yoloV5训练自己的数据集-文本区域识别
代码链接:
https://github.com/ultralytics/yolov5
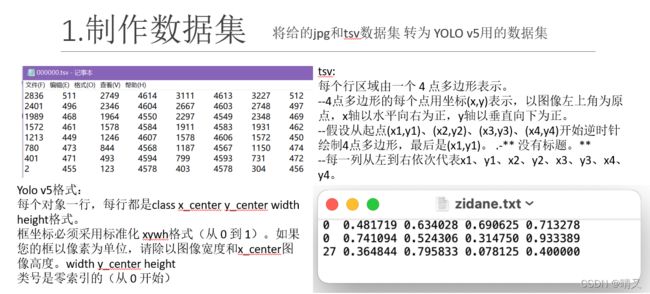
竞赛给的数据是jpg和tsv格式
但是yolov5需要YOLO格式数据集
需要把tsv转成yolo格式
代码:
import csv
from PIL import Image
import os
os.chdir(r'D:\test\tsv_yolo')
path = '041'
error_num = 0
for root, dirs, files in os.walk(path):
list = []
for file in files:
if ".jpg" in file:
file = file.rstrip(".jpg")
print(file)
tsv_name = './' + path + '/' + file + '.tsv'
tsvfile = open(tsv_name)
filename_txt = './' + path + '/' + file + '.txt'
file_txt = open(filename_txt, 'w+')
tsvreader = csv.reader(tsvfile, delimiter="\t")
filename_jpg = './' + path + '/' + file + '.jpg'
file_path = filename_jpg
img = Image.open(file_path)
imgSize = img.size # 大小/尺寸
width_img = img.width # 图片的宽
height_img = img.height # 图片的高
print("width_img:", width_img, "height_img:", height_img)
i = 1
for line in tsvreader:
print("No.", i)
print("old:", line[0:])
x_center = (int(line[4]) + int(line[0])) / 2
print(line[4],line[0])
print("x_center:", x_center)
y_center = (int(line[5]) + int(line[1])) / 2
print("y_center:", y_center)
width = int(line[4]) - int(line[0])
print("width:", width)
height = int(line[5]) - int(line[1])
print("height:", height)
x_center = x_center / width_img
print("x_center:", x_center)
if x_center >= 1:
print("*****************************error********************")
error_num = 1
y_center = y_center / height_img
print("y_center:", y_center)
if y_center >= 1:
print("*****************************error********************")
error_num = 1
width = width / width_img
print("width:", width)
if width >= 1:
print("*****************************error********************")
error_num = 1
height = height / height_img
print("height:", height)
if height >= 1:
print("*****************************error********************")
error_num = 1
file_txt.write('0 %f %f %f %f' % (x_center, y_center, width, height))
file_txt.write('\n') # 换行
i = i + 1
print("\n")
print("result:", error_num)
转换公式:
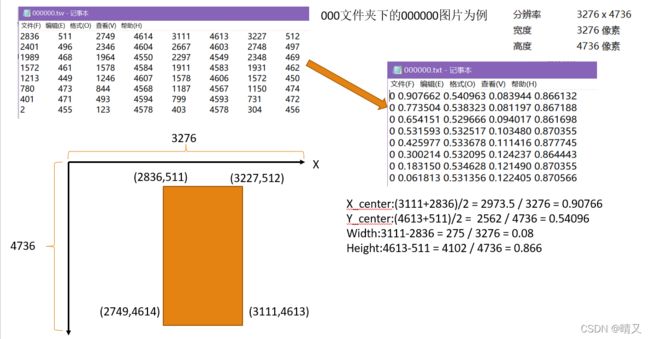
把所有jpg放到images下
所有生成的txt文件放到ImageSets
两个文件夹如图所示:

放完图片的images如下所示:
每一个文件夹下都是jpg

txt标签文件夹如下:
每个文件夹下都是txt
再接着生产三个txt文本,包括:
val.txt
test.txt
train.txt
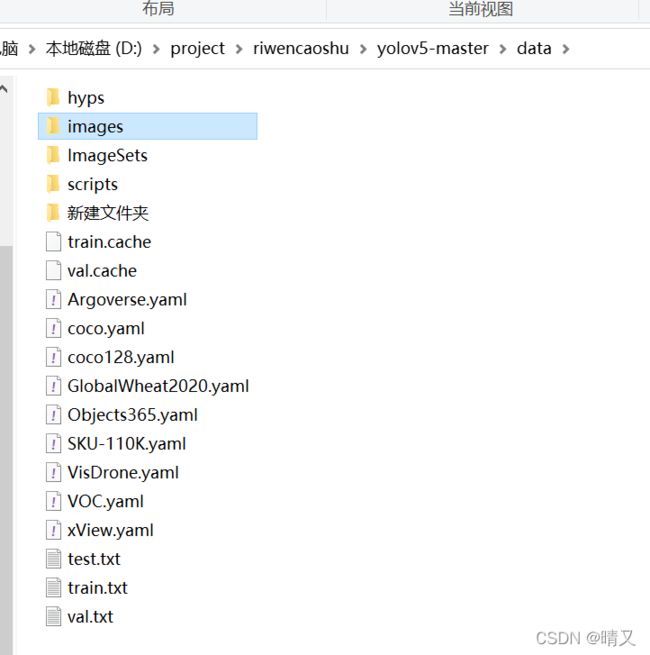
代码规则也就是把文件夹里的文件名字包括路径(路径用的是yolov5的路径),写入txt里
代码如下:
import csv
import os
os.chdir(r'D:\test\tsv_yolo\data\images')
path = '001'
file_txt = open('val.txt', 'a')
for root, dirs, files in os.walk(path):
list = []
for file in files:
# file = file.rstrip(".jpg")
print(file)
file_txt.write('data/images/'+path+'/'+file)
file_txt.write('\n') # 换行
file_txt.close()
成品:
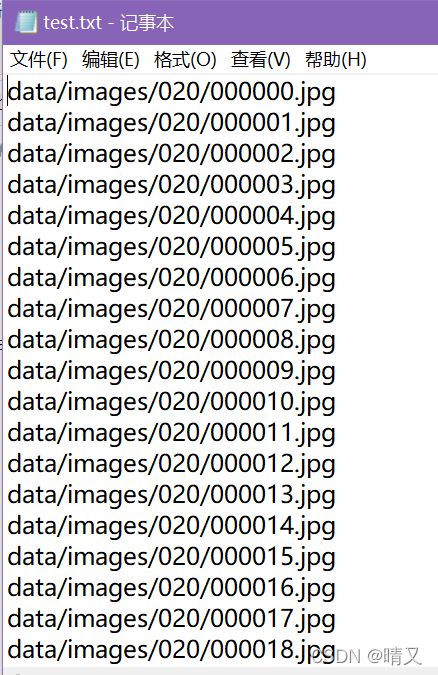
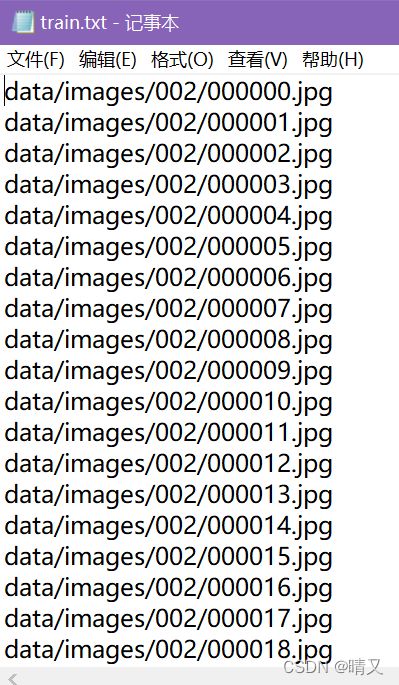
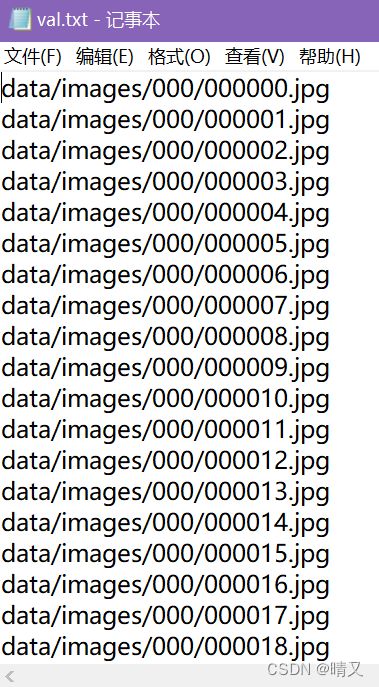
修改配置文件:
修改data文件夹下coco.yaml文件,也可以自己新建一个.yaml文件,建议直接在coco.yaml文件上修改(减少在其他代码上的修改量)。
我的class就一个,因为只识别文本的区域
名字就是text
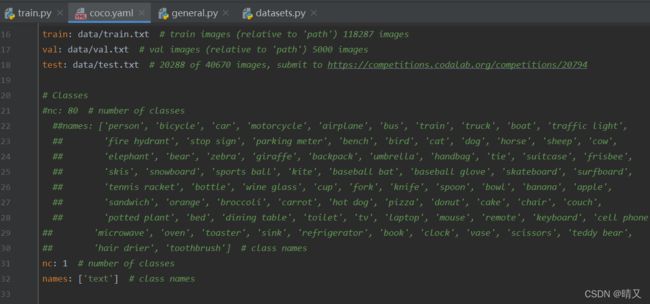
coco.yaml代码:
# YOLOv5 by Ultralytics, GPL-3.0 license
# COCO 2017 dataset http://cocodataset.org by Microsoft
# Example usage: python train.py --data coco.yaml
# parent
# ├── yolov5
# └── datasets
# └── coco ← downloads here (20.1 GB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
#path: ../datasets/coco # dataset root dir
#train: train2017.txt # train images (relative to 'path') 118287 images
#val: val2017.txt # val images (relative to 'path') 5000 images
#test: test-dev2017.txt # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
train: data/train.txt # train images (relative to 'path') 118287 images
val: data/val.txt # val images (relative to 'path') 5000 images
test: data/test.txt # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
# Classes
#nc: 80 # number of classes
##names: ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
## 'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
## 'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
## 'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
## 'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
## 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
## 'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
## 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear',
## 'hair drier', 'toothbrush'] # class names
nc: 1 # number of classes
names: ['text'] # class names
# Download script/URL (optional)
download: |
from utils.general import download, Path
# Download labels
segments = False # segment or box labels
dir = Path(yaml['path']) # dataset root dir
url = 'https://github.com/ultralytics/yolov5/releases/download/v1.0/'
urls = [url + ('coco2017labels-segments.zip' if segments else 'coco2017labels.zip')] # labels
download(urls, dir=dir.parent)
# Download data
urls = ['http://images.cocodataset.org/zips/train2017.zip', # 19G, 118k images
'http://images.cocodataset.org/zips/val2017.zip', # 1G, 5k images
'http://images.cocodataset.org/zips/test2017.zip'] # 7G, 41k images (optional)
download(urls, dir=dir / 'images', threads=3)
接着修改./models/yolov5m.yaml
在models中有yolov5m.yaml / yolov5l.yaml / yolov5x.yaml /yolov5s.yaml几种可以选择,根据自身条件选择
yolov5m.yaml文件修改如图:

yolov5m.yaml代码:
# YOLOv5 by Ultralytics, GPL-3.0 license
# Parameters
#nc: 80 # number of classes
nc: 1 # number of classes
depth_multiple: 0.67 # model depth multiple
width_multiple: 0.75 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
再接着,预训练权重下载
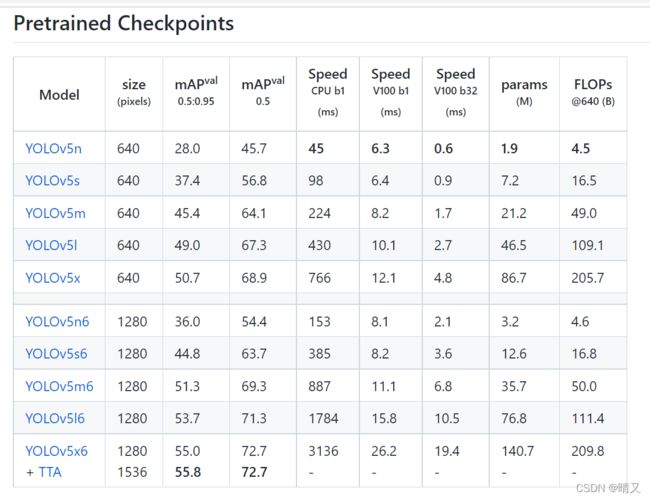
点击下面这个pt下载

修改train.py代码:
报错:

解决:

问题:
D:\anaconda\python.exe “D:\PyCharm Community Edition 2019.3.3\plugins\python-ce\helpers\pydev\pydevd.py” --multiproc --qt-support=auto --client 127.0.0.1 --port 53523 --file D:/project/riwencaoshu/yolov5-master/train.py
pydev debugger: process 5152 is connecting
Connected to pydev debugger (build 193.6494.30)
train: weights=weights/yolov5m.pt, cfg=models/yolov5m.yaml, data=data/coco.yaml, hyp=data/hyps/hyp.scratch-low.yaml, epochs=1, batch_size=16, imgsz=[640, 640], rect=False, resume=False, nosave=False, noval=False, noautoanchor=False, evolve=None, bucket=, cache=None, image_weights=False, device=cpu, multi_scale=False, single_cls=False, optimizer=SGD, sync_bn=False, workers=0, project=runs/train, name=exp, exist_ok=False, quad=False, cos_lr=False, label_smoothing=0.0, patience=100, freeze=[0], save_period=-1, local_rank=-1, entity=None, upload_dataset=False, bbox_interval=-1, artifact_alias=latest
github: skipping check (not a git repository), for updates see https://github.com/ultralytics/yolov5
‘git’ �����ڲ����ⲿ���Ҳ���ǿ����еij���
���������ļ���
YOLOv5 2022-4-6 torch 1.11.0+cpu CPU
hyperparameters: lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=0.05, cls=0.5, cls_pw=1.0, obj=1.0, obj_pw=1.0, iou_t=0.2, anchor_t=4.0, fl_gamma=0.0, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.0, copy_paste=0.0
Weights & Biases: run ‘pip install wandb’ to automatically track and visualize YOLOv5 runs (RECOMMENDED)
TensorBoard: Start with ‘tensorboard --logdir runs\train’, view at http://localhost:6006/
2022-04-07 16:12:39.116248: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library ‘cudart64_110.dll’; dlerror: cudart64_110.dll not found
2022-04-07 16:12:39.116349: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
from n params module arguments
0 -1 1 5280 models.common.Conv [3, 48, 6, 2, 2]
1 -1 1 41664 models.common.Conv [48, 96, 3, 2]
2 -1 2 65280 models.common.C3 [96, 96, 2]
3 -1 1 166272 models.common.Conv [96, 192, 3, 2]
4 -1 4 444672 models.common.C3 [192, 192, 4]
5 -1 1 664320 models.common.Conv [192, 384, 3, 2]
6 -1 6 2512896 models.common.C3 [384, 384, 6]
7 -1 1 2655744 models.common.Conv [384, 768, 3, 2]
8 -1 2 4134912 models.common.C3 [768, 768, 2]
9 -1 1 1476864 models.common.SPPF [768, 768, 5]
10 -1 1 295680 models.common.Conv [768, 384, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, ‘nearest’]
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 2 1182720 models.common.C3 [768, 384, 2, False]
14 -1 1 74112 models.common.Conv [384, 192, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, ‘nearest’]
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 2 296448 models.common.C3 [384, 192, 2, False]
18 -1 1 332160 models.common.Conv [192, 192, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 2 1035264 models.common.C3 [384, 384, 2, False]
21 -1 1 1327872 models.common.Conv [384, 384, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 2 4134912 models.common.C3 [768, 768, 2, False]
24 [17, 20, 23] 1 24246 models.yolo.Detect [1, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [192, 384, 768]]
YOLOv5m summary: 369 layers, 20871318 parameters, 20871318 gradients
Transferred 474/481 items from weights\yolov5m.pt
Scaled weight_decay = 0.0005
optimizer: SGD with parameter groups 79 weight (no decay), 82 weight, 82 bias
Traceback (most recent call last):
File “D:\anaconda\lib\contextlib.py”, line 137, in exit
self.gen.throw(typ, value, traceback)
File “D:\project\riwencaoshu\yolov5-master\utils\torch_utils.py”, line 37, in torch_distributed_zero_first
yield
File “D:\project\riwencaoshu\yolov5-master\utils\datasets.py”, line 115, in create_dataloader
dataset = LoadImagesAndLabels(
File “D:\project\riwencaoshu\yolov5-master\utils\datasets.py”, line 419, in init
self.mosaic_border = [-img_size // 2, -img_size // 2]
TypeError: bad operand type for unary -: ‘list’
imgsz那里,不能用数组【640,640】,改为单个数字就行
报错
OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll alread
解决:

https://blog.csdn.net/jialibang/article/details/107392240
网上搜索出来的方法:
允许副本存在,程序中添加
import os
os.environ[‘KMP_DUPLICATE_LIB_OK’] = ‘TRUE’ 解决了
解决了问题
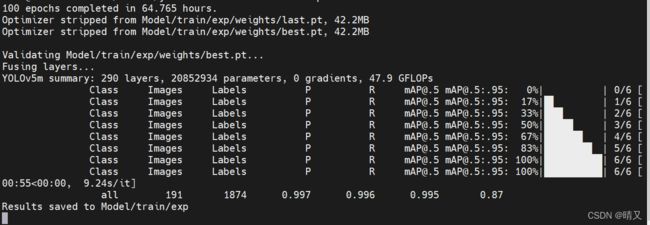
训练结束
进行测试
修改dete.py
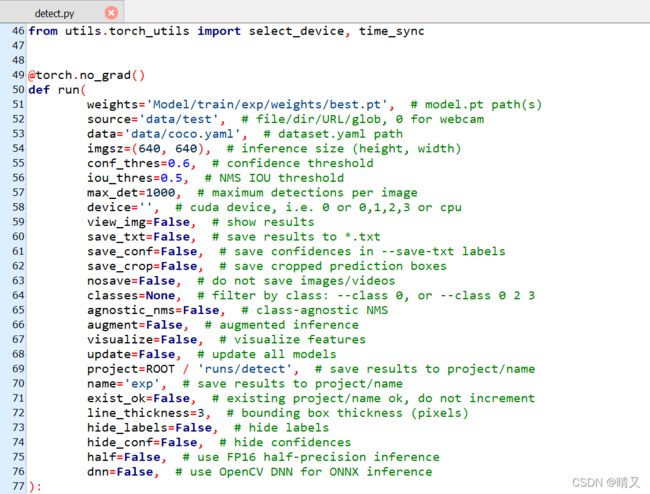
修改以下段:
weights='Model/train/exp/weights/best.pt', # model.pt path(s)
source='data/test', # file/dir/URL/glob, 0 for webcam
data='data/coco.yaml', # dataset.yaml path
`
conf_thres=0.6, # confidence threshold
iou_thres=0.5, # NMS IOU threshold``
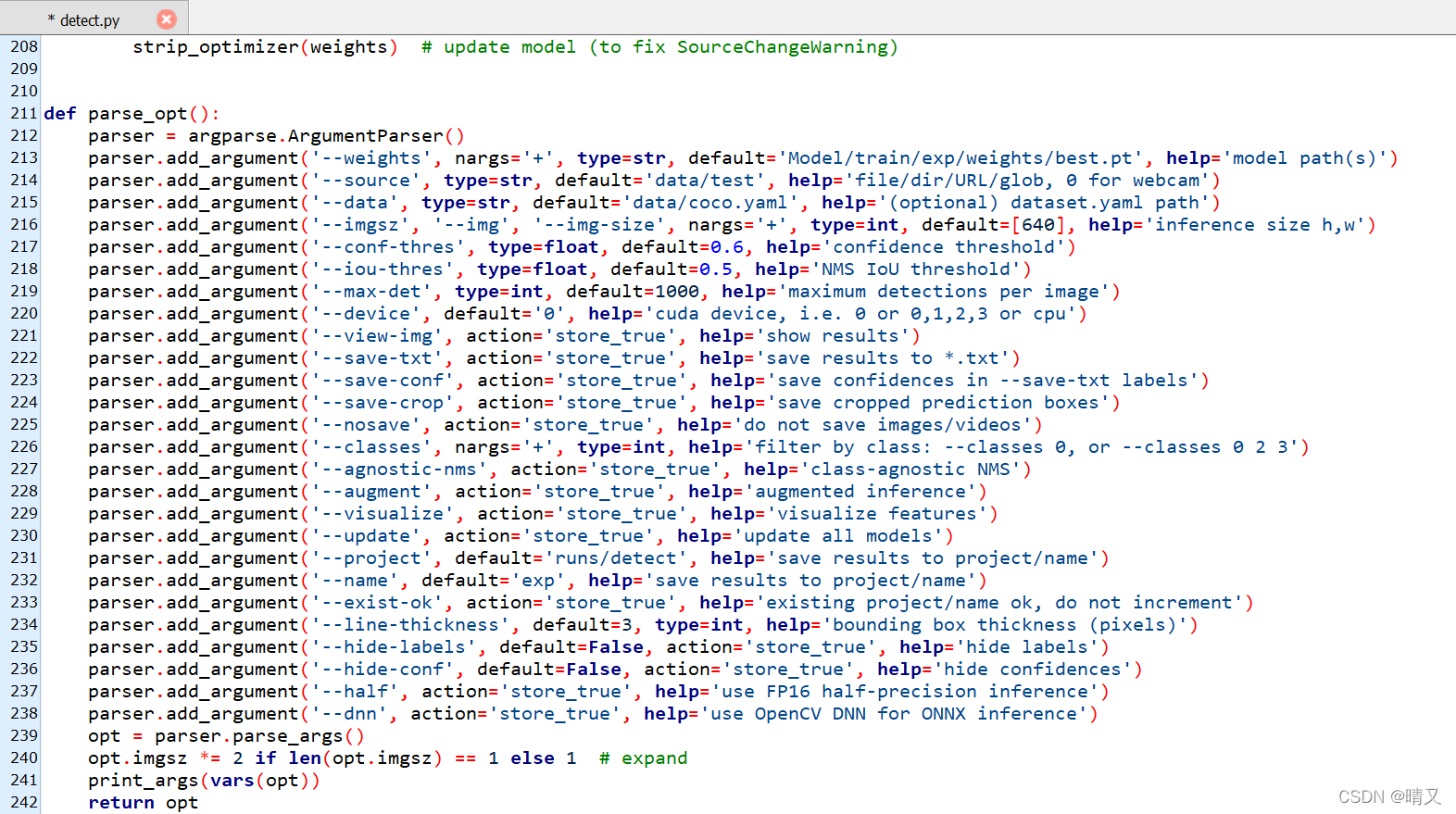
```cpp
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='Model/train/exp/weights/best.pt', help='model path(s)')
parser.add_argument('--source', type=str, default='data/test', help='file/dir/URL/glob, 0 for webcam')
parser.add_argument('--data', type=str, default='data/coco.yaml', help='(optional) dataset.yaml path')
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
parser.add_argument('--conf-thres', type=float, default=0.6, help='confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.5, help='NMS IoU threshold')
parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='show results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --classes 0, or --classes 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--visualize', action='store_true', help='visualize features')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default='runs/detect', help='save results to project/name')
图片路径
预测
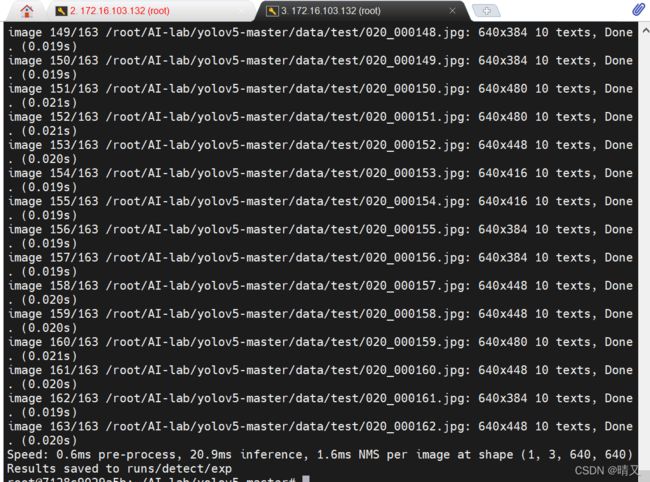
输出结果
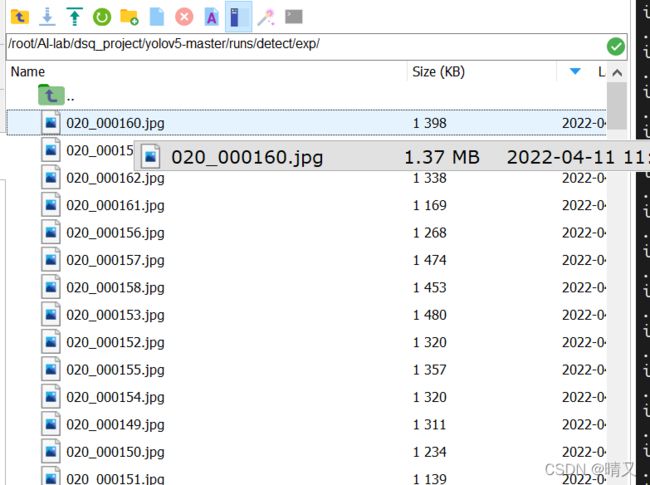
但是只有框,没有坐标,无法进行比对,准备把yoloV5的坐标信息打印出来
在另一个帖子:
添加链接描述