Make Your First GAN With PyTorch:2. 第一个 PyTorch 网络(下)
本章通过构建一个简单但常见的实际神经网络,来加深对 PyTorch 和神经网络的认识。
本章是 Make Your First GAN With PyTorch 的第 2 章(由于篇幅较长,分上下两篇发布,上篇详见链接),其他介绍详见这篇文章。
本文目录
- 1. MNIST 图像数据集
-
- 1.1 下载 MNIST 数据并上传到 Google Colab
- 1.2 观察 MNIST 数据
- 2. 简单的神经网络
-
- 2.1 网络的基本结构
- 2.2 使用 PyTorch 实现网络架构
- 2.3 误差计算与参数更新
- 2.4 训练可视化
- 2.5 MNIST 数据集类
-
- 2.5.1 定义相关类和函数
- 2.5.2 验证工作
- 2.6 分类器的训练
- 2.7 展示网络结果
- 2.8 网络的性能测试
1. MNIST 图像数据集
1.1 下载 MNIST 数据并上传到 Google Colab
1.2 观察 MNIST 数据
2. 简单的神经网络
2.1 网络的基本结构
2.2 使用 PyTorch 实现网络架构
2.3 误差计算与参数更新
2.4 训练可视化
一般而言,神经网络训练可能成千上万次,比如 MNIST 数据集有 60,000 个训练实例,所以一般是每 10 次训练保存一个 loss 值。
下面的代码创建了一个计数器 counter,初始值为 0,并在神经网络的构造函数中创建一个空的列表 progress:
# 初始化计数器和列表
self.counter = 0
self.progress = []
在 train() 函数内部,我们可以每次训练对 counter + 1,并每 10 次运行,将损失值增加到 progress 列表的末尾:
self.counter += 1
if (self.counter % 10 == 0):
self.progress.append(loss.item())
pass
上面代码中,
% 10表示被 10 除的余数,比如当counter值为 10、20、30 等数字时,计算结果为 0;
另外,loss.item()是指对单一值的张量展开,获得内部数字的函数。
之后,每 10000 次训练后,打印输出 counter:
if (self.counter % 10000 == 0):
print("counter = ", self.counter)
pass
下面的代码是为了使用图表显示损失值,增加的新函数 plot_progress():
def plot_progress(self):
df = pandas.DataFrame(self.progress, columns=['loss'])
df.plot(ylim=(0, 1.0), figsize=(16,8), alpha=0.1, marker='.', grid=True, yticks=(0, 0.25, 0.5))
pass
显示图表的函数实际上很简单,第 1 行是将损失值的列表
progress转化为一个 pandas dataframe,便于绘制图像。第 2 行的选项是plot()函数用于设定图像的设计和风格。
2.5 MNIST 数据集类
PyTorch 可以完成神经网络训练中所需的自动打乱数据、并行多进程载入数据、数据分批等功能。
2.5.1 定义相关类和函数
这里不使用打乱或者分批操作,直接导入 torch.utils.data.Dataset 类进行处理:
from torch.utils.data import Dataset
就像从 nn.Module 中继承一个神经网络类,并提供了一个 forward() 函数一样,对于继承自 Dataset 的数据集,可以提供下面两个特殊的函数:
__len__()返回数据集(dataset)的项目数。__getitem__()返回数据集的第 n 个项目。
观察下面的 MnistDataset 类:
class MnistDataset(Dataset):
def __init__(self, csv_file):
self.data_df = pandas.read_csv(csv_file, header=None)
pass
def __len__(self):
return len(self.data_df)
def __getitem__(self, index):
# 图像标签
label = self.data_df.iloc[index,0]
target = torch.zeros((10))
target[label] = 1.0
# 图上数据, 从 0-255 归一化到 0-1
image_values = torch.FloatTensor(self.data_df.iloc[index,1:].values)/ 255.0
# 返回图像标签、图像数据和目标
return label, image_values, target
pass
该类继承自 Dataset,解释一下上述代码:
- ① 当使用该类创建一个对象时,读取
csv_file到一个名称为data_df的 pandas dataframe 中;- ②
__len__()函数的作用是返回data_df变量的长度;- ③
__getitem__()函数,用于获取数据集中第index个项目的 标签(label);- ④ 这里也创建一个长度为 10 的张量
target来代表神经网络的预期输出。张量中,除了有 1 位根据标签设置为 1.0 外,其他位数字都是 0。比如数字 0 的对应一个类似[1,0,0,0,0,0,0,0,0,0]的张量,而数字 4 的对应的张量为[0,0,0,0,1,0,0,0,0,0],这称之为 独热编码(onehot encoding);- ⑤ 根据图像的像素值创建一个张量
image_values,该数字除以 255,使得范围为 0 到 1;- ⑥ 返回值是所有三个变量:
label,image_values和target。
为了便于观察数据集对应的图像,在 MnistDataset 类增加一个方法:
def plot_image(self, index):
arr = self.data_df.iloc[index,1:].values.reshape(28,28)
plt.title("label = " + str(self.data_df.iloc[index,0]))
plt.imshow(arr, interpolation='none', cmap='Blues')
pass
- 上述代码中,除了显示图像外,还增加了 label = xx 的文字,来说明图像实际代表的数字。
- 当然,由于用到了
matplotlib.pyplot库,所以要提前导入它:import matplotlib.pyplot as plt。
2.5.2 验证工作
下面来检查目前工作的内容。首先,通过传递 CSV 文件位置的方式,使用这个
类来创建一个数据集对象:
mnist_dataset = MnistDataset('mount/My Drive/Colab Notebooks/myo_gan/mnist_data/mnist_train.csv')
上面代码中,class 构造函数将 CSV 文件的数据载入到一个 pandas dataframe,之后可以使用 plot_image() 函数画出数据集的第 10 个图像:
mnist_dataset.plot_image(9)
第 10 个图像的索引值为 9,因为第一个图像的索引为 0。
输出为一个手写体的 4 的图像,标签也明确该图像为 4:
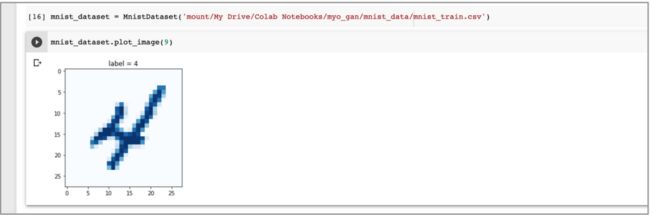
上图确认了定义的 dataset 类正确载入了数据。同时使用类似 mnist_dataset[100]的例子,确定这个类允许通过索引获取。可以看到它同时返回了label,像素值和 target 张量。
2.6 分类器的训练
相比设定数据集和神经网络类而言,训练一个分类器神经网络相对简单:
首先使用我们的 Classifier 类创建一个神经网络:
# 创建神经网络
C = Classifier()
网络的训练代码也非常简单:
# 使用 MNIST 数据集训练网络
for label, image_data_tensor, target_tensor in mnist_dataset:
C.train(image_data_tensor, target_tensor)
pass
由于 mnist_dataset 继承自 PyTorch 的 Dataset,因此可以使用简洁的 for 循环来对整个训练数据进行操作。对每个训练示例,只需要简单的将图像数据和目标张量传递到分类器的 train() 函数中即可。
同时,Python notebook 文件每个 cell 的运行计时很简单,只需要在计时的 cell 顶端简单增加一个 %%time 命令即可,可以用来估计神经 网络训练的时间:
%%time
# 创建神经网络
C = Classifier()
# 使用 MNIST 数据集训练网络
epochs = 3
for i in range(epochs):
print('training epoch', i + 1, "of", epochs)
for label, image_data_tensor, target_tensor in mnist_dataset:
C.train(image_data_tensor, target_tensor)
pass
psss
运行这个 cell 在每完成 10000 次调用后, train() 函数将打印已经完成的例子数量。
可以看到 3 个训练 epochs 使用了大约 4 分钟:

下面对训练中的损失值画图,获得训练进程的全貌:
# 画出损失值训练曲线
C.plot_progress()
运行完成后,可以看到类似下面的图表:

- 可以看到 损失(loss) 值快速下降到大约 0.1,然后由于训练原因,下降变慢且噪声更大了,逐渐趋近于 0。
- 损失值的下降表明网络分类图像正确性变得越来越好。
2.7 展示网络结果
训练完成后,使用 MNIST 的 10,000 个 测试数据集来测试这个网络。同样使用一个新的 Dataset 对象载入数据集:
# 载入 MNIST 测试数据
mnist_test_dataset = MnistDataset('mount/My Drive/Colab Notebooks/gan/mnist_data/mnist_test.csv')
选择测试数据集中一个数据来观察图像的样式,下面的代码选择了第 20 个数据, 索引数为 19:
# 选择索引数为 19
record = 19
# 展示图像并确认数字情况
mnist_test_datset.plot_image(record)
可以看到图像看起来像 4,数据的标签也确认确实是 4。

下面来看一下训练好的网络如何识别这个图像:
image_data = mnist_test_dataset[record][1]
# 使用 forward 函数,使得数据通过网络 C
output = C.forward(image_data)
# 显示输出张量
pandas.DataFrame(output.detach().numpy()).plot(kind='bar',legend=False, ylim=(0.1))
- 上面的代码的
record为 19 ,提取的图像像素值为image_data。之后使用forward()函数将图像通过神经网络。- 为了便于使用柱状图显示,上述代码首先将
output转换为一个更简单的 **numpy **数组,之后转换为 DataFrame 形式的变量。

上图的 10 个柱子是 10 个神经网络输出节点的值,其中最大的值对应了节点 4,表示 神经网络认为这个图像是一个数字 4。
如果更认真观察的话,可以看到其他节点的输出并不是 0。
这结果很正常,并不能期望分类神经网络会有一个十分明确的答案,实际上这次网络还认为这个图像也可能是数字 9。
2.8 网络的性能测试
查看神经网络正确分类图像的能力的一个简单方法,是对 MNIST 测试数据集所 有的 10,000 个图像进行操作,统计识别正确的个数。
下面的代码设定一个变量 score, 初始值为 0,然后对整个数据进行处理,如果每次网络输出是正确的,则增加 score 的值:
# 测试网络的性能
score = 0
items = 0
for label, image_data_tensor, target_tensor in mnist_test_dataset:
answer = C.forward(image_data_tensor).detach().numpy()
if (answer.argmax() == label):
score += 1
pass
item += 1
pass
print(scores, items, score/items)
上面第 8 行中,
answer.argmax()代码是找到张量answer最大值的索引值。如果第一个值最大,则argmax()的输出为 0。同时,如果网络的输出answer.argmax()与数据的标签label相同的话,则说明识别结果正确。
最后,输出 score 分数,使用分数来确定神经网络的性能:
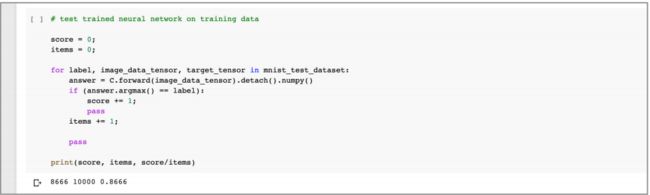
结果显示,获得了 87% 的分数,由于网络很简单,所以分数还不错。
同时可以尝试是否可以通过超过 3 次 epochs 的训练来改进这个分数;同时,如果你训练不够 3 次 epochs 将会发生什么呢?
可以在线探索这个简单的 MNIST 分类器代码:
- https://github.com/makeyourownneuralnetwork/gan/blob/master/02_mnist_data.ipynb