Make Your First GAN With PyTorch:2. 第一个 PyTorch 网络(上)
本章通过构建一个简单但常见的实际神经网络,来加深对 PyTorch 和神经网络的认识。
本章是 Make Your First GAN With PyTorch 的第 2 章(由于篇幅较长,分上下两篇发布),其他介绍详见这篇文章。
本文目录
- 1. MNIST 图像数据集
-
- 1.1 下载 MNIST 数据并上传到 Google Colab
- 1.2 观察 MNIST 数据
-
- 1.2.1 挂载 Google Drive 为文件夹
- 1.2.2 观察 MNIST 数据基本情况
- 1.2.3 显示数据图像
- 2. 简单的神经网络
-
- 2.1 网络的基本结构
- 2.2 使用 PyTorch 实现网络架构
- 2.3 误差计算与参数更新
-
- 2.3.1 定义 `forward()` 函数
- 2.3.2 训练函数
- 2.4 训练可视化
- 2.5 MNIST 数据集类
- 2.6 分类器的训练
- 2.7 展示网络结果
- 2.8 网络的性能评判
1. MNIST 图像数据集
MNIST 数据集是著名的手写体数字的图像集合,常用来测量和比较机器学习算法的性能。该数据集包括了用于训练的 60,000 个图像和用于测试性能的 10,000 个图像。
数据集的图像是黑白的(每个像素点范围在 0 到 255 之间,),尺寸为 28*28 像素, 使用浅色或暗色像素来表示数字。
典型的 MNIST 数据集如下图所示。

1.1 下载 MNIST 数据并上传到 Google Colab
使用下面的链接下载 MNIST 数据:
- 训练数据:https://pjreddie.com/media/files/mnist_train.csv
- 测试数据:https://pjreddie.com/media/files/mnist_test.csv
如果仍在 Google Colab 中使用数据,那么下载完成这两个文件后,需要其上传到在线的 mnist_data 文件夹中:
1.2 观察 MNIST 数据
在数据处理前,首先直观地观察数据情况。
1.2.1 挂载 Google Drive 为文件夹
为了上传的 MNIST 数据能被 Google Colab 的代码获取,需要通过挂载 Google Drive 使其显示为一个文件夹。
感觉这也是 Google Colab 很方便的地方,可以很方便的加载数据。还记得在某国内的深度学习云平台上,为了上传数据,需要经过无比专业+复杂的过程,严重制约了平台的易用性。
新建一个 notebook 文件,运行如下代码:
# 挂载 Google Drive 来获取数据文件
from google.colab import drive
drive.mount('./mount')
通过点击显示的链接,询问确认账号并获取挂载 Google Drive 的权限,将获取的代码拷贝到 notebook 的 cell 中。
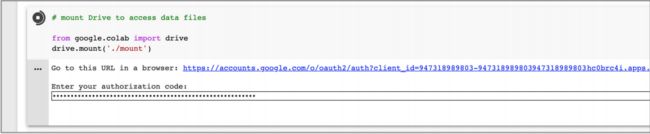
点击确认就提示 Google Drive 已经挂载完成,可以在 Python 代码中使用文件夹 ./mount 来访问数据。
1.2.2 观察 MNIST 数据基本情况
我们下载的 MNIST 文件为 逗号分隔值文件(Comma Separated Values,CSV) 格式,可以使用 pandas 库方便的读取并显示:
首先,导入 pandas 库并将 MNIST 数据载入到变量 df 中:
# 导入 pandas 库来读取 csv 文件
import pandas
# 载入 csv 文件(注意下面代码的地址要与文件的实际地址一致)
df = pandas.read_csv('mount/My Drive/Colab Notebooks/myo_gan/mnist_data/mnist_train.csv', header=None)
之后,使用 pandas 的 head() 函数来观察数据前五行内容:
# 观察 csv 数据的前五行
df.head()
结果如下所示:

MNIST 数据每行包括 785 个值,其中第一个值是图像代表的 “数字”,其他 784 个值是 28*28 图像的像素值,下面使用 info() 函数获得数据的概要:

上图说明该变量共有 60,000 行,也就是 60,000 个训练图像,每行共有 785 个 int64 的值。
1.2.3 显示数据图像
下面使用 matplotlib 库,通过将一行像素值转变为实际图像,进行数据可视化,代码为:
## 导入 matplotlib 库来进行图像可视化
import matplotlib.pyplot as plt
# 从 df 中获得数据,通过是设定 row = 0 来选择第一行数据
row = 0
data = df.iloc[row]
# 变量 data 中的第 1 个值是该行代表的数字,赋值为 label
label = data[0]
# 剩下的 784 个数值可以可视化为图像并显示
img = data[1: ].values.reshape(28, 28)
plt.title("label = " + str(label))
plt.imshow(img, interpolation='none', cmap='Blues')
plt.show()
显示的结果如下图:

上图是 MNIST 训练数据集的第一个图像,该图像是手写体的数字 5。
2. 简单的神经网络
2.1 网络的基本结构
首先写出识别 MNIST 手写数字的神经网络流程图:

该流程图起点是一个尺寸为 28*28 的 MNIST 图像,这意味着神经网络的第一层只能是 28*28=784 个节点。
最后一层的节点数量则与网络的功能紧密相关,比如这个网络是为了回答 “这是哪个数字?” 的问题,而这个问题共有 0 - 9 等 10 中可能,所以最后一层最简单的方法就是设置 10 个节点。
隐藏的中间层有更多的选择,这里直接使用 Make Your Own Neural Network 中的知识,选择尺寸为 200。
这里的网络的特点是,每层所有的节点都连接到下一层的每个节点,所以称之为 全连接层(fully connected layers)。
上图缺少了一个关键的东西,也就是 激活函数(activation function),应用于隐藏和输出层的输出。Make Your Own Neural Network 使用了 s型 logistic 函数:

这就做好了将神经网络 架构(architecture) 迁移到 PyTorch 代码的准备,编程时需要遵循 PyTorch 的编程模式。
2.2 使用 PyTorch 实现网络架构
首先,创建一个继承自从 PyTorch torch.nn 的神经网络类(class),这个类包 括了 Pytorch 的自动构建计算图、计算权重,并在训练时更新权重等机制。
首先导入 torch 和 torch.nn:
# 导入相关的库
import torch
import torch.nn as nn
下面的代码定义一个 Classfier 类,继承自 nn.Module 模块:
class Classifier(nn.Module):
def __init__(self):
# 初始化 Pytorch 的父类
super().__init__()
- 上面的代码中,
__init__(self)函数是一个特殊函数,该函数常用来创建对象并使之做好准备,称之为 构造函数(constructor)。 这里设置的super().__init__(),看起来很神秘,但实际上可以简单称之为父类(parent class)的构造函数,所以 PyTorch 的nn.Module将为我们创建属于自己的Classifier。- 个人感觉,如果对 Python 代码不够熟悉,建议可以采用模仿的方式编写代码。
下面来定义神经网络的架构。PyTorch 提供了几种不同的方法来完成该项工作, 对于简单网络可以使用 nn.Sequential() 来提供网络组成部分的清单,该清单必 须按照顺序提供:
class Classifier(nn.Module):
def __init__(self):
# 初始化 Pytorch 的父类
super().__init__()
# 定义神经网络的各层架构
self.model = nn.Sequential(
nn.Linear(784, 200),
nn.Sigmoid(),
nn.Linear(200, 10),
nn.Sigmoid()
)
可以看到在
nn.Sequential()中定义的不同元素:
nn.Linear(784, 200)是从 784 个节点到 200 个节点的全连接映射。这个元素包括了不同节点连接的权重,将在训练中被更新;nn.Sigmoid()在前一个元素的输出端应用 s-型 logistic 激活函数,该案例中为 200 个节点。nn.Linear(200,10)将 200 个节点映射为 10 个节点。这包括了在中间隐藏层和 10 个输出节点的最后一层的连接的权重。nn.Sigmoid()对 10 个节点的输出应用 s-型 logistic 激活函数。该结果是网络的最终输出。
之所以 nn.Linear 使用 “线性(Linear)” 的表述,是因为它对输入到输出的值应用了一个形式为 A x + B Ax + B Ax+B 的线性函数。其中 A A A 为连接权重, B B B 可以认为是偏置。所有的这些参数都在训练时被更新,有些人称之为可学习参数(learnable
parameters)。
2.3 误差计算与参数更新
有很多的方法来定义网络的误差,而且 PyTorch 也提供了很多预置函数。 其中最简单的一个是 均方误差(Mean Squared Error),PyTorch 提供了均方误差的计算函数 torch.nn.MSELoss() 。可以在构造函数中使用这个误差函数:
# 创建损失函数
self.loss_function = nn.MSELoss()
代码中可以使用 error 或 loss 的表述,这通常没有差别。如果深究一些,error 是在预期输出和实际输出的简单差别,而 loss 是对 error 进行二次计算的结果。
使用 error 函数(或者 loss 函数)来更新网络的连接权重,PyTorch 也提供了一些常见的函数,比如下面使用的称之为 **随机梯度下降(Stochastic Gradient Descent,SGD)**的简单函数,学习率为 0.01。
# 使用随机梯度下降函数来创建优化器
self.optimiser = torch.optim.SGD(self.parameters(), lr=0.01)
代码中,使用了 PyTorch 的 self.parameters() 函数将所有的可
学习参数传递到 SGD 优化器,使得所有的参数都可获得。
2.3.1 定义 forward() 函数
为了通过网络传递信息,需要采用 forward() 函数。下面很简单的
代码可以创建一个 forward() 函数:
def forward(self, inputs):
# 简单的运行模型
return self.model(inputs)
上述代码简单获得输入并传递给使用
nn.Sequential()定义的self.model()模型中。模型的输出可以返回给任何调用forward()函数的地方。
上面定义的神经网络类应该类似下面代码:
class Classifier(nn.Module):
def __init__(self):
# 初始化 PyTorch 父类
super().__init__()
# 定义神经网络各层结构
self.model = nn.Sequential(
nn.Linear(784, 200),
nn.Sigmoid(),
nn.Linear(200, 10),
nn.Sigmoid()
)
# 定义损失函数
self.loss_function = nn.MSELoss()
# 使用 SGD 函数创建优化器
self.optimiser = torch.optim.SGD(self.parameters(), lr=0.01)
pass
def forward(self, inputs):
# 简单的运行模型
return self.model(inputs)
简单总结一下已经创建的内容:
- 创建了一个继承自
nn.Module的神经网络类,这可以提供训练神经网络的更多机制。- 通过信息流定义了神经网络的元素。对很简洁的网络,可以直接使用了
nn.Sequential方法。- 定义了 损失(loss) 函数和 优化器(optimiser) 来更新网络的 可学习参数(learnable parameters)。
- 最后,增加一个
forward()函数,用于通过网络传递信息。
2.3.2 训练函数
为了保证代码的简洁性和一致性,在 forward() 函数旁边创建 train() 函数。 train() 函数需要网络的输入,也需要预期的 目标(target) 输出来与实际输
出进行比较来计算 损失(loss)。
def train(self, inputs, targets):
# 使用 forward() 计算网络的输出
outputs = self.forward(inputs)
# 计算损失值 loss
loss = self.loss_function(outputs, targets)
- 上述代码中,
train()函数做的第一件事就是使用forward()方法来通过网络传递输入来获得输出。- 使用之前定义的损失函数
loss_function()来计算损失值。由于 PyTorch 的应用,只需要为该函数提供网络的输出和预期的输出。
获得了 loss 值后,可以很简单的用之来更新网络的梯度:
# 使用反向(backward)操作来更新网络
self.optimiser.zero_grad()
loss.backward()
self.optimiser.step()
这三个步骤是几乎所有由 PyTorch 构建神经网络的关键模式,下面分步说明:
• 首先,使用optimiser.zero_grad()将计算图中的所有梯度均设为 0;
• 其次,使用loss.backward()计算损失函数,获得网络内部的梯度;
• 最后,通过self.optimiser.step()计算这些梯度,用于更新网络的可学习参数。
需要注意的是,每次训练网络时,都需要将梯度设置为 0,如果没有置 0 的话, 使用
loss.backward()计算梯度时均会将之前的梯度值累加。
优化器通过梯度,并通过逐步降低梯度更新可学习参数。但是在训练过程中,可以增加可视化的方法,观察训练的基本情况。