2022.7.31 第十七次周报
目录
一、Intorduction of Meta Learning
1.What is Meta Learning?
2.Meta learning
step1
step2
step3
3.framework
4.ML V.S. Meta
目标Goal
训练资料Training Data
Loss
二、What is learnable in a learning algorithm
1.Review:Gradient Descent
2.Learning to initialize
Model-Agnostic Meta-Learning(MAML)
Reptile
3.How to train your MAML
MAML
Pre-training(Self-supervised Learning/more typical ways)
4.Optimizer
5.Network Architecture Search(NAS)
6.Data Augmentation
7.Sample Reweighting
8.Beyond Gradient Descent
三、Applications
1.Few-shot Image Classification
2.Omniglot
一、Intorduction of Meta Learning
1.What is Meta Learning?
meta learning = learn to learn
元学习其实就是阐释训练模型的一种算法。
元学习是通过一系列task的训练,让机器成为一个更好的学习者,当机器遇到新的学习任务时,就能更快的完成。类比到现实生活中,元学习不是指某一类的知识内容,更像是学习一种学习方法。
Meta learning指的是找到产生f的函数F,向F输入训练数据,可以产生满足需求的f。

2.Meta learning
step1
寻找方法:要学的参数是Φ。之前这些component都是人定的,元学习里是求这些component。

step2
计算Loss:以往的机器学习是通过计算训练资料得出Loss,而元学习是通过训练任务里的测试资料计算。

step3
最优化使Loss最小。

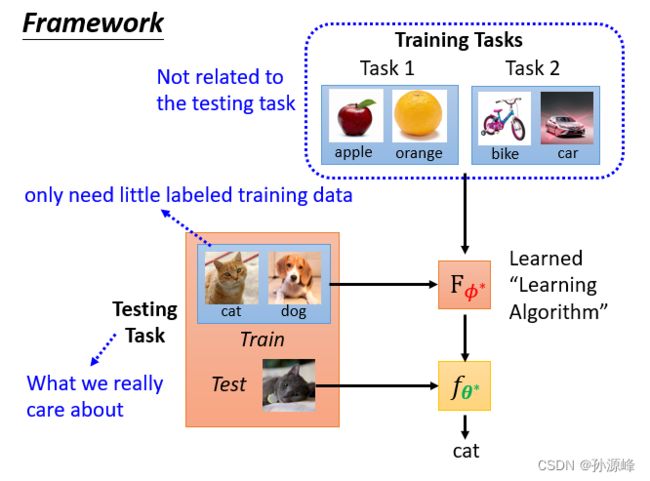
3.framework
注意这里是测试任务里的训练资料也作为输入,通过F方法,学习出classify,然后把这个classify用到测试任务里的测试资料上,得到结果。
训练任务是为了找出最优算法,测试任务是为了最终结果。
4.ML V.S. Meta
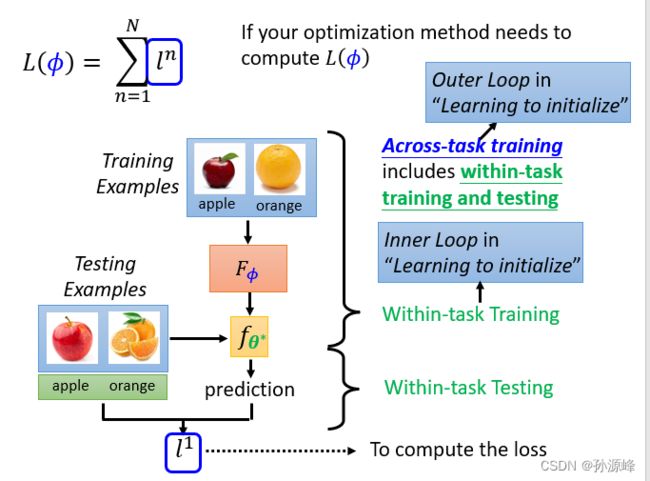
目标Goal
机器学习是找到f方法。
元学习的目的是找到可以“寻到f方法”的F方法。

训练资料Training Data
support set是训练资料,query set是测试资料。
机器学习是任务内训练,元学习是跨任务学习。

Loss
within-task training又叫inner loop。
acros-task training又叫outer loop。
二、What is learnable in a learning algorithm
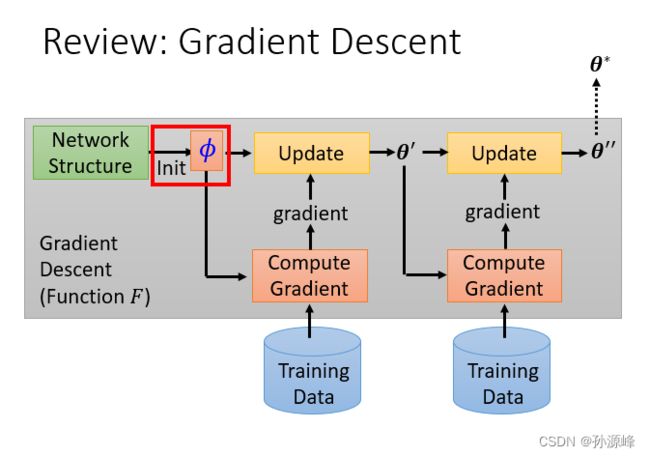
1.Review:Gradient Descent
2.Learning to initialize
我们能不能透过一些训练的任务来找出一个对训练特别有帮助的初始化参数?
下面介绍两个方法
Model-Agnostic Meta-Learning(MAML)

Reptile

3.How to train your MAML
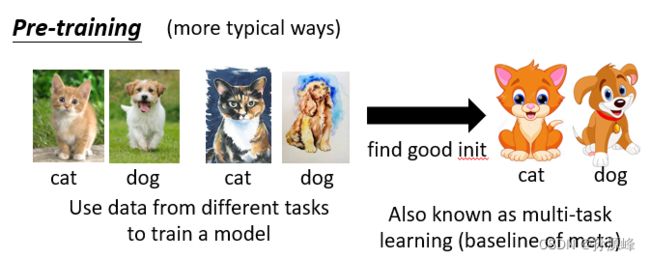
MAML和Pre-train最明显的不同是MAML用到了标注资料,而Pre-train没有。
MAML

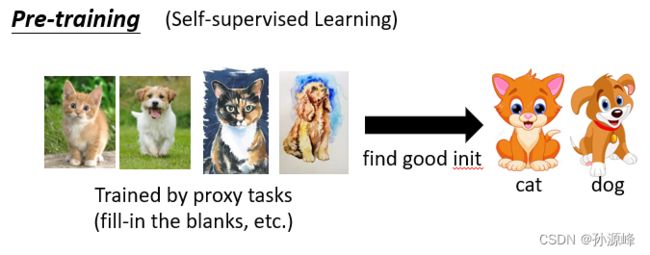
Pre-training(Self-supervised Learning/more typical ways)
4.Optimizer
我们还可以学习optimizer。

5.Network Architecture Search(NAS)
我们还可以训练network 架构,那这系列的研究就叫做NAS。

6.Data Augmentation
除了network architecture还有什么可以learn的呢?Data processing 也有可能可以learn。我们在训练network 的时候也要做Data Augmentation。下面给出一些文章能让machine自动找data augmentation。

7.Sample Reweighting
我们知道在training的时候,有时候要给不同的sample不同的weight。

8.Beyond Gradient Descent
我们之前看到的方法都是基于梯度下降法再去做的。我们有没有可能直接舍弃Gradient Descent。

三、Applications
1.Few-shot Image Classification
这是最常用来测试mate learning 的任务。
N种方式K-shot分类:在每个任务中,有N个类,每个类都有K个示例。
在元学习中,您需要准备许多N-way K-shot任务作为训练和测试任务。

2.Omniglot
可以制造N-way K-shot classification。
将角色拆分为训练和测试角色
样本 N 训练字符,每个采样字符的样本 K 示例→一个训练任务
示例 N 个测试字符,每个采样字符的样本 K 示例→一个测试任务
