY_FUNC_REG(BatchNorm, BatchNormVerify);5.6 算子信息库文件
算子信息库作为算子开发的交付件之一,主要体现算子在昇腾AI处理器上的具体实现规格,算子开发者需要通过配置算子信息库文件,将算子在昇腾AI处理器上相关实现信息注册到算子信息库中,包括算子支持输入输出type、format以及输入shape等信息。网络运行时,FE会根据算子信息库中的算子信息做基本校验,选择dtype,format等信息,并根据算子信息库中信息找到对应的算子实现文件进行编译,用于生成算子二进制文件。

图17 算子信息库文件
参数说明请参见文档中的表1。
6. BatchNorm算子编译
6.1 基本概念
算子交付件开发完成后,需要对算子工程进行编译,生成自定义算子安装包*.run,详细的编译操作包括:
-
将TBE算子信息库定义文件*.ini编译成aic-{soc version}-ops-info.json。
-
将原型定义文件.h**与.cc编译成libcust_op_proto.so。
-
将TensorFlow/Caffe/Onnx算子的适配插件实现文件.h**与.cc编译成libcust{tf|caffe|onnx}parsers.so。
6.2 编译操作
MindStudio界面顶部,点击Build -> Edit Build Configurations。

图18 打开算子编译配置窗口
进入编译配置窗口,以远程编译为例,若未配置远程连接,则先在Deployment后面点击“+“进行配置,并在Envrionment Variables处进行如下配置,用户需将/home/xxx/Ascend/ascend-toolkit/latest/替换为CANN实际安装路径。
ASCEND_TENSOR_COMPILER_INCLUDE=/home/xxx/Ascend/ascend-toolkit/latest/include

图19 算子编译配置
表1 算子编译配置参数说明
| 参数 | 说明 |
|---|---|
| Build Configuration | 编译配置名称,默认为Build-Configuration |
| Build Mode | 编译方式。 Remote Build:远端编译。 Local Build:本地编译。 |
| Deployment | Remote Build模式下显示该配置。 可以将指定项目中的文件、文件夹同步到远程指定机器的指定目录。 |
| Environment variables | Remote Build模式下显示该配置。配置环境变量。 |
| Target OS | Local Build模式下显示该配置。 针对Ascend EP:选择昇腾AI处理器所在硬件环境的Host侧的操作系统。 针对Ascend RC:选择板端环境的操作系统。 |
| Target Architecture | Local Build模式下显示该配置。选择Target OS的操作系统架构。 |
点击Build进行工程编译。编译完成后,显示远程编译完成 Information:build remotely finished。

图20 算子编译完成输出日志
在算子工程的cmake-build目录下生成了编译后的BacthNorm算子安装包,包含了操作系统及对应系统架构信息,如下图所示。

图21 算子编译生成安装包.run文件
7. BatchNorm算子部署
7.1 基本概念
算子部署指将算子编译生成的自定义算子安装包(*.run)部署到OPP算子库中。
-
推理场景下,自定义算子直接部署到开发环境的OPP算子库。
-
训练场景下,自定义算子安装包需要部署到运行环境的OPP算子库中。
7.2 部署操作
在MindStudio工程界面,选中算子工程,点击顶部的Ascend > Operator Deployment,进入算子打包部署界面

图22 打开算子部署配置窗口
如下算子部署界面,Operator Package即前面编译后生成的自定义算子安装包
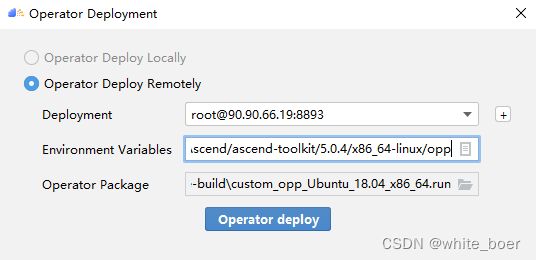
图23 算子部署配置
在Environment Variables中直接输入ASCEND_OPP_PATH=/home/xxx/Ascend/ascend-toolkit/latest/opp。 /home/xxx/Ascend/ascend-toolkit/latest为OPP组件(算子库)的安装路径,请根据实际情况配置。
也可以点击文本框后的图标,在弹出的对话框中填写。
-
在Name中输入环境变量名称:ASCEND_OPP_PATH。
-
在Value中输入环境变量值:home/xxx/Ascend/ascend-toolkit/latest/opp。
表2 算子部署配置参数说明
| 参数 | 说明 |
|---|---|
| Build Configuration | 编译配置名称,默认为Build-Configuration |
| Deployment | Remote Build模式下显示该配置。 可以将指定项目中的文件、文件夹同步到远程指定机器的指定目录。 |
| Environment variables | Remote Build模式下显示该配置。配置环境变量。 |
点击Operator deploy进行算子部署,部署成功会出现以下输出日志。

图24 算子部署完成输出日志
8. BatchNorm算子UT
8.1 基本概念
基于MindStudio进行算子开发的场景下,用户可基于MindStudio进行算子的UT,UT(Unit Test:单元测试)是开发人员进行算子代码验证的手段之一,主要目的是:
-
测试算子代码的正确性,验证输入输出结果与设计的一致性。
-
UT侧重于保证算子程序能够跑通,选取的场景组合应能覆盖算子代码的所有分支(一般来说覆盖率要达到100%),从而降低不同场景下算子代码的编译失败率。
8.2 UT操作
开发人员可以执行当前工程中所有算子的UT用例,也可以执行单个算子的UT用例:
-
右键单击“testcases/ut/ops_test”文件夹,选择Run TBE Operator'All'UT Impl with coverage,执行整个文件夹下算子实现代码的测试用例。
-
右键单击“testcases/ut/ops_test/算子名称”文件夹,选择Run TBE Operator'算子名称'UT Impl with coverage,执行单个算子实现代码的测试用例。

图25 第一次打开UT配置窗口
第一次运行时弹出UT配置窗口,进行如下配置后,点击OK执行算子UT。

图26 UT配置
表3 算子UT配置参数说明
| 参数 | 说明 |
|---|---|
| Name | 运行配置名称,用户可以自定义。 |
| Compute Unit | 选择计算单元 |
| SoC Version | 下拉选择当前版本的昇腾AI处理器类型。 |
| Target | 运行环境。 Simulator_Function:功能仿真环境。 Simulator_TMModel:快速展示算子执行的调度流水线,不进行实际算子计算。 |
| Operator Name | 选择运行的测试用例。 |
| CANN Machine | CANN工具所在设备的deployment信息。 |
| Case Names | 勾选需要运行的测试用例,即算子实现代码的UT Python测试用例。 |
第二次执行UT文件不弹出运行配置,若需改配置,在顶部选择更改的文件,点击Edit Configurations即可修改。

图27 重新打开UT配置窗口
在Target选择Simulator_TMModel时,可以查看执行流水线,如下图所示图。

图28 UT流水线
点击Run,会有一个用例测试结果的url。

图29 UT完成输出日志url
点击该url,查看UT的具体执行结果。

图30 UT测试结果详情
可点击页面中对应算子,进入UT用例覆盖率详情页面,通过绿色和红色标签区分是否覆盖。
图31 UT代码覆盖
9. BatchNorm算子ST
9.1 基本概念
自定义算子部署到算子库(OPP)后,可进行ST(System Test),在真实的硬件环境中,验证算
子功能的正确性。
ST的主要功能是:
-
基于算子测试用例定义文件*.json生成单算子的om文件;
-
使用AscendCL接口加载并执行单算子om文件,验证算子执行结果的正确性。ST会覆盖算子实现文件,算子原型定义与算子信息库,不会对算子适配插件进行测试。
9.2 ST操作
ST用例的创建与UT用例的创建类似:
-
右键单击算子工程根目录,选择New Cases > ST Case。
-
右键单击算子信息定义文件:{工程名} /tbe /op_info_cfg/ai_core/SoC version} /xx.ini,选择New Cases > ST Case。若已经存在了对应算子的ST Case,可以右键单击testcases目录,或者testcases > st目录,选择New Cases > ST Case,追加ST测试用例。
执行ST
在工程目录testcases -> st -> batch_norm -> {SoC Version} -> xxx.json,找到保存的ST用例定义文件,右键单击选择Run ST Case ‘xxx.json',首次执行时,会弹出配置窗口中进行ST用例运行配置。

图32 第一次打开ST配置窗口
执行ST用例,其中在Advanced options下勾选Enable Profiling,可获取算子在昇腾AI处理器上的性能数据,该功能需要将运行环境中的msprof工具所在路径配置到PATH环境变量中,可在.bashrc文件中添加如下语句:
export PATH="$PATH:/usr/local/Ascend/ascend-toolkit/latest/tools/profiler/bin/"
参考如下配置,其中环境变量配置如表4
表4 ST环境变量配置说明
| Name | Value |
|---|---|
| ASCEND_DRIVER_PATH | /usr/local/Ascend/driver |
| ASCEND_HOME | /usr/local/Ascend//ascend-toolkit/latest |
| LD_LIBRARY_PATH | ${ASCEND_DRIVER_PATH}/lib64: ${ASCEND_HOME}/lib64:$LD_LIBRARY_PATH |

图33 ST配置

图34 ST性能数据日志

图35 ST完成输出日志
在’算子工程根目录/testcases/st/out/‘目录下生成测试数据和测试代码,并编译出可执行文件,在指定的硬件设备上执行测试用例。在’算子工程根目录/testcases/st/out/‘目录下生成的st_report.json文件记录了测试情况,可参考MindStudio文档中的ST测试执行结果表。
10. 关于BatchNorm算子开发的FAQ
1. 创建的BatchNorm算子工程,代码的头文件或者导入的依赖显示为红色。
首先检查是否参考MindStudio的安装指南安装好对应的依赖和环境,其次算子工程是在服务器端的 CANN框架下运行的,但是工程文件保存在Windows端本地,本地没CANN环境会显示为红色,但是不会影响远端工程的运行。
2. 算子流程中的编译、部署和ST测试中如何设置相应的环境变量。
参考MindStudio用户手册中的用户指南,在自定义算子开发章节下的TBE算子开发(TensorFlow/Caffe)小节中,有详细讲解如何设置环境变量。
3. 算子UT测试中无法生成流水线图。
在UT测试的配置框中,Target选择Stimulator_TMModel,UT执行完成后可生成流水线图。
4. ST测试中,勾选了Enable Profiling后的ST日志里,没有出现性能数据,并提示msprof command未找到。
进入Linux服务器,在.bashrc文件最底部中添加export PATH="$PATH:/usr/local/Ascend/ascend-toolkit/latest/tools/profiler/bin/",其中路径需配置到msprof工具实际所在bin目录下。配置完成后,则无该提示并出现性能数据。
5. 如何打开UT测试和ST测试的运行配置窗口。
第一次进行UT测试和ST测试时,运行前会自动打开配置窗口让用户进行配置,第二次开始就会按照第一次的默认配置进行执行,只需在MindStudio界面上方的绿色锤子旁边先选择UT或ST的配置文件,再点击Edit Configurations即可再次打开配置窗口。

图36 再次打开UT、ST配置窗口
11. 从昇腾社区寻求更多AI内容
若是开发者在对CANN和MindStudio的安装与配置、算子工程流程中的困惑与问题而寻求解决方案时,又或者是想和其他开发者进行技术交流、寻找技术资料等情况,我们都可以进入昇腾社区,在昇腾论坛发帖表达个人的想法或搜索想要的信息。
可以通过下面的方式进入昇腾论坛,进入昇腾首页,顶部菜单找到开发者->社区下的昇腾论坛

图37 昇腾首页

图38 昇腾论坛
附链接:
-
昇腾官网:昇腾社区-官网丨昇腾万里 让智能无所不及
-
昇腾论坛:昇腾论坛_开发者论坛-华为云论坛
-
MindStudio:昇腾社区-官网丨昇腾万里 让智能无所不及
-
CANN开发者TBE算子开发文档:昇腾社区-官网丨昇腾万里 让智能无所不及