利用Python进行数据分析之超市零售分析
| Author | Bryce230 |
|---|---|
| [email protected] | |
| Software | win10,Pycharm2019.3.3,Python3.7.7,jupyter notebook |
超市零售数据分析
- 1 背景与需求
- 2 数据收集与整合
- 3 数据清洗
- 4 数据分析及可视化
-
- 4.1 销售情况分析
-
- 4.1.1 销售额分析
- 4.1.2 销量分析
- 4.1.3 利润分析
- 4.1.4 客单价分析
- 4.1.5 市场布局分析
- 4.2 商品情况分析
-
- 4.2.1 销量前10名的商品
- 4.2.2 销售额前10名的商品
- 4.2.3 利润前10的商品
- 4.2.4 商品种类销售情况
- 4.3 用户情况分析
-
- 4.3.1 不同类型的用户占比
- 4.3.2 用户下单行为分析
- 4.3.3 RFM模型分析
- 4.3.4 新用户、活跃用户、不活跃用户和回归用户分析
- 4.3.5 复购率和回购率分析
- 5 总结
- 6 参考资料
1 背景与需求
本文主要对一家全球超市四年(2011-2014)的销售数据进行销售情况分析、商品情况分析和用户情况分析,并给出提升销量的建议。(本文基于参考资料[2],在其基础上做了进一步的分析,并得出详细的结论)
销售情况分析:销售额、销量、利润、客单价和市场布局等情况分析;
商品情况分析:商品结构、优势商品、劣势/待优化商品等情况分析;
用户情况分析:客户数量、新老客户、RFM模型、复购率和回购率等情况分析。
2 数据收集与整合
数据来源于kaggle平台,是一份全球大型超市四年的零售数据集,共有51290条数据,共24个特征。想获取原始数据集,见参考资料。
整合数据:
# 加载数据分析需要使用的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
plt.rcParams['font.sans-serif'] = ['SimHei']
warnings.filterwarnings('ignore')
#数据加载和整合
# 加载零售数据集,使用'ISO-8859-1'编码方式
df = pd.read_csv('superstore_dataset2011-2015.csv',encoding='ISO-8859-1')
df.head()
#数据大小
df.shape
#数据分布情况
df.describe()
3 数据清洗
1)改写不符合规则的列名,统一采用下划线格式
#重命名列名
df.rename(columns = lambda x: x.replace(' ', '_').replace('-', '_'), inplace=True)
2)将下单日期改为datetime类型
df["Order_Date"] = pd.to_datetime(df["Order_Date"])
3)方便后续的分析,新增加年份列和月份列
df['year'] = df["Order_Date"].dt.year
df['month'] = df['Order_Date'].values.astype('datetime64[M]')
4)邮编信息一列缺失太多,且对后续分析无影响,直接删除
#查看缺失值
df.isnull().sum(axis=0)
#删除邮编信息列
df.drop(["Postal_Code"],axis=1, inplace=True)
5)查看有无异常值
#异常值处理
df.describe() #无异常,不需要处理
#重复值处理
df.duplicated().sum() #无重复值,不需要处理
4 数据分析及可视化
4.1 销售情况分析
构建销售情况子数据集,并按照年份、月份对销售子数据集进行分组求和。
# 整体销售情况子数据集,包含下单日期、销售额、销量、利润、年份、月份信息
sales_data = df[['Order_Date','Sales','Quantity','Profit','year','month']]
#按照年份、月份对销售子数据集进行分组求和
sales_year = sales_data.groupby(['year','month']).sum()
部分结果如下:
Sales Quantity Profit
year month
2011 2011-01-01 138241.30042 2178 13457.23302
2011-02-01 134969.94086 1794 17588.83726
2011-03-01 171455.59372 2183 16169.36062
2011-04-01 128833.47034 2181 13405.46924
2011-05-01 148146.72092 2057 14777.45792
2011-06-01 189338.43966 2715 25932.87796
2011-07-01 162034.69756 2266 10631.84406
2011-08-01 219223.49524 2909 19650.67124
2011-09-01 255237.89698 3357 32313.25458
2011-10-01 204675.07846 2615 30745.54166
2011-11-01 214934.29386 3165 21261.40536
2011-12-01 292359.96752 4023 33006.85862
对以上数据进行拆分,每年为一个表
year_2011 = sales_year.loc[(2011,slice(None)),:].reset_index()
year_2012 = sales_year.loc[(2012,slice(None)),:].reset_index()
year_2013 = sales_year.loc[(2013,slice(None)),:].reset_index()
year_2014 = sales_year.loc[(2014,slice(None)),:].reset_index()
4.1.1 销售额分析
#销售额分析
sales=pd.concat([year_2011['Sales'],year_2012['Sales'],
year_2013['Sales'],year_2014['Sales']],axis=1)
# 对行名和列名进行重命名
sales.columns=['Sales-2011','Sales-2012','Sales-2013','Sales-2014']
sales.index=['Jau','Feb','Mar','Apr','May','Jun','Jul','Aug','Sep','Oct','Nov','Dec']
# 颜色越深,销售额越高
sales.style.background_gradient()
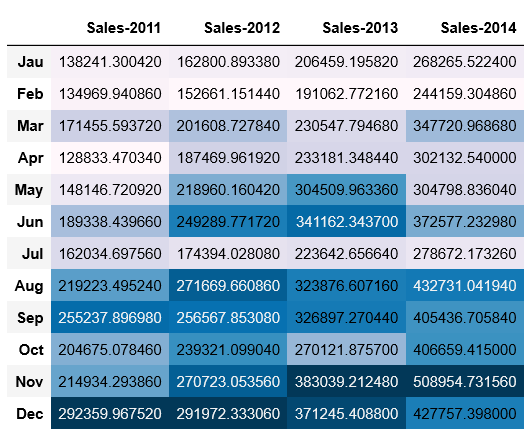
从上面的销售额表可以得出,下半年的销售额明显好于上半年,且逐年递增。
计算每年的销售总额及增长率并绘图显示:
sales_sum=sales.sum()
sales_sum.plot(kind='bar',alpha=0.5)
plt.grid()
# 计算每年增长率
rise_12=sales_sum[1]/sales_sum[0]-1
rise_13=sales_sum[2]/sales_sum[1]-1
rise_14=sales_sum[3]/sales_sum[2]-1
rise_rate=[0,rise_12,rise_13,rise_14]
# 显示增长率
sales_sum=pd.DataFrame({'sales_sum':sales_sum})
sales_sum['rise_rate']=rise_rate
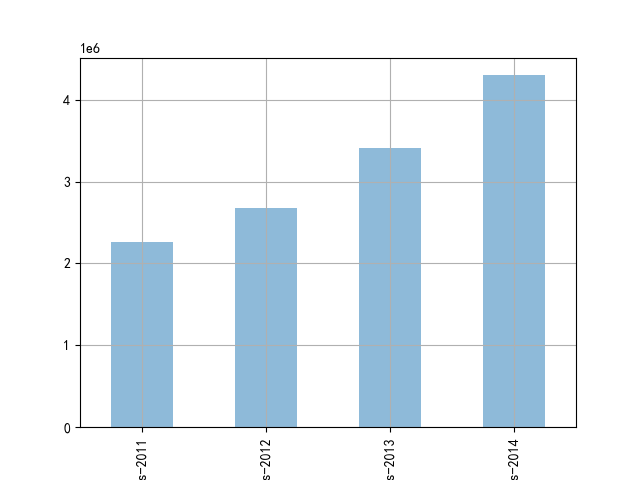
从上图可以看出,销售额是逐年递增的,2014的销售额接近于2011年的两倍,说明公司发展势头很好。接着了解每月的销售额情况,用面积图显示
sales.plot.area(stacked=False)
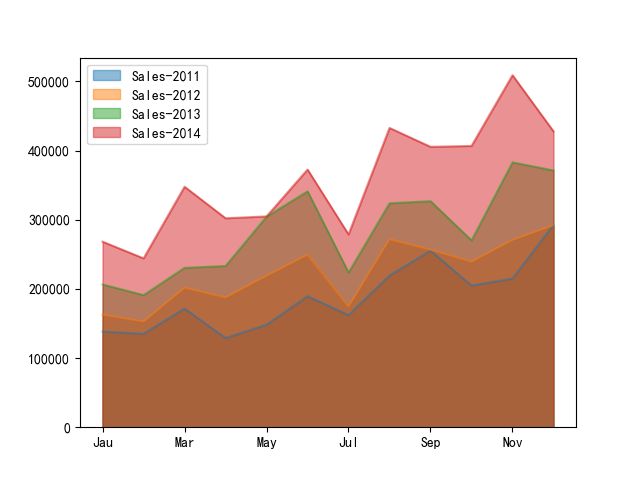 从图中可以看出,在一年中,销售额基本呈现整体递增趋势,下半年好于上半年。
从图中可以看出,在一年中,销售额基本呈现整体递增趋势,下半年好于上半年。
因此,下半年运营推广等策略要继续维持,还可以加大投入,提高整体销售额;而在上半年,可以结合产品特点进行新产品拓展,举办一些促销活动等吸引客户。
4.1.2 销量分析
构建销量表并递增显示
#销量分析
quantity = pd.concat([year_2011['Quantity'],year_2012['Quantity'],
year_2013['Quantity'],year_2014['Quantity']],axis=1)
# 对行名和列名进行重命名
quantity.columns=['Quantity-2011','Quantity-2012','Quantity-2013','Quantity-2014']
quantity.index=['Jau','Feb','Mar','Apr','May','Jun','Jul','Aug','Sep','Oct','Nov','Dec']
# 颜色越深,销量越高
quantity.style.background_gradient()
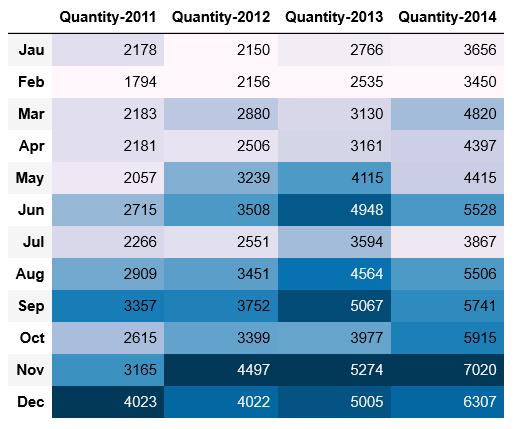
计算销量增长率和每年的销量总和
# 计算年度销量并图表展示
quantity_sum=quantity.sum()
quantity_sum.plot(kind='bar',alpha=0.5)
plt.grid()
# 计算每年增长率
rise_12=quantity_sum[1]/quantity_sum[0]-1
rise_13=quantity_sum[2]/quantity_sum[1]-1
rise_14=quantity_sum[3]/quantity_sum[2]-1
rise_rate=[0,rise_12,rise_13,rise_14]
# 显示增长率
quantity_sum=pd.DataFrame({'quantity_sum':quantity_sum})
quantity_sum['rise_rate']=rise_rate
 与销售额趋势一致,销量也是下半年好于上半年,且逐年递增。
与销售额趋势一致,销量也是下半年好于上半年,且逐年递增。
4.1.3 利润分析
构建利润表
profit=pd.concat([year_2011['Profit'],year_2012['Profit'],
year_2013['Profit'],year_2014['Profit']],axis=1)
profit.columns=['Profit-2011','Profit-2012','Profit-2013','Profit-2014']
profit.index=['Jau','Feb','Mar','Apr','May','Jun','Jul','Aug','Sep','Oct','Nov','Dec']
profit.style.background_gradient()
结果如下:
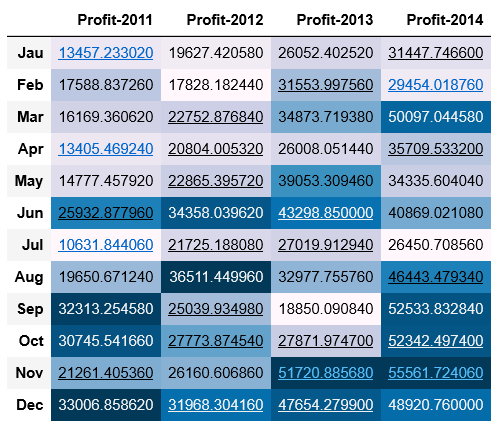
计算每年总利润和利润率
profit_sum=profit.sum()
profit_sum.plot(kind='bar',alpha=0.5)
plt.grid()
profit_sum=pd.DataFrame({'profit_sum':profit_sum})
profit_sum["year"] = [2011, 2012, 2013, 2014]
sales_sum=pd.DataFrame({'sales_sum':sales.sum()})
sales_sum["year"] = [2011, 2012, 2013, 2014]
profit_sum = pd.merge(profit_sum, sales_sum)
profit_sum["profit_rate"] = profit_sum["profit_sum"] / profit_sum["sales_sum"]
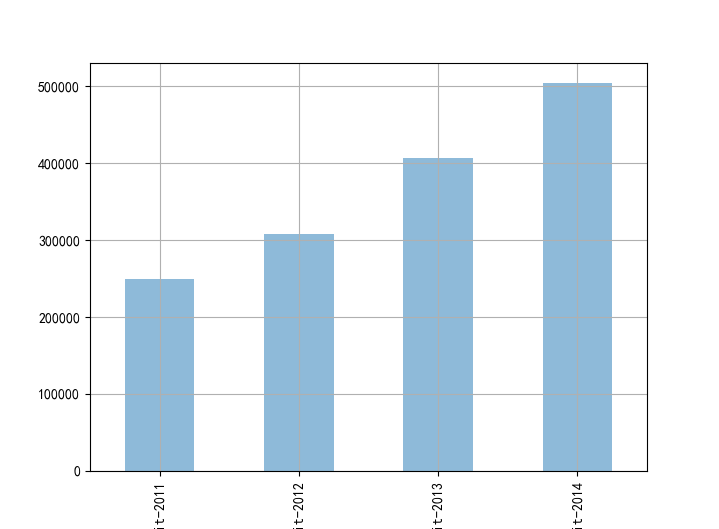 利润变化和销售额、销量变化一致,下半年利润高于上半年,逐年在递增。说明公司近几年持续收益很高,发展很不错。
利润变化和销售额、销量变化一致,下半年利润高于上半年,逐年在递增。说明公司近几年持续收益很高,发展很不错。
4.1.4 客单价分析
客单价(per customer transaction)是指商场(超市)每一个顾客平均购买商品的金额,也即是平均交易金额。(百度百科)
客单价的计算公式是:客单价=销售额÷成交顾客数。
> # 2011-2014年客单价
for i in range(2011,2015):
data=df[df['year']==i]
price=data[['Order_Date','Customer_ID','Sales']]
# 计算总消费次数
price_dr=price.drop_duplicates(
subset=['Order_Date', 'Customer_ID'])
# 总消费次数:有多少行
total_num=price_dr.shape[0]
print('{}年总消费次数='.format(i),total_num)
unit_price = price['Sales'].sum()/total_num
print('{}年客单价='.format(i), unit_price,'\n')
------------------------------------------------------------------------------
2011年总消费次数= 4453
2011年客单价= 507.3997070604087
2012年总消费次数= 5392
2012年客单价= 496.55762136498515
2013年总消费次数= 6753
2013年客单价= 504.3308824788983
2014年总消费次数= 8696
2014年客单价= 494.4647965225392
从输出结果来看,总消费次数呈现逐年递增的趋势,但是客单价保持在500左右不变。
4.1.5 市场布局分析
分析不同地区之间的销售情况
Market_Year_Sales = df.groupby(['Market', 'year']).agg({'Sales':'sum'}).reset_index().rename(columns={'Sales':'Sales_amounts'})
Market_Year_Sales.head()
sns.barplot(x='Market', y='Sales_amounts', hue='year', data = Market_Year_Sales)
plt.title('2011-2014 market sales')
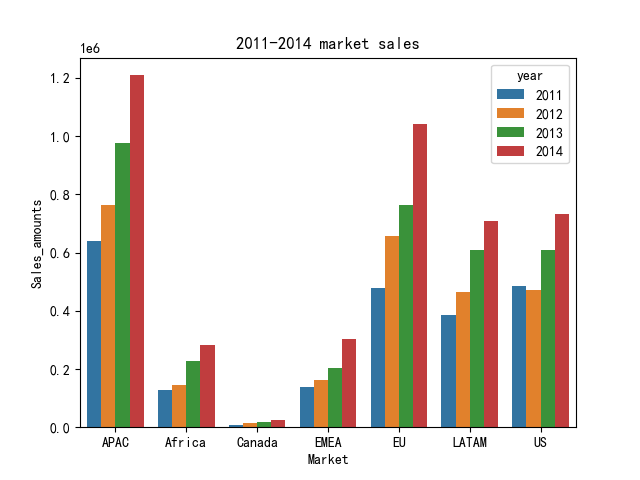 不管在哪个地区,销售额呈现逐年递增的趋势。
不管在哪个地区,销售额呈现逐年递增的趋势。
计算各个地区销售额占总销售额的百分比
Market_Sales = df.groupby(['Market']).agg({'Sales':'sum'})
Market_Sales["percent"] = Market_Sales["Sales"] / df["Sales"].sum()
Market_Sales.style.background_gradient()

从图表可以看出,每个地区每年销售额总体处于上升趋势,其中APAC(亚太地区)、EU(欧盟)、US(美国)、LATAM(拉丁美洲)的销售额超过了总销售额的85%,总体也与地区的经济发展相匹配。其中加拿大Canada的销售额微乎其微,可以结合公司整体战略布局进行取舍。
4.2 商品情况分析
4.2.1 销量前10名的商品
productId_count = df.groupby('Product_ID').count()['Customer_ID'].sort_values(ascending=False)
print(productId_count.head(10))
--------------------------------------
Product_ID
OFF-AR-10003651 35
OFF-AR-10003829 31
OFF-BI-10002799 30
OFF-BI-10003708 30
FUR-CH-10003354 28
OFF-BI-10002570 27
OFF-BI-10004140 25
OFF-BI-10004195 24
OFF-BI-10001808 24
OFF-BI-10004632 24
Name: Customer_ID, dtype: int64
4.2.2 销售额前10名的商品
productId_amount = df.groupby('Product_ID').sum()['Sales'].sort_values(ascending=False)
print(productId_amount.head(10))
-----------------------------------
Product_ID
TEC-CO-10004722 61599.8240
TEC-PH-10004664 30041.5482
OFF-BI-10003527 27453.3840
TEC-MA-10002412 22638.4800
TEC-PH-10004823 22262.1000
FUR-CH-10002024 21870.5760
FUR-CH-10000027 21329.7300
OFF-AP-10004512 21147.0840
FUR-TA-10001889 20730.7557
OFF-BI-10001359 19823.4790
Name: Sales, dtype: float64
从结果可以看出,销量最高的大部分是办公用品,而销售额最高的大部分是电子产品、家具这些单价较高的商品。
4.2.3 利润前10的商品
productId_Profit= df.groupby('Product_ID').sum()['Profit'].sort_values(ascending=False)
print(productId_Profit.head(10))
------------------------------------
Product_ID
TEC-CO-10004722 25199.9280
OFF-AP-10004512 10345.5840
TEC-PH-10004823 8121.4800
OFF-BI-10003527 7753.0390
TEC-CO-10001449 6983.8836
FUR-CH-10002250 6123.2553
TEC-PH-10004664 5455.9482
OFF-AP-10002330 5452.4640
TEC-PH-10000303 5356.8060
FUR-CH-10002203 5003.1000
Name: Profit, dtype: float64
利润最高的大部分是电子类产品。
4.2.4 商品种类销售情况
# 根据商品种类和子种类,重新重合成一个新的种类
df['Category_Sub_Category'] = df[['Category','Sub_Category']].apply(lambda x:str(x[0])+'_'+str(x[1]),axis=1)
# 按照新的种类进行分组,统计销售额和利润
df_Category_Sub_Category=df.groupby("Category_Sub_Category").agg({"Profit":"sum","Sales":"sum"}).reset_index()
# 按照销售额倒序排序
df_Category_Sub_Category.sort_values(by=["Sales"],ascending=False, inplace=True)
# 每个种类商品的销售额累计占比
df_Category_Sub_Category['cum_percent'] = df_Category_Sub_Category['Sales'].cumsum()/df_Category_Sub_Category['Sales'].sum()
df_Category_Sub_Category
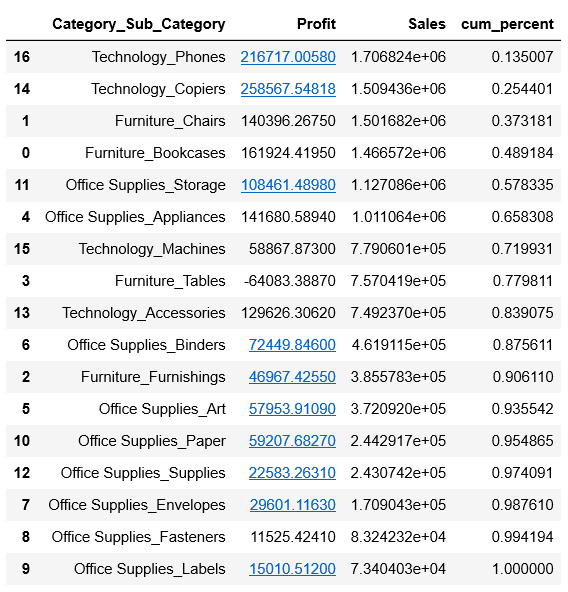 从表中可以看出,有将近一半的商品的总销售占比达到84%,大概率是自家优势主营产品,后续经营中应继续保持,可以结合整体战略发展适当加大投入,逐渐形成自己的品牌。
从表中可以看出,有将近一半的商品的总销售占比达到84%,大概率是自家优势主营产品,后续经营中应继续保持,可以结合整体战略发展适当加大投入,逐渐形成自己的品牌。
需要关注的是,Tables(桌子)的利润是负,表明这个产品目前处于亏损状态,应该是促销让利太多。通过检查原数据,发现Tabels大部分都在打折,打折的销量高达76%。如果是在清库存,这个效果还是不错的,但如果不是,说明这个产品在市场推广上遇到了瓶颈,或者是遇到强竞争对手,需要结合实际业务进行分析,适当改善经营策略。
4.3 用户情况分析
4.3.1 不同类型的用户占比
df["Segment"].value_counts().plot(kind='pie', autopct='%.2f%%', shadow=True, figsize=(14, 6))
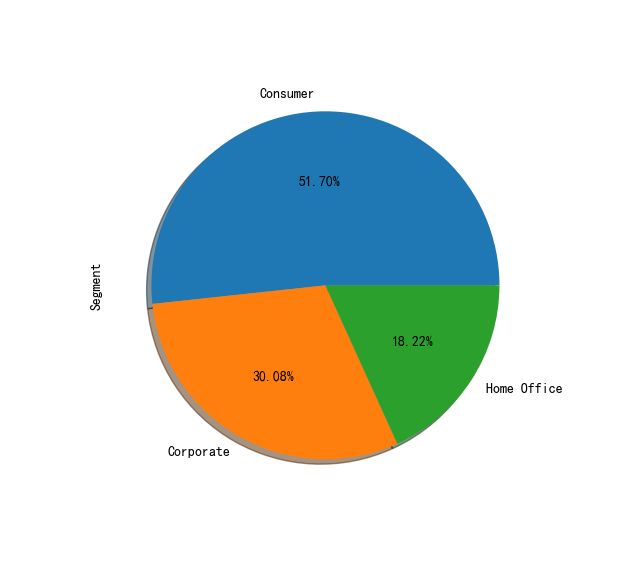 蓝色部分最大,也就是说,普通用户占比是最多的。
蓝色部分最大,也就是说,普通用户占比是最多的。
每一年不同类型的用户数量情况
Segment_Year = df.groupby(["Segment", 'year']).agg({'Customer_ID':'count'}).reset_index()
sns.barplot(x='Segment', y='Customer_ID', hue='year', data = Segment_Year)
plt.title('2011-2014 Segment Customer')
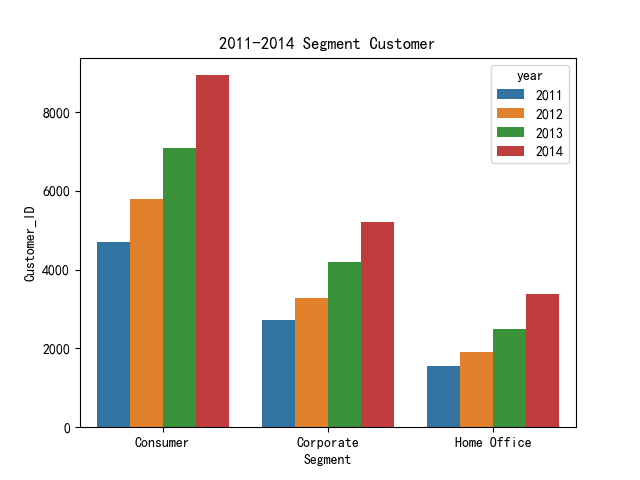 从上图可以看出,不管是哪种类型的用户,每年都是呈现一个递增的趋势,这个势头很不错。
从上图可以看出,不管是哪种类型的用户,每年都是呈现一个递增的趋势,这个势头很不错。
不同类型的用户每年贡献的销售额:
Segment_sales = df.groupby(["Segment", 'year']).agg({'Sales':'sum'}).reset_index()
sns.barplot(x='Segment', y='Sales', hue='year', data = Segment_sales)
plt.title('2011-2014 Segment Sales')
 与用户数量变化一样,不管是哪种类型的用户,用户销售额每年都是呈现一个递增的趋势。
与用户数量变化一样,不管是哪种类型的用户,用户销售额每年都是呈现一个递增的趋势。
4.3.2 用户下单行为分析
获取新的子数据集
grouped_Customer = df[['Customer_ID','Order_Date',
'Quantity', 'Sales', 'month']].sort_values(['Order_Date']).groupby('Customer_ID')
grouped_Customer.head()
用户的第一次购买日期分布
grouped_Customer.min().Order_Date.value_counts().plot()
 可以看出, 在2013年初以后新用户增长的趋势缓慢,长期来看,这不利于商家的发展,所以商家可以通过广告等推广策略吸收更多的新用户。如果能够在新客户获取上能够突破,会给企业带来很大的增长空间。
可以看出, 在2013年初以后新用户增长的趋势缓慢,长期来看,这不利于商家的发展,所以商家可以通过广告等推广策略吸收更多的新用户。如果能够在新客户获取上能够突破,会给企业带来很大的增长空间。
用户的最后一次购买日期分布
grouped_Customer.max().Order_Date.value_counts().plot()
 通过观察最近一次购买日期,可以发现用户基本没有流失,也验证了每年销售额的增长趋势。
通过观察最近一次购买日期,可以发现用户基本没有流失,也验证了每年销售额的增长趋势。
只购买过一次的客户数量
# 统计每个客户第一次和最后一次购买记录
Customer_life = grouped_Customer.Order_Date.agg(['min','max'])
# 查看只有一次购买记录的顾客数量,第一次和最后一次是同一条记录,则说明购买只有一次
(Customer_life['min'] == Customer_life['max']).value_counts()
-----------------------------------------------------
False 1580
True 10
dtype: int64
购买一次的用户只有10位,说明该商家在维持老客方面做得很不错,这也保证了商家的销售额。
4.3.3 RFM模型分析
R是指用户的最近一次消费时间,用最通俗的话说就是,用户最后一次下单时间距今天有多长时间了,这个指标与用户流失和复购直接相关。
F是指用户下单频率,通俗一点儿就是,用户在固定的时间段内消费了几次。这个指标反映了用户的消费活跃度。
M是指用户消费金额,其实就是用户在固定的周期内在平台上花了多少钱,直接反映了用户对公司贡献的价值。
而RFM模型就是通过一个客户的近期购买行为、购买的总体频率以及花了多少钱三项指标,来描述该客户的价值状况。
 构建RFM表
构建RFM表
rfm = df.pivot_table(index='Customer_ID',
values = ["Quantity","Sales","Order_Date"],
aggfunc={"Quantity":"sum","Sales":"sum","Order_Date":"max"})
# 所有用户最大的交易日期为标准,求每笔交易的时间间隔即为R
rfm['R'] = (rfm.Order_Date.max() - rfm.Order_Date)/np.timedelta64(1,'D')
# 每个客户的总销量即为F,总销售额即为M
rfm.rename(columns={'Quantity':'F','Sales':'M'},inplace = True)
rfm.head()

对客户价值进行标注,将客户分为8个等级
# 基于平均值做比较,超过均值为1,否则为0
rfm[['R','F','M']].apply(lambda x:x-x.mean())
def rfm_func(x):
level =x.apply(lambda x:'1'if x>0 else '0')
level =level.R +level.F +level.M
d = {
"111":"重要价值客户",
"011":"重要保持客户",
"101":"重要挽留客户",
"001":"重要发展客户",
"110":"一般价值客户",
"010":"一般保持客户",
"100":"一般挽留客户",
"000":"一般发展客户"
}
result = d[level]
return result
rfm['label']= rfm[['R','F','M']].apply(lambda x:x-x.mean()).apply(rfm_func,axis =1)
rfm.head()
 重要价值客户和非重要价值客户进行可视化展示
重要价值客户和非重要价值客户进行可视化展示
rfm.loc[rfm.label=='重要价值客户','color']='g'
rfm.loc[~(rfm.label=='重要价值客户'),'color']='r'
rfm.plot.scatter('F','R',c= rfm.color)
 从图中可以看出,R值小的F值大的点数占多,这说明最近购买的日期很近,交易频率也很高,这是很好的现象。
从图中可以看出,R值小的F值大的点数占多,这说明最近购买的日期很近,交易频率也很高,这是很好的现象。
4.3.4 新用户、活跃用户、不活跃用户和回归用户分析
设置Customer_ID为索引,month为列名,统计每个月的购买次数。
pivoted_counts = df.pivot_table(index= 'Customer_ID',
columns= 'month',
values= 'Order_Date',
aggfunc= 'count').fillna(0)
# 大于一次的全部设为1
df_purchase = pivoted_counts.applymap(lambda x:1 if x>0 else 0)
df_purchase.head()
定义状态函数并进行状态标记。
def active_status(data):
status = []
for i in range(48):
if data[i] == 0:
if len(status)>0:
if status[i-1] == "unreg":
# 未注册客户
status.append("unreg")
else:
# 不活跃用户
status.append("unactive")
else:
status.append("unreg")
# 若本月消费了
else:
if len(status) == 0:
# 新用户
status.append("new")
else:
if status[i-1] == "unactive":
# 回归用户
status.append("return")
elif status[i-1] == "unreg":
status.append("new")
else:
status.append("active")
return pd.Series(status)
purchase_stats = df_purchase.apply(active_status,axis =1)
purchase_stats.head()
结果如下:
 用NaN替代 “unreg”,并统计每月各状态客户数量。
用NaN替代 “unreg”,并统计每月各状态客户数量。
purchase_stats_ct = purchase_stats.replace('unreg',np.NaN).apply(lambda x:pd.value_counts(x))
# 用0填充NaN
purchase_stats_ct.fillna(0).T.plot.area()
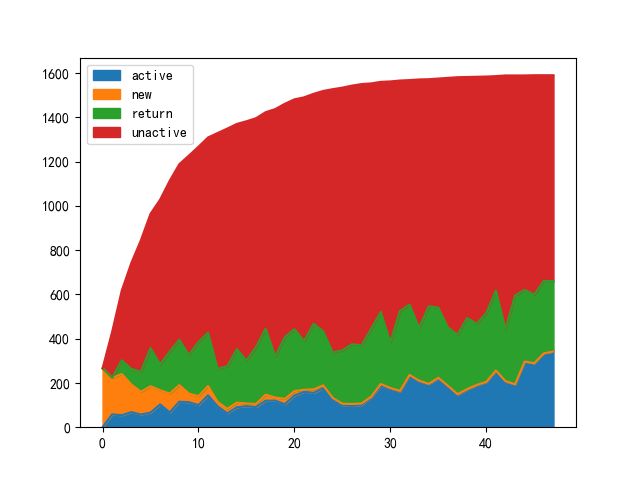 从以上结果可以发现活跃客户、新客户和回归客户,每年呈一定的规律起伏,这可能和年终大促有关,需要更多数据进行验证。
从以上结果可以发现活跃客户、新客户和回归客户,每年呈一定的规律起伏,这可能和年终大促有关,需要更多数据进行验证。
4.3.5 复购率和回购率分析
复购率计算指标:用户在该月购买过一次以上算复购。
purchase_r = pivoted_counts.applymap(lambda x :1 if x>1 else np.NaN if x==0 else 0)
(purchase_r.sum()/purchase_r.count()).plot(figsize=(10,4))

回购率计算指标:在该月购买过,且在下月也购买时计入回购。
def purchase_back(data):
status=[]
for i in range(47):
if data[i] ==1:
if data[i+1] == 1:
status.append(1)
if data[i+1] == 0:
status.append(0)
else:
status.append(np.NaN)
status.append(np.NaN)
return status
purchase_b = df_purchase.apply(purchase_back,axis =1,result_type='expand')
(purchase_b.sum()/purchase_b.count()).plot(figsize=(10,4))

从上可以发现复购率基本大于0.52,且呈总体上升趋势,说明客户忠诚度高,也和之前分析的商家维持老客做得很好相对应;回购率在年中年末呈峰形态,可能与商家折扣活动或节日有关,间接也说明活动或节日起到了一定的影响力。
5 总结
1)从销售情况分析来看,每年下半年的销售额、销量和利润均是明显好于上半年,且均逐年递增;从输出结果来看,总消费次数呈现逐年递增的趋势,但是客单价保持在500左右不变;不管在哪个地区,销售额呈现逐年递增的趋势。
2)从商品情况分析来看,销量最高的大部分是办公用品,电子产品的销售额最高而且利润最大,所以商家可以持续发展在电子产品类的利润优势,但是Tables(桌子)的利润是负的,需要保持关注,收集更多数据去了解和确定产生负利润的原因。
3)从用户情况分析来看,不管是哪种类型的用户,其数量和销售额每年都是呈现一个递增的趋势;该商家在维持老客方面做得很不错,但是2013年初后,新客增长趋势缓慢,商家需要通过广告、活动等方式吸引更多的新客。
6 参考资料
1、原始数据集
链接:https://pan.baidu.com/s/13QNHG7sRZu4iwcJ4Sz9F1g
提取码:ec7j
2、数据分析实战之超市零售分析
3、RFM模型
4、python 数据表格的合并和重塑