python粗糙集简约算法+可视化界面
粗糙集简约算法理论参照:粗糙集简约程序算法介绍
完整代码:程序完整代码
实验名称:粗糙集知识约简程序
实验平台:Python
实验过程和结果
1、实验数据

2、实验说明及过程截图
本次粗糙集简约实验使用的算法为领域粗糙集属性简约算法。本平台名为“5433粗糙集属性简约平台”。以下是平台导入数据界面截图:

图1 平台导入数据界面截图(未读入数据时)

图2 平台导入数据截图2(读入数据时)
点击“开始计算”按钮即可进入计算结果展示界面,计算结果展示界面截图如下:
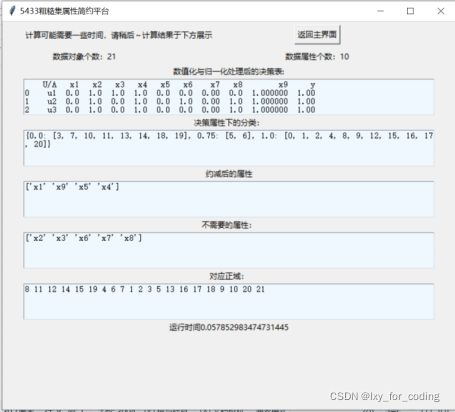
图3 计算结果界面截图
3、实验结果
导入样例数据于平台数据库,点击“进行计算”。实验结果截图如下:
 约减后的属性有:x1、x4、x5、x9
约减后的属性有:x1、x4、x5、x9
不需要的属性有:x2、x3、x6、x7、x8
上代码!!!
若需要完整现成代码请至程序完整代码下载!!!
main.py
from tkinter import *
from MainPage import *
root = Tk()
root.title('5433粗糙集属性简约平台')
MainPage(root)
root.mainloop()
mainPage.py
from tkinter import *
from data_input import data_input
class MainPage(object):
def __init__(self, master=None):
self.root = master # 定义内部变量root
self.root.geometry('%dx%d' % (900, 400)) # 设置窗口大小
self.createPage()
def createPage(self):
self.page = Frame(self.root) # 创建Frame
self.page.pack()
Label(self.page, text='欢迎使用5433粗糙集属性简约平台').grid(row=0, columnspan=4, stick=W, pady=10)
Label(self.page, text='算法思想:').grid(row=1, columnspan=4, stick=W,pady=10)
Label(self.page, text='前向贪心约简(F2HARNRS)算法的具体策略是:初始化属性约简集合为空集,此时约简集合下的正域为空集,每次选取使正域中对象增加最多的属性加入').grid(
row=2, columnspan=4, stick=W, pady=10)
Label(self.page,
text='到约简集合中,直至正域中的对象不再增加,输出集合。其中,胡玉清等人证明了F2HARNRS算法满足正域单调性,即约简集合中新增加的属性不会使已').grid(
row=3, columnspan=4, stick=W, pady=10)
Label(self.page, text='属于正域的样本变为非正域样本这一性质,在算法的计算过程中,每次仅对还未判定为正域的样本进行正域计算,进一步缩减了算法的时间开销。胡玉').grid(row=4, columnspan=4, stick=W, pady=10)
Label(self.page, text='清经过实验得到的 0.1~0.3 是δ较好的取值区间,此时δ使得分类器有良好的分类效果。(说明 本程序为了计算方便 使用的是每个都是对象或者属性的下标)').grid(row=5, columnspan=4, stick=W, pady=10)
# emply line
Label(self.page, text="").grid(row=6, column=2)
Button(self.page, text='从本地文件读入数据计算', command = self.jump1 ).grid(row=7, columnspan=4)
def jump1(self):
self.page.destroy()
data_input(self.root)
data_input.py
from tkinter import *
import tkinter.messagebox
import os
from tkinter import filedialog, dialog
from count_page import count_page
class data_input(object):
def __init__(self, master=None):
self.root = master # 定义内部变量root
self.root.geometry('%dx%d' % (700, 500)) # 设置窗口大小
self.path_ = ""
self.path = StringVar()
def selectPath(self): #选择路径
#选择文件path_接收文件地址
path_ = filedialog.askopenfilename()
#通过replace函数替换绝对文件地址中的/来使文件可被程序读取
self.path_ = path_
#path设置path_的值
self.path.set(path_)
with open(file=self.path_, mode='r+', encoding="utf-8") as file:
self.file_text = file.read()
def createPage(self):
def upload_data():
if self.path_[-1] != "v":
tkinter.messagebox.showwarning('警告','请导入csv文件!')
else:
text1.insert('insert', self.file_text)
self.page = Frame(self.root) # 创建Frame
self.page.pack()
Label(self.page, text="").grid(row=0, column=0)
Label(self.page, text="").grid(row=0, column=1)
Label(self.page, text="").grid(row=0, column=2)
Label(self.page, text="").grid(row=0, column=3)
Label(self.page, text="").grid(row=0, column=4)
Label(self.page, text="").grid(row=0, column=5)
input_path = Entry(self.page, textvariable=self.path, width=30)
input_path.grid(row=2, columnspan=2)
text1 = Text(self.page, width=90, height=25, bg='AliceBlue')
text1.grid(row=4, columnspan=5)
Button(self.page, text="选择路径", command=self.selectPath).grid(row=2, column=2)
Button(self.page, text="导入数据", command=upload_data).grid(row=2, column=3)
# emply line
Label(self.page, text="").grid(row=3, column=2)
Label(self.page, text="").grid(row=7, column=0)
def count():
with open("path.txt", 'w', encoding='utf-8') as f:
f.write(self.path_)
f.close()
if not text1.get("2.0","end"):
tkinter.messagebox.showwarning('警告', '请导入数据!')
else:
self.page.destroy()
count_page(self.root)
Button(self.page, text="开始计算", command=count).grid(row=11,columnspan=5)
count_page.py
from tkinter import *
import MainPage
from sklearn import preprocessing
import pandas as pd
import numpy as np
import math
import random
import time
class count_page(object):
def __init__(self, master=None):
self.root = master # 定义内部变量root
self.root.geometry('%dx%d' % (700, 600)) # 设置窗口大小
self.createPage()
def read_path(self):
with open("path.txt", 'r', encoding='utf-8') as f:
line = f.read()
f.close()
return line
def createPage(self):
m_chart1 = pd.read_csv(self.read_path())
m_chart = np.array(m_chart1.values[:, 1:])
self.page = Frame(self.root)
self.page.pack()
start = time.time()
m_pro = m_chart1.copy(deep=True)
m_chart2 = m_chart1.drop(columns=[m_chart1.columns[0]])
dd1 = m_chart1.where(m_chart2.applymap(type).eq(int))
dd2 = m_chart1.where(m_chart2.applymap(type).eq(str))
c_num = dd1.dropna(axis=1, how='all')
c_str = dd2.dropna(axis=1, how='all')
c_num1 = np.array(c_num)
c_str1 = np.array(c_str)
if not c_str.empty:
c = np.unique(c_str1)
for i, j in enumerate(c):
m_chart[m_chart == j] = i
col = m_chart1.columns
m_chart1[col[1:]] = m_chart
o_l, p_l = m_chart.shape
o_all = list(np.arange(o_l))
p_all = list(np.arange(p_l - 1))
smp = list(o_all)
red = []
argu = 0.2
Label(self.page, text='计算可能需要一些时间,请稍后~计算结果于下方展示').grid(row=0,columnspan = 4, stick=W, pady=10)
Button(self.page, text="返回主界面", command=self.jump_back).grid(row=0,column=3)
Label(self.page, text="数据对象个数:{}".format(o_l)).grid(row=1, column=0)
Label(self.page, text="数据属性个数:{}".format(p_l)).grid(row=1, column=3)
min_max_scaler = preprocessing.MinMaxScaler()
X_minMax = min_max_scaler.fit_transform(m_chart)
m_chart = X_minMax
m_copy = m_chart1.copy(deep=True)
m_copy[col[1:]] = m_chart
def f_distance(o_i, o_j, r):
d = 0
for k in r:
d = d + (m_chart[o_i, k] - m_chart[o_j, k]) ** 2
d = math.sqrt(d)
return d
def get_nei(o_i, r):
nei = [o_i]
for i in o_all:
if i != o_i:
if f_distance(o_i, i, r) < argu:
nei.append(i)
return nei
Label(self.page, text="数值化与归一化处理后的决策表:").grid(row=2, columnspan=5)
text1 = Text(self.page, width=90, height=4, bg='AliceBlue')
text1.grid(row=3, columnspan=5)
text1.insert('insert', m_copy)
Label(self.page, text="决策属性下的分类:").grid(row=4, columnspan=5)
text2 = Text(self.page, width=90, height=4, bg='AliceBlue')
text2.grid(row=5, columnspan=5)
num_d = np.unique(m_chart[:, -1])
dd = m_chart[:, -1]
d_cla = {}
for j in num_d:
d_cla[j] = list(np.where(dd == j)[0])
text2.insert('insert', d_cla)
pos_end = []
while smp != []:
test = list(set(p_all) - set(red))
dict_len = {}
dict_n = {}
for p_i in test:
pos = []
for o_i in smp:
test1 = red + [p_i]
nei = get_nei(o_i, test1)
if len(set(dd[nei])) == 1:
pos.append(o_i)
dict_len[p_i] = len(pos)
dict_n[p_i] = pos
key_max = max(dict_len, key=dict_len.get)
if dict_n[key_max] != []:
red.append(key_max)
pos_end.extend(dict_n[key_max])
smp = list(set(smp) - set(dict_n[key_max]))
else:
break
red1 = [i + 1 for i in red]
unimp = list(set(p_all) - set(red))
unimp1 = [i + 1 for i in unimp]
Label(self.page, text="约减后的属性").grid(row=6, columnspan=5)
text6 = Text(self.page, width=90, height=4, bg='AliceBlue')
text6.grid(row=7, columnspan=5)
text6.insert('insert', m_chart1.columns[red1].values)
Label(self.page, text="不需要的属性:").grid(row=8, columnspan=5)
text7 = Text(self.page, width=90, height=4, bg='AliceBlue')
text7.grid(row=9, columnspan=5)
text7.insert('insert', m_chart1.columns[unimp1].values)
pos_end1 = [i + 1 for i in pos_end]
Label(self.page, text="对应正域:").grid(row=10, columnspan=5)
text4 = Text(self.page, width=90, height=4, bg='AliceBlue')
text4.grid(row=11, columnspan=5)
text4.insert('insert', pos_end1)
Label(self.page, text="运行时间{}".format((time.time()-start))).grid(row=14, columnspan=5)
def jump_back(self):
self.page.destroy()
MainPage.MainPage(self.root)