利用传统简单CNN(AlexNet,VGG等)做猫狗分类
卷积神经网络介绍:
随时代的发展,带标签的数据集增多,算力的提升。使神经网络闪耀的站在了舞台中央,早期LeNet的提出并在实际生活中得到了应用,到后来AlexNet的提出再次掀起了深度学习研究的热潮。本篇博客打算简单介绍AlexNet和VGG这两个经典的卷积神经网络,它们共同的特点是在卷积神经网络的深度上做了进一步的讨论与实验。并且,在ImageNet数据集上都收获了良好的表现。
AlexNet
论文地址:https://dl.acm.org/doi/pdf/10.1145/3065386
AlexNet网络的提出,斩获了LSVRC-2010图像分类赛道的冠军,大大减小了top-1与top-5的错误率,分别为37.5% 与17.0%,使用集成的方法可以使错误率更低。
整体结构
由五层卷积层加上三层全连接层,每个卷积层后面都会跟着一个最大池化层用于下采样,其中的细节由论文中的结构图展示 除了以上方法,论文中还提到了Local Response Normalization(LRN,局部相应规范化),但这种方法在之后的卷积神经网络的研究中已经不再使用了。 论文地址:https://arxiv.org/pdf/1409.1556.pdf 跟AlexNet相比,VGG网络除了网络层数更多,另一个比较大的区别是VGG网络中从头至尾用的都是3×3的小卷积核。用小的卷积核主要有两个好处,一个是可以增加网络深度(卷积层增加),则激活函数也随之变多,增加网络的非线性性,使网络表达能力变得更强;另一方面是可以减小参数量,举个例子,假设输入与最终的输出的通道数都为C,当使用7×7大小的卷积核时所需要学习的参数数量为7×7×C×C ,当使用三层3×3的卷积核时只需要3×[(3×3)×C×C]个参数。(用三层3×3的卷积核的感受野(receptive field)与一层7×7的卷积核的感受野相同,也就是说在感受野相同的前提下,用小卷积核所需要的学习的参数更少)。这种小卷积核的方法在后续的研究中得到了充分的利用。 上面两篇论文都是卷积神经网络中的经典,为卷积神经网络的发展做出了非常大的贡献,这里只是粗略的和大家分享其中的一些特点,还有许多细节没有说清楚,尤其是VGG中训练时对数据的处理,这一部分大家可以找原文自己过一遍。 这里浅用刚学习的一些知识来做一个小的demo,主要是借鉴了VGG结构,其中还用到了BN层(使用了超前知识哈哈哈哈哈)。 其中包含了自己写的Dataset方法重构(个人认为这非常重要,毕竟在不同数据集下,处理方式不同)。大家可以借这个比赛锻炼一下自己的实操能力,根据实际情况来应用神经网络中的优化方法,我也在摸索中。下面贴出训练过程中准确率变化的图片,在上面的链接里都可以查看。 Dataset方法重构
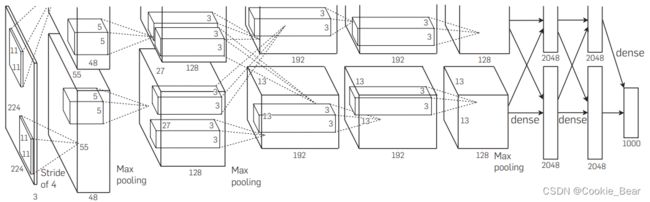
从图中可以看出网络由上下两个部分构成,这是因为当时训练的时候是由两个GPU进行并行训练的。论文针对网络训练速度,过拟合问题提出了相应的优化方法。
网络训练速度提升:①AlexNet网络中的激活函数用的是ReLU,使用ReLU激活函数可以显著的提升网络训练速度②使用两个GPU并行训练用于提升训练速度;
过拟合问题:1、数据扩充(数据增广,Data augmentation),论文中主要采用了两种方式进行。①将原始图像的短边放缩至255(图像是等比例放缩的),然后在中心裁剪出一个256×256的图像,接着再随机裁取一个244×244的图像,并进行水平翻转,这样操作下来相当于将数据量扩大了2048(32×32×2)倍。②利用PCA的方法进行数据扩充。2、Dropout方法,以一定概率令神经元变为零(即不参加前向与反向传播)。这种方法可以视为一种高效的模型集成。3、Overlapping Pooling(池化/汇合),论文中采用了"重叠池化",假设池化区域是s×s的,步长为z,当zVGG
VGG网络的基本思想是通过单纯的堆叠卷积层(当然在细节方面有改进),使网络深度变得更深来研究网络深度对网络表现的影响。论文中研究了网络层数从11到19层的表现,具体的结构由论文中的图给出
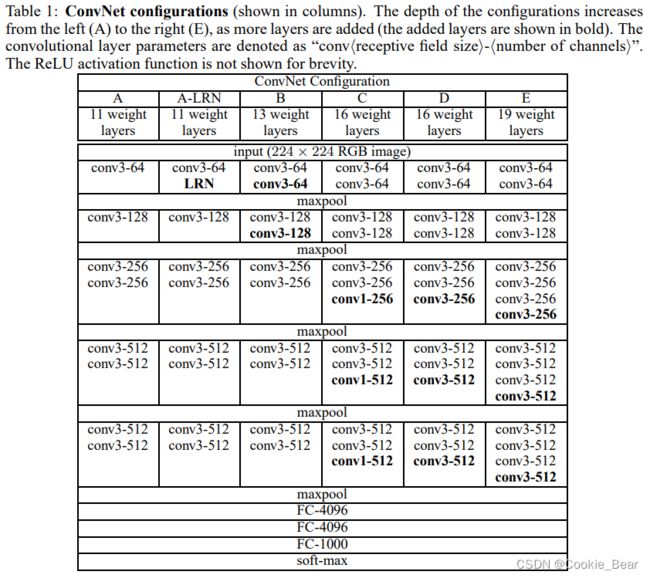
以上是VGG在网络结构上的主要改进,除了没有沿用AlexNet中LRN方法,其他优化方法大致相同。VGG在ImageNet Challenge 2014的图像分类赛道上获得了第二名(第一是GoogLeNet,提出了inception结构)。
这篇论文中比较难理解的部分其实是训练与测试时图像的处理操作,这些操作在后面的许多神经网络论文中也会用到。
关于VGG巨大的参数量这个诟病(模型非常臃肿),也是许多学者在论文中经常用来对比的一个点(VGG表示:勿cue我),但是它在许多数据集上的泛化能力很好,也经常用于迁移学习。总结
本人小白,刚阅读了十来篇CNN相关的论文,许多东西理解的还不够透彻,其中有不对的地方希望大家可以指出来,如果有疑问也可以评论,我尽量回复。kaggle猫狗大战
网络结构:五层卷积(每层由3×3卷积核、BN(batch normalization)层、ReLU)加上两层全连接层。
测试集准确率:训练了20个epoch,最后一个epoch准确率为88.7%,应该是还没有收敛,继续跑下去应该可以有更高的准确率。
深度学习框架是Pytorch,在kaggle平台上用免费的GPU跑的代码。附上链接,里面是全部的代码。kaggle猫狗大战demo
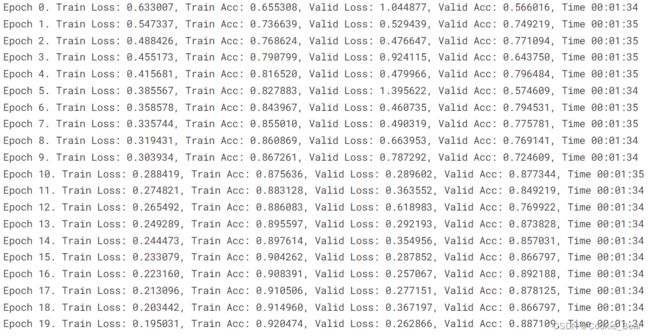
整体的网络结构如下:class easy_cnn(nn.Module):
def __init__(self):
super(easy_cnn, self).__init__()
self.feature = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.MaxPool2d(2,2),
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.MaxPool2d(2,2),
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.MaxPool2d(2,2),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.MaxPool2d(2,2),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.MaxPool2d(2,2),
)
self.fc = nn.Sequential(
nn.Linear(1024, 100),
nn.Dropout(p=0.5),
nn.ReLU(True),
nn.Linear(100, 2)
)
def forward(self, x):
x = self.feature(x)
x = x.view(x.shape[0], -1)
x = self.fc(x)
return x
from torch.utils.data import Dataset
class mydataset(Dataset):
def __init__(self, img_path ,transform=None):
super(mydataset, self).__init__()
self.path = img_path
self.transform = transform
self.label = None
self.transform = transform
# 可以在这对图像做一些操作,而不用transform
def __getitem__(self, index):
img = cv2.imread(self.path[index])
if self.transform:
img = self.transform(img)
if "cat" in self.path[index].split('\\')[-1]:
self.label = 1
else:
self.label = 0
return img, torch.tensor(self.label)
def __len__(self):
return len(self.path)