【part2】Tensorflow Object detection API Win10使用教程(tensorflow数据集生成教程)
前言:
该教程目的是为了把Pascal VOC数据集转换成tensorflow object detection api可用的数据集的格式(.tfrecord)。
教程结构:
本教程分为四个部分:
一、前期准备
二、数据集生成工具使用方法
三、使用详细步骤及效果
四、各个.py文件作用说明
注意:
假如数据集用labelImg进行标注,且输出标注格式为Pascal VOC,则该教程可以直接使用。
为了演示,”models-r1.13.0.zip”里面的“/research/object_detection/images/”目录已经内置了:
Pascal VOC数据集文件、经过转换生成的.csv文件,以及最后转换生成的tfrecord
如果需要使用新标注的数据去生成tensorflow数据集,把”images”文件夹下图中的内容清空,然后重新放置Pascal VOC数据集到对应的位置,然后使用下面的流程重新生成.csv和.tfrecord即可。
一、前期准备
需要下载2个文件, 可以在我github上进行Clone:
数据集转换工具(voc2tfrecord).rar
https://github.com/HelloSZS/VOC_to_TFrecord
models-r1.13.0.zip
https://github.com/HelloSZS/models-r1.13.0
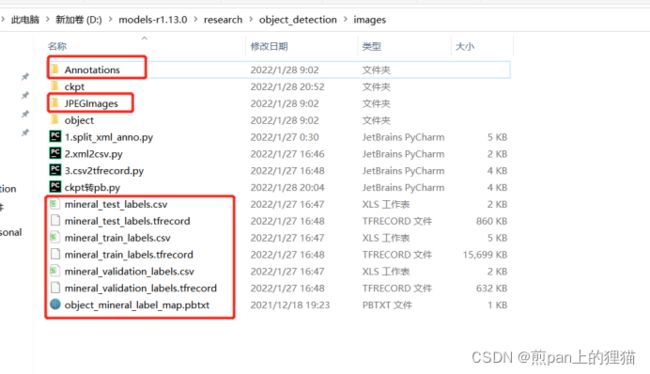
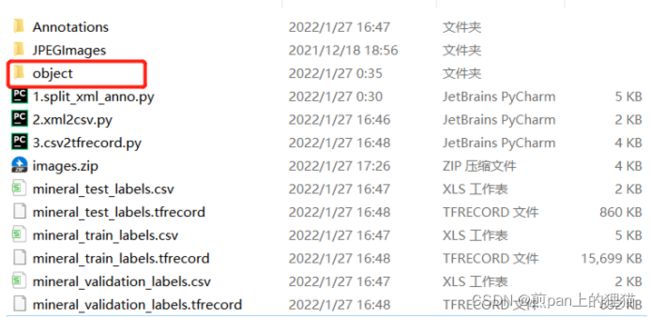
前期准备阶段,需要把标注好的数据集放到tensorflow object detection文件夹的对应目录中。放置的第一级文件目录结构样式如下图所示:
第一级文件目录存放了:
- Annotations文件夹: 标注信息文件夹
- JPEGImages文件夹:图片文件夹
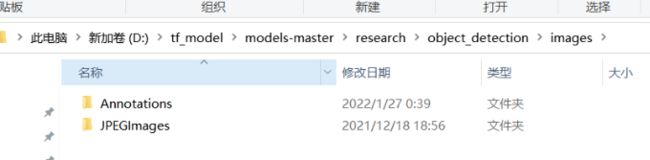
1.Annotations文件夹的内容如下图所示,存放着.xml标注文件(VOC数据集标注文件格式)。

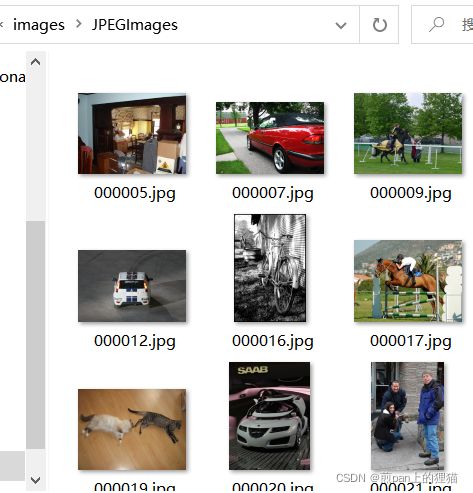
2.JPEGImages文件夹的内容如下图所示,存放被标注好的图片文件。
二、数据集生成工具使用方法
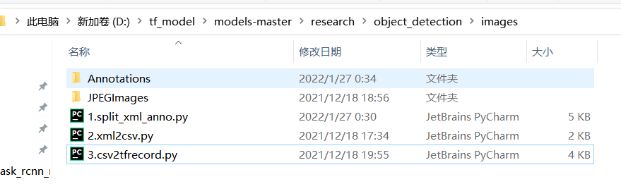
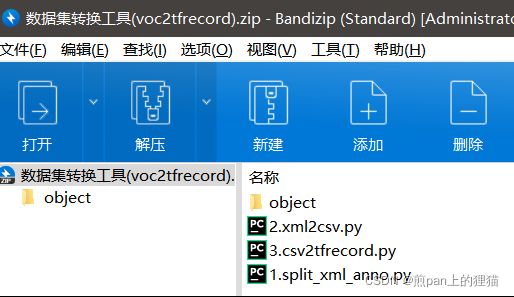
1.把图片文件、标注文件放置好,然后把”数据集转换工具(voc2tfrecord).rar”里面的三个.py文件,解压到下图位置(其实已经内置)。三个.py文件的名称:
“1.split_xml_anno.py”
“2.xml2csv.py”
“3.csv2tfrecord.py”
”数据集转换工具(voc2tfrecord).rar”的内容,里面有一个object文件夹放置模型配置信息,三、详细使用步骤及效果中会提及到。
2.使用步骤:使用cmd命令运行三个文件之前,先切换cmd的“当前目录”。
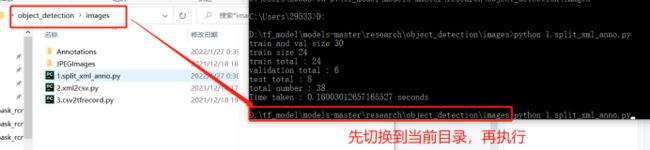
第一步:用cmd执行:python 1.split_xml_anno.py
第二步:用cmd执行:python 2.xml2csv.py
第三步:
先修改3.csv2tfrecord.py里面对应位置的代码,修改方法在“三、执行步骤详细教程及效果”的第3点,修改完再按顺序在cmd里面执行以下命令:
python 3.csv2tfrecord.py --csv_input=mineral_train_labels.csv --output_path=mineral_train_labels.tfrecord
python 3.csv2tfrecord.py --csv_input=mineral_test_labels.csv --output_path=mineral_test_labels.tfrecord
python 3.csv2tfrecord.py --csv_input=mineral_validation_labels.csv --output_path=mineral_validation_labels.tfrecord
三、详细使用步骤及效果:
1.执行第一步,如果成功,会显示数据集分割的信息,以及数据数量。

2.执行第二步,可能会显示该环境没有安装相应的库,如下图所示:

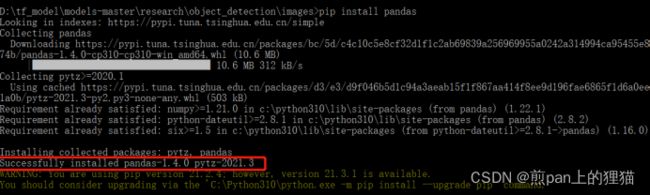
查看上述错误结果,缺少pandas库,使用python语言自带的pip进行下载安装,注意检查是否已连接网络。
对应缺少pandas库,使用:pip install pandas 来安装,若安装成功,则cmd输出应该会如下图所示:
然后重新运行,第二步成功执行,如果成功,cmd输出如下图:

成功执行第二步,文件夹会生成三个文件:
mineral_test_labels.csv
mineral_train_labels.csv
mineral_validation_labels.csv

打开.csv文件,里面会存放类似信息,如下图:

3.执行第三步,执行之前需要按照标注时标注的类别名称修改:“3.csv2tfrecord.py”中的代码
以下图为例子,需要转换的数据集被分成了20个类别:则代码如下图所示:

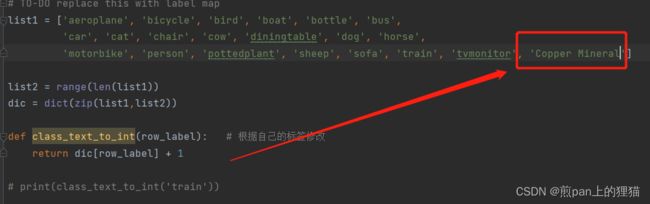
假如标注时添加了一类“Copper Mineral”,则在该代码文件里面需要修改部分代码,在上图基础上做更改,如下图所示:
修改完成之后保存,然后在cmd下分次运行下面三个命令:
python 3.csv2tfrecord.py --csv_input=mineral_train_labels.csv --output_path=mineral_train_labels.tfrecord
python 3.csv2tfrecord.py --csv_input=mineral_test_labels.csv --output_path=mineral_test_labels.tfrecord
python 3.csv2tfrecord.py --csv_input=mineral_validation_labels.csv --output_path=mineral_validation_labels.tfrecord
如果此步骤执行成功,则cmd会分次生成以下三个提示:


![]()
并且文件夹中会生成三个文件:
mineral_test_labels.tfrecord
mineral_train_labels.tfrecord
mineral_validation_labels.tfrecord

至此,tensorflow运行需要的数据集已经生成完成。
三个生成文件的名字可以修改,不过要和后续使用tensorflow object detection api运行模型其中所需的模型配置文件里面的数据集名称一致,如下图绿框部分所示:

下面介绍配置模型配置文件需要配置的部分。
4.模型配置文件的介绍
“配置文件”包含tensorflow object detection api在训练模型之前,它需要获取的全部信息:模型的结构设置、优化器的参数设置、数据集存放的位置,数据集读取器的参数设置等。
不过在本“数据集转换”教程中,只会讲述“配置文件”中与“数据集”相关的部分。
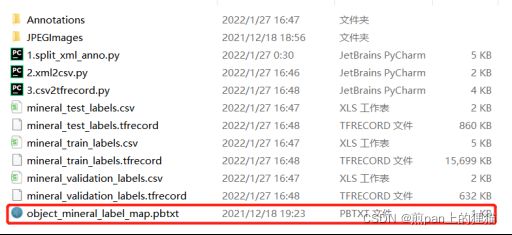
把”数据集转换工具(voc2tfrecord).rar”里面的object文件夹也解压到当前数据集文件夹中:
object文件夹中包含一个模型配置文件(.config):

(可以用记事本,也可以用vscode或pycharm等IDE打开)打开之后,跳到代码第173行,该位置内容如下图所示。
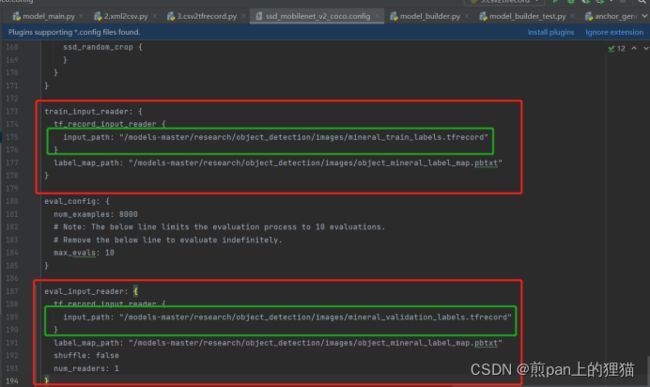
最后,看到上图红框的部分,里面有:
label_map_path: "/models-master/research/object_detection/images/object_mineral_label_map.pbtxt"
在"/models-master/research/object_detection/images/”下新建一个”.pbtxt”文件,文件名随意,不过要和上图文件中的一致(可修改上图中对应的部分,也可直接修改该文件名。也可以同时修改两者的名称)。
该.pbtxt的作用是给模型输入类名和类标号, 该文件可用“记事本”方式打开,其内容为:
item {
id: 1
name: 类名1
}
item {
id: 2
name: 类名2
}
......
内容示例:假如标注有两类类别的目标”Goal Mineral”和”Silver Mineral”,则内容如下图:

如果和在三、执行步骤详细教程及效果里面同样:要添加一类“Copper Mineral”,则该.pbtxt修改后的内容如下图所示:

至此,教程全部结束。
四、各个.py文件作用说明
第一个文件:1.split_xml_anno.py用作划分训练集、验证集以及测试集。
第二个文件:2.xml2csv.py用作把第一步产生的各个集合里的所有xml文件转换为csv文件。
CSV文件打开后的内容如图所示,记录(该训练集或验证集或测试集)中每张图片标注的标注框bbox信息。
第三个文件;3.csv2tfrecord.py把csv文件转换成tensorflow可用的数据集文件格式(.tfrecord)