Python数据分析之用户留存
Python数据分析之用户留存
- 前言
- 概览
- 数据预处理和数据集探究
-
- 规范列名
- 删除多余的列
- dummy化类别型特征
- 探究通话时间与费用的关系
- 探究流失率
- 添加平均通话时长
- 可视化缺失值分布
- 训练模型
-
- 模型对比
- 训练决策树
- 网格搜索-优化决策树
- 评判模型效果-混淆矩阵
- 进阶分析-模型再优化
-
- 网格搜索2
- 参数选择
- 决策树模型可视化
- 后记
前言
在产品生产力过剩的年代,由于转换成本越来越低,消费者也越来越容易放弃原来所依赖的产品而转去体验别的企业的产品,所以企业处理用户留存问题的能力对企业的持续盈利及发展有着至关重要的作用。在互联网产品的用户留存问题中,已然形成一系列成熟的方法论,包括但不局限于同期群分析、用户生命周期分析等。而这些方法论的核心思想,同样适用于金融行业、餐饮行业、通讯行业,因为企业只要有完善的数据平台采集、记录、实时更新用户的关键行为数据,就能通过数据分析的方式给用户留存问题一个定量的视角去赋能于实际业务。
本文就以通讯行业的用户行为数据和企业提供的CLV(客户终身价值)、CRC(客户留存成本)等信息,通过数据分析和数学建模的视角去给通讯行业的用户留存问题提出一种解决方案。值得说明的是,这种解决方案同样适用于互联网商业产品、金融服务产品甚至于餐饮行业的会员制管理的用户留存问题。
要想直接看解决方案可直接跳转到留存方案APP。
概览
本文处理的数据集原地址为:https://www.kaggle.com/datasets/sagnikpatra/edadata。该数据集记录了3000+用户的行为数据,包括每个时段的通话时长、是否开通长途电话套餐、拨打了多少次运营商服务电话等信息,并且标记出每个用户最终是否流失掉。(下图为部分数据)
本文目标是通过机器学习中的二分类算法模型训练该数据集以预测用户是否将要流失掉从而及时得采取行动留存用户。
数据预处理和数据集探究
规范列名
import pandas as pd
pd.options.display.encoding = 'GBK'
df=pd.read_csv('telecom_churn.csv')
#列重命名-将列名所有小写,并将空格替换成下划线
df.columns=[col.lower().replace(' ','_') for col in df]
删除多余的列
#查看state的元素
len(df['state'].unique()) #51个
#state元素太多了,即类别太多了,最好删掉
state=df.pop('state')
#drop掉无用的列-account length呈现
df.drop(['account_length'],axis=1,inplace=True)
dummy化类别型特征
#查看area code的元素
df['area_code'].unique()
#仅有3个,可以转成字符型数值以便于后面dummy
df['area_code']=df['area_code'].astype('str')
mapping={'415':'A','408':'B','510':'C'}
df['area_code']=df['area_code'].map(mapping)
df=pd.get_dummies(df,drop_first=True)
探究通话时间与费用的关系
'''data manipulation'''
#可视化通话时间和收费的关系
import matplotlib.pyplot as plt
fig , axes=plt.subplots()
axes.scatter(df['total_night_minutes'],df['total_night_charge'])
axes.set(ylabel='total_night_charge', xlabel='total_night_minutes',title='通话时间和收费的关系')
plt.savefig('image/通话时间和收费的关系.jpg',dpi=400)

不出所料地,他们是呈绝对的线性关系,所以之后为了避免共线性的影响需要删除其中之一的特征列
探究流失率
labels = 'churn', 'stay'
sizes = [len(df[df['churn']==1]), len(df[df['churn']==0])]
explode = (0.1, 0)
fig1, ax1 = plt.subplots()
ax1.pie(sizes, explode=explode ,labels=labels, autopct='%1.1f%%',
shadow=True, startangle=90)
ax1.axis('equal') # Equal aspect ratio ensures that pie is drawn as a circle.
ax1.set_title('churn rate')
plt.savefig('image/churn_rate.jpg',dpi=400)

#探究该运营商的收费标准
#可视化每个时间段收费标准的分布
fig,axes=plt.subplots(nrows=2,ncols=2)
fig.suptitle(u'每个时间段收费标准的分布')
ax0, ax1, ax2, ax3 = axes.flatten()
ax0.hist(df['total_day_charge']/df['total_day_minutes'])
ax0.set(title='日间收费标准',ylabel='记录数')
ax1.hist(df['total_eve_charge']/df['total_eve_minutes'])
ax1.set(title='傍晚收费标准',ylabel='记录数')
ax2.hist(df['total_night_charge']/df['total_night_minutes'])
ax2.set(title='夜晚收费标准',ylabel='记录数')
ax3.hist(df['total_intl_charge']/df['total_intl_minutes'])
ax3.set(title='国际通话收费标准',ylabel='记录数')
fig.tight_layout()
plt.savefig('image/每个时间段收费标准的分布.jpg',dpi=400)
#发现收费标准呈类似正态分布
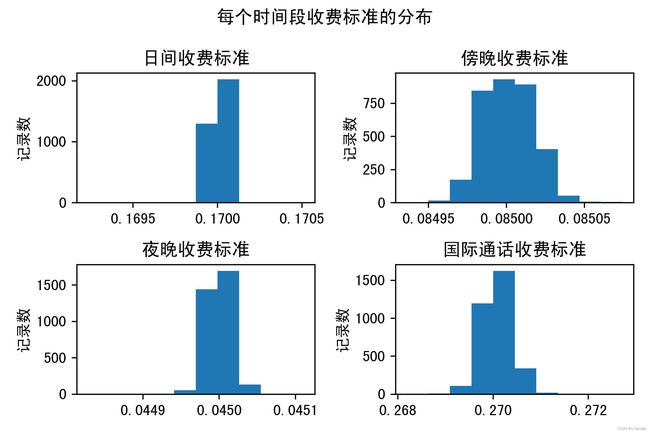
由上图可知,不同客户的不同时间段的收费标准都有可能不尽相同。其中,国际长途话费平均(0.27)>日间话费平均(0.17)>傍晚话费平均(0.085)>国际长途话费平均(0.045)。
添加平均通话时长
#因为运营商收取的费用与通话时长线性相关,所以需要去掉通话时长--避免共线性
df.drop(['total_day_charge','total_eve_charge','total_night_charge','total_intl_charge'],axis=1,inplace=True)
#添加用户在每个时间段的平均通话时长
df['avg_day_minutes']=df.apply(lambda x: x.total_day_minutes/x.total_day_calls
if x.total_day_calls != 0 else 0, axis=1)
df['avg_eve_minutes']=df.apply(lambda x: x.total_eve_minutes/x.total_eve_calls
if x.total_eve_calls != 0 else 0, axis=1)
df['avg_night_minutes']=df.apply(lambda x: x.total_night_minutes/x.total_night_calls
if x.total_night_calls != 0 else 0, axis=1)
df['avg_intl_minutes']=df.apply(lambda x: x.total_intl_minutes/x.total_intl_calls
if x.total_intl_calls != 0 else 0, axis=1)
可视化缺失值分布
#缺失值数可视化
import seaborn as sns
sns.heatmap(df.isnull()) #可视图看出没有缺失值

由上图可知,数据集中已无缺失值。至此,数据预处理完毕。
训练模型
现在有许多成熟且有科学的数学理论支撑的二分类算法模型,比如支持向量机、逻辑回归和决策树等。
模型对比
训练各算法模型并比较分类效果
x=df.drop('churn',axis=1) #特征集
y=df['churn'] #标签
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.ensemble import VotingClassifier
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
model1=LogisticRegression(solver='liblinear')
model2=DecisionTreeClassifier()
model3=SVC()
model4=KNeighborsClassifier()
model_combo=VotingClassifier(estimators=[('lrp',model1),('dt',model2),('sv',model3),('knn',model4)])
from sklearn.model_selection import cross_val_score
model1_score=cross_val_score(model1,x,y,scoring='f1',cv=10,verbose=0) #verbose=0 为不在标准输出流输出日志信息
model2_score=cross_val_score(model2,x,y,scoring='f1',cv=10,verbose=0)
model3_score=cross_val_score(model3,x,y,scoring='f1',cv=10,verbose=0)
model4_score=cross_val_score(model4,x,y,scoring='f1',cv=10,verbose=0)
model_combo_score=cross_val_score(model_combo,x,y,scoring='f1',cv=10,verbose=0)
print('LogisticRegression',model1_score.mean()) #0.29
print('DecisionTreeClassifier',model2_score.mean()) #0.70
print('SVC',model3_score.mean()) #0.01
print('KNeighborsClassifier',model4_score.mean()) #0.45
print('model combo',model_combo_score.mean()) #0.11
method_name=np.array(['LogisticRegression','DecisionTreeClassifier','SVC','KNeighborsClassifier','model combo'])
mult_method_score=np.array([0.29,0.70,0.01,0.45,0.11])
fig, ax = plt.subplots(figsize=(30,10))
method_name_sort = method_name[np.argsort(mult_method_score)]
mult_method_score_sort = mult_method_score[np.argsort(mult_method_score)]
ax.set_yticks(np.arange(len(method_name_sort)), method_name_sort, fontsize =18)
rect=ax.barh(np.arange(len(method_name_sort)), mult_method_score_sort)
ax.bar_label(rect, padding=3)
ax.set_xlabel('f1_score')
plt.title('模型效果对比')
plt.savefig('image/模型效果对比.jpg',dpi=400)
plt.show()

发现决策树模型在这个数据集和实际业务问题中表现最佳,所以决定采用决策树模型。
f1_score为模型的综合得分
训练决策树
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=50)
model2.fit(x_train,y_train)
model2_pred_train= model2.predict(x_train)
f1_score(y_train,model2_pred_train) #1.0
## testing data
model2_pred_test = model2.predict(x_test)
f1_score(y_test,model2_pred_test) #0.69
model2.tree_.max_depth #max_depth=21
在没有进行任何调参数的情况下,这个决策树模型应用在训练集上的f1_score为1,而在测试集上的f1_score仅为0.69,且该决策树树深为21,初步判断该决策树过拟合了。一般采用剪枝解决决策树的过拟合问题。
过拟合:当模型过度拟合训练集的数据而导致模型在训练集上的表现极佳,但是在测试集上表现欠佳(也称模型的泛化能力差)。
剪枝:减少树的深度
网格搜索-优化决策树
调用sklearn中的网格搜索以训练不同最大树深的决策树,并对比他们K层交叉检验后的f1_score,找出泛化能力强的决策树深度。
K层交叉检验就是把原始的数据随机分成K个部分。在这K个部分中,选择一个作为测试数据,剩下的K-1个作为训练数据。
交叉检验的过程实际上是把实验重复做K次,每次实验都从K个部分中选择一个不同的部分作为测试数据(保证K个部分的数据都分别做过测试数据),剩下的K-1个当作训练数据进行实验,最后把得到的K个实验结果平均。
parameter_grid = {'max_depth':range(1,50)}
import numpy as np
from sklearn.model_selection import GridSearchCV # import
gird = GridSearchCV(model2,
parameter_grid,
verbose=2,
scoring='f1',
return_train_score=True,
cv=10) #initialize
gird.fit(x,y)
## verbose shows the output
## best parameters
gird.best_params_
gird.best_score_
results=gird.cv_results_
ddf_result=pd.DataFrame(results)
results['mean_train_score']
save_grid_best_balance=DecisionTreeClassifier(max_depth=9)
#visualizing the process of training
plt.figure(figsize=(13, 13))
plt.title("GridSearchCV evaluating using different max_depth", fontsize=16)
plt.xlabel("max_depth")
plt.ylabel("f1_score")
ax = plt.gca()
ax.set_xlim(1,51)
ax.set_ylim(0.6, 1)
# Get the regular numpy array from the MaskedArray
X_axis = np.array(results["param_max_depth"].data, dtype=float)
for sample, style in (("train", "--"), ("test", "-")):
sample_score_mean = results["mean_%s_score" % sample]
sample_score_std = results["std_%s_score" % sample]
ax.plot(
X_axis,
sample_score_mean,
style,
alpha=1 if sample == "test" else 0.7,
label="f1 (%s)" % sample,
)
best_index = np.nonzero(results["rank_test_score" ] == 1)[0][0]
best_score = results["mean_test_score"][best_index]
# Plot a dotted vertical line at the best score for that scorer marked by x
ax.plot(
[
X_axis[best_index],
]
* 2,
[0, best_score],
linestyle="-.",
marker="x",
markeredgewidth=3,
ms=8,
)
best_score=round(best_score,2)
# Annotate the best score for that scorer
ax.annotate('['+str(best_index)+','+str(best_score)+']', (X_axis[best_index], best_score + 0.005))
plt.legend(loc="best")
plt.grid(False)
plt.savefig('image/训练过程可视化.jpg',dpi=400)
plt.show()
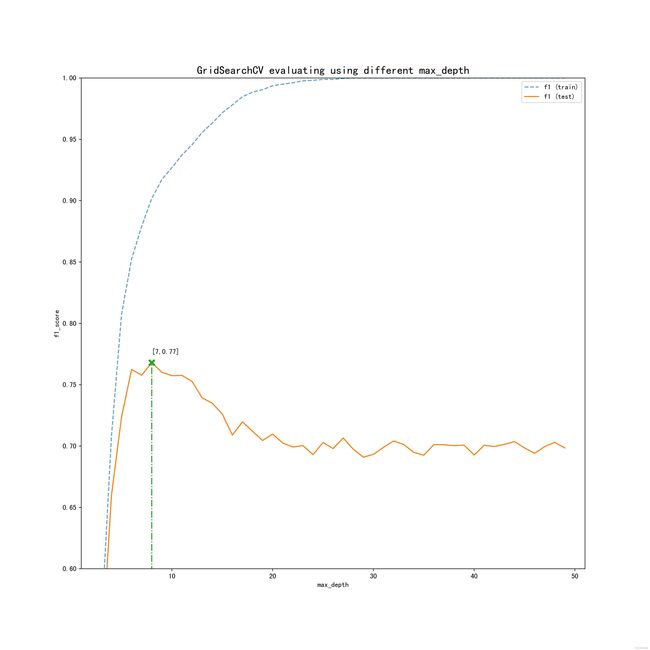
由上图可知,当max_depth=7时,决策树的表现虽然在训练集上还没达到最好的表现,但是这时在测试集上表现最佳,所以应该选择max_depth=7作为训练决策树模型的参数。
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=4)
dt = DecisionTreeClassifier(max_depth=7) #initialize
dt.fit(x_train,y_train) #fit
dt_pred_test = dt.predict(x_test)
评判模型效果-混淆矩阵
二分类算法的预测结果的混淆矩阵通常最能说明模型的预测效果
def confusion_matrix_func(y_true,y_pred,labels,image_name):
from sklearn.metrics import (confusion_matrix,precision_score,
recall_score,accuracy_score,f1_score)
import matplotlib.pyplot as plt
from mlxtend.plotting import plot_confusion_matrix
conf_matrix = confusion_matrix(y_true=y_true, y_pred=y_pred)
fig, ax = plt.subplots(figsize=(7.5, 7.5))
ax.matshow(conf_matrix, cmap=plt.cm.Blues, alpha=0.3)
plot_confusion_matrix(conf_mat=conf_matrix, figsize=(6, 6), cmap=plt.cm.Greens)
plt.xlabel('Predictions', fontsize=18)
plt.ylabel('Actuals', fontsize=18)
plt.title('Confusion Matrix', fontsize=18)
textstr = '\n'.join((
r'f1_score:%.2f' % f1_score(y_true,y_pred),
r'accuracy:%.2f' % accuracy_score(y_true,y_pred),
r'precision:%.2f' % precision_score(y_true,y_pred),
r'recall:%.2f' % recall_score(y_true,y_pred)
))
props = dict(boxstyle='round', facecolor='wheat', alpha=0.5)
plt.text(3.1,4.2,textstr, transform=ax.transAxes, fontsize=12,
verticalalignment='top', bbox=props)
xlocations = np.array(range(len(class_names)))
plt.xticks(xlocations, class_names)
plt.yticks(xlocations, class_names)
plt.savefig('image/'+image_name+'_confusion_matrix.jpg', dpi=300)
confusion_matrix_func(y_test,dt_pred_test,class_names,image_name='decsion_tree_2')

TN(True Negative-真阴性):模型预测为不会流失的用户中,实际上确实没流失的用户
FN(False Negative-假阴性):模型预测为不会流失的用户中,但实际上其实是流失掉的用户
FP(False Positive-假阳性):模型预测为会流失的用户中,但实际上其实是没流失的用户
TP(True Positive-真阳性):模型预测为会流失的用户中,实际上确实流失掉的用户
在该预测结果中:
Accuracy=准确率=(TP+TN)/(TP+TN+FP+FN)=0.95,表示模型预测的结果有95%都是正确的。
Recall=召回率=真阳性率=TP/(TP+FN)=0.78,表示实际上流失掉的用户中,有78%被模型识别出来了。
Precision=精度=TP/(TP+FP)=0.84,表示模型预测为会流失的用户中,有84%是确实会流失的。
f1_score=2*Recall*Precision/(Recall+Precision)=0.71,表示召回率和精度的综合评分为81分(100分满分)
值得注意的是,优化决策树最后的结果表明交叉检验的f1_score平均值为0.77,但是模型混淆矩阵中的f1_score竟能高达0.81。这是由于,交叉检验的平均值就好比一个考生考了10次考试的平均值,而混淆矩阵仅能说明该考生一次考试中的具体情况。
在一般的二分类预测任务中,通常以f1_score为判断模型好坏的标准,因为f1_score代表了模型预测的综合表现。至此,经过了数据预处理、模型的选取、模型训练及模型优化、模型的评价,标准的解决二分类问题的流程就结束了。
但是在预测流失的业务场景中,由于客户终身价值一般会比留存成本高出好几倍,也就是说损失掉一个客户的代价往往比挽留一个客户的成本要高不少,所以这时Recall(召回率)就是最重要的指标,召回率越高模型就越不容易放过要流失掉的客户。在优先保证召回率的前提下,f1_score应为评判模型的第二指标。
进阶分析-模型再优化
要想提高模型的召回率,最直接的做法为增加流失掉客户的权重,即改变决策树参数中的class_weight参数。这是因为当给“流失”这一类别的权重越多,模型就越倾向于将客户预测成会流失,使得召回率会随之上升。而更多本不该被标记成“流失”的客户也会被标记成“流失”,使得精度下降。综合了召回率的上升和精度的下降,f1_score会时而上升时而下降,但总体的趋势一定是随着人为给的某一类别的权重越来越极端而下降。
score_list_class_weight_f1=[]
score_list_class_weight_recall=[]
for i in range(0,30,1):
class_weight_dict = {0:1,1:i+1}
dt = DecisionTreeClassifier(max_depth=7,class_weight=class_weight_dict)
score_f1=cross_val_score(dt,x,y,scoring='f1',cv=10,verbose=1).mean()
score_list_class_weight_f1.append(score_f1)
score_recall=cross_val_score(dt,x,y,scoring='recall',cv=10,verbose=1).mean()
score_list_class_weight_recall.append(score_recall)
#plt.figure(figsize=[20,5])
fig, ax=plt.subplots(figsize=[20,5])
ax.plot(range(1,31,1),score_list_class_weight_recall,label='recall')
ax.plot(range(1,31,1),score_list_class_weight_f1,label='f1')
ax.legend(loc='lower right')
ax.set(xlabel='class_weight',ylabel='Score',title='f1 score and recall score of Decision tree in different class_weight')

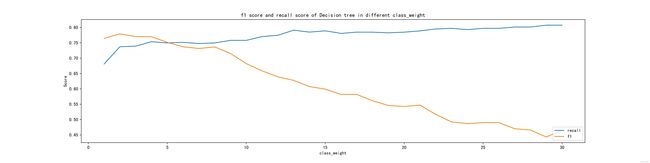
网格搜索2
结合优化决策树中的max_depth和上述的class_weight这两参数训练模型,并记录不同参数的决策树模型的f1_score和recall
import numpy as np
from sklearn.model_selection import GridSearchCV # import
parameter_grid = {'max_depth':range(2,12),
'class_weight':[{0:1,1:i} for i in range(1,30)]}
scoring=['f1','recall']
gird = GridSearchCV(model2,
parameter_grid,
verbose=2,
scoring=scoring,
refit='f1',
return_train_score=True,
cv=10) #initialize
gird.fit(x,y)
results_after=gird.cv_results_
result_df_after=pd.DataFrame(results_after)
result_df_edited_after=result_df_after[['param_class_weight','param_max_depth','mean_test_recall','mean_test_f1','mean_train_recall','mean_train_f1','std_test_recall','std_test_f1']]
fig,ax=plt.subplots()
ax.set_xlim(0.4,0.9)
ax.set_ylim(0.3, 0.8)
ax.scatter(result_df_edited_after['mean_test_recall'],result_df_edited_after['mean_test_f1'])
ax.set(xlabel='recall score',ylabel='f1 score', title='the trade off between recall score and f1 score')
plt.show()

这时,我们可以画出该散点图的边界。

借用一下经济学中资产定价模型的概念,该边界顶点的右边的点形成的曲线可以称之为有效前沿,这是因为在相似的Recall score的情况下,有效前沿有着最高的f1 score; 在相似的f1 score的情况下,有效前沿有着最高的Recall score。
甚至,可以用多项式拟合边界的曲线。
result_df_edited_after['mean_test_recall']=round(result_df_edited_after['mean_test_recall'],2)
result_df_edited_after['mean_test_f1']=round(result_df_edited_after['mean_test_f1'],2)
fig,ax=plt.subplots()
ax.set_xlim(0.4,0.9)
ax.set_ylim(0.3, 0.8)
ax.scatter(result_df_edited_after['mean_test_recall'],result_df_edited_after['mean_test_f1'])
plt.show()
df_groupby= result_df_edited_after[['mean_test_recall','mean_test_f1']].groupby(by='mean_test_recall',as_index=False).max()
df_merge=pd.merge(df_groupby,result_df_edited_after,on=['mean_test_recall','mean_test_f1'],how='left')
df_merge_deleted=df_merge[~((0.55<df_merge['mean_test_recall'])
& (df_merge['mean_test_recall']<0.7)
& (0.5<df_merge['mean_test_f1'])
& (df_merge['mean_test_f1']<0.6))]
df_merge_deleted.to_csv('df_merge_deleted.csv',index=False)
df_merge_deleted=pd.read_csv('df_merge_deleted.csv')
## build a f1 score function of recall score
fig,ax=plt.subplots()
ax.set_xlim(0.4,0.9)
ax.set_ylim(0.3, 0.8)
ax.scatter(df_merge_deleted['mean_test_recall'],df_merge_deleted['mean_test_f1'])
score_of_recall=df_merge_deleted['mean_test_recall']
score_of_f1_initial=df_merge_deleted['mean_test_f1']
para=np.polyfit(score_of_recall, df_merge_deleted['mean_test_f1'], deg=12)
score_f1_r=np.poly1d(para)
score_f1_r_demical2=[]
for i in range(len(score_f1_r)):
score_f1_r_demical2.append(round(score_f1_r[i],2))
score_of_f1=score_f1_r(score_of_recall)
ax.plot(score_of_recall,score_of_f1,'g')
ax.set(xlabel='recall score',ylabel='f1 score', title='curve fitting')
plt.show()
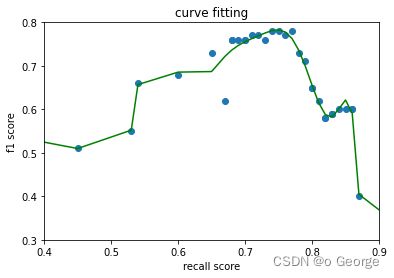
参数选择
现在我有了多个决策树模型,且这些决策树模型的参数和分类效果都各不相同,那么怎么根据实际的业务问题去选择具体的最佳的某一个决策树模型呢?本文采用定量的数学建模来辅助决策,并使用交互界面帮助企业根据自己的实际情况选择合适的模型。
假设这样一个情况,当该电信公司进行一次用户留存(比如每个月给可能要流失的用户发放coupon)时,假设该公司现有10000个用户,每次发放coupon的成本是5刀,而用户平均终身价值为31刀,且该月的用户流失率与数据集中的流失率一致,即实际上该月应该会有10000*流失率约等于1450个用户会流失。该公司的运营人员即可通过https://zhuozhiou.github.io/留存问题解决方案.html这个APP 将滑块①滑到step=客户终身价值/客户留存成本*10=31/5*10=62的位置,查看这种情况下预期损失最小的决策树模型的参数。
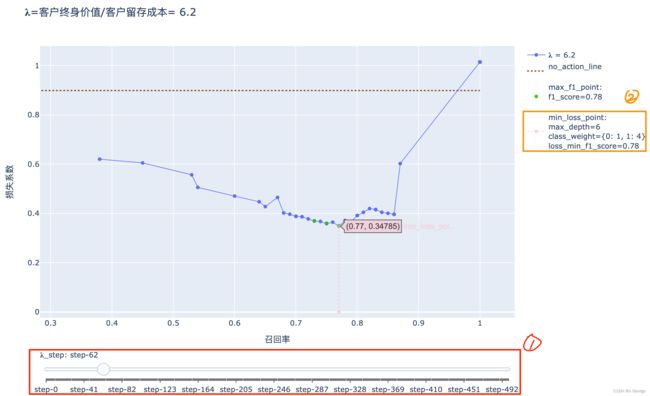
如图上所示,这时预期损失最小的决策树模型对应的召回率和f1 score分别为0.77、0.78,这表示在网格搜索的结果中,用②max_depth=6且class_weight={0:1,1:4}的决策树模型来预测用户流失能使预期的损失系数最小。可以算出精度=f1_score*Recall/(2*Recall-f1_score)=0.80。
这意味着在10000churn_ratio=1450个会流失的用户中,有77%(这表示TP=1117)的人被我们成功识别出来,剩下的333个(FN)没有被识别出来;而被标记成流失的用户中,有80%确实是会流失的,且有20%(这表示FP=279)人被误诊为会流失。所以电信公司预期损失为(279+1117)*5+279*31=15629(美元)。而损失系数的意义在于,它能更精准的预测电信公司的具体损失,能更快捷地计算出预计损失为损失系数客户总数*留存成本=17392.5(美元)。
应该说明的是,用损失系数计算出来的结果和用模型效果指标计算出来的结果不尽相同,这是因为上述的模型效果指标都是经过四舍五入的,所以真实的业务场景的损失更加接近17392.5。
总的来说,该APP实现了根据企业实情去选择合适的参数训练决策树模型的功能,并理论上能使企业的在用户流失方面的损失最小。
一个APP仅适用于一个提供了用户行为数据集的企业,也就是说对于某一企业而言,这套解决方案是定制性的。而搭建的思路和方法同样适用于要处理用户留存问题的、有收集用户行为数据能力的企业。
上述的损失系数搭建过程如下:
实际预期流失人数=流失率*客户数量
TP=实际预期流失人数*召回率
FN=实际预期流失人数-TP
FP=TP/精度-TP
预计损失=FN*客户终身价值+(TP+FP)*留存成本
损失系数=预计损失/(客户总数*留存成本)
所以预计损失也=损失系数*客户总数*留存成本
搭建交互界面的代码如下:
def f_loss_data(loss_to_cost):
score_of_recall=df_merge_deleted['mean_test_recall']
score_of_f1=df_merge_deleted['mean_test_f1']
Retention_Cost=1
people_num=1
loss_to_cost=loss_to_cost
Potential_Loss=loss_to_cost*Retention_Cost
churn_ratio=0.14491449144914492
score_of_prec=score_of_f1*score_of_recall/(2*score_of_recall-score_of_f1)
Actual_churn=churn_ratio*people_num
TP=Actual_churn*score_of_recall
FN=Actual_churn-TP
FP=TP/score_of_prec-TP
loss_r=FN*Potential_Loss+(TP+FP)*Retention_Cost
dic={
'mean_test_recall':score_of_recall,
'mean_test_f1':score_of_f1,
'score_of_prec':score_of_prec,
'loss_r':loss_r
}
df_loss_r=pd.DataFrame(dic)
df_loss_r['mean_test_recall']=round(df_loss_r['mean_test_recall'],2)
df_loss_r['mean_test_f1']=round(df_loss_r['mean_test_f1'],2)
df_loss_r_merge=pd.merge(df_merge_deleted,df_loss_r,on=['mean_test_recall','mean_test_f1'],how='left')
return df_loss_r_merge
import plotly.graph_objects as go
import plotly
# Create figure
fig = go.Figure()
# Add traces, one for each slider step
for step in np.arange(0, 50, 0.1):
step=round(step,1)
data=f_loss_data(step)
loss_min_index=np.argmin(data['loss_r'])
loss_min_score=round(data['loss_r'][loss_min_index], 5)
loss_min_recall=data['mean_test_recall'][loss_min_index]
loss_min_f1_score=data['mean_test_f1'][loss_min_index]
loss_min_class_weight=data['param_class_weight'][loss_min_index]
loss_min_max_depth=data['param_max_depth'][loss_min_index]
f1_max_f1_score=data['mean_test_f1'].max()
df_loss_r_max_f1=data[data['mean_test_f1']==f1_max_f1_score]
f1_max_recall=df_loss_r_max_f1['mean_test_recall']
f1_max_score=round(df_loss_r_max_f1['loss_r'], 2)
fig.add_trace(
go.Scatter(
visible=False,
line=dict(width=1),
mode='lines+markers',
name=" = " + str(step),
x=data['mean_test_recall'],
y=data['loss_r']))
x_no_action=np.linspace(0,1)
loss_no_action=0.14491449144914492*step+0*x_no_action
fig.add_trace(go.Scatter(
visible=False,
line=dict(dash='dot'),
x=x_no_action, y=loss_no_action,
name='no_action_line
',
marker_color='rgba(124, 53, 3, .9)'))
fig.add_trace(go.Scatter(
visible=False,
mode='markers',
x=f1_max_recall,
y=f1_max_score,
name='max_f1_point:'+'
'+'f1_score='+str(f1_max_f1_score)+'
',
marker_color='rgba(32, 200, 0, .9)'))
fig.add_trace(go.Scatter(
visible=False,
line=dict(dash='dot'),
x=[loss_min_recall,loss_min_recall],
y=[0,loss_min_score],
name='min_loss_point:'+'
'+'max_depth='+str(loss_min_max_depth)+'
'+'class_weight='+str(loss_min_class_weight)+'
'+'loss_min_f1_score='+str(loss_min_f1_score),
marker_color='rgba(255, 182, 193, .5)'))
# Make 10th trace visible
fig.data[10*4].visible = True
fig.data[10*4+1].visible = True
fig.data[10*4+2].visible = True
fig.data[10*4+3].visible = True
# Create and add slider
steps = []
for i in range(int(len(fig.data)/4)):
step = dict(
method="update",
args=[{"visible": [False] * len(fig.data)},
{"title": "=客户终身价值/客户留存成本= " + str(i/10)}], # layout attribute
)
step["args"][0]["visible"][i*4] = True # Toggle i'th trace to "visible"
step["args"][0]["visible"][i*4+1] = True
step["args"][0]["visible"][i*4+2] = True
step["args"][0]["visible"][i*4+3] = True
steps.append(step)
steps
sliders = [dict(
active=10,
currentvalue={"prefix": "_step: "},
pad={"t": 50},
steps=steps
)]
sliders
fig.update_layout(
sliders=sliders,
title='滑动页面底部滑块至 _step=客户终身价值/客户留存成本*10 的位置上',
xaxis=dict(visible=True,title=dict(text='召回率')),
yaxis=dict(visible=True,title=dict(text='损失系数'))
)
plotly.offline.plot(fig, filename='留存问题解决方案.html')
决策树模型可视化
from io import StringIO
import pydotplus
from sklearn.tree import export_graphviz
from ipywidgets import Image
dt6=DecisionTreeClassifier(random_state=19,max_depth=6,class_weight={0:1,1:4}).fit(x_train,y_train)
dot2_data=StringIO()
export_graphviz(decision_tree=dt6,
out_file=dot2_data,filled=True,
feature_names=df.drop(['churn'], axis=1).columns)
graph1=pydotplus.graph_from_dot_data(dot2_data.getvalue())
Image(value=graph1.create_png())
#Image(graph1.create_png()) #show image
graph1.write_pdf("tree6.pdf")

后记
如果数据是弹药、数据分析手段是武器、解决业务问题是靶心。那么,如果靶心是“新功能上线后的留存率是否比之前要高,为什么?”,数据应该就要是有时序信息、点击浏览量、各环节的停留时间等用户信息,数据分析手段可以是留存率是否改变的假设检验说明“发生了什么”的这种描述性问题,然后是通过同期群分析、可视化分析去说明“为什么”的这种解释性问题,最后通过上述的分析提出解决方法并跟踪跟进后的用户数据验收效果。这个靶心所要求的数据分析手段在技术性上要求没那么高,基础的假设检验、可视化工具就能解决问题。而本文回答的“用户是否会流失?”的问题需要通过二分类各种机器学习算法去预测,然后还结合了实际业务场景,将有限数据维度的数据集用尽其用来提取出商业价值。
但值得注意的是,无论是鸟枪还是大炮,能精准地击中目标的就是趁手的武器,且如今很多成熟公司的用户数据都十分立体且维度丰富,所以日后更重要的能力是筛选和提取出有用的数据并且能运用合适的数据分析手段给业务赋能。