黑马程序员最新Python教程——第一阶段(2)
黑马程序员最新Python教程——第一阶段(2)
- 第一阶段——第五章
-
- 01-函数的初体验
- 02-函数的基本定义语法
- 03-函数的基本定义练习案例
- 04-函数的传入参数
- 05-函数的参数练习案例
- 06-函数的返回值定义语法
- 07-函数返回值之None类型
- 08-函数的说明文档
- 09-函数的嵌套调用
- 10-变量在函数中的作用域
- 11-函数综合案例
- 第一阶段——第六章
-
- 01-数据容器入门
- 02-列表的定义语法
- 03-列表的下标索引
- 04-列表的常用操作方法
- 05-列表的常用操作方法课后练习
- 06-列表的循环遍历
- 07-元组的定义和操作
- 08-字符串的定义和操作
- 09-字符串的定义和操作课后练习
- 10-数据容器(序列)的切片
- 11-序列切片课后练习讲解
- 12-集合的定义和操作
- 13-集合的课后练习
- 14-字典的定义
- 15-字典的常用操作
- 16-字典课后练习讲解
- 17-五类数据容器的总结对比
- 18-数据容器的通用操作
- 19-拓展字符串大小比较方式
- 第一阶段——第七章
-
- 01-函数的多返回值
- 02-函数的多种参数使用形式
- 03-函数作为参数传递
- 04-lambda匿名函数
第一阶段——第五章
这是这个笔记的第二篇,第一篇为黑马程序员最新Python教程——第一阶段(1)欢迎大家批评指正。
01-函数的初体验
函数:是组织好的,可重复使用的,用来实现特定功能的代码段。

我们前面使用的是print()、input()、str()等都是Python内置函数。
一个小案例:查找字符串长度
if __name__ == '__main__':
str1 = "abcdefd"
str2 = "sdfghnsfjdl"
str3 = "sdgnker"
count_1 = 0
count_2 = 0
count_3 = 0
for s in str1:
count_1 +=1
count_2 = len(str2)
print(f"count_1 = {count_1}")
print(f"count_2 = {count_2}")
"""
count_1 = 7
count_2 = 11
"""
利用函数:(不懂咋写的没关系 后面讲)
if __name__ == '__main__':
str1 = "abcdefd"
str2 = "sdfghnsfjdl"
str3 = "sdgnker"
def my_len(data):
count = 0
for s in data:
count += 1
print(f"字符串{data}的长度 = {count}")
my_len(str1)
my_len(str2)
my_len(str3)
"""
字符串abcdefd的长度 = 7
字符串sdfghnsfjdl的长度 = 11
字符串sdgnker的长度 = 7
"""
为什么要学习、使用函数呢?
为了得到一个针对特定需求、可供重复利用的代码段提高程序的复用性,减少重复性代码,提高开发效率。
02-函数的基本定义语法
函数的定义:
def 函数名 (传入参数):
函数体
return 返回值 #其中传入参数与返回值可以没有
函数的调用:
函数名 ()
函数名(传入参数)
a = 函数名()
a = 函数名(传入参数)
03-函数的基本定义练习案例
案例说明:
定义一个函数,函数名任意,要求调用函数后可以输出如下欢迎语:
欢迎来到黑马程序员!
请出示您的健康码以及72小时核酸证明!
if __name__ == '__main__':
def check():
print("欢迎来到黑马程序员!\n请出示您的健康码以及72小时核酸证明!")
check()
04-函数的传入参数
if __name__ == '__main__':
def add(x, y):#xy 是形式参数 参数任意多
result = x + y
print(f"{x} + {y}的结果是: {result}")
add(3,5)#3,5是实际参数
if __name__ == '__main__':
def add(x, y , z):
result = x + y + z
print(f"{x} + {y} + {z}的结果是: {result}")
add(3,4,5)
05-函数的参数练习案例
案例说明:
定义一个函数,名称任意,并接受一个参数传入(数字类型,表示体温)在函数内进行体温判断(正常范围:小于等于37.5度),并输出如下内容:
欢迎来到黑马程序员!请出示您的健康码以及72小时核酸证明,并配合测量体温!
体温测量中,您的体温是: 37.3度,体温正常请进!
欢迎来到黑马程序员!请出示您的健康码以及72小时核酸证明,并配合测量体温!
体温测量中,您的体温是: 39.3度,需要隔离!
if __name__ == '__main__':
# 定义函数,接收1个形式参数,数字类型,表示体温
def check(num):
# 在函数体内进行判断体温
print("欢迎来到黑马程序员!请出示您的健康码以及72小时核酸证明,并配合测量体温! ")
if num <= 37.5:
print(f"体温测量中,您的体温是: {num}度, 体温正常请进! ")
else:
print(f"体温测量中,您的体温是: {num}度, 需要隔离! ")
check(37.0)
check(350.0)
"""
欢迎来到黑马程序员!请出示您的健康码以及72小时核酸证明,并配合测量体温!
体温测量中,您的体温是: 37.0度, 体温正常请进!
欢迎来到黑马程序员!请出示您的健康码以及72小时核酸证明,并配合测量体温!
体温测量中,您的体温是: 350.0度, 需要隔离!
"""
06-函数的返回值定义语法
if __name__ == '__main__':
def add(a,b):
result = a + b
return result
r = add(1,2)
print(r)
"""
定义两数相加的函数功能。完成功能后,会将相加的结果返回给函数调用者
所以,变量r接收到了函数的执行结果
"""
综上所述:所谓**"返回值”,就是程序中函数完成事情后,最后给调用者的结果**
07-函数返回值之None类型
思考:如果函数没有使用return语句返回数据,那么函数有返回值吗?
实际上是:有的。
Python中有一个特殊的字面量: None, 其类型是:
无返回值的函数,实际上就是返回了: None这个字面量
if __name__ == '__main__':
def add(a,b):
result = a + b
r = add(1,2)
print(type(r))#None作为一个特殊的字面量,用于表示:空、无意义,其有非常多的应用场景。
- 用在函数无返回值上
- 用在if判断上
在if判断中,None等同于False,一般用于在函数中主动返回None,配合if判断做相关处理
if __name__ == '__main__':
# 主动返回None的函数
def say_hi2():
print("你好呀")
return None
result = say_hi2()
print(f"无返回值函数,返回的内容是: {result}")
print(f"无返回值函数,返回的内容类型是: {type(result)}")
# None用于if判断
def check_age(age):
if age > 18:
return " SUCCESS"
else:
return None
result=check_age(16)
if not result:
# 进入if表示result是None值也就是False
print("未成年,不可以进入")
"""
你好呀
无返回值函数,返回的内容是: None
无返回值函数,返回的内容类型是:
未成年,不可以进入
"""
- 用于声明无内容的变量上
定义变量,但暂时不需要变量有具体值,可以用None来代替
if __name__ == '__main__':
name = None
08-函数的说明文档
函数是纯代码语言,想要理解其含义,就需要一行行的去阅读理解代码,效率比较低。
我们可以给函数添加说明文档,辅助理解函数的作用。
语法如下:
if __name__ == '__main__':
# 主动返回None的函数
def add(x,y):
"""
add函数可以接收2个参数,进行2数相加的功能
:param x:形参x 表示相加的其中一个数字
:param y:形参y 表示相加的另一个数字
:return:返回值是2 数相加的结果
"""
result =x+y
print(f"和为{result}")
return result
Pycharm的自动补充功能,写好函数体,在函数提前加上“”“ “””回车 自动补齐
通过多行注释的形式,对函数进行说明解释——内容应写在函数体之前
在PyCharm编写代码时,可以通过鼠标悬停,查看调用函数的说明文档

09-函数的嵌套调用
if __name__ == '__main__':
# 定义函数func_ _b
def func_b():
print("---2---")
# 定义函数func_ a,并在内部调用func_ b
def func_a():
print("---1---")
# 嵌套调用func_ .b .
func_b()
print("---3---")
# 调用函数func_ a
func_a()
"""
---1---
---2---
---3---
"""
如果函数A中,调用另外一个函数B,那么先把函数B中的任务都执行完毕之后才会回到上次 函数A执行的位置
10-变量在函数中的作用域
变量作用域指的是变量的作用范围(变量在哪里可用,在哪里不可用)
主要分为两类:局部变量和全局变量
局部变量的作用:在函数体内部,临沭存储数据 调用完之后 立即消失(前面讨论if for while 中定义的变量时 外部可以访问 但是不推荐那样用 函数 是出错 不可以外面调用局部变量)。
if __name__ == '__main__':
def testA():
num = 100
print(num)
testA() # 100
print(num)# 报错: name 'num is not defined'
全局变量:指的是在函数体内、外都能生效的变量。
if __name__ == '__main__':
num = 100
def testA():
print(num)
testA() # 100
print(num)# 100
但是在函数内部书写global关键字 就是全局变量了
if __name__ == '__main__':
num = 100
def testA():
num = 200
print(num)
testA() # 200
print(num)# 100
if __name__ == '__main__':
num = 100
def testA():
global num
num = 200
print(num)
testA() # 200
print(num)# 200
11-函数综合案例
要求说明:

if __name__ == '__main__':
def menu():
print('---------------主菜单---------------')
print('周杰轮,您好,欢迎来到黑马银行ATM。请选择操作:')
print('查询余额\t[输出1]')
print('存款\t\t[输出2]')
print('取款\t\t[输出3]')
print('退出\t\t[输出4]')
def yuehcaxun():
print('---------------查询余额---------------')
print('周杰轮,您好,您的余额: ',yue,' 元')
def cunkuan(num):
print('---------------存款---------------')
print('周杰轮,您好,您存款 ', num, ' 元成功')
print('周杰轮,您好,您的余额: ', yue+num, ' 元')
def qukuan1(num):
print('---------------取款---------------')
print('周杰轮,您好,您取款 ', num, ' 元成功')
print('周杰轮,您好,您的余额: ', yue-num, ' 元')
def qukuan2():
print('---------------取款---------------')
print('周杰轮,您好,您的余额不足')
def tuichu():
print('---------------退出---------------')
print('拜拜')
yue = 10000
menu()
while True:
a = int(input("请输入你的选择:"))
if a == 1:
yuehcaxun()
elif a == 2:
num = int(input("请输入你要存的金额:"))
cunkuan(num)
yue += num
elif a == 3:
num = int(input("请输入你要取的金额:"))
if(num>yue):
qukuan2()
else:
qukuan1(num)
yue -= num
elif a == 4:
tuichu()
break
else:
print("请输入正确的指示!")
第一阶段——第六章
01-数据容器入门
为什么学习数据容器呢?
思考:如果我想要在程序中,记录5个同学的信息姓名。如何去做?
if __name__ == '__main__':
name1 = "wang"
name2 = "liu"
name3 = "yang"
name4 = "zhang"
name5 = "li"
太繁琐!!!低效!我们引入列表数据容器,一个变量记录多份数据
if __name__ == '__main__':
name_list = ['wang','liu','yang','zhang','li']
print(name_list)
"""
['wang', 'liu', 'yang', 'zhang', 'li']
"""
Python中的数据容器:
一种可以容纳多份数据的数据类型,容纳的每一份数据称之为1个元素每一个元素,可以是任意类型的数据,如字符串、数字、布尔等。
数据容器根据特点的不同,如:
- 是否支持重复元素
- 是否可以修改
- 是否有序,等
分为5类,分别是:列表(list) 、元组(tuple) 、字符串(str) 、集合(set) 、字典(dict)
'''
# 文本类型:str(字符串)
# 数字类型: int(整数),float(浮点数),complex(复数)
# 序列类型:list(列表)[],tuple(元组)(),range(范围),dic(字典)
# 套装类型:set(集合),frozenset(冻结集)
# 布尔类型:bool
# 二进制类型:bytes,bytearray,memoryview
'''
02-列表的定义语法
思考:有一个人的姓名(TOM)怎么在程序中存储?
答:字符串变量
思考:如果一个班级100位学生,每个人的姓名都要存储,应该如何书写程序?声明100个变量吗?
答:No,我们使用列表就可以了,列表一次可以存储多个数据
列表(list) 类型,是数据容器的一类,我们来详细学习它。
#字面量
[元素1,元素2,元素3...]
#定义变量
变量名称 = [元素1,元素2,元素3...]
#定义空列表
变量名称 = []
变量名称 = list()
- 列表内的每一个数据,称之为元素
- 以[ ]作为标识
- 列表内每一个元素之间用,逗号隔开
注意:列表可以存储一次存储多个数据,切可以为不同的数据类型,支持嵌套
if __name__ == '__main__':
my_list = ["itheima", "itcast", "python"]
print(my_list)
print(type(my_list))
my_list = [" itheima",666,True]
print(my_list)
print(type(my_list))
'''
['itheima', 'itcast', 'python']
[' itheima', 666, True]
'''
if __name__ == '__main__':
# 定义一个嵌套的列表
my_list = [[1, 2, 3],[4, 5, 6]]
print(my_list)
print(type(my_list))
'''
[[1, 2, 3], [4, 5, 6]]
'''
03-列表的下标索引

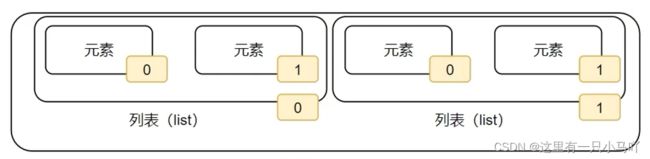
如图,列表中的每一个元素,都有其位置下标索引,从前向后的方向,从0开始,依次递增
我们只需要按照下标索引,即可取得对应位置的元素。
if __name__ == '__main__':
# 定义一个嵌套的列表
my_list = [[1, 2, 3],[4, 5, 6]]
print(my_list[0])
print(my_list[1])
print(my_list[0][0])
'''
[1, 2, 3]
[4, 5, 6]
1
'''

if __name__ == '__main__':
# 定义一个嵌套的列表
my_list = [[1, 2, 3],[4, 5, 6]]
print(my_list[-1])
print(my_list[-2])
print(my_list[0][-1])
'''
[4, 5, 6]
[1, 2, 3]
3
'''
嵌套列表的下标索引
04-列表的常用操作方法
列表除了定义、使用下标索引,以外也提供了一系列功能:插入元素、删除元素、清空元素、修改元素、统计元素个数等等功能,我们成为列表的方法
- 列表的查询功能
函数是一个封装的代码单元,可以提供特定功能。在python中,如果将函数定义为class(类)的成员,那么函数会称为:方法
# 函数
def add(x,y):
return x + y
#方法
class Student:
def add(self,x,y):
return x + y
方法和函数功能一样,有传入参数,有返回值,只是方法的使用格式不同:
函数的使用:num= add(1,2)
方法的使用:student = Student() num = student.add(1,2)
查找某元素的下标
功能:查找指定元素在列表的下标,如果找不到,报错ValueError
语法:列表.index(元素)
index就是列表对象(变量)内置的方法(函数)
if __name__ == '__main__':
my_list = [" itheima", 666, True]
print(my_list.index(" itheima"))
my_list = [[1, 2, 3], [4, 5, 6]]
print(my_list.index(1)) #报错!!!
print(my_list.index([1, 2, 3])) # 0
- 列表的修改功能(方法)
修改特定位置(索引)的元素值:
语法:列表[下标]=值
可以使用如上语法,直接对指定下标(正向、反向下标均可)的值进行:重新赋值(修改)
if __name__ == '__main__':
# 正向下标
my_list = [1,2,3]
my_list[0] = 5
print(my_list) # 结果: [5,2,3]
# 反向下标
my_list = [1,2,3]
my_list[-3] = 5
print(my_list) # 结果: [5,2, 3]
- 插入元素:
语法:列表.insert(下标,元素),在指定的下标位置,插入指定的元素
if __name__ == '__main__':
my_list = [1,2,3]
my_list.insert(1,"itheima")
print(my_list)
'''
[1, 'itheima', 2, 3]
'''
- 追加元素:
语法:列表.append(元素),在指定元素,追加到列表的尾部
if __name__ == '__main__':
my_list = [1,2,3]
print(my_list)
my_list.append("4")
print(my_list)
# 结果:
'''
[1, 2, 3]
[1, 2, 3, '4']
'''
extend用法
if __name__ == '__main__':
my_list = [1,2,3]
my_list.extend([4,5,6])
print(my_list)
# 结果:
'''
[1, 2, 3, 4, 5, 6]
'''
if __name__ == '__main__':
my_list = ["1,2,3"]
my_list.extend(["4,5,6"])
print(my_list)
my_list.extend("4")
print(my_list)
- 删除元素:
语法:del 列表[下标],列表.pop(下标)
if __name__ == '__main__':
my_list = [1,2,3]
print(my_list)
del my_list[1]
print(my_list)
my_list.pop(1)
print(my_list)
# 结果:
'''
[1, 2, 3]
[1, 3]
[1]
'''
语法:列表.remove(元素)
if __name__ == '__main__':
my_list = [1,2,3]
print(my_list)
my_list.remove(2)
print(my_list)
my_list.remove(2)#报错
print(my_list)
# 结果:
'''
[1, 2, 3]
[1, 3]
'''
- 清空列表:
语法:列表.clear()
if __name__ == '__main__':
my_list = [1,2,3]
print(my_list)
my_list.clear()
print(my_list)
# 结果:
'''
[1, 2, 3]
[]
'''
- 统计某个元素个数:
语法:列表.count(元素)
if __name__ == '__main__':
my_list = [1,2,3,3,3,3,5]
print(my_list)
count = my_list.count(3)
print(count)
# 结果:
'''
[1, 2, 3, 3, 3, 3, 5]
4
'''
- 统计全部元素个数:
语法:len(列表)
if __name__ == '__main__':
my_list = [1,2,3,3,3,3,5]
print(my_list)
count = len(my_list)
print(count)
# 结果:
'''
[1, 2, 3, 3, 3, 3, 5]
7
'''

经过上述对列表的学习,可以总结出列表有如下特点:
●可以容纳多个元素(上限为2**63+1、9223372036854775807个)
●可以容纳不同类型的元素(混装)
●数据是有序存储的 (有下标序号)
●允许重复数据存在
●可以修改(增加或删除元素等)
05-列表的常用操作方法课后练习
需求说明:
有一个列表,内容是: [21, 25, 21, 23, 22, 20],记录的是一批学生 的年龄
请通过列表的功能(方法),对其进行
1.定义这个列表,并用变量接收它
2.追加一个数字31,到列表的尾部
3.追加一个新列表[29, 33, 30], 到列表的尾部
4. 取出第一个元素(应是: 21)
5.取出最后一个元素(应是: 30)
6. 查找元素31,在列表中的下标位置
if __name__ == '__main__':
my_list = [21,25,21,23,22,20]
print(my_list)
my_list.append(31);
print(my_list)
my_list.extend([29,33,30])
print(my_list)
del my_list[0]
print(my_list)
del my_list[-1]
print(my_list)
a= my_list.index(31)
print(a)
# 结果:
'''
[21, 25, 21, 23, 22, 20]
[21, 25, 21, 23, 22, 20, 31]
[21, 25, 21, 23, 22, 20, 31, 29, 33, 30]
[25, 21, 23, 22, 20, 31, 29, 33, 30]
[25, 21, 23, 22, 20, 31, 29, 33]
5
'''
06-列表的循环遍历
while循环
定义一个变量表示下标,从0开始
循环条件:下标值 < 列表的元素数量
if __name__ == '__main__':
my_list = [21,25,21,23,22,20]
index = 0
while index < len(my_list):
my_list[index] +=1
index +=1
print(my_list) #[22, 26, 22, 24, 23, 21]
'''
index = 0
while index
for循环
表示,从容器内,依次取出元素并赋值到临时变量上。
在每一次的循环中,我们可以对临时变量(元素)进行处理。
if __name__ == '__main__':
my_list = [21,25,21,23,22,20]
index = 0
for a in my_list:
print(a+1 ,end=" ")#22 26 22 24 23 21
print()
print(my_list) #[21, 25, 21, 23, 22, 20]
'''
for 临时变量 in 数据容器:
对临时变量进行处理
'''
while与for的对比
while循环和for循环,都是循环语句,但细节不同:
-
在循环控制上:
●while循环可以自定循环条件,并自行控制
●for循环不可以自定循环条件,只可以一个个从容器内取出数据 -
在无限循环上:
●while循环可以通过条件控制做到无限循环
●for循环理论上不可以,因为被遍历的容器容量不是无限的 -
在使用场景上:
●while循环适用于任何想要循环的场景
●for循环适用于,遍历数据容器的场景或简单的固定次数循环场景
07-元组的定义和操作
为什么要引入元组?
思考列表的痛点,他可以被修改,我们有时候需要我自己封装的程序数据不被修改,那么我们就引入了元组——一旦完成定义,就不可以修改。他同样可以储存不同类型元素。

if __name__ == '__main__':
# 定义元组
t1 = (1,"Hello",True)
t2 = ()
t3 = tuple()
print(f"t1的类型是: {type(t1)}, 内容是: {t1}")
print(f"t2的类型是: {type(t2)}, 内容是: {t2}")
print(f"t3的类型是: {type(t3)}, 内容是: {t3}")
'''
t1的类型是: , 内容是: (1, 'Hello', True)
t2的类型是: , 内容是: ()
t3的类型是: , 内容是: ()
'''
但是定义单个变量时!!!!一个元素后面加上,
if __name__ == '__main__':
# 定义元组
t1 = ("Hello",)
t2 = ("Hello")
print(f"t1的类型是: {type(t1)}, 内容是: {t1}")
print(f"t2的类型是: {type(t2)}, 内容是: {t2}")
'''
t1的类型是: , 内容是: ('Hello',)
t2的类型是: , 内容是: Hello
'''
同样元组可以嵌套使用
if __name__ == '__main__':
# 元组的嵌套
t5 = ((1, 2, 3),(4, 5,6))
print(f"t5的类型是: {type(t5)}, 内容是: {t5}")
'''
t5的类型是: , 内容是: ((1, 2, 3), (4, 5, 6))
'''

if __name__ == '__main__':
# 元组支持下标索引
t5 = ((1, 2, 3),(4, 5,6))
num = t5[1][2]
print(f"t5的取出的内容是: {num}") #6
# 根据index(),查找特定元素的第一个匹配项
t1 = (1,2,'hello', 3,4,'hello')
print(t1.index('hello')) # 结果:2
# 统计某个数据在元组内出现的次数
t1 = (1,2,'hello',3,4,'hello')
print(t1.count('hello')) # 结果: 2
# 统计元组内的元素个数
t1 = (1,2,3)
print(len(t1)) # 结果3
元组的遍历
if __name__ == '__main__':
t1 = ("h",1,4.2,True)
index = 0
while index < len(t1):
print(f"元组的元素有: {t1[index]}")
# 至关重要
index += 1
# 元组的遍历: for
for eLement in t1:
print(f"2元组的元素有: {eLement}")
如果尝试修改tuple中的数据:
错误提示:TypeError: ' tuple 'object does not support item assignment
但是如果你元组中嵌套了一个list,它就可以改list里面的东西
if __name__ == '__main__':
# 尝试修改元组内容
t1 = (1,2,['itheima', 'itcast'])
t1[2][1] = ' best'
print(t1)# 结果:(1, 2, ['itheima', ' best'])
08-字符串的定义和操作
尽管字符串看起来并不像:列表、元组那样,一看就是存放了许多数据的容器。
但不可否认的是,字符串同样也是数据容器的一员。
字符串是字符的容器,一个字符串可以存放任意数量的字符。

和其它容器如:列表、元组一样,字符串也可以通过下标进行访问
●从前向后,下标从0开始
●从后向前,下标从-1开始
- 字符串的下标(索引)
if __name__ == '__main__':
# 尝试修改元组内容
t1 = "(1,2,['itheima', 'itcast'])"
print(t1[2])#,
print(t1.index("h"))#9
- 字符串无法修改
所以:
●修改指定下标的字符(如:字符串[0]=“a" )
●移除特定下标的字符(如: del 字符串[0]、字符串.remove()、字符串.pop()等)
●追加字符等(如:字符串.append())
都是无法完成的,除非重新定义另一个字符串才可以
错误:TypeError: 'str' object does not support item assignment - 字符串的替换
语法:字符串.replace(字符串1,字符串2)
功能:将字符串内的全部:字符串1,替换为字符串2
注意:不是修改字符串本身,而是得到了一个新字符串哦
if __name__ == '__main__':
# 尝试修改元组内容
t1 = "(1,2,['itheima', 'itcast'])"
t2 = t1.replace(',',"34345")
print(t2) #(134345234345['itheima'34345 'itcast'])
- 字符串的分割
语法:字符串.split(分隔符字符串)
功能:按照指定的分隔符字符串,将字符串划分为多个字符串,并存入列表对象中
注意:字符串本身不变,而是得到了一个列表对象
if __name__ == '__main__':
# 尝试修改元组内容
t1 = "(1,2,['itheima', 'itcast'])"
t2 = t1.split(',')
print(t2) #['(1', '2', "['itheima'", " 'itcast'])"]
- 字符串的规整操作
 6. 字符串的元素个数
6. 字符串的元素个数
if __name__ == '__main__':
my_str = "itheima and itcast"
count = my_str.count("it")
print(f"字符串{my_str}中it出现的次数是: {count}")
'''
字符串itheima and itcast中it出现的次数是: 2)
'''
- 字符串的长度
if __name__ == '__main__':
my_str = "itheima and itcast"
a = len(my_str)
print(a)#18
09-字符串的定义和操作课后练习

if __name__ == '__main__':
my_str = "itheima itcast boxuegu"
my_str_count = my_str.count("it")
my_str_replace = my_str.replace(" ",'|')
my_str_split = my_str_replace.split("|")
print(my_str)
print(my_str_count)
print(my_str_replace)
print(my_str_split)
'''
2
itheima|itcast|boxuegu
['itheima', 'itcast', 'boxuegu']
'''
10-数据容器(序列)的切片
序列是指:内容连续、有序,可使用下标索引的一类数据容器
列表、元组、字符串,均可以可以视为序列。

切片操作不会影响序列本身
if __name__ == '__main__':
# 对list进行切片,从1开始,4结束,步长1
my_list = [0, 1,2, 3,4, 5,6]
result1 = my_list[1:4]
# 步长默认是1,所以可以省略不写
print(f"结果1: {result1}")
# 对tuple进行切片,从头开始,到最后结束,步长1
my_tuple = (0,1, 2,3, 4,5,6)
result2 = my_tuple[:]
# 起始和结束不写表示从头到尾,步长为1可以省略
print(f"结果2: {result2}")
# 对str进行切片,从头开始,到最后结束,步长2
my_str = "01234567"
result3 = my_str[::2]
print(f"结果3: {result3}")
# 对str进行切片,从头开始,到最后结束,步长-1
my_str = "01234567"
result4 = my_str[::-1]
# 等同于将序列反转了
print(f"结果4: {result4}")
# 对列表进行切片,从3开始,到1结束,步长-1
my_list = [0,1, 2, 3, 4, 5, 6]
result5 = my_list[3:1:-1]
print(f"结果5: {result5}")
# 对元组进行切片,从头开始,到尾结束,步长-2
my_tupLe = (0,1, 2, 3, 4,5,6)
result6 = my_tupLe[::-2]
print(f"结果6: {result6}")
'''
结果1: [1, 2, 3]
结果2: (0, 1, 2, 3, 4, 5, 6)
结果3: 0246
结果4: 76543210
结果5: [3, 2]
结果6: (6, 4, 2, 0)
'''
11-序列切片课后练习讲解
案例说明:
有字符串: “万过薪月,员序程马黑来,nohtyP学”
请使用学过的任何方式,得到黑马程序员
if __name__ == '__main__':
my_str = "万过薪月,员序程马黑来,nohtyP学"
my_list = my_str.split(',')
a = my_list[1]
b = a[::-1]
c = b.replace("来", " ")
d = c.strip()
print(d)
12-集合的定义和操作
**为什么有引入了集合呢?**我们目前接触到了列表、元组、字符串三个数据容器了。基本满足大多数的使用场景。为何又需要学习新的集合类型呢?
通过特性来分析:
●列表可修改、支持重复元素且有序
●元组、字符串不可修改、支持重复元素且有序
局限就在于:它们都支持重复元素。
如果场景需要对内容做去重处理,列表、元组、字符串就不方便了。而集合,最主要的特点就是:不支持重复(自带去重功能)、并且内容无序
if __name__ == '__main__':
# 定义集合
my_set = {"传智教育","黑马程序员", "itheima", "传智教育","黑马程序员","itheima", "传智教育","黑马程序员","itheima"}
my_set_empty = set()
# 定义空集合
print(f"my_ set的内容是: {my_set}, 类型是: {type(my_set)}")
print(f"my_ set. _empty的内容是: {my_set_empty}, 类型是: {type(my_set_empty)}")
'''
my_ set的内容是: {'itheima', '黑马程序员', '传智教育'}, 类型是:
顺序无序、所以不支持下标索引访问 但是他可以修改!!!!!
my_ set. _empty的内容是: set(), 类型是:
'''
- 添加新元素
if __name__ == '__main__':
# 定义集合
my_set = {"传智教育","黑马程序员", "itheima", "传智教育","黑马程序员","itheima", "传智教育","黑马程序员","itheima"}
print(my_set)
#{'传智教育', 'itheima', '黑马程序员'}
my_set.add("Python")
print(my_set)
#{'黑马程序员', 'Python', '传智教育', 'itheima'}
- 移除元素
if __name__ == '__main__':
# 定义集合
my_set = {"传智教育","黑马程序员", "itheima", "传智教育","黑马程序员","itheima", "传智教育","黑马程序员","itheima"}
print(my_set)
#{'传智教育', 'itheima', '黑马程序员'}
my_set.remove("itheima")
print(my_set)
#{'黑马程序员', '传智教育'}
- 随机移除元素
if __name__ == '__main__':
# 定义集合
my_set = {"传智教育","黑马程序员", "itheima", "传智教育","黑马程序员","itheima", "传智教育","黑马程序员","itheima"}
print(my_set)
#{'传智教育', 'itheima', '黑马程序员'}
a = my_set.pop()
print(a)
#黑马程序员
print(my_set)
#{'黑马程序员', '传智教育'}
- 清空元素
if __name__ == '__main__':
# 定义集合
my_set = {"传智教育","黑马程序员", "itheima", "传智教育","黑马程序员","itheima", "传智教育","黑马程序员","itheima"}
print(my_set)
#{'传智教育', 'itheima', '黑马程序员'}
a = my_set.clear()
print(a)
print(my_set)
# None
# set()
- 取俩个集合的差集
if __name__ == '__main__':
set1 = {1,2,3}
set2 = {1, 5,6}
set3 = set1.difference(set2)
print(set3) # 结果:{2,3} 得到的新集合
print(set1) # 结果:{1,2,3}不变
print(set2) # 结果:{1, 5,6}不变
- 消除2个集合的差集
if __name__ == '__main__':
set1 = {1,2,3}
set2 = {1,5,6}
set1.difference_update(set2)
print(set1)
# 结果:{2,3}
print(set2)
# 结果:{1,5,6}
- 2个集合合并
语法:集合1.union(集合2)
功能:将集合1和集合2组合成新集合
结果:得到新集合,集合1和集合2不变
if __name__ == '__main__':
set1 = {1,2,3}
set2 = {1,5,6}
set3 = set1.union(set2)
print(set3)
# 结果:{1,2,3,5,6},新集合
print(set1)
# 结果:{1,2,3},set1不变
print(set2)
# 结果:{1,5,6},set2不变
- 集合长度
if __name__ == '__main__':
set1 = {1,2,3}
set2 = {1,5,6}
set3 = set1.union(set2)
print(set3)
# 结果:{1,2,3,5,6},新集合
print(len(set3))#5
- 集合的遍历
因为集合不能用于索引下标,所以只能用for循环进行遍历,while循环不可以使用哦
if __name__ == '__main__':
set1 = {1, 2,3,4,5}
for eLement in set1:
print(f"集合的元素有: {eLement}")

13-集合的课后练习
需求说明:
有如下列表对象:
my_list= [‘黑马程序员’, ‘传智播客’, ‘黑马程序员’, ‘传智播客’, ‘itheima’, ‘itcast’, ‘itheima’, ‘itcast’,‘best’]请:
●定义一个空集合
● 通过for循环遍历列表
● 在for循环中将列表的元素添加至集合
● 最终得到元素去重后的集合对象,并打印输出
if __name__ == '__main__':
my_list= ['黑马程序员', '传智播客', '黑马程序员', '传智播客', 'itheima', 'itcast', 'itheima', 'itcast','best']
my_set = set() #千万不要记成my_set={} 集合没有这个用法
for index in my_list:
my_set.add(index)
print(my_set)
'''
{'黑马程序员', 'itheima', '传智播客', 'itcast', 'best'}
'''
14-字典的定义


可以使用字典,实现用Key取出Value的操作
字典的含义:同样使用{},不过存储的元素是一个个的:键值对,如下语法:
if __name__ == '__main__':
my_dict1 = { "k1":99,"k2":75 ,"k3":75}
my_dict2 ={}
my_dict3 = dict()
print(f"字典1的内容是: {my_dict1},类型: {type(my_dict1)}")
print(f"字典2的内容是: {my_dict2},类型: {type(my_dict2)}")
print(f"字典3的内容是: {my_dict3},类型: {type(my_dict3)}")
'''
字典1的内容是: {'k1': 99, 'k2': 75, 'k3': 75},类型:
字典2的内容是: {},类型:
字典3的内容是: {},类型:
'''
当key重复时,第二个会把第一个会被覆盖掉
if __name__ == '__main__':
my_dict1 = { "k1":99,"k2":75 ,"k3":75,"k1":77}
print(f"字典1的内容是: {my_dict1},类型: {type(my_dict1)}")
'''
字典1的内容是: {'k1': 77, 'k2': 75, 'k3': 75},类型:
'''
字典的Key和Value可以是任意数据类型(Key不可为字典)
那么,就表明,字典是可以嵌套的
需求如下:记录学生各科的考试信息
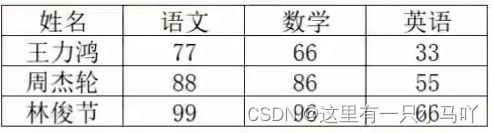
字典可以嵌套
if __name__ == '__main__':
my_dict1 = { "k1": {"语文":77,"数学":66,"英语":33},
"k2":{"语文":88,"数学":66,"英语":33} ,
"k3":{"语文":99,"数学":66,"英语":33}}
print(f"字典1的内容是: {my_dict1},类型: {type(my_dict1)}")
'''
字典1的内容是: {'k1': {'语文': 77, '数学': 66, '英语': 33}, 'k2': {'语文': 88, '数学': 66, '英语': 33}, 'k3': {'语文': 99, '数学': 66, '英语': 33}},类型:
'''
if __name__ == '__main__':
my_dict1 = { "k1": {"语文":77,"数学":66,"英语":33},
"k2":{"语文":88,"数学":66,"英语":33} ,
"k3":{"语文":99,"数学":66,"英语":33}}
print(f"字典1的内容是: {my_dict1},类型: {type(my_dict1)}")
score = my_dict1["k1"]["语文"]
print(score)
'''
字典1的内容是: {'k1': {'语文': 77, '数学': 66, '英语': 33}, 'k2': {'语文': 88, '数学': 66, '英语': 33}, 'k3': {'语文': 99, '数学': 66, '英语': 33}},类型:
77
'''
15-字典的常用操作
- 新增元素
语法:字典[Key] = Value,结果:字典被修改,新增了元素
if __name__ == '__main__':
my_dict1 = { "k1": {"语文":77,"数学":66,"英语":33},
"k2":{"语文":88,"数学":66,"英语":33} ,
"k3":{"语文":99,"数学":66,"英语":33}}
print(f"字典1的内容是: {my_dict1},类型: {type(my_dict1)}")
my_dict1["k4"] = {"语文":1,"数学":6,"英语":3}
print(f"字典1的内容是: {my_dict1},类型: {type(my_dict1)}")
'''
字典1的内容是: {'k1': {'语文': 77, '数学': 66, '英语': 33}, 'k2': {'语文': 88, '数学': 66, '英语': 33}, 'k3': {'语文': 99, '数学': 66, '英语': 33}},类型:
字典1的内容是: {'k1': {'语文': 77, '数学': 66, '英语': 33}, 'k2': {'语文': 88, '数学': 66, '英语': 33}, 'k3': {'语文': 99, '数学': 66, '英语': 33}, 'k4': {'语文': 1, '数学': 6, '英语': 3}},类型:
'''
- 更新元素
语法:字典[Key] = Value2 结果:字典被修改, - 删除元素
语法:字典.pop(Key) 结果:获得指定Key的Value,同时字典被修改,指定Key的数据被删除
if __name__ == '__main__':
my_dict1 = { "k1": {"语文":77,"数学":66,"英语":33},
"k2":{"语文":88,"数学":66,"英语":33} ,
"k3":{"语文":99,"数学":66,"英语":33}}
print(f"字典1的内容是: {my_dict1},类型: {type(my_dict1)}")
a = my_dict1.pop("k1")
print(f"字典1的内容是: {my_dict1},类型: {type(my_dict1)}")
'''
字典1的内容是: {'k1': {'语文': 77, '数学': 66, '英语': 33}, 'k2': {'语文': 88, '数学': 66, '英语': 33}, 'k3': {'语文': 99, '数学': 66, '英语': 33}},类型:
字典1的内容是: {'k2': {'语文': 88, '数学': 66, '英语': 33}, 'k3': {'语文': 99, '数学': 66, '英语': 33}},类型:
'''
- 清空元素
语法:字典.clear()
if __name__ == '__main__':
my_dict1 = { "k1": {"语文":77,"数学":66,"英语":33},
"k2":{"语文":88,"数学":66,"英语":33} ,
"k3":{"语文":99,"数学":66,"英语":33}}
print(f"字典1的内容是: {my_dict1},类型: {type(my_dict1)}")
my_dict1.clear()
print(f"字典1的内容是: {my_dict1},类型: {type(my_dict1)}")
'''
字典1的内容是: {'k1': {'语文': 77, '数学': 66, '英语': 33}, 'k2': {'语文': 88, '数学': 66, '英语': 33}, 'k3': {'语文': 99, '数学': 66, '英语': 33}},类型:
字典1的内容是: {},类型:
'''
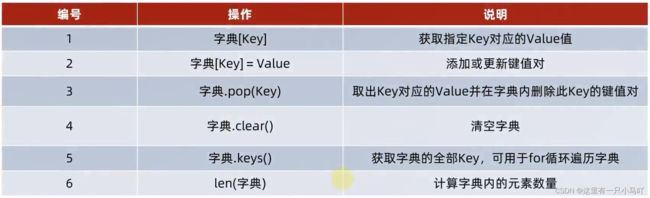
- 获取全部的key
语法:字典.keys(),结果:得到自带那种的全部Key
if __name__ == '__main__':
my_dict1 = { "k1": {"语文":77,"数学":66,"英语":33},
"k2":{"语文":88,"数学":66,"英语":33} ,
"k3":{"语文":99,"数学":66,"英语":33}}
print(f"字典1的内容是: {my_dict1},类型: {type(my_dict1)}")
keys = my_dict1.keys()
print(keys)
'''
字典1的内容是: {'k1': {'语文': 77, '数学': 66, '英语': 33}, 'k2': {'语文': 88, '数学': 66, '英语': 33}, 'k3': {'语文': 99, '数学': 66, '英语': 33}},类型:
dict_keys(['k1', 'k2', 'k3'])
'''
- 遍历字典
语法:只能for 不能while 因为他不支持下标索引!!!!
if __name__ == '__main__':
my_dict = { "k1": {"语文":77,"数学":66,"英语":33},
"k2":{"语文":88,"数学":66,"英语":33} ,
"k3":{"语文":99,"数学":66,"英语":33}}
keys = my_dict.keys()
# 方式1:通过获取到全部的key来完成遍历
for key in keys:
print(f"字典的key是: {key}")
print(f"字典的value是: {my_dict[key]}")
# 方式2:直接对字典进行for循环,每一次循环都是直接得到key
for key in my_dict:
print(f"2字典的key是: {key}")
print(f"2字典的value是: {my_dict[key]}")
'''
字典的key是: k1
字典的value是: {'语文': 77, '数学': 66, '英语': 33}
字典的key是: k2
字典的value是: {'语文': 88, '数学': 66, '英语': 33}
字典的key是: k3
字典的value是: {'语文': 99, '数学': 66, '英语': 33}
--------------------------------------------------------------
2字典的key是: k1
2字典的value是: {'语文': 77, '数学': 66, '英语': 33}
2字典的key是: k2
2字典的value是: {'语文': 88, '数学': 66, '英语': 33}
2字典的key是: k3
2字典的value是: {'语文': 99, '数学': 66, '英语': 33}
'''
- 统计字典内的元素数量
语法:len(字典)
if __name__ == '__main__':
my_dict = { "k1": {"语文":77,"数学":66,"英语":33},
"k2":{"语文":88,"数学":66,"英语":33} ,
"k3":{"语文":99,"数学":66,"英语":33}}
print(len(my_dict))#3
16-字典课后练习讲解
案例说明:

if __name__ == '__main__':
my_dict = { "王": {"部门": "科技部", "工资": 3000, "级别": 1},
"周": {"部门": "市场部", "工资": 5000, "级别": 2},
"林": {"部门": "市场部", "工资": 7000, "级别": 3},
"张": {"部门": "科技部", "工资": 4000, "级别": 1},
"刘": {"部门": "市场部", "工资": 6000, "级别": 2},
}
for key in my_dict:
if(my_dict[key]["级别"] ==1):
a = my_dict[key]
a["工资"] +=1000
my_dict[key]["工资"] = a["工资"]
a = my_dict[key]
a["级别"] +=1
my_dict[key]["级别"] = a["级别"]
print(my_dict[key])
'''
{'部门': '科技部', '工资': 4000, '级别': 2}
{'部门': '市场部', '工资': 5000, '级别': 2}
{'部门': '市场部', '工资': 7000, '级别': 3}
{'部门': '科技部', '工资': 5000, '级别': 2}
{'部门': '市场部', '工资': 6000, '级别': 2}
'''
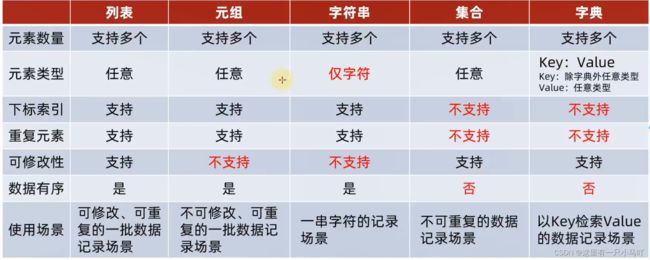
17-五类数据容器的总结对比
数据容器可以从以下视角进行简单的分类:
- 是否支持下标索引
●支持:列表、元组、字符串-序列类型
●不支持:集合、字典-非序列类型 - 是否支持重复元素:
●支持:列表、元组、字符串-序列类型
●不支持:集合、字典-非序列类型 - 是否可以修改
●支持:列表、集合、字典
●不支持:元组、字符串
18-数据容器的通用操作


if __name__ == '__main__':
my_list = [1, 2, 3, 4, 5]
my_tuple = (1, 2, 3, 4,5)
my_str = "abcdefg"
my_set = {1,2, 3, 4,5}
my_dict = {"key1": 1, "key2": 2,"key3": 3,"key4": 4, "key5": 5}
# len元素个数
print(f"列表元素个数有: {len(my_list)}")
print(f"元组元素个数有: {len(my_tuple)}")
print(f"字符串元素个数有: {len(my_str)}")
print(f"集合元素个数有: {len(my_set)}")
print(f"字典元素个数有: {len(my_dict)}")
# max最大元素最大元素
print(f"最大元素值: {max(my_list)}")
print(f"最大元素值: {max(my_tuple)}")
print(f"最大元素值: {max(my_str)}")
print(f"最大元素值: {max(my_set)}")
print(f"最大元素值: {max(my_dict)}")
# min最小元素
print(f"最小元素值: {min(my_list)}")
print(f"最小元素值: {min(my_tuple)}")
print(f"最小元素值: {min(my_str)}")
print(f"最小元素值: {min(my_set)}")
print(f"最小元素值: {min(my_dict)}")
'''
列表元素个数有: 5
元组元素个数有: 5
字符串元素个数有: 7
集合元素个数有: 5
字典元素个数有: 5
最大元素值: 5
最大元素值: 5
最大元素值: g
最大元素值: 5
最大元素值: key5
最小元素值: 1
最小元素值: 1
最小元素值: a
最小元素值: 1
最小元素值: key1
'''

if __name__ == '__main__':
my_list = [1, 2, 3, 4, 5]
my_tuple = (1, 2, 3, 4,5)
my_str = "abcdefg"
my_set = {1,2, 3, 4,5}
my_dict = {"key1": 1, "key2": 2,"key3": 3,"key4": 4, "key5": 5}
# 类型转换:容器转列表
print(f"列表转列表的结果是: {list(my_list)}")
print(f"元组转列表的结果是: {list(my_tuple)}")
print(f"字串转列表结果是: {list(my_str)}")
print(f"集合转列表的结果是: {list(my_set)}")
print(f"字典转列表的结果是: {list(my_dict)}")
# 类型转换:容器转元组
print(f"列表转元组的结果是: {tuple(my_list)}")
print(f"元组转元组的结果是: {tuple(my_tuple)}")
print(f"字串转元组结果是: {tuple(my_str)}")
print(f"集合转元组的结果是: {tuple(my_set)}")
print(f"字典转元组的结果是: {tuple(my_dict)}")
# 类型转换:容器转字符串
print(f"列表转字符串的结果是: {str(my_list)}")
print(f"元组转字符串的结果是: {str(my_tuple)}")
print(f"字串转字符串结果是: {str(my_str)}")
print(f"集合转字符串的结果是: {str(my_set)}")
print(f"字典转字符串的结果是: {str(my_dict)}")
# 类型转换:容器转集合
print(f"列表转集合的结果是: {set(my_list)}")
print(f"元组转集合的结果是: {set(my_tuple)}")
print(f"字串转集合结果是: {set(my_str)}")
print(f"集合转集合的结果是: {set(my_set)}")
print(f"字典转集合的结果是: {set(my_dict)}")
'''
列表转列表的结果是: [1, 2, 3, 4, 5]
元组转列表的结果是: [1, 2, 3, 4, 5]
字串转列表结果是: ['a', 'b', 'c', 'd', 'e', 'f', 'g']
集合转列表的结果是: [1, 2, 3, 4, 5]
字典转列表的结果是: ['key1', 'key2', 'key3', 'key4', 'key5']
-----------------------------------------------------------
列表转元组的结果是: (1, 2, 3, 4, 5)
元组转元组的结果是: (1, 2, 3, 4, 5)
字串转元组结果是: ('a', 'b', 'c', 'd', 'e', 'f', 'g')
集合转元组的结果是: (1, 2, 3, 4, 5)
字典转元组的结果是: ('key1', 'key2', 'key3', 'key4', 'key5')
-----------------------------------------------------------
列表转字符串的结果是: [1, 2, 3, 4, 5]
元组转字符串的结果是: (1, 2, 3, 4, 5)
字串转字符串结果是: abcdefg
集合转字符串的结果是: {1, 2, 3, 4, 5}
字典转字符串的结果是: {'key1': 1, 'key2': 2, 'key3': 3, 'key4': 4, 'key5': 5}
-----------------------------------------------------------
列表转集合的结果是: {1, 2, 3, 4, 5}
元组转集合的结果是: {1, 2, 3, 4, 5}
字串转集合结果是: {'a', 'b', 'e', 'c', 'd', 'f', 'g'}
集合转集合的结果是: {1, 2, 3, 4, 5}
字典转集合的结果是: {'key5', 'key1', 'key3', 'key2', 'key4'}
-----------------------------------------------------------
'''
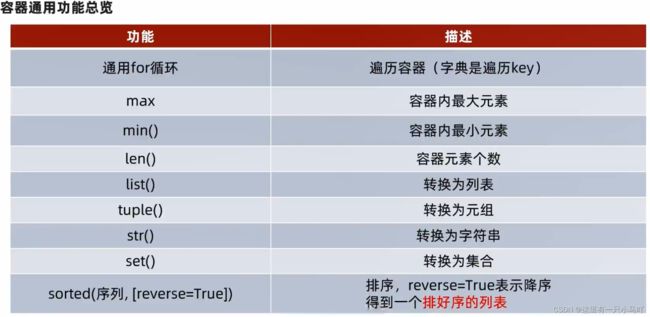
容器通用排序和功能
**sorted(容器,[reverse = True])**其中,最重要的是,排序结果变成了列表!!!!字典value丢失
if __name__ == '__main__':
my_list = [3, 1, 2, 5, 4]
my_tuple = (3, 1, 2, 5, 4)
my_str = "bdcefga"
my_set = {3, 1, 2, 5, 4}
my_dict = {"key3": 1,"key1": 2,"key2": 3,"key5": 4,"key4": 5}
print(f"列表对象的排序结果: {sorted(my_list)}" )
print(f"元组对象的排序结果: {sorted(my_tuple)}")
print(f"字符串对象的排序结果: {sorted(my_str)}")
print(f"集合对象的排序结果: {sorted(my_set)}" )
print(f"字典对象的排序结果: {sorted(my_dict)}")
print(f"列表对象的排序结果: {sorted(my_list,reverse=True)}" )
print(f"元组对象的排序结果: {sorted(my_tuple,reverse=True)}")
print(f"字符串对象的排序结果: {sorted(my_str,reverse=True)}")
print(f"集合对象的排序结果: {sorted(my_set,reverse=True)}" )
print(f"字典对象的排序结果: {sorted(my_dict,reverse=True)}")
'''
列表对象的排序结果: [1, 2, 3, 4, 5]
元组对象的排序结果: [1, 2, 3, 4, 5]
字符串对象的排序结果: ['a', 'b', 'c', 'd', 'e', 'f', 'g']
集合对象的排序结果: [1, 2, 3, 4, 5]
字典对象的排序结果: ['key1', 'key2', 'key3', 'key4', 'key5']
列表对象的排序结果: [5, 4, 3, 2, 1]
元组对象的排序结果: [5, 4, 3, 2, 1]
字符串对象的排序结果: ['g', 'f', 'e', 'd', 'c', 'b', 'a']
集合对象的排序结果: [5, 4, 3, 2, 1]
字典对象的排序结果: ['key5', 'key4', 'key3', 'key2', 'key1']
'''
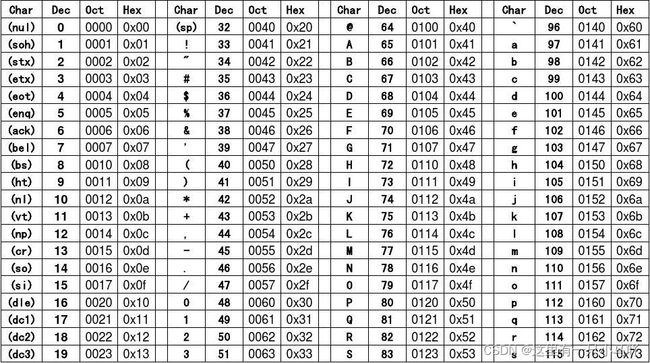
19-拓展字符串大小比较方式
ASCI码表
在程序中,字符串所用的所有字符如:大小写英文单词、数字、特殊符号(!、\、|、@、#、空格等)
都有其对应的ASCI码表值。
每一个字符都能对应上一个:数字的码值。字符串进行比较就是基于数字的码值大小进行比较的。

if __name__ == '__main__':
# abc比较abd
print(f"abd大于abc,结果: {'abd' > 'abc'}")
# a比较ab
print(f"ab大于a,结果: {'ab' > 'a'}")
# a比较A
print(f"a大于A,结果: {'a' > 'A'}")
# key1比较key2
print(f"key2 > key1, 结果: {'key2' > 'key1'}")
'''
abd大于abc,结果: True
ab大于a,结果: True
a大于A,结果: True
key2 > key1, 结果: True
'''
第一阶段——第七章
01-函数的多返回值

那多个返回值怎么接受呢?

利用逗号 直接写在一起,并且接受多个即可
if __name__ == '__main__':
# 演示使用多个变量,接收多个返回值
def test_return ():
return 1,2,3
x,y,z = test_return()
print(x)
print(y)
print(z)
'''
1
2
3
'''
if __name__ == '__main__':
# 演示使用多个变量,接收多个返回值
def test_return ():
return 1,'hello',True
x,y,z = test_return()
print(x)
print(y)
print(z)
'''
1
hello
True
'''
02-函数的多种参数使用形式
函数参数种类
使用方式上的不同,函数有4中常见参数使用方式:
| 位置参数 | 关键字参数 | 缺省参数 | 不定长参数 |
|---|
位置参数调用函数时根据函数定义的参数位置来传递参数,传递的参数和定义的参数的顺序及个数必须一致

关键字参数:函数调用时通过“键=值”形式传递参数
作用:可以让函数更加清晰、容易使用,同时也清楚了参数的顺序需求

注意:
函数调用时,如果有位置参数时,位置参数必须在关键字参数的前面,但关键字参数之间不存在先后顺序
if __name__ == '__main__':
def user_info(name, age, gender):
print(f"姓名是:{name},年龄是:{age}, 性别是: {gender}")
# 位置参数-默认使用形式
user_info('小明',20,'男')
# 关键字参数
user_info(name='小王',age = 11, gender = '女' )
user_info(age=10,gender = '女', name = '潇潇')
# 可以不按照参数的定义顺序传参
user_info('甜甜',gender='女',age=90 )
'''
姓名是:小明,年龄是:20, 性别是: 男
姓名是:小王,年龄是:11, 性别是: 女
姓名是:潇潇,年龄是:10, 性别是: 女
姓名是:甜甜,年龄是:90, 性别是: 女
'''
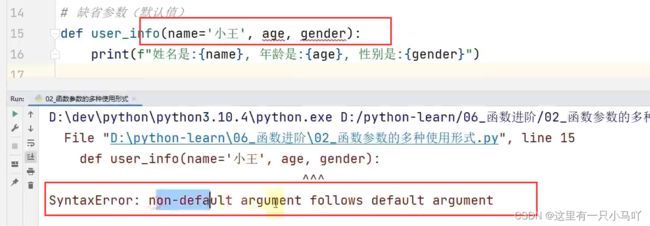
缺省参数:缺省参数也叫默认参数,用于定义函数,为参数提供默认值,调用函数时可不传该默认参数的值(注意:所有位置参数必须出现在默认参数前,包括函数定义和调用)。
作用:当调用函数时没有传递参数,就会使用默认是用缺省参数对应的值.
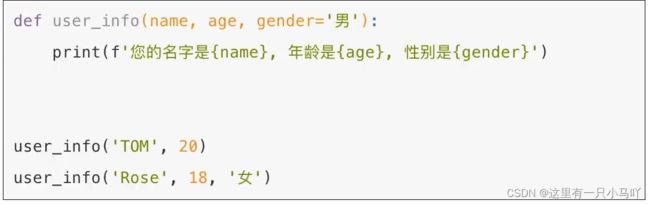
注意:函数调用时,如果为缺省参数传值则修改默认参数值,否则使用这个默认值!并且给你的默认值必须放到最后
if __name__ == '__main__':
def user_info(name, age, gender = '男'):
print(f"姓名是:{name},年龄是:{age}, 性别是: {gender}")
user_info('xs',2)
user_info('xs', 2,gender ='兽' )
'''
姓名是:xs,年龄是:2, 性别是: 男
姓名是:xs,年龄是:2, 性别是: 兽
'''
位置不定长参数:不定长参数也叫可变参数。中用于不确定调用的时候会传递多少个参数(不传参也可以)的场景。
作用:当调用函数时不确定参数个数时,可以使用不定长参数
不定长参数的类型:
①位置传递 ②关键字传递

关键字不定长参数

if __name__ == '__main__':
# 不定长定义的形式参数会作为元组存在,接收不定长数量的参数传入
def user_info(*args):
print(f"args参数的类型是: {type(args)}, 内容是:{args}")
user_info(1,2,3,'小明')#args参数的类型是: , 内容是:(1, 2, 3, '小明')
# 不定长一关键字不定长,**号
def user_info(** kwargs):
print(f"args参数的类型是: {type(kwargs)}, 内容是:{kwargs}")
user_info(name='小王',age=11, gender=' 男孩',addr='北京')#args参数的类型是: , 内容是:{'name': '小王', 'age': 11, 'gender': ' 男孩', 'addr': '北京'}
03-函数作为参数传递

if __name__ == '__main__':
# 定义一个函数,接收另一个函数作为传入参数
def test_func(compute):
result = compute(1,2) # 确定compute 是函数
print(f" compute参数的类型是: {type(compute)}")
print(f"计算结果: {result}")
# 定义一个函数,准备作为参数传入另一个函数
def compute(x,y):
return x + y
# 调用,并传入函数
test_func(compute)
'''
compute参数的类型是:
计算结果: 3
'''
1.函数本身是可以作为参数,传入另一个函数中进行使用的。
2.将函数传入的作用在于:传入计算逻辑,而非传入数据。
04-lambda匿名函数
●def关键字,可以定义带有名称的函数
●lambda关键字,可以定义匿名函数(无名称)
有名称的函数,可以基于名称重复使用。无名称的匿名函数,只可临时使用一次。
匿名函数定义语法:lambda传入参数:函数体(一行代码)
- lambda是关键字,表示定义匿名函数
- 传入参数表示匿名函数的形式参数,如: x, y表示接收2个形式参数
- 函数体,就是函数的执行逻辑,要注意:只能写一行,无法写多行代码

if __name__ == '__main__':
# 定义一个函数,接收另一个函数作为传入参数
def test_func(compute):
result = compute(3,2) # 确定compute 是函数
print(f" compute参数的类型是: {type(compute)}")
print(f"计算结果: {result}")
test_func(lambda x,y:x+y)
test_func(lambda x, y: x - y)
test_func(lambda x, y: x * y)
'''
compute参数的类型是:
计算结果: 5
compute参数的类型是:
计算结果: 1
compute参数的类型是:
计算结果: 6
'''