知识图谱从入门到应用——知识图谱推理:基于符号逻辑的知识图谱推理
分类目录:《知识图谱从入门到应用》总目录
基于本体的推理
OWL本体语言简介
在介绍基于本体的推理之前,先回顾RDF的三元组模型,每一条三元组描述了客观世界的一个逻辑事实。这些事实性三元组是进一步叠加逻辑推理的基础。利用RDF或RDFS可以实现比较简单的演绎推理。例如可以利用subClassOf关系推断父子类关系。OWL扩展了RDF Schema的表达能力,提供了更多描述类和属性的表达构件。例如,可以声明两个类的相交性或互补性,可以定义传递关系、互反关系,还可以利用属性链(Property Chain)定义关系之间的关系。利用这些语义表达构件,可以完成更加复杂的本体逻辑推理。
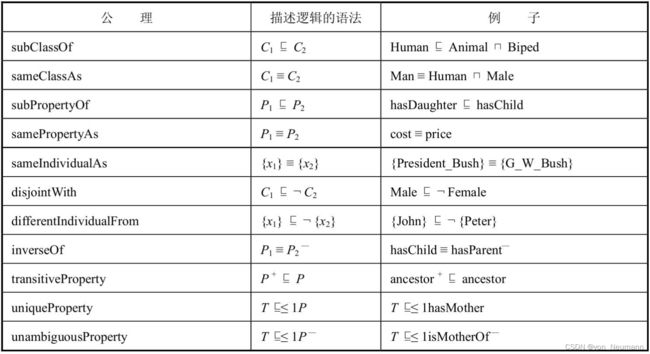
在介绍基于OWL实现的本体推理之前,先熟悉OWL的描述逻辑语义及语法。在一个OWL知识库中,包含原子概念 A A A和原子概念 R R R。可以对概念叠加合取和析取的逻辑操作。可以进一步增加存在量词和全称量词。例如:用 ∃ \exists ∃代表存在量词,∃has_child.Male的语义是指:“Somebody who has a child who is a male”。用 ∀ \forall ∀代表全称量词,∀has_child.Doctor的语义是指“Somebody whose children are all Doctor”。进一步可以定义更多的公理描述概念与概念之间、属性与属性之间的关系,以及属性本身的特性。例如,可以声明has_daughter在逻辑上蕴含has_child;cost和price是同一种语义;has_child和has_parent是互反关系;ancestor是传递关系等。如下图所示分别为OWL语言基本语法和OWL公理基本语法。限于篇幅,不对OWL完整语法展开介绍,有兴趣的读者可以参考OWL官方白皮书。

概念包含推理
首先来看基于OWL的概念之间的包含关系推理。概念包含推理是定义在TBox上面的推理,一般基于TBox中的公理推断两个概念之间是否存在包含关系。例如,已知Women概念包含Mother,Person概念包含Women,可以简单推理得到Person概念包含Mother,如下图所示。这种推理似乎太简单了,但事实上,人脑对概念的抽象和组合能力是很强的。经常会将多个概念进行组合来描述事物。例如,会描述:“红色、古风、适合于少女穿的长裙”,并判断“红色女装”是否包含这个概念所描述的语义。

再来看一个完整的例子,如下图所示。在一个OWL本体中先定义如下几条公理,如第一条公理定义:“苹果由富达和黑石投资”,第二条公理定义:“借助富达融资的公司都是创新企业”,第三条公理定义:“借助黑石融资的公司都是创新企业”,第四条公理声明:“投资即是帮助融资”。

首先基于第一条公理,可以得出图中横线下面的第一条结论,即:苹果由富达投资。进一步叠加第四条公理,可以推理得出苹果由富达融资。再进一步叠加第二条公理,因为凡是由富达融资的公司都是创新公司,因此可以推理得出苹果也是创新公司。
实例检测推理
再来看在OWL本体上实现的第二种推理,即:实例检测推理。它主要用于计算知识库中符合某个概念或关系定义的所有实例。如下图所示,知道Alice是Mother,而Mother概念包含于Women概念,因此可以计算得出Alice也是Women。类似地,也可以计算两个实体能满足的新的二元关系。

再来看一个完整的例子。在金融领域,希望定义一个兼并重组的套利策略,例如希望描述这样一种策略:与大盘股公司兼并重组的上市企业有很高的预期收益。可以根据自己的需要定义大盘股的概念,例如,可以定义:上证50和沪深300指数中的标的属于大盘股,并进一步定义上证180中的标的也属于沪深300。这些在TBox中定义的公理实际上描述了一种选股的专家知识,现在希望计算得出符合这种兼并重组策略的所有高预期公司。假如在知识库中,发现一条事实性三元组描述“赢时胜SZ300377和恒生电子SH600570在区块链方面有业务兼并”,同时也知道“恒生电子是上证180的成分股”,如下图所示。这类在ABox层的三元组数据可以从已有的结构化数据转化过来,也可以是从新闻公报中实时提取出来的。不管怎样获取知识,这个事实型的ABox可能包含很多不断更新和变化的实例化三元组知识。接下来的目标是基于这些实例层三元组,推算哪些公司符合前面公理所定义的兼并重组策略描述的高预期公司。

首先基于第四条公理,推理知道恒生电子也是HS300的成份股。接下来,基于第三条公理,得出恒生电子是BigCapital大盘股。再接下来,叠加第一条公理就可以推理得出:赢时胜在短期内是一家高收益公司ValueSecurity。通过这个例子可以看到,本体推理其实模仿了人做决策判断的过程。TBox中的本体公理可以用来描述和表示复杂的选股策略知识,也就是所谓的专家知识。同时,ABox中的事实型知识可以利用大数据技术实时获取和更新,规模可能会很大。综合TBox中的策略知识和ABox中大量的事实型知识,可以通过一个推理机来完成复杂股票的筛选过程,这是传统数据库技术所实现不了的。
Tableax算法
OWL本体上实现的各种推理都可以用Tableaux算法来实现。Tableaux算法的基本思想是通过一系列规则构建ABox,以检测知识库的可满足性。Tableaux算法将概念包含、实例检测等推理都转化为可满足性检测问题来实现。Tableaux算法检查可满足性的基本思想类似于一阶逻辑的归结反驳。Tableaux算法主要基于一组描述逻辑算子来实现,如下图所示,列举了常用的几种运算规则。例如第一个规则定义:如果ABox中声明 x x x属于 C C C和 D D D的组合类,但 C ( x ) C(x) C(x)和 D ( x ) D(x) D(x)都还不在ABox中,则把 C ( x ) C(x) C(x)和 D ( x ) D(x) D(x)都加入到ABox中。

来看一个简单的例子:给定上文图中所示的本体,怎样检测实例Allen是否属于Woman类?首先将待证明的事实Woman(Allen)加入知识库中。然后逐一应用前面列表中所给出的规则,例如应用第二条规则,得出新的结论:Allen既是Man也是Women。这显然是不正确的,因为知识库中已经声明了,同时是Man和Women的人不存在,因此这会导致知识库不可满足。因而得出该知识库不可满足,从而得出结论:Allen不属于Woman类。所以,可以利用这种归结反驳推理的过程来做实例检测推理。同样的,也可以利用类似的方法完成如概念包含等推理。有很多实现这类本体推理的工具,以及各种改进和优化的Tableaux算法,这里不做具体介绍。感兴趣的读者可以查阅相关资料进一步学习。

基于Datalog的知识图谱推理
接下来讲解基于Datalog的知识图谱符号推理方法。前面介绍的本体推理主要实现的是基于本体概念描述的推理,无法支持规则型知识的推理。规则是非常常见的一种形式的知识,非常易于描述各类业务逻辑型知识。Datalog是一种可以将本体推理和规则推理相结合的推理语言。Datalog的基本组成单元是原子谓词 p p p,其中 n n n代表谓词的目数,例如has_child(X,Y)的目数是2,即二元关系。从这里可以看到,Datalog允许刻画多元关系。一条规则由头部原子H和多个体部原子组成,表示是体部描述对头部描述的逻辑蕴含关系。例如规则has_child(X,Y):-has_son(X,Y)表示has_son(X,Y)逻辑上蕴含has_child(X,Y)。和OWL本体一样,Datalog知识库还包含大量的事实型知识,在语法层面指那些没有体部也没有变量的规则。因此,Datalog知识库就是一组规则的集合。
下面举例来介绍Datalog推理过程。如下图所示,定义一组描述 a a a、 b b b、 c c c中的节点和路径的规则和事实型知识。基于第一条规则和第一条事实,可以推理得出新的结果path(a,b)。继续应用第一条规则和第二条事实,得出path(b,c)的事实。最后应用第二条规则和新产生的两条事实,得出path(a,c)。需要说明的是,在实际应用场景中,事实集通常是很大的,整个推理的计算复杂度也会随着规则集的增大而增加。

基于产生式规则的推理
产生式规则简介
最后简要介绍传统的产生式规则推理方法。产生式规则推理最早主要出现在专家系统时代的知识库推理中,其基本组成包含三个方面,即:Working Memory中的事实集合、产生式规则集合以及推理引擎。在Working Memory中的存储的事实可以类比本体中对于类和关系的描述,只是在语法方面会有所不同。产生式规则集合中存储都是像IF conditions THEN actions的规则,其中conditions是由条件组成的集合,又称为Left Hand Side(LHS),actions是由动作组成的序列,又称为Right Hand Side(RHS)。
LHS由一组条件取并操作组成,每个条件的形式如(type attr_1:spec_1attr_2:spec_2…attr_n:spec_n)所示。其中,原子,如:Alice,用于判断取值是否等于Alice;变量,如: x x x,用于判断取值是否等于(如果未绑定常量,则视其为自由变量);表达式,如: [ n + 4 ] [n+4] [n+4],用于判断取值是否等于(需要事先赋值);布尔测试,如: { > 10 } \{>10\} {>10},用于判断取值是否满足给定条件。若LHS中的所有条件均被满足,则该规则被触发。RHS由一组动作序列组成,当执行时,这些动作依次执行。动作的种类包括如:Add Pattern操作将向WM中加入型如Pattern的新事实;REMOVE i执行删除事实 i i i的操作;MODIFY i执行对应的属性修改操作。如下图所示的产生式规则定义了这样的推导逻辑:如果一个学生名为 x x x,则向事实集中加入一个Person,并设定其名字为 x x x所指代的名称。

产生式规则通过一个推理引擎来控制系统的执行,并完成模式匹配、冲突解决和动作执行的操作。模式匹配用规则的条件部分匹配事实集中的事实,整个LHS都被满足的规则触发,并被加入议程(agenda)。冲突解决模块按一定的策略从被触发的多条规则中选择一条。动作执行模块执行被选择出来的规则的RHS,从而对WM进行一定的操作。因此,推理算法的核心是做规则匹配。但这个匹配过程并不简单,如下图所示,对于规则中的每一个条件都可能有很多事实进行匹配,想象一下在关系数据库中所面临的Join计算的复杂性问题,规则匹配也是一个组合爆炸问题。


Rete算法
Rete算法是产生式规则系统中常用的推理算法。它也是一个比较传统的算法,其核心思想是将产生式规则中的LHS部分组织成判别网络,然后用分离的匹配项构造匹配网络,同时缓存中间结果。其基本优化思想是以空间来换取时间。下面简要介绍Rete算法的基本过程。如下图所示, α \alpha α网络用来检验和保存规则集合中每条规则所对应的条件集合。 β \beta β网络用于保存Join计算的中间结果。例如,Working Memeory中的所有事实首先与 α \alpha α网络中的元素进行匹配,然后按网络的结构形式完成Join操作,Join的中间结果保存于 β \beta β网络,最终结果加入议程完成推理。

Rete算法高效的主要原因是用空间换时间。Rete算法是一种启发式算法,不同规则之间往往含有相同的模式,因此在Rete网络中可以共享不同规则的条件部分。如果Rete网络中的某一个条件节点被 N N N条规则共享,则算法在此节点上效率会提高 N N N倍。Rete算法由于采用AlphaMemory和BetaMemory存储事实,当事实集合变化不大时,保存在 α \alpha α和 β \beta β节点中的状态不需要太多变化,避免了大量的重复计算,提高了匹配效率。从Rete网络可以看出,Rete匹配速度与规则数目无直接关系,这是因为事实只有满足本节点才会继续向下沿网络传递。
符号知识图谱推理总结
常见的基于符号的知识图谱推理方法有基于OWL的本体推理,基于Datalog的规则推理和比较传统的基于Rete算法的产生式规则推理。基于符号表示的推理的最大优势是精确并具有可解释性,因而对那些规模可控,对知识表示的精确度要求比较高的场景更加适用。这类基于符号表示的推理都是基于演绎逻辑的推理,对知识的表示和描述要求比较高,这增加了知识获取的难度,同时在知识库规模比较大时,推理的健壮性和效率都会降低。因此,当前更多的研究是基于大数据的推理实现,这将在后面展开介绍。
参考文献:
[1] 陈华钧.知识图谱导论[M].电子工业出版社, 2021
[2] 邵浩, 张凯, 李方圆, 张云柯, 戴锡强. 从零构建知识图谱[M].机械工业出版社, 2021