卷积生成对抗网络(Make Your First GAN With PyTorch 第9章)
- 本文是 Make Your First GAN With PyTorch 的第 9 章,本书的介绍详见这篇文章。
本文目录
- 1. GAN 的内存消耗情况
- 2. 卷积基本概念
-
- 2.1 卷积滤波器
- 2.2 特征的层次结构
- 3. MNIST 卷积神经网络
-
- 3.1 将网络修改为卷积网络
- 3.2 训练并对比网络
- 4. CelebA CNN
-
- 4.1 定义辅助函数
- 4.2 鉴别器网络
- 4.3 生成器网络
-
- 4.3.1 转置卷积
- 4.3.2 设计生成器网络
- 4.4 训练 GAN
- 4.5 进一步讨论
- 5. 要点总结
本文对上一章 CelebA GAN 进行改进,主要是 CelebA GAN 存在两个问题:
- CelebA GAN 生成的图像看起来很模糊,而我们期望的色彩比较平滑且对比度较高;
- CelebA GAN 使用的全连接网络消耗的内存很多,甚至稍大的图像或者网络将很快耗尽 GPU 的资源。
1. GAN 的内存消耗情况
在探索新的 GAN 技术前,先确认一下之前的 GAN 消耗的内存资源。
之前的 notebook 文件,鉴别器、生成器网络,以及输入的信息、输出数据以及可学习参数都是张量,会消耗内存。
使用以下代码检查当前分配了多少内存:
# 当前分配给张量的内存
torch.cuda.memory_allocated(device) / (1024 * 1024 * 1024)
- 代码中除以
1024 * 1024 * 1024,是为了将 bytes 转变为 GB。
结果如下:

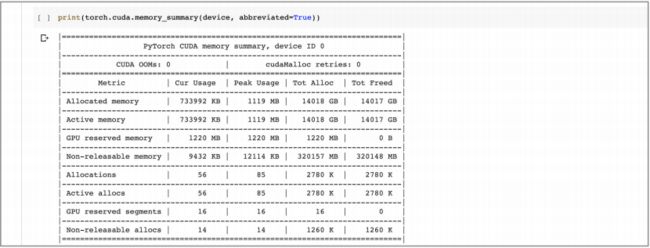
- 可以看到在整个 notebook 代码运行后,大约 0.70 GB 的内存分配给了张量。
- 这个数字并不是整个运行中所有的内存,因为在 GAN 代码运行之后,一些内存将被释放。
下面代码给出了在运行期间张量消耗的内存峰值:
# total memory allocated to tensors during program (in Gb)
torch.cuda.max_memeory_allocated(device) / (1024*1024*1024)
- 运行代码过程中张量使用的峰值内存略大于 1.09 GB。
也可以使用 print(torch.cuda.memory_summary(device, abbreviated=True)) 来获得内存的总体情况:
2. 卷积基本概念
机器学习的黄金法则是最大限度地利用试图解决的问题的任何知识。这个 “领域知识(domain knowledge)”,可以通过排除确定无效的可能性来减少问题的规模,使得可学习参数组合的可选空间更小了。
如果更深入的思考图像相关问题,可以意识到意义丰富的 特征(features) 是在集 中在图像的 局部(localised)。
举例而言,代表眼睛和鼻子的像素距离很近,这对图像分类为脸部很有用。如果能够应用这个局部特征,就可能通过应用临近像素组的信息,设计一个分类器神经网络。
之前的 MNIST 和 CelebA 分类器并没有考虑局部特征,而是考虑了整个图像的像素信息。这并没有错,事实证明,这些网络能使用图像的全部信息,对这些图像进行分类。但是,由于没有利用这些图像特征的局部信息,消耗的资源和分类的精度可能受限。
- 考虑局部信息常用的手段,就是 卷积。
2.1 卷积滤波器
观察下面 6×6 像素的 “人脸” 图像:

假设有一个 放大镜,仅仅能观察图像中任意的 4×4 像素的部分。我们可以 在图像上移动这个放大镜,给出上面提到的 局部(locality) 信息。
如果将 放大镜 移动过上面的人脸图像,并且对 放大镜 中 4×4 视野有多少个暗的像素进行计数,可以创建一个汇总了布局的信息新的网格。
下面的图像显示了这个过程1:
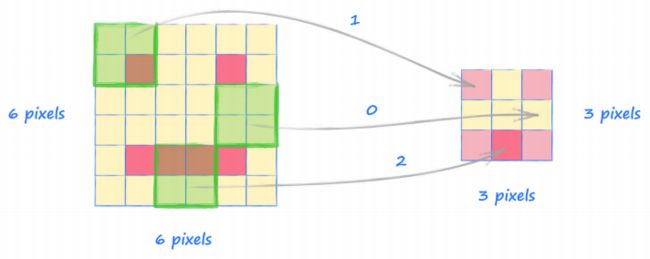
- 卷积结果的尺寸是 3×3,并且汇总了图像每个区域的信息。可以看到 放大镜 在图像的左上部和右上部发现了眼睛,在底部也发现了暗像素,特别是中间密度更高,同时它也发现了中间左侧和中间右侧并没有任何暗像素。
观察下面的图片,显示了将 放大镜 应用到一个略微不同脸部的过程:
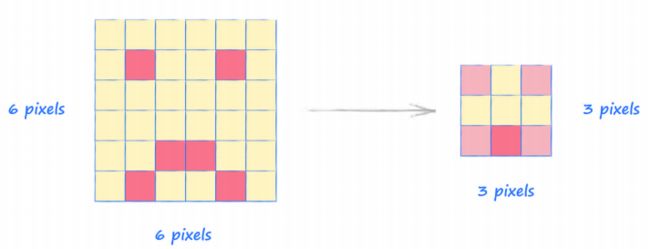
- 比较两个过程,发现不同脸,却有相同的结果。但这也说明 “放大镜” 的过程识别了图像的局部特征,而且对图像的微小变化不敏感。
移过一个图像并汇总它到一个新的网格中,称之为 卷积(convolution)。
- 卷积过程可以更复杂,比如,如果 放大镜 具有偏置,对某些像素赋予更高的分值,另一些像素给予更低的分值,就能够挑选出特别的模式。
下图给出对一种 放大镜,镜子具有偏置功能,通过对上面 2 个像素值乘以 1, 对上面的 2 个像素进行计数,通过下面 2 个像素乘以 0 来忽略下面 2 个像素,具体过程如下图:
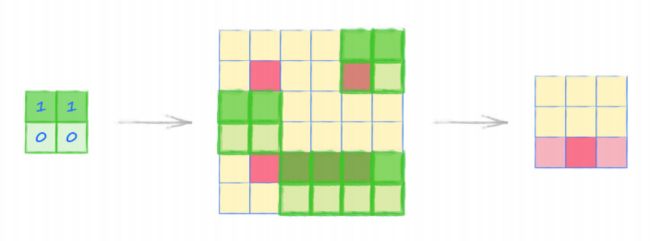
- “放大镜” 的学术名称,叫做 卷积核(convolution kernel)。
下面为两个不同的 卷积核 应用到同一个图像的结果:

- 上面两个卷积核,都使用了对角方向的偏置,上图可以看到不同的核挑选出了匹配它们各自方向的对角特征区域。
- 后面会写一篇文章,专门给出一些卷积的实例,进一步进行解释。
卷积有很多不同的核,那我们在使用时如何找到最优的核呢?
- 其实,没必要事前确定用哪个核,而是可以使用多个核(比如 20 个),然后将这些核的权重作为训练的参数进行训练,让神经网络自动选择哪个核更重要——进而给这些重要的核赋予更大的权重。
2.2 特征的层次结构
上面讨论的一层卷积核如何识别出低层特征,如边缘或斑点,进而提供汇总信息的网格(这个网格恰当的说法称为 特征映射(feature maps));
如果将另一层卷积核应用于这些特征映射,可以找到更高层次的特征,这些特征是一些低级特征的组合;更进一步,可以应用另一层卷积核来找到更高级的特征,这些特性是这些中级特征的组合…
下图是一个卷积层的层次结构,这些卷积层发现了低级、中级和高级特征,其中内核和特征图仅是示例:
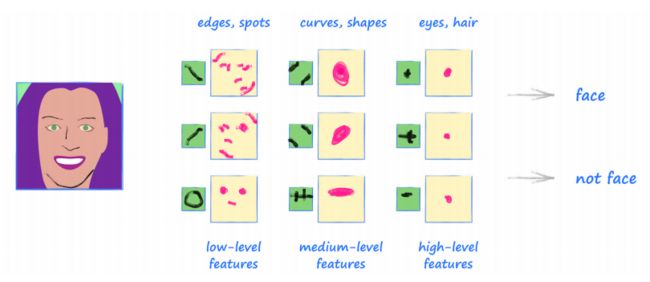
- 关于人类大脑如何理解眼睛所见的科学观点还没有定论,但是许多研究认为其机制与上述层次分析类似。
很明显,这种从中级特征构建图像内容的方法可以使图像分类的任务更加高效,事实上,卷积神经网络(convolutional neural networks, CNN) 在图像分类中一直是最先进的。
3. MNIST 卷积神经网络
为了更加熟悉神经网络中卷积的概念,在卷积 GAN 之前,先制作一个 MNIST 分类器。
使用之前的 MNIST 分类器,只需要改变分类器神经网络的定义,其他用于加载数据、查看图像、训练网络和检查分类性能的代码不需要做太多更改。
- 该神经网络有 784 个输入节点,全连接到 200 个节点的中间层,之后全连接到 10 个输出节点。中间层有一个
LeakReLU激活函数,之后进行了层归一化,而输出层只是应用了一个sigmoid激活函数。该网络在 MNIST 测试数据上达到了 97% 的准确率。
3.1 将网络修改为卷积网络
由于卷积只能作用于二维图像,而这里的输入是一个简单的一维像素值列表,因此先将传递到网络的 image_data_tensor 重塑为 (28, 28) 的形状。
- 实际上,我们需要的是一个 4 维张量,因为 PyTorch 的卷积过滤器要求数据张量有
(batch size, channels, height, width)等 4 个元素。- 而我们使用的
batch size为 1,MNIST 图像仅有 1 个通道,所以 MNIST 数据需要被格式化为(1, 1, 28, 28)。编程中,可以使用view()函数很容易地做到这一点。
观察下面的卷积神经网络代码:
self.model = nn.Sequential(
# 从 1 个输入通道,扩展到 10 个特征映射
nn.Conv2d(1, 10, kernel_size=5, stride=2),
nn.LeakReLU(0.02),
nn.BatchNorm2d(10),
# 10 个特征映射 到 10 个特征映射
nn.Conv2d(10, 10, kernel_size=3, stride=2),
nn.LeakyReLU(0.02),
nn.BatchNorm2d(10),
View(250),
nn.Linear(250, 10),
nn.Sigmoid()
)
上面神经网络的第一个元素是卷积层 nn.Conv2d,其第一个参数是输入通道数( MNIST 图像为 1),第二个参数是输出通道数(创建了 10 个卷积核,产生了 10 个特征映射)。
下一个参数 kernel_size 是核的尺寸( 5×5);最后一个参数 stride,是核移动的步长。
- 下面的图,使用步长为 2 和 1 的例子,展示了
stride不同的设置时的情况。注意到当stride为 1 时,核覆盖的区域有重叠,这是允许的。
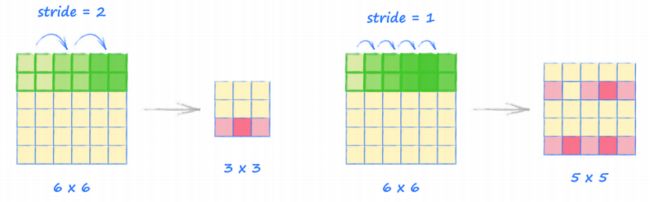
对于尺寸为 28*28 的 MNIST 图像,使用步长为 2 的 5×5 的核心,特 征映射尺寸为 12×12。
- 特征映射输出尺寸的计算公式为:
H o u t = ⌊ H i n + 2 × p a d d i n g − d i l a t i o n × ( k e r n e l _ s i z e − 1 ) − 1 s t r i d e + 1 ⌋ H_{out} = \lfloor \frac{H_{in} + 2 \times padding - dilation \times (kernel\_size - 1) - 1}{stride} + 1 \rfloor Hout=⌊strideHin+2×padding−dilation×(kernel_size−1)−1+1⌋- 其中, H o u t H_{out} Hout 和 H i n H_{in} Hin 分别是输出和输入的高度(宽度也类似),符号 ⌊ ∗ ⌋ \lfloor * \rfloor ⌊∗⌋ 指的是向下取整;而 p a d d i n g padding padding, d i l a t i o n dilation dilation 的定义可参考 PyTorch 的官方文档。
这里每层输出的非线性的激活函数,仍使用了 LeakReLU(0.02); 正规化操作则没有使用 LayerNorm(),而是使用了 BatchNorm2d()。
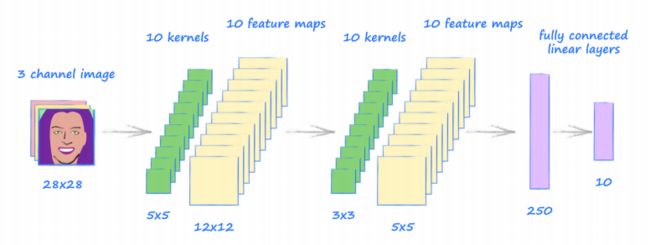
后面的代码类似,nn.Conv2d(10, 10, kernel_size=3, stride=2) 是对上面的 10 个特征映射进行卷积, 获得 10 个新的特征映射;使用的核尺寸为 3×3,步长为 2,输出的特征映射尺寸为 5×5。
网络最后部分是对 10 个特征映射进行处理,将其尺寸从 10×5×5=250 改变为 250 个值的一维向量(这里使用的 View() 函数定义见 这篇文章),并通过全连接映射到 10 个输出节点(对应 10 个数字),每个节点都有一个 sigmoid 激活函数。
下面是整个网络架构的示意图:
3.2 训练并对比网络
对网络进行训练,并使用 之前全连接 MNIST 分类器的方法测试其性能并进行对比。
第一个区别是 CNN 训练速度更快,大概只需 0.5 分钟,而全连接网络需要 13.5 分钟。
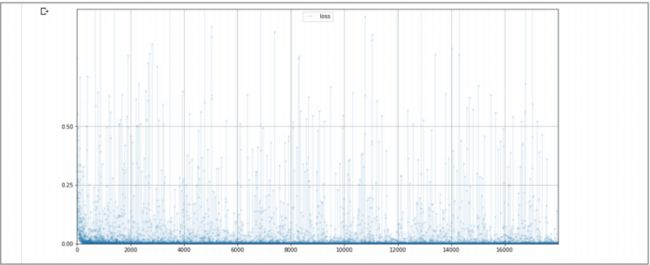
相同的地方是,CNN 的损失函数图表和全连接网络非常类似,损失函数很快下降到接近 0,并且保持在 0 附近。
使用 print(score, items, socre/items) 的代码,获取性能得分为 98%,比之前最好的性能 97% 还高。
- 分数可能看起来增加并不多,但对 MNIST 分类而言,超过 98% 的分数并不容易,这个 CNN 分类器,使用了很简单的设计和少量的代码就获得了 98% 的分数。
这部分的代码,可以参考下面的附件:
- https://github.com/makeyourownneuralnetwork/gan/blob/master/13_cnn_mnist.ipynb
4. CelebA CNN
下面,使用 CNN 创建一个 GAN,同样使用 之前的 CelebA GAN 的代码 进行修改。
4.1 定义辅助函数
- CelebA 图像尺寸为 217×178 ,为了保证卷积简单可行,我们将原始图像裁剪为 128×128 的尺寸。
下面定义了一个辅助函数 crop_centre,用于切割 numpy 数组的中心位置到给定的尺寸:
def crop_centre(img, new_width, new_height):
height, width, _ = img.shape
startx = width//2 - new_width//2
starty = height//2 - new_height//2
return img[starty:starty + new_height, startx:startx + new_width, :]
- 对图像
img裁剪,可以使用crop_centre(img, 128, 128)。
由于需要在 Dataset 类的定义中使用 crop_centre() 函数,需要将函数移动到 notebook 文件中 Dataset 类的上面。
下面的代码更新了 __getitem__() 和 plot_image() 的方法,使得在不同的情况下,都可以从 HDF5 数据集中提取一个图像并切割为 128×128 的正方形。
def __getitem__(self, index):
if (index >= len(self.dataset)):
raise IndexError()
img = numpy.array(self.dataset[str(index)+'.jpg'])
# crop to 128*128 square
img = crop_centre(img, 128, 128)
return torch.cuda.FloatTesor(img).permute(2,0,1).view(1,3,128,128) / 255.0
def plot_image(self, index):
img = numpy.array(self.dataset[str(index)+'.jpg'])
# crop to 128*128 square
img = crop_centre(img, 128, 128)
plt.imshow(img, interpolation='nearest')
pass
- 上文中
__getitem__()需要返回的张量为(batch size, channels, height, width)形式的四维张量;由于读取的是形式为(height, width, 3)的三维numpy数组,所以现在需要使用permute(2, 0, 1)将数组的形式调整为(3, height, width),并使用view(1, 3, 128, 128)增加额外的一个batch size维度,并设置为 1。
可以看到运行后,图像确实被切割为较小的 128×128 的正方形:

4.2 鉴别器网络
设计 CNN 各层时,需要计算每层的输入和输出,这就需要按照上面提到的根据卷积核、步长等进行计算每一层的大小。
- 那么,网络需要多少层呢?中间层需要多少核心呢?这个问题并没有明确答案,我们应当试着构建最简单的网络开始…
先考虑鉴别器,下面这个网络,有 3 个卷积层,再加上最后一个全连接层:

- 网络的第一个卷积层,输入的是 3 通道彩色图像,并且使用 256 个卷积核获得 256 个特征映射。由于核心尺寸为 8×8 且步长为 2,所以特征映射尺寸为 61×61,小于输入图像 的 128×128 ;
- 下一个卷积层也一样,具有 256 个尺寸为 8×8 步长为 2 的卷积核,获得 256 个特征映射,尺寸缩减为 27×27;
- 到网络的最后需要考虑约简数据。下一个卷积层仅有 3 个核心,但是尺寸仍然是 8×8,步长仍是 2,这提供了 3 个尺寸为 10×10 的特征映射;
- 这 300 个值(3×10×10)需要约简为一个单独的鉴别器输出值,由于 300 已经足够小,可以简单使用全连接层来输出为一个值。
- 上面讨论很多,但是一次结合图示,应该可以较为简单的理解。
下面是鉴别器的代码:
self.model = nn.Sequential(
# 输入的尺寸为 (1,3,128,128)
nn.Conv2d(3, 256, kernel_size=8, stride=2),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
nn.Conv2d(256, 256, kernel_size=8, stride=2),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
nn.Conv2d(256, 3, kernel_size=8, stride=2),
nn.LeakyReLU(0.2),
View(3*10*10),
nn.Linear(3*10*10, 1),
nn.Sigmoid()
)
代码并不需要过多的解释,前面文章基本解释过了。
- 值得注意的是,代码中使用 了
View()来将最后的特征映射的尺寸(1, 3, 10, 10)重塑为简单的尺寸为 300 的一维张量,便于输入到线性层。
使用随机图像测试鉴别器,更新代码使 generate_random_image() 生成预期尺寸为 (1, 3, 128, 128) 的四维张量。
D.train(generate_random_image((1, 3, 128, 128)), torch.cuda.FloatTensor([0.0]))
训练循环大约需要 10 分钟,下面的图表显示了训练中的损失值:
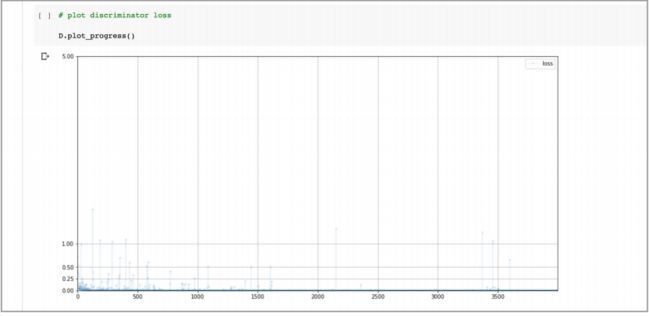
可以看到损失值很快下降到接近 0,同时噪声很小,仅有很少的跳到更高的值上,而跳到更高值的情况却在之前的网络中非常常见。
4.3 生成器网络
首先考虑将鉴别器的镜像作为生成器设计的基准,这样不会出现两者一强一弱的情况。
- 那么,卷积操作的镜像是什么呢?
4.3.1 转置卷积
卷积是将较大的张量约简为较小的张量,那么卷积的相反步骤是需要将较小的张量扩展到较大的张量。PyTorch 称这个相反的步骤为 转置卷积(transposed convolution),函数模块为 nn.ConvTranspose2d 。
下面展示了转置卷积的操作过程:
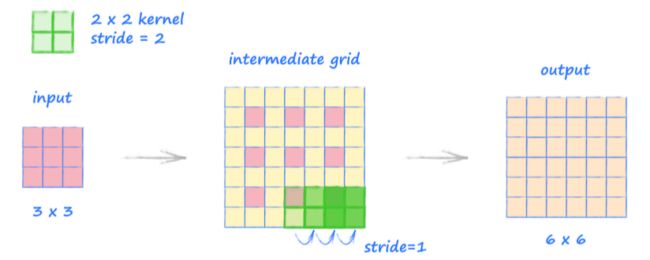
- 上图中,输入的张量尺寸为 3×3,核心的尺寸为 2×2,步长为 2。
- 转置卷积的工作方式是核心以 1(而不是 2 的步长)在中间网格上移动。其中,中间网格是在原始输入变量方格之间添加值为 0 的附加网格形成的。
- 为了获取中间网格,需要将原始值按步长(这里是 2)的大小分开,然后,在边的周围加上最大数量的 0 的值的方块,这样核仍然可以至少覆盖一个原来的方块。
- 最后图中显示输出张量的大小为 6×6。
- 这个展开方法看起来好像过于复杂,但这种方法的主要优点是,它消除了配置 了相同选项的正常卷积的效果。例如,如果使用输出的 6×6 张量,并对步长为 2 的 2×2 的核执行普通卷积,我们将再次得到 3×3 的张量。
- 当然,在一些特殊情况下,反转并不精确,需要额外的填充。我后面也会再写一篇文章,专门给出一些实例,进一步进行解释。
4.3.2 设计生成器网络
下面的图片显示了一个卷积网络结构,它以大小为 100 的种子最终生成一个形
状为 (1, 3, 128, 128) 的张量:
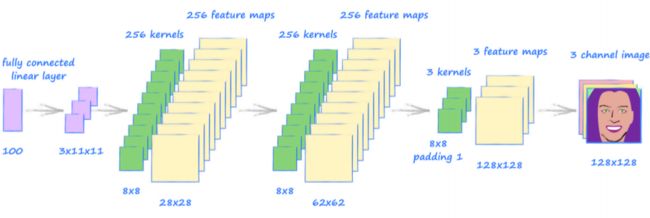
- 网络以一个全连接网络开始,可以将 100 个种子值映射为 3×11×11,然后可以将形状重塑为需要的四维张量
(1, 3, 11, 11),进而作为转置卷积的输入。 - 下面是转置卷积层,最后一层需要一个额外的值为 1 的参数
padding,如果没有这个参数,将很难获得尺寸为(1, 3, 128, 128)的输出。
- 当然,为了省事,可以通过在最后增加一个全连接层来获得需要的输出尺寸,用来降低卷积生成器网络的设计难度。
- 但是,如果可以直接由局部化特征来构建图像的话,应当避免使用全连接层。
下面是生成器网络的代码:
self.model = nn.Sequential(
# 输入为一维的数据
nn.Linear(100, 3*11*11),
nn.LeakyReLU(0.2),
# 将输入数据重塑为思维的数据
View((1, 3, 11, 11))
nn.ConvTranspose2d(3, 256, kernel_size=8, stride=2),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
nn.ConvTranspose2d(256, 256, kernel_size=8, stride=2),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
nn.ConvTranspose2d(256, 3, kernel_size=8, stride=2, padding=1),
nn.BatchNorm2d(3),
nn.Sigmoid()
- 代码是按照之前画的示意图写的,有 3 个转置卷积,每个的核心尺寸为 8,步长为 2。其中前两层有 256 个核心, 并且最后一个约简为 3 个核心,因为输出张量需要有 3 个色彩通道。
经过检查,确定生成器网络确实可以生成尺寸正确的随机图像。
- 需要使用
permute(0, 2, 3, 1)和view(128, 128, 3)将生成器获得四维的张量重新排列,这样才能正确输出显示图像。

未经训练的生成器确实可以创建正确尺寸的图像,这个图像看起来是随机的像素值。但是如果仔细看它好像是 棋盘形 的模式,同时在图像的边缘还有一个暗色的 晕影(vignette)。
- 这是代码出现了错误?
- 其实并没有。当使用一系列转置卷积构建图像时,由于特征映射的重叠,特别是当步长不是核心尺寸的整数倍时,会产生棋盘的模式。同时图像边缘重叠较少,使得边界较暗。随着对生成器进行训练,可以补偿这个效应。
4.4 训练 GAN
在所有这些准备后,终于可以对 GAN 训练一个 epoch,而且并不需要改变任何训练循环代码。
- 训练的代码可以参考之前的文章。
下面看一下 生成器损失值(上) 和 鉴别器损失值(下):
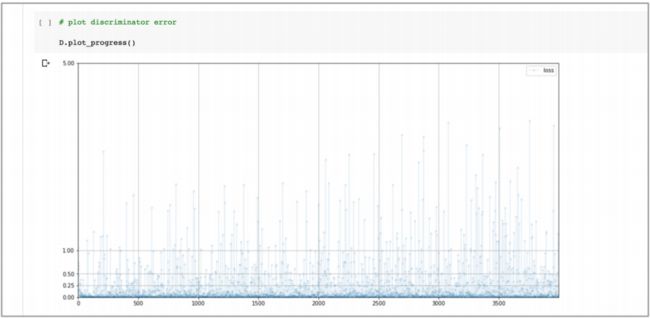
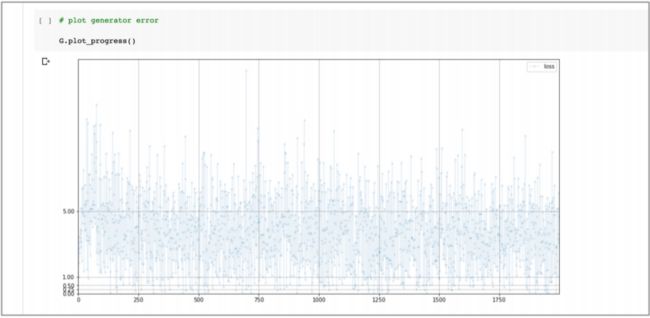
- 鉴别器每个 epoch 训练大概需要 15 分钟,而且鉴别器损失值非常迅速的下降接近 0, 并且保持低位。这比非常混沌不稳定的损失值要好,但是如果能接近理想值 0.693 将会更好。同时,有一些迹象显示损失值在训练过程的末段开始有所增加。
- 生成器的损失值也不混乱,这很不错。虽然损失值比理想值要高一些,但是它 在缓慢下降中,或者需要更长的训练?
观察一个 epoch 的训练后生成器产生的图像:

不错,卷积 GAN 已经产生了脸部的基本特征,包括了两个眼睛、一个鼻子、 一个嘴和很多图像里的头发。
- 图像的质量不是很高,但是这里取得的成绩值得思考。这些图像是卷积神经网络通过高、中和低层次的局部特征产生的,同时,这些特征并不是拷贝自训练数据,而诸如眼睛在鼻子之上、鼻子在嘴巴之上的布局,是通过鉴别器学习获得的。
- 同样注意到,我们非常幸运,或者说很聪明,因为好像网络已经避免了模式坍塌,生成的图像很多样化。
下面,检查一下这个卷积 GAN 的内存消耗情况,来确定是不是比开始时的全连接 GAN 更低。
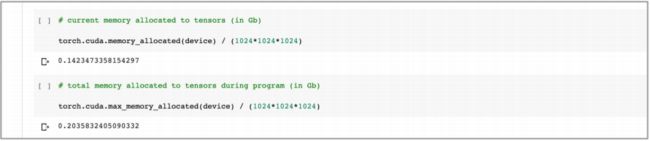
文件完整运行后分配给张量的内存为 0.14 GB,这主要是仍然存在的鉴别器和生成器对象。
- 考虑到全连接 GAN 的值为 0.70 GB,说明卷积网络是全连接内存的五分之一。
下面看一下多次训练能否改进图像,观察训练 1, 2, 3, 4, 6, 8 个 epoch 的图像,这些图像放在一起,便于比较图像质量。

刚开始时图像质量并不好,但随着训练,脸部开始变得越来越好,一些脸看起来有更加真实的光滑的皮肤。
同样网络还避免了模式坍塌,并且脸部和姿势角度的多样性令人鼓舞。
- 当然,并不是每个图像都很好,现在并不清楚更长的训练能不能修复这种情况,有可能这个简单的网络架构有其内在的限制。
进一步观察这些图像,确实看起来像将一些局部碎片放在一起的。
举例而言,能看到某张脸一个眼睛可能与另一个眼睛不同,或者头发两边的发型也不相同,在全连接 GAN 中,这种现象不多见。
- 这是因为卷积网络中,每一个特征并不是前一层产生的图像全貌所产生的。所以卷积方法,在有意缩小的关注点在有很大优势的同时,也有一些不足。
刚才开发的代码在下面链接可得:
- https://github.com/makeyourownneuralnetwork/gan/blob/master/14_gan_cnn_celeba.ipynb
4.5 进一步讨论
下面可以有意识地尝试用我们自己的想法来改进 GAN。
- 我们可以尝试不同种类的损耗函数,不同大小的神经网络,甚至可能是标准训练循环的变体;也可以尝试通过在损失函数中包含多个输出多样性的措施来阻止模式坍塌;如果足够自信,也可以尝试实现自己的优化器,使得更适合 GAN 的对抗性。
下面是我自己的一个简单的实验,使用了一个叫做 GELU 的激活函数,它和 ReLU 有点类似,但是有一个更柔和的角。

- 有人认为这种激活函数现在是最先进的,因为它们提供了良好的梯度,并且在原点周围没有明显的不连续性。
下图由类似上面例子生成,只是将 nn.LeakReLU(0.2) 换为了 nn.GELU():

看起来使用 GELU 激活函数可以轻微地增加图像质量,下面的图像是更多的 10 和 12 个 epoch 的训练的结果:

在这些图像中,真实感真的变得令人印象深刻,进一步的训练可以进一步提高图像质量。
这里的代码在下面链接可得:
- https://github.com/makeyourownneuralnetwork/gan/blob/master/15_gan_cnn_celeba_refinements.ipynb
5. 要点总结
- 目前最先进的图像分类网络利用了以下理论:有意义的图像特征是 局部化(localised) 的,可识别的对象由低级细节特征的 层次结构(hierarchy) 组成,这些低级细节特征组合形成中等级别的特征,它们本身组合形成高级特征级对象;
- 卷积(Convolutions) 在图像上应用 内核(kernel) 来输出 特征映射(feature maps)。特定的内核可以识别出图像中特定的局部模式;
- 神经网络中的卷积层可以学习好的核函数来完成给定的任务。也就是说,网络知道哪些图像特征最有用,而不需要我们直接设计这些特征。使用卷积层的神经网络通常比等效的全连接网络在图像分类方面表现更好;
- 在卷积减少数据的情况下,等效配置的 转置卷积(transposed convolution) 会逆转这种减少,使其成为生成网络的理想选择;
- 基于卷积网络的 GAN 通过将低层特征合成为中层特征,再由中层特征组成高层特征来构造图像。实验表明,它们产生的图像质量比等效的全连接的 GAN 高;
- 卷积 GAN 比全连接的 GAN 需要更少的内存。这可能是在 GPU 内存限制下处理大中型图像时的一个考虑因素,比如本文中例子内存消耗减少了 5 倍。
- 卷积生成器的一个缺点是,它们会导致由不匹配元素组成的图像,例如,具有不同颜色眼睛的人脸。这是因为通过一个卷积网络的信息流被有意地局部化,而全局关系并没有被学习。
个人注:这个图疑似有问题,图中并不是 4×4 的 放大镜,而应该是一个 2×2 的 放大镜,同时 放大镜 的移动是 “跳动” 的 (也就是步长为 2)。我后面会写一篇专门解释卷积的文章,用例子来说明。 ↩︎