[yzhpdh多读论文]How Powerful are Interest Diffusion on Purchasing Prediction: A Case Study of Taocode
How Powerful are Interest Diffusion on Purchasing Prediction: A Case Study of Taocode
Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. (2021)
作者介绍
浙江大学 & 阿里巴巴
通讯作者:杨洋(浙江大学)
research interest:
- Anomaly Detection in Graphs.
- Time2Graph: Revisiting Time Series Modeling from the Perspective of Graphs.
- Learning Robust Graph Models.
Link:http://yangy.org
introduction
本文从 Taocode(一种特殊的文本编码,用户可以用其进行产品有关信息分享) 出发,利用该信息理解用户之间的社会关系。
文章认为:用户购买商品的行为一般是出两种动机,一是出于自身的需要,二是被亲近的朋友推荐,在这种情况下即使没有紧急的需要也会促进其购买该商品。
因此这篇文章主要从 information diffusion 这一角度研究网购预测的问题
文章认为通过朋友与朋友间的传播,可以用 ‘interest diffusion’ 来表示。
为什么之前这类工作比较少?
1.信息难以获得,大多兴趣扩散都发生在私人社交通信过程中,以往通过分析邮件的工作在现实生活中会产生偏差。
2.问题难以建模,用户对不同产品的兴趣可能会呈现不同的扩散模式,兴趣扩散的动态建模仍然是一个具有挑战性的研究问题。
如何利用淘码进行兴趣传播
![[yzhpdh多读论文]How Powerful are Interest Diffusion on Purchasing Prediction: A Case Study of Taocode_第1张图片](http://img.e-com-net.com/image/info8/7b467aa9cae04883ac791c809bc9b772.jpg)
作者在文章中提到,Taocode的传播过程可以被淘宝完整记录下来,所以可以追踪物品在扩散流上的显式共享路径,哪个用户在什么时间与谁共享哪个产品的详细信息。
面临的建模难点:大多数现有GNN可能无法处理不同时间的动态边权值。
所以文章去深入了解Taocode传播的行为模式,并且提出了几点见解,最后提出InfNet这一框架。
Contributions:
- 提出了一个对在线网购平台中的商品共享进行大规模分析,以淘宝中的Taocode为例。
- 对1亿条Taocode共享数据进行综合分析,描述了几个商品兴趣传播在淘宝社交网络上的隐含特征。
- 设计了一个端到端框架:InfNet,进行购买预测。实验表明了他们用于捕获用户对不同商品和兴趣传播动态的多层序列和图注意力机制是有效的。
Problem Formulation:
接下来介绍一下文章的定义,
![[yzhpdh多读论文]How Powerful are Interest Diffusion on Purchasing Prediction: A Case Study of Taocode_第2张图片](http://img.e-com-net.com/image/info8/f553c979284a4691b917ae2175899f7d.jpg)
![[yzhpdh多读论文]How Powerful are Interest Diffusion on Purchasing Prediction: A Case Study of Taocode_第3张图片](http://img.e-com-net.com/image/info8/87bd33df273e413b88980c440a793862.jpg)
![[yzhpdh多读论文]How Powerful are Interest Diffusion on Purchasing Prediction: A Case Study of Taocode_第4张图片](http://img.e-com-net.com/image/info8/4282268dbb2348f7ac50e0059b7399dd.jpg)
![[yzhpdh多读论文]How Powerful are Interest Diffusion on Purchasing Prediction: A Case Study of Taocode_第5张图片](http://img.e-com-net.com/image/info8/c248adec5e784a64929ff25946c15801.jpg)
问题建模
文章从共1亿的Taocode共享记录中采样,然后从不同时间步长的Taocode记录中构建兴趣扩散网络:在每个时间跨度内都有一个唯一的扩散网络,其中每个节点代表一个用户,两个节点之间的有向边表示淘码共享关系。此外,网络结构的动态揭示了信息在边之间的扩散,这可能反映了用户对不同商品组的购买偏好。
输入:一个 user-item pair
目标:利用在给定时间跨度内的兴趣扩散网络序列,根据购买和Taocode扩散历史来估计用户购买该产品的可能性
3 OBSERV ATIONAL STUDIES
3.1 Dataset descriptions
作者分析了2020年中某一段时间内的数据。
每条数据包含:
- 创建和共享Taocode的人,即发送者;
- 谁接收到淘码,即接收者;
- 接收者何时打开Taocode链接,即时间戳;
- 此Taocode所代表的商品的详细信息,包括其价格指数(PI)及其所属类别
3.2 Taocode’s effect on purchases
Q1:Taocode扩散对用户购买行为有影响吗?
文章对应提出了一个指标:conversion index(CI)
![[yzhpdh多读论文]How Powerful are Interest Diffusion on Purchasing Prediction: A Case Study of Taocode_第6张图片](http://img.e-com-net.com/image/info8/590227f1b74a457f9e602be397e0e80a.jpg)
f是一个单调递增的标量函数,可以将原始比例映射导另外一个值,这样是为什么数据隐私考虑。淘码的CI,记录是淘码消息。
文章进一步将 CI(淘码)/CI(分享)的比值表示为CI Lift,以揭示淘码分享对购买行为的影响。
如果一个产品的CI Lift值很高,那么它在通过淘码分享后就更有可能被购买。
文章比较了所有产品的淘码分享和产品浏览记录的平均CI,
通过淘码分享的商品更有可能被购买。
CI Lift与平均PI呈显著正相关,PI与CI Lift的Spearman相关性为0.336,换句话说,当物品的PI增加时,它的CI Lift也会变高
![[yzhpdh多读论文]How Powerful are Interest Diffusion on Purchasing Prediction: A Case Study of Taocode_第7张图片](http://img.e-com-net.com/image/info8/037e5e5ae1a14d7e895fe5ad7f62906c.jpg)
3.3 Structural dynamics of Taocode
Q2:Are there any structural characteristics of Taocode diffusion patterns?
文章将所有时间点建立的 Taocode diffusion network合成一个。并且计算了每个用户对应的 不同类别产品的入度和出度。 超过80%的用户的度数在1-9之间。展现出一个长尾形态。
主要有以下发现:
- 处于网络中心的消费者很容易受到他人的影响;
- 我们发现当发送者和接收者之间的度差越大时,CI就会越高。这可以解释为,如果一个用户与另一个社交行为模式非常不同的用户进行社交互动,她的在线购物可能会更频繁;
Q3: the influence of the receiver’s neighbors in the Taocode diffusion
文章将发送者的接收到Taocode码并且买到相同产品的一跳邻居作为 close neighbors,
接收者的 close neighbors可以在一定程度上反映扩散流中物品的受欢迎程度。
3.4 Temporal dynamics of Taocode
Q4:Does the senders’ past receiving history do have impact on receivers’ purchasing?
Taocode的长、短期时间动态存在,一个Taocode信息越频繁的在短期内传播,CI越高。或者一个用户会在收到一个产品后很长时间后才会分享该商品,因为要评估该商品是否值得推荐。
4 MODEL:INFNET
该框架首先为每个查询构建一个“动态子网络”序列,然后在动态节点和边属性上应用两种不同的基于注意力的聚合策略来学习用户的隐藏表示。最后,用户的嵌入以及商品特征被输入到外部分类器中,以预测目标用户是否会在给定的时间跨度内购买商品。
4.1 Preprocessing: Sub-graph construction
Seed node sampling
选取目标用户与其1跳节点
Sub-network construction
给定了seed nodes后,采用一个BFS策略寻找2条邻居,从每个原始传播网络中进行采样节点。
Node and edge attributes
节点属性:Attr(u):用户购买记录和一个 one-hot编码,表示该节点是否为查询中的节点或seed node.
边属性:是用户u发给用户v这条边上的所有特征在时间区间t的和。
4.2 Structural block
文章通过第3章的分析认为局部图结构是判断Taocode能够促进购买的重要因素。
该模块是用于学习结构特征的,即对于一个用户u,第一层是对用户属性做一个非线性转换,并输出初始隐含表示。
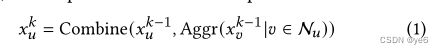
4.3 Diffusion block
因为structural block只学习了节点特征,没有考虑用户间动态的商品传播过程,且文章提出一个场景:假如用户v收到了很多衣服或电脑的Taocode,但用户v只向用户u分享了衣服的Taocode,那么对于用户v关于电脑的信息中可能会成为预测用户u购买行为的噪音。
所以文章设计了一个特殊的多层合并策略:
1.学习每条边的权重;
2.然后合并 节点与其邻居之间 的边特征得到一个更新的表示;
通过注意力机制,邻居节点的表示将会间接影响节点的最终表示并且避免噪音被学习到。
为了捕获Taocode的动态,文章独立地合并了与用户相连的边的属性,从而获得每个时间点的隐藏状态。对于相同的用户,在每个时间点的初始状态都是相同的(用户节点属性的非线性变化获得),然后对于用户u在时间点t且位于第k层时,文章分别对节点的入边和出边进行表示。
![[yzhpdh多读论文]How Powerful are Interest Diffusion on Purchasing Prediction: A Case Study of Taocode_第8张图片](http://img.e-com-net.com/image/info8/8e84dcb6b5ad43878605eafdcaa10798.jpg)
ATT是一个注意力函数,将用户在最后一层的隐藏状态和边属性作为输入,然后输出边的注意力权重。
除此之外,文章还使用一个序列编码器获取时间动态。
![]()
Enc可以只是一个简单的操作,如Mean-pooling、GRU、Masked self-attention。
4.3 Model learning
在获得用户结构表征和Taocode传播表征后,文章将这二者合起来预测用户购买行为。
文章不仅考虑用户u的表示和商品p属性,还考虑了将商品发给u的人。

将目标用户结构表征、Taocode传播表征、向目标用户发送Taocode的用户的表征、商品的属性作为输出层的输入,获得预测结构,文章中将交叉熵作为损失函数。
![]()

5 Experiments
5.1 Experimental setup
文章将整个时间跨度分成四个相等的段,这意味着每个查询总共有四个扩散子图,以一周为时间步长。为了使离线实验与在线上预测时查询时间之前无法获得任何信息的情况保持一致,我们将前两天的数据集以7:3的比例随机分为训练集和验证集,第三天的所有查询都用于测试。
![[yzhpdh多读论文]How Powerful are Interest Diffusion on Purchasing Prediction: A Case Study of Taocode_第9张图片](http://img.e-com-net.com/image/info8/1c0a22ea57e04a68b54fadc0e726fdbd.jpg)
Result
与最佳baselines方法相比,本文的方法在AUC_PR和AUC_ROC方面分别带来了4.6%和6.3%的平均相对性能增长
![[yzhpdh多读论文]How Powerful are Interest Diffusion on Purchasing Prediction: A Case Study of Taocode_第10张图片](http://img.e-com-net.com/image/info8/88abad0f8bdb45f1a6e565f7d4c3af13.jpg)
5.3 In-depth analysis of InfNet
不仅如此,文章还做了消融实验。并且发现屏蔽Taocode特性导致的性能下降幅度最大。这说明Taocode是预测用户购买行为的关键因素,因此InfNet可以更好地对Taocode扩散模型进行购买预测.
因此得出的结论是:
- 序列编码器是InfNet必不可少的组成部分,self-attention是InfNet的最佳选择。
- 在InfNet的输入特性中,Taocode的信息量最大。
- 注意力机制可以帮助InfNet更好地模拟Taocode兴趣扩散。
- 结构信息也有利于模型的改进。
![[yzhpdh多读论文]How Powerful are Interest Diffusion on Purchasing Prediction: A Case Study of Taocode_第11张图片](http://img.e-com-net.com/image/info8/33b46fb69bd84ff2823ee12c973d466d.jpg)
Cold-start challenge
为了进一步验证InfNet的强大,我们对传统推荐系统所面临的挑战进行了分析,即冷启动问题。文章使用了负采样的方法,即找出一些没有购买记录的用户,冷启动有两种不同的类型:产品冷启动和用户冷启动,而这里我们关注的是用户冷启动问题。文章发现除了Cate#2之外,InfNet在Cold上比DiffNet的改进显著高于Warm,这表明InfNet是解决冷启动问题的潜在更好的方法。
![[yzhpdh多读论文]How Powerful are Interest Diffusion on Purchasing Prediction: A Case Study of Taocode_第12张图片](http://img.e-com-net.com/image/info8/c1f4d163453644b2a5db732425943ec7.jpg)
Conclusion
本文研究了以Taocode为例,网络购物平台中信息扩散对用户购买行为的影响。
- 文章收集了一个大规模的现实数据集,其中包括超过1亿的Taocode共享记录。
- 基于数据集,进行了实证观察,探讨了淘宝上产品兴趣扩散的内在属性,发现淘码扩散对用户购买行为有很强的影响,而扩散网络的结构动态和时间动态在这种相关性中起着关键作用.
- 受这些观察见解的启发,设计了一个基于gnn的端到端框架,称为InfNet,通过Taocode对产品兴趣扩散进行建模。更具体地说,应用图级和序列级注意机制来捕捉用户在不同时间步骤对不同产品的兴趣动态。
- 在真实世界六种不同产品类别的Taocode扩散数据集上的项目级购买预测任务中,与最先进的baselines相比,InfNet取得了明显更好的性能;此外,消融研究表明,通过仔细设计的结构和时间组件,可以引入了额外的预测能力。
读后感:看起来是一篇和阿里合作的文章,所以说数据应该是很丰富的,但这种数据太过于隐私了,所以无法复现,也需要校企合作的契机。
但文章中实证观察的角度可以学习参考用于自己的工作。
还有一个问题是文章提出的框架看起来流程还是比较繁琐的,不知道构图的时间消耗是否适合在线推荐。